本文主要是介绍深度学习基础——激活函数以及什么时候该使用激活函数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载地址:http://www.datalearner.com/blog/1051508750742453
一、简介
如今的互联网提供了大量的信息。我们只需要通过Google就可以找到这些信息。而我其中最重要的一个挑战是区分相关信息和非相关信息。当我们的大脑充满了信息的时候,它会第一时间区分哪些是有用信息哪些是无用信息。因此,在神经网络中我们也需要一个类似的机制来区分有用信息和无用信息。
这是一个非常重要的概念。因为并不是所有的信息都是同样重要的,有些信息可能就是噪音。激活函数就是帮助网络来区分这些信息。激活函数帮助神经网络获取有用信息而抛弃无用信息。在这篇博客中,我们将看看有哪些激活函数,以及它们的工作原理,并讲述这些激活函数分别适用哪些问题。
在我们讲述激活函数的细节之前,我们来简单描述一下神经网络以及它们的工作原理。神经网络是非常重要的一种机器学习机制,它是一种模仿人类大脑学习机制的一种方法。人类的大脑从外界接受刺激,并处理这些输入(通过神经元处理),最终产生输出。
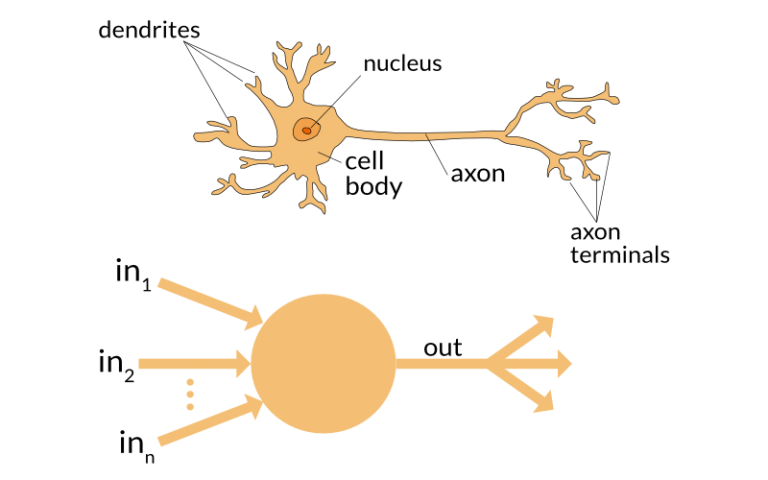
当任务变得复杂的时候,大脑会使用多个神经元来形成一个复杂的网络,并在神经元之间传递信息。
人工神经网络就是模仿这种处理机制的一种算法。如下图的网络是一种由多个互联的神经元组成的网络。
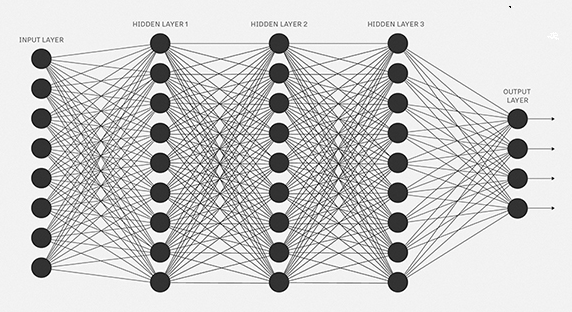
图中黑色的圆圈就是上述的神经元。每一个神经元都由权重、偏移和激活函数组成。数据由输入层输入。然后神经元基于权重和偏移,通过线性变换将输入数据进行转换。激活函数则是用来完成非线性的转换。数据从输入层输入后,会来到隐藏层。隐藏层将会对数据进行处理并输送到输出层。这种数据处理方式就是著名的前向传播。但是,当输出层的结果和我们期望的结果相差很大怎么办呢?在神经网络中,我们可以基于这种错误来更新神经元的权重和偏移。这种处理方式被称为后向传播算法。一旦所有的数据经历过这个处理,最终的权重和便宜就可以用来做预测了。
上面这一小段是原文的翻译,不太好懂,这里我做一个简单点的说明。实际上,一个神经网络算法主要有输入层、隐藏层和输出层组成,输入层接受数据,并对数据做一些转换后传递给隐藏层,隐藏层则是对转换后的数据做数据处理,处理完成发送给输出层。详情可以参考人工神经网络(Artificial Neural Network)算法简介。
神经网络中每一层都是有多个神经元组成的,且隐藏层可以有多个,并可以互相连接。每个神经元其实可以理解成如下的线性回归的模型:
\text{neron} = W^TX+W_0neron=WTX+W0
