本文主要是介绍MySQL系列:innodb源码分析之重做日志结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在innodb的引擎实现中,为了实现事务的持久性,构建了重做日志系统。重做日志由两部分组成:内存日志缓冲区(redo log buffer)和重做日志文件。这样设计的目的显而易见,日志缓冲区是为了加快写日志的速度,而重做日志文件为日志数据提供持久化的作用。在innodb的重做日志系统中,为了更好实现日志的易恢复性、安全性和持久化性,引入了以下几个概念:LSN、log block、日志文件组、checkpoint和归档日志。以下我们分别一一来进行分析。
1.LSN
在innodb中的重做日志系统中,定义一个LSN序号,其代表的意思是日志序号。LSN在引擎中定义的是一个dulint_t类型值,相当于uint64_t,关于dulint_t的定义如下:
typedef struct dulint_struct
{ulint high; /* most significant 32 bits */ulint low; /* least significant 32 bits */
}dulint_t;
void log_write_low(byte* str, ulint str_len)
{log_t* log = log_sys;
. . .
part_loop:/*计算part length*/data_len = log->buf_free % OS_FILE_LOG_BLOCK_SIZE + str_len;
. . . /*将日志内容拷贝到log buffer*/ut_memcpy(log->buf + log->buf_free, str, len);str_len -= len;str = str + len;. . .if(data_len = OS_FILE_LOG_BLOCK_SIZE - LOG_BLOCK_TRL_SIZE){ /*完成一个block的写入*/
. . .len += LOG_BLOCK_HDR_SIZE + LOG_BLOCK_TRL_SIZE;log->lsn = ut_dulint_add(log->lsn, len);. . .}else /*更改lsn*/log->lsn = ut_dulint_add(log->lsn, len);. . .
}
LSN是不会减小的,它是日志位置的唯一标记。在重做日志写入、checkpoint构建和PAGE头里面都有LSN。
关于日志写入:
例如当前重做日志的LSN = 2048,这时候innodb调用log_write_low写入一个长度为700的日志,2048刚好是4个block长度,那么需要存储700长度的日志,需要量个BLOCK(单个block只能存496个字节)。那么很容易得出新的LSN = 2048 + 700 + 2 * LOG_BLOCK_HDR_SIZE(12) + LOG_BLOCK_TRL_SIZE(4) = 2776。
关于checkpoint和日志恢复:
在page的fil_header中的LSN是表示最后刷新是的LSN, 假如数据库中存在PAGE1 LSN = 1024,PAGE2 LSN = 2048, 系统重启时,检测到最后的checkpoint LSN = 1024,那么系统在检测到PAGE1不会对PAGE1进行恢复重做,当系统检测到PAGE2的时候,会将PAGE2进行重做。一次类推,小于checkpoint LSN的页不用重做,大于LSN checkpoint的PAGE就要进行重做。
2.Log Block
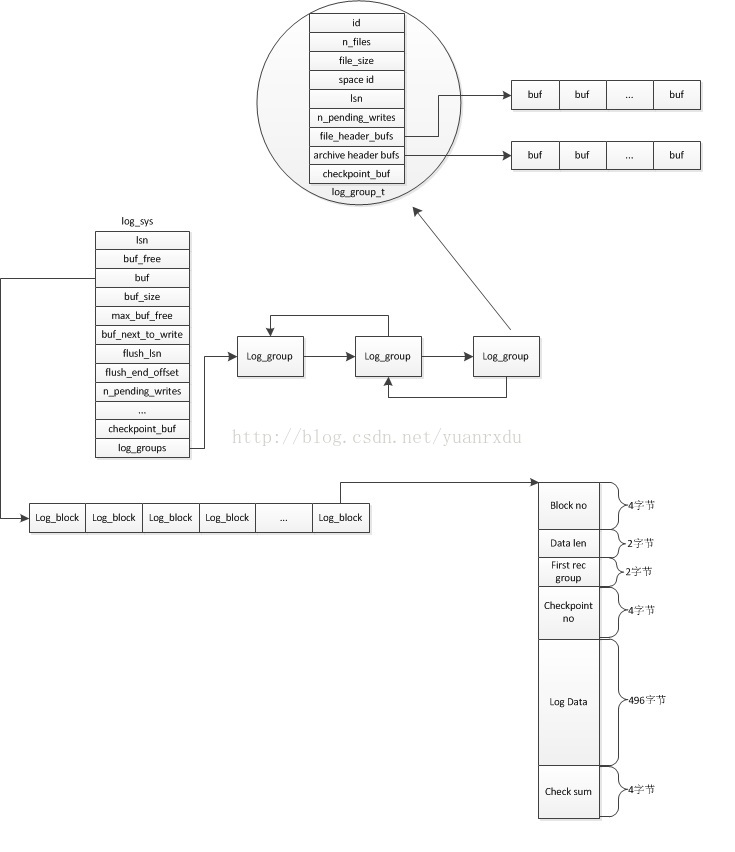
innodb在日志系统里面定义了log block的概念,其实log block就是一个512字节的数据块,这个数据块包括块头、日志信息和块的checksum.其结构如下: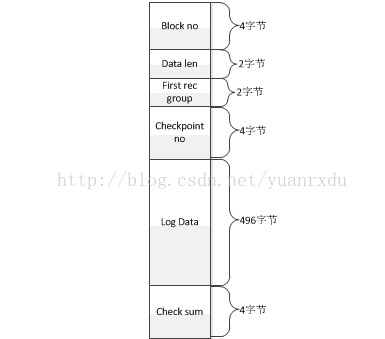
