本文主要是介绍OpenCSG全网首发!Phi-3.5 Mini Instruct全参微调中文版,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前沿科技速递🚀
🎉 震撼发布!OpenCSG正式推出全参数微调的Phi-3.5-mini-instruct中文版模型!
🔍 本次发布的Phi-3.5-mini-instruct中文版模型基于最新的Phi-3.5架构,经过全参数微调,专为中文场景优化而设计。我们采用了先进的训练技术和大规模数据集,确保模型在中文自然语言处理任务中的卓越表现。训练过程使用了多台NVIDIA A800显卡,显存管理精确高效,使得大规模语料训练更加稳定顺畅。数据集涵盖了新闻、社交媒体、技术文档等多种领域,确保模型在多样化的语境中都能生成流畅、自然且精准的文本。
⚡ 在推理阶段,Phi-3.5-mini-instruct中文版展现了强大的理解和生成能力。无论是对话生成、文本分类,还是机器翻译,模型都表现出色,且在中文环境下的表现尤为突出。
📥 部署该模型极为便捷,OpenCSG开源社区已开放下载链接,供开发者和研究人员自由使用。通过以下链接,您可以立即下载Phi-3.5-mini-instruct中文版模型,体验中文AI带来的全新智能互动。
来源:传神社区
01 模型介绍🦙
Phi-3.5-mini-instruct是Phi-3模型家族的最新成员,专为高效、先进的自然语言处理任务而设计。该模型以Phi-3的数据集为基础,包含合成数据和经过严格筛选的公开网站数据,着重于高质量、推理密集的内容。Phi-3.5-mini-instruct模型支持128K的token上下文长度,并经过了监督微调、近端策略优化(PPO)和直接偏好优化(DPO),确保了指令执行的精确性和模型的安全性。
为了更好地适应中文场景,我们对Phi-3.5-mini-instruct模型进行了全参数微调,推出了中文版。这一版本基于大量中文语料,进行了深度优化,以提升模型在中文自然语言处理任务中的表现。经过微调的中文版在语义理解、上下文关联和文本生成的质量上均有显著提升,能够更好地满足中文用户在各种应用场景中的需求。
02 训练细节🔍
在训练过程中,我们使用了一台NVIDIA A800显卡。下图展示了A800显卡在训练过程中的显存使用情况:
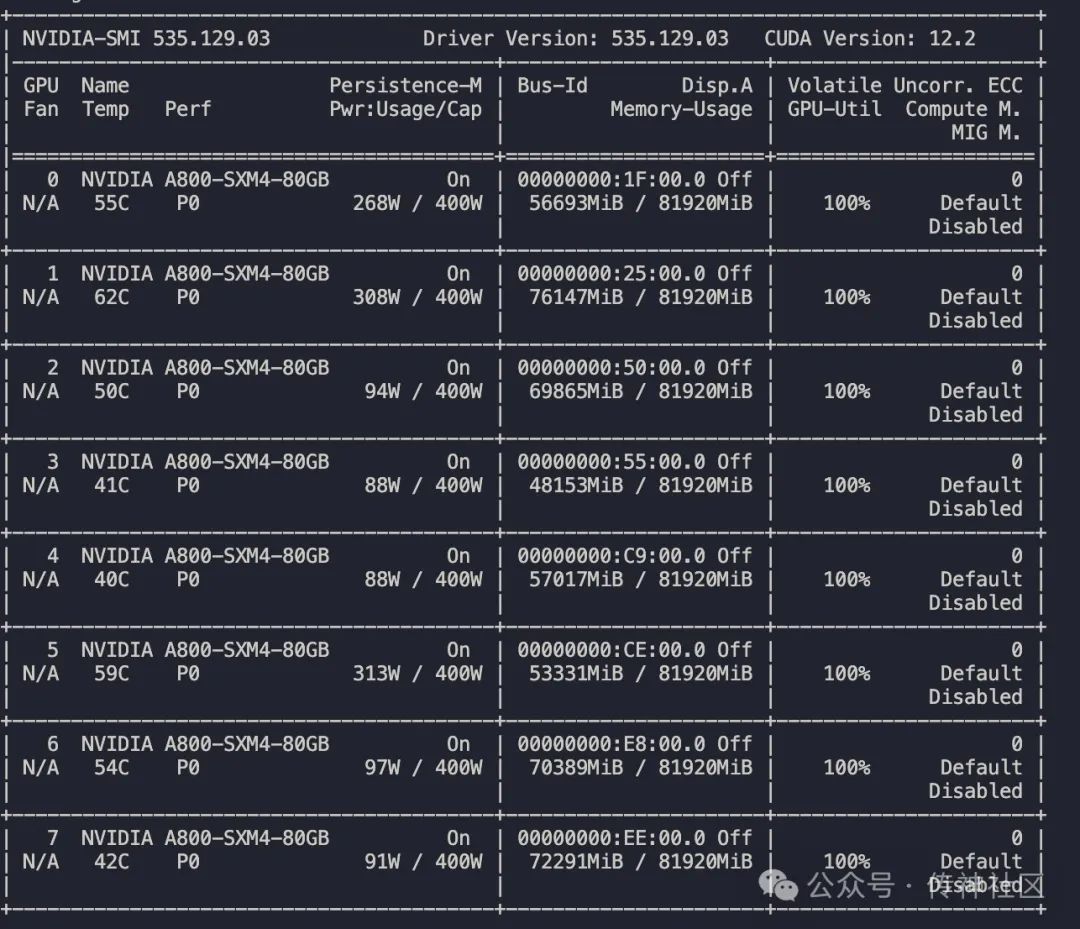
通过图示可以看出,单台A800显卡在训练过程中显存使用稳定,高效的显存管理和优化技术保障了训练过程的顺利进行。此外,模型训练采用了大规模高质量的中文语料,包括新闻、百科、社交媒体等多种来源,确保模型在各类文本场景中的适用性。