这里的XX是这个神经元的输入,一般它都是来自于前面一层的某些或者所有的神经元的结果。W^TWT是这个神经元的权重,是需要我们计算的,W_0W0是这个偏移。所有的神经元都是类似这种结构。并以一种方式互相连接,连接就是谁的输出作为谁的输入的意思。但是,这种方式都是线性变换,对于复杂问题的建模是不够的,因此对于每个神经元的上述结果,我们做一个非线性的转换f(\cdot)f(⋅)。这里的\cdot⋅就是刚才那个线性模型的输出,ff就是激活函数了。这样的神经网络可以对较为复杂的任务建模。
激活函数是神经网络中极其重要的概念。它们决定了某个神经元是否被激活,这个神经元接受到的信息是否是有用的,是否该留下或者是该抛弃。激活函数的形式如下:
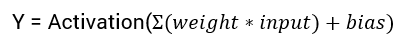
激活函数是我们对输入做的一种非线性的转换。转换的结果输出,并当作下一个隐藏层的输入。
在上式中我们可以看到,激活函数大大增加了神经网络的复杂性,那么没有神经网络是否可行呢?
当没有神经网络的时候,神经元对数据的处理就是基于权重和偏移做线性变换。线性变换很简单,但是限制了对复杂任务的处理能力。没有激活函数的神经网络就是一个线性回归模型。激活函数做的非线性变换可以使得神经网络处理非常复杂的任务。例如,我们希望我们的神经网络可以对语言翻译和图像分类做操作,这就需要非线性转换。
同时,激活函数也使得反向传播算法变的可能。因为,这时候梯度和误差会被同时用来更新权重和偏移。没有可微分的线性函数,这就不可能了。
最简单的决定神经元是否被激活的方式是基于分类器使用一个二元阶梯函数。例如,当分类器结果Y高于某个值的时候,我们使用这个神经元,否则就抛弃这个信息。例如,我们可以定义如下:
f(x) = \begin{cases} 1 &\text{if } x \geqslant 0 \\ 0 &\text{if } x < 0 \end{cases}f(x)={10if x⩾0if x<0
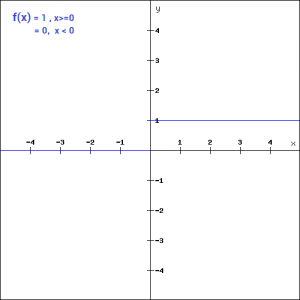
二元阶梯函数非常简单,他可以用来创建二元分类器。当我们对一个东西只要简单的回答“是”或者“否”的时候,阶梯函数是很好的选择,因为它使得神经元要么被激活,要么被抛弃。
但是二元阶梯函数通常只在理论上用的多。实际中,我们大部分时候需要对物体做多类别分类,而不是简单得将其划分到某一类中,阶梯函数无法做到这点。
同时,阶梯函数的梯度是0。这使得梯度函数在后向传播算法中不可行。因为后向传播算法需要使用激活函数的梯度计算误差来优化结果。由于阶梯函数的梯度为0,因此模型不会有任何实际的提升。
线性函数也很简单,我们可以定义一个如下的线性函数:
f(x) = axf(x)=ax
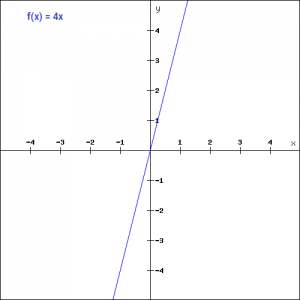
图中我们列决的是一个4倍的线性转换。我们对输入值xx扩大4倍。这种激活函数可以同时应用在多个不同的神经元上,可以同时激活多个神经元。当我们有多个类别的时候,我们可以取结果最大的类别作为激活的类别。但是我们依然有些问题,比如上式这个线性函数的梯度是4。也就是说,这个激活函数的梯度不依赖于任何输入值。这就意味着在做反向传播的时候,梯度总是一样的。那么,我们其实没有做任何优化模型的措施。而且,这是一个线性的转换,那么,不管我们有多少个层,我们最终其实都是在做线性变换。
