本文主要是介绍从零手搓中文大模型|Day04|模型参数和训练启动|我的micro大模型预训练成功跑起来啦,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
走过路过不要错过,先关注一下,第一时间获取最新进度(或催更)

从零手搓中文大模型|🚀Day04
前面已经完成了数据预处理,今天我们来研究一下模型的配置。
litgpt使用的配置文件和transformers有点不太一样,它的仓库里提供了一些预训练所用的yaml配置文件样例。这个主要用于需要自定义模型的场景。
另外litgpt也内置了一些huggingface上的现成模型,可以直接拿来使用。
训练配置文件
以下是我这次定义的一个配置文件。
内容有点多,但是还是都列举出来了,可以直接跳到后面对一些关键参数的解释。
# The name of the model to pretrain. Choose from names in ``litgpt.config``. Mutually exclusive with
# ``model_config``. (type: Optional[str], default: null)
model_name: microstories# A ``litgpt.Config`` object to define the model architecture. Mutually exclusive with
# ``model_config``. (type: Optional[Config], default: null)
model_config:name: microstorieshf_config: {}scale_embeddings: falseblock_size: 512padded_vocab_size: 65024vocab_size: 64798n_layer: 6n_head: 6n_query_groups: 6n_embd: 512head_size: 48rotary_percentage: 1.0parallel_residual: falsebias: falsenorm_class_name: RMSNormmlp_class_name: LLaMAMLPintermediate_size: 768# Directory in which to save checkpoints and logs. If running in a Lightning Studio Job, look for it in
# /teamspace/jobs/<job-name>/share. (type: <class 'Path'>, default: out/pretrain)
out_dir: /home/puppyapple/Server/BigAI/Chinese_LLM_From_Scratch/Experiments/Output/pretrain/microstories# The precision to use for pretraining. Possible choices: "bf16-true", "bf16-mixed", "32-true". (type: Optional[str], default: null)
precision: bf16-mixed# Optional path to a checkpoint directory to initialize the model from.
# Useful for continued pretraining. Mutually exclusive with ``resume``. (type: Optional[Path], default: null)
initial_checkpoint_dir:# Path to a checkpoint directory to resume from in case training was interrupted, or ``True`` to resume