03 推理效果 ⚡
为了评估Phi-3.5-mini-instruct模型在中文语境下的表现,我们对微调后的中文版和未经过微调的原始版本进行了详细对比。以下是两者在推理过程中生成的对话示例:


左图:Phi-3.5-mini-instruct中文微调版 右图:Phi-3.5-mini-instruct
在中文对话生成中,Phi-3.5-mini-instruct中文版展现出卓越的表现。生成的文本不仅流畅自然,而且对语义的理解非常精准。无论是处理复杂的上下文关联,还是应对语义上的细微差异,中文版模型都表现出了极高的适应性。尤其是在涉及中文特有的文化背景、习惯用语和成语等内容时,模型的生成结果显得非常贴切和准确,能够很好地理解用户的意图并给出合理的回应。这使得该模型在中文对话生成、文本摘要、情感分析等任务中表现出色。
相比之下,原始版本虽然具备较好的通用性和高质量的文本生成能力,但在中文处理上略显不足。由于该版本未经过针对中文语料的微调,模型在理解和生成与中文相关的细微语义时,偶尔会出现理解偏差或生成的文本不够自然的情况。尤其是在面对涉及复杂语境、长句子结构或文化特定表达的场景时,原始版本的响应会显得略微生硬,无法完全达到中文用户的期望。
通过对比,我们可以清楚地看到,经过中文微调的Phi-3.5-mini-instruct模型在中文自然语言处理任务中表现显著优于原始版本。这不仅验证了微调过程的有效性,也充分展示了模型在中文语境下的适应能力和强大的生成性能。对于需要精准处理中文内容的应用场景,Phi-3.5-mini-instruct中文版无疑是更为理想的选择。
04 模型下载 📥
通过本次微调,Phi-3.5 Mini Instruct模型在中文自然语言处理任务中的表现得到了显著提升。我们欢迎各位开发者和研究人员下载并试用该模型,并期待您的反馈与建议。如果您对我们的工作感兴趣,欢迎加入OpenCSG社区,与我们一起探索中文AI的未来。
模型地址:https://opencsg.com/models/OpenCSG/Phi-3.5-Chinese
点击阅读原文即可跳转~
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区

这篇关于OpenCSG全网首发!Phi-3.5 Mini Instruct全参微调中文版的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!