Sigmoid函数是一种运用非常广泛的激活函数。形式如下:
f(x) = \frac{1}{1+e^{-x}}f(x)=1+e−x1
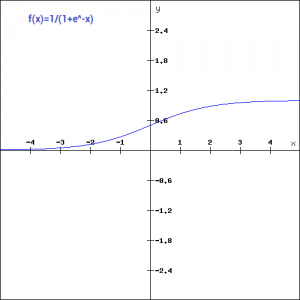
这是一个连续且可微的函数。它比上述两种激活函数最大的优点是非线性的。这点是非常厉害的。这意味着当我们有多个不同的神经元的时候,其输出结果也都是非线性的。这个函数是0-1之间的S形的。我们看一下这个函数的梯度(如下图所示),它在-3到3之间是比较大的。但是在其他地方是比较平坦的。
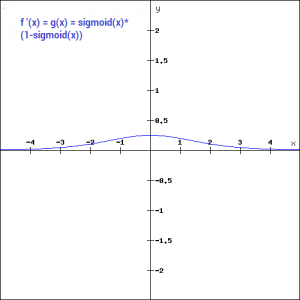
这意味着很小范围内的x的变动也可以导致Y值较大的变化。这种函数使得Y值趋向于极端情况。这种特性非常适合我们将某些值分到某种特定的类别上。
同时,这个函数的梯度也是光滑的,而且是依赖于输入值x的。这就意味着后向传播算法也可以使用。误差可以通过后向传播的方式传递给前面的神经元,并对其权重和偏移做更新。
Sigmoid函数在今天运用非常广泛,但是仍然有些问题需要解决。前面说道,在-3和3之外的区域,它的图像很平坦。这就意味着一旦函数的结果落入这个区域,它的梯度也会非常平坦,且接近于0,也就意味着后向传播的优化就不存在了。
另一个问题是Sigmoid函数的值域在0-1之间。这就意味着它并不是一个对称的算法,它的值都是正值。但是并不是所有的时候我们都希望下一个神经元只接受正值。这导致了tanh激活函数的出现。
Tanh函数的形式和Sigmoid很像,如下:
\tanh(x) = 2\text{sigmoid}(2x) - 1 = \frac{2}{1+e^{-x}} - 1tanh(x)=2sigmoid(2x)−1=1+e−x2−1
其图形如下:
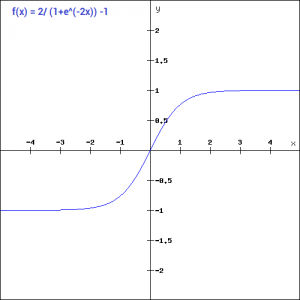
我们可以看到,这个图形是完全对称的,它的值域范围也是-1到1之间。它解决了Sigmoid函数的上述两个缺点。而其他特性又和Sigmoid函数一样。它是在所有点上连续可导的。其梯度的图像如下:
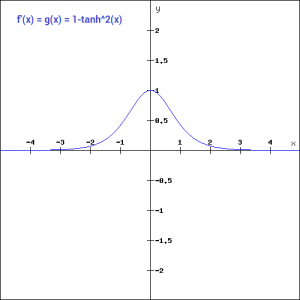
Tanh的梯度相比较Sigmoid更加陡峭。我们选择Sigmoid还是Tanh是根据问题中对梯度的要求而定的。但是,和Sigmoid类似,Tanh也有梯度崩塌的情况。即区域外的Tanh非常平坦,其梯度特别小。
ReLU是整流线性单元。它也是最广泛使用的激活函数之一,形式和图形如下:
f(x) = max(0,x)f(x)=max(0,x)
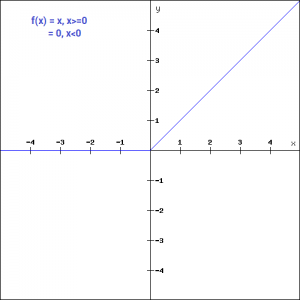