# from the latest checkpoint in ``out_dir``. An error will be raised if no checkpoint is found. Passing
# ``'auto'`` will resume from the latest checkpoint but not error if no checkpoint exists.
# (type: Union[bool, Literal["auto"], Path], default: False)
resume: true# Data-related arguments. If not provided, the default is ``litgpt.data.TinyLlama``.
data:# TinyStoriesclass_path: litgpt.data.LitDatainit_args:data_path: Chinese_LLM_From_Scratch/Data/TinyStoriesChinese/processed_datasplit_names:- train- val# Training-related arguments. See ``litgpt.args.TrainArgs`` for details
train:# Number of optimizer steps between saving checkpoints (type: Optional[int], default: 1000)save_interval: 1000# Number of iterations between logging calls (type: int, default: 1)log_interval: 1# Number of samples between optimizer steps across data-parallel ranks (type: int, default: 512)global_batch_size: 512# Number of samples per data-parallel rank (type: int, default: 4)micro_batch_size: 32# Number of iterations with learning rate warmup active (type: int, default: 2000)lr_warmup_steps: 1000# Number of epochs to train on (type: Optional[int], default: null)epochs:# Total number of tokens to train on (type: Optional[int], default: 3000000000000)max_tokens: 3000000000000# Limits the number of optimizer steps to run. (type: Optional[int], default: null)max_steps:# Limits the length of samples. Off by default (type: Optional[int], default: null)max_seq_length: 512# Whether to tie the embedding weights with the language modeling head weights. (type: Optional[bool], default: False)tie_embeddings: true# (type: Optional[float], default: 1.0)max_norm: 1.0# (type: float, default: 4e-05)min_lr: 0.0# Evaluation-related arguments. See ``litgpt.args.EvalArgs`` for details