之所以是最广泛使用的激活函数原因首先是它是非线性的,也就意味着反向传播算法可用。而ReLu一个非常好的特性是它不会同时激活所有的神经元。这是什么意思呢?我们可以看到ReLU的图形,在输入是负值的情况下,它会输出0,那么神经元就不会被激活。这意味着同一时间只有部分神经元会被激活,从而使得网络很稀疏,进而对计算来说是非常有效率的。
ReLU的梯度如下:

但是ReLU也会有一个趋向于0的梯度区域。也就是说,反向传播中,输入值是负值也不会再更新了。这意味着有些神经元是死的,永远不会被激活。
Leaky ReLU激活函数是ReLU的一个改进版本。我们看到在x\lt 0x<0的时候,其梯度为0,这使得这个区域的神经元死掉了。而Leaky ReLU就是为了解决这个问题。其形式和图形如下:
f(x) = \begin{cases} ax, &x<0 \\ x, &x \geqslant 0 \end{cases}f(x)={ax,x,x<0x⩾0
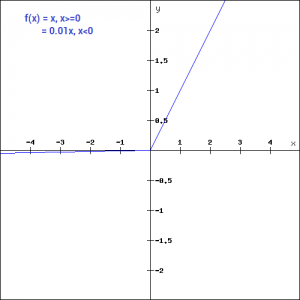
这个函数最好的优点是将0的梯度去掉,换成了一个非0的梯度。这里一般我们会把这个aa值设置得比较小,如0.01等。这样子做把0梯度变成了一个很小的但是不为0的梯度。
类似的,我们也可以定一个参数化的ReLU激活函数(Parameterised ReLU function)。这个函数的意思就是把a变成一个需要学习的参数。Parameterised ReLU function是当Leaky ReLU依然失败的时候使用。
Softmax是另一种Sigmoid函数,但是它是在分类中比较容易控制的一种激活函数。Sigmoid只能处理两类的问题。Softmax将输出结果压缩在0-1之间,并依据输出的总和来分类。它给输入的概率一个概率。Softmax形式如下:
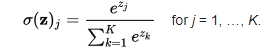
假设我们的一个输出结果是[1.2,0.9,0.75][1.2,0.9,0.75],当我们使用了softmax之后,这个值变成了[0.42, 0.31, 0.27][0.42,0.31,0.27],我们可以使用这些概率当做每一类的概率。
Softmax在输出层中使用是比较完美的,这里我们通常是需要获得输入数据对应的类别的各种概率。
这么多激活函数需要在什么时候使用什么呢?这里并没有特定的规则。但是根据这些函数的特征,我们也可以总结一个比较好的使用规律或者使用经验,使得网络可以更加容易且更快的收敛。
- Sigmoid函数以及它们的联合通常在分类器的中有更好的效果
- 由于梯度崩塌的问题,在某些时候需要避免使用Sigmoid和Tanh激活函数
- ReLU函数是一种常见的激活函数,在目前使用是最多的
- 如果遇到了一些死的神经元,我们可以使用Leaky ReLU函数
- 记住,ReLU永远只在隐藏层中使用
- 根据经验,我们一般可以从ReLU激活函数开始,但是如果ReLU不能很好的解决问题,再去尝试其他的激活函数
这篇关于深度学习基础——激活函数以及什么时候该使用激活函数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