eval:# Number of optimizer steps between evaluation calls (type: int, default: 1000)interval: 2000# Number of tokens to generate (type: Optional[int], default: null)max_new_tokens:# Number of iterations (type: int, default: 100)max_iters: 100# Whether to evaluate on the validation set at the beginning of the traininginitial_validation: false# Whether to evaluate on the validation set at the end the trainingfinal_validation: false# Optimizer-related arguments
optimizer:class_path: torch.optim.AdamWinit_args:# (type: float, default: 0.001)lr: 0.0005# (type: float, default: 0.01)weight_decay: 0.1# (type: tuple, default: (0.9,0.999))betas:- 0.9- 0.95# How many devices/GPUs to use. Uses all GPUs by default. (type: Union[int, str], default: auto)
devices: auto# How many nodes to use. (type: int, default: 1)
num_nodes: 1# Optional path to the tokenizer dir that was used for preprocessing the dataset. Only some data
# module require this. (type: Optional[Path], default: null)
tokenizer_dir: Chinese_LLM_From_Scratch/References/chatglm3-6b# The name of the logger to send metrics to. (type: Literal['wandb', 'tensorboard', 'csv'], default: tensorboard)
logger_name: wandb# The random seed to use for reproducibility. (type: int, default: 42)
seed: 42
model_config
model_config:name: microstorieshf_config: {}scale_embeddings: falseblock_size: 512padded_vocab_size: 65024vocab_size: 64798n_layer: 6n_head: 6n_query_groups: 6n_embd: 512head_size: 48rotary_percentage: 1.0parallel_residual: falsebias: falsenorm_class_name: RMSNormmlp_class_name: LLaMAMLPintermediate_size: 768
scale_embeddings控制是否对embedding进行缩放。

如果为True,那么在forward函数中会对embedding进行缩放。注意个缩放和sefl-attention中的缩放不是一回事,不要弄混了。
其实也有很多讨论关于这个地方这一步是否有必要的,目前看来似乎是区别不大,可以设置为False。
transformer中的block_size,也就是max_seq_length。padded_vovab_size和vocab_size直接取自tokenizer。n_layer和n_head都是6,构建了一个6层6头的transformer。n_query_groups是6,这是GQA(Grouped-Query Attention)的一个参数,控制query的分组。当n_query_groups等于n_head时,其实就是MHA(Multi-Head Attention)。下面这个图比较直观:
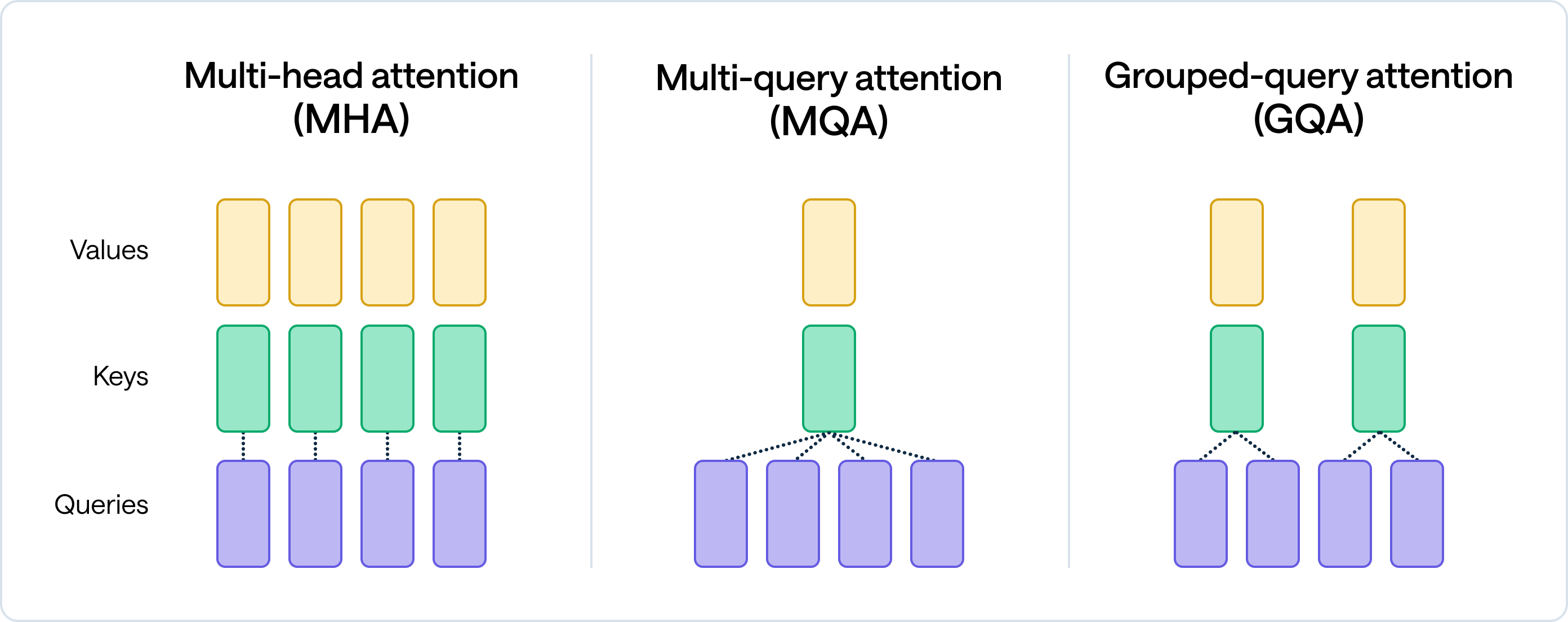
- 头的大小
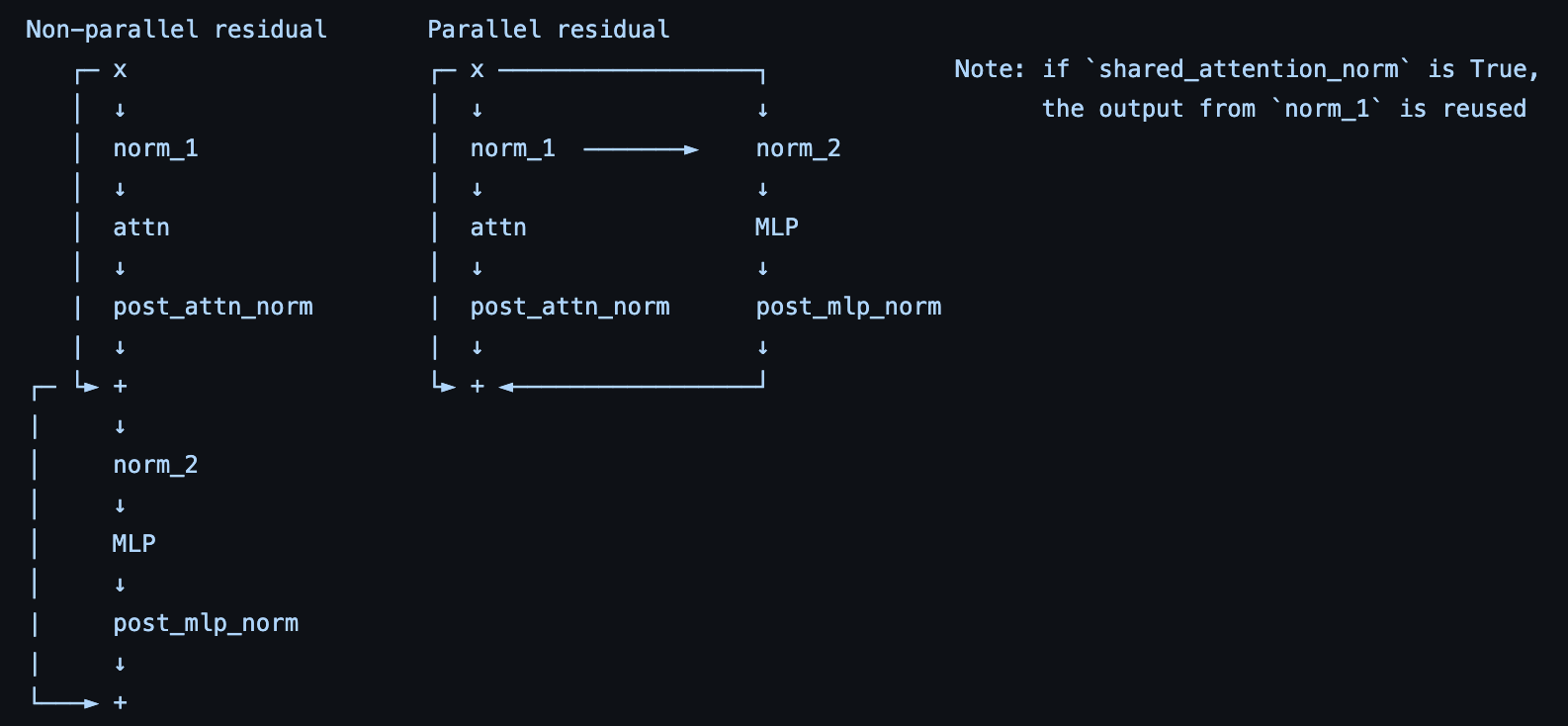
head_size是48,n_embd是512。 rotary_percentage是1.0,这个是旋转编码(Rotary Position Embedding, RoPE)的有关参数,这里先不展开介绍了。parallel_residual是false,关于parallel residual和non-parallel residual的解释可以参考这个图:
bias控制Linear层的bias是否存在,现在大多模型一般都是false。norm_class_name是RMSNorm,mlp_class_name是LLaMAMLP,具体可以参见litgpt里model.py中的实现。intermediate_size是768,这个是上面的MLP中间层的大小。
按照上面的配置得到的模型参数量在44M左右,也就是只有0.044B的大小。
但根据微软的TinyStories论文结论,10-80M级别的模型能在小故事生成这种简单的语言任务上达到不错的效果(依旧能说人话)。
其他参数
其余的都是一些训练的参数,比如batch_size,lr,weight_decay等等,这些都是比较常见的参数,不再赘述。
logger我这里选择的是wandb,可以直接在wandb上查看训练过程中的一些指标。
data设置成之前预处理好的数据集的路径(其中指定了加载数据所用的litdata的类名)
tokenizer_dir是选用的或者自己训练好的tokenizer的路径。
启动训练
litgpt pretrain --config Experiments/configs/microstories.yaml
预训练启动的命令非常简单,只需要指定上面的配置文件的路径即可。
不出意外地话模型就能开始训练了,可以在wandb上查看训练过程中的指标。
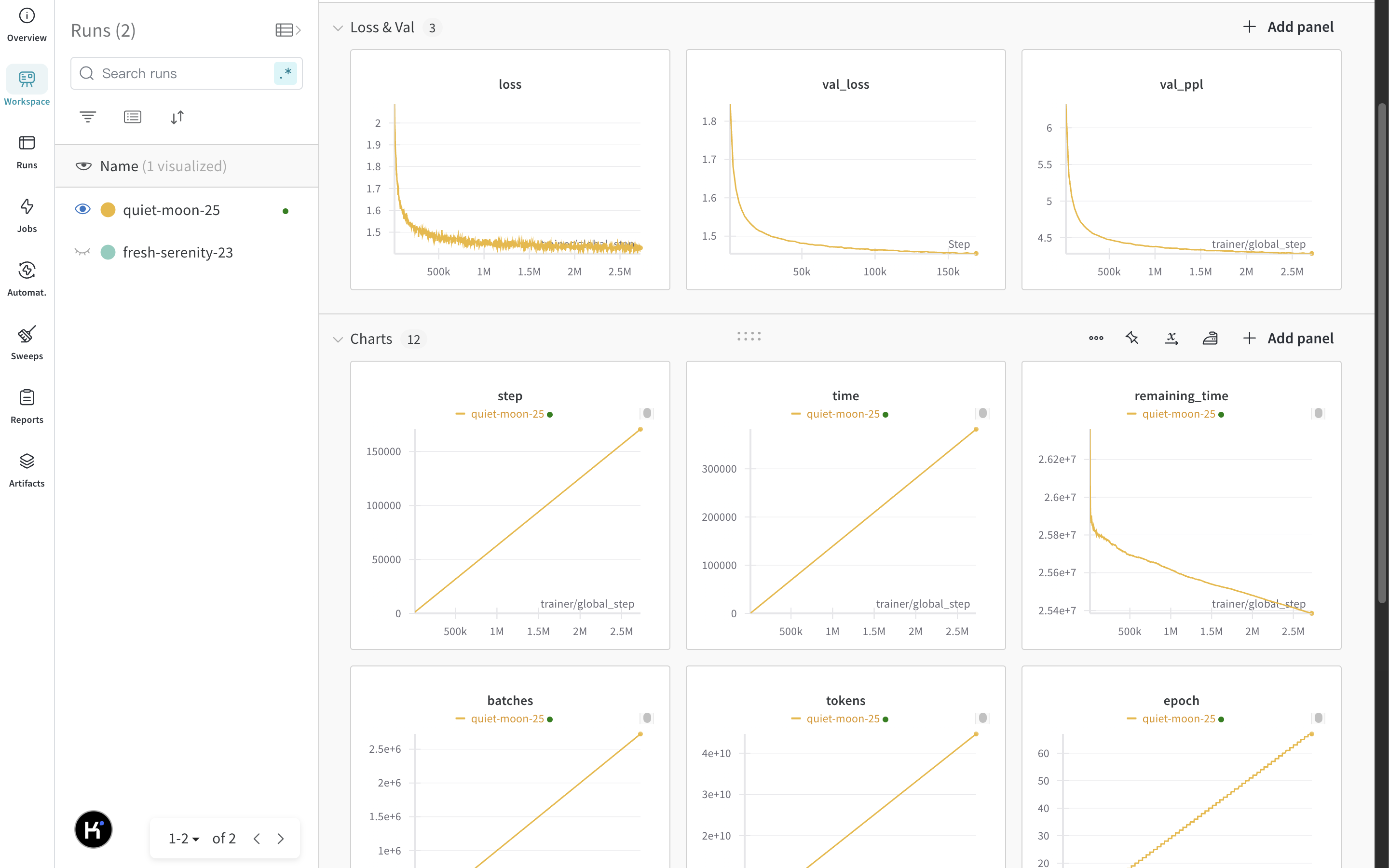
我的模型其实已经训练了一段时间,show一下训练过程中的图表:
小结
- 详细介绍了
litgpt的预训练模型配置文件。 - 顺带解释了一些重要参数的原理。
- 训练启动。
走之前点个赞和关注吧,你的支持是我坚持更新的动力!
我们下期见!
这篇关于从零手搓中文大模型|Day04|模型参数和训练启动|我的micro大模型预训练成功跑起来啦的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