Block no的最高位是描述block是否flush磁盘的标识位.通过lsn可以blockno,具体的计算过程是lsn是多少个512的整数倍,也就是no = lsn / 512 + 1;为什么要加1呢,因为所处no的块算成clac_lsn一定会小于传入的lsn.所以要+1。其实就是block的数组索引值。checksum是通过从块头开始到块的末尾前4个字节为止,做了一次数字叠加,代码如下:
sum = 1;sh = 0;for(i = 0; i < OS_FILE_LOG_BLOCK_SIZE - LOG_BLOCK_TRL_SIZE, i ++){sum = sum & 0x7FFFFFFF;sum += (((ulint)(*(block + i))) << sh) + (ulint)(*(block + i));sh ++;if(sh > 24) sh = 0;}
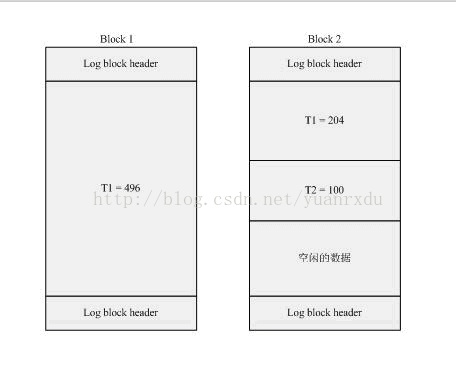
3.重做日志结构和关系图
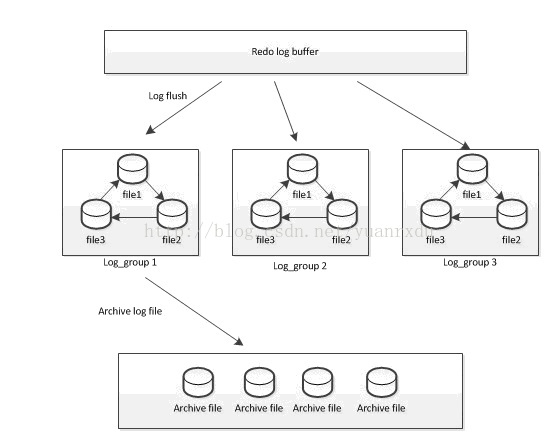
innodb在重做日志实现当中,设计了3个层模块,即redo log buffer、group files和archive files。这三个层模块的描述如下:
redo log buffer 重做日志的日志内存缓冲区,新写入的日志都是先写入到这个地方.redo log buffer中数据同步到磁盘上,必须进行刷盘操作。
group files 重做日志文件组,一般由3个同样大小的文件组成。3个文件的写入是依次循环的,每个日志文件写满后,即写下一个,日志文件如果都写满时,会覆盖第一次重新写。重做日志组在innodb的设计上支持多个。
archive files 归档日志文件,是对重做日志文件做增量备份,它是不会覆盖以前的日志信息。
以下是它们关系示意图:
3.1重做日志组
重做日志组可以支持多个,这样做的目的应该是为了防止一个日志组损坏后,可以从其他并行的日志组里面进行数据恢复。在MySQL-5.6的将日志组的个数设置为1,不允许多个group存在。网易姜承尧的解释是innodb的作者认为通过外层存储硬件来保证日志组的完整性比较好,例如raid磁盘。重做日志组的主要功能是实现对组内文件的写入管理、组内的checkpoint建立和checkpiont信息的保存、归档日志状态管理(只有第一个group才做archive操作).以下是对日志组的定义:
typedef struct log_group_struct
{ulint id; /*log group id*/ulint n_files; /*group包含的日志文件个数*/ulint file_size; /*日志文件大小,包括文件头*/ulint space_id; /*group对应的fil_space的id*/ulint state; /*log group状态,LOG_GROUP_OK、LOG_GROUP_CORRUPTED*/dulint lsn; /*log group的lsn*/dulint lsn_offset; /*当前lsn相对组内文件起始位置的偏移量 */ulint n_pending_writes; /*本group 正在执行fil_flush的个数*/byte** file_header_bufs; /*文件头缓冲区*/byte** archive_file_header_bufs;/*归档文件头信息的缓冲区*/ulint archive_space_id; /*归档重做日志ID*/ulint archived_file_no; /*归档的日志文件编号*/ulint archived_offset; /*已经完成归档的偏移量*/ulint next_archived_file_no; /*下一个归档的文件编号*/ulint next_archived_offset; /*下一个归档的偏移量*/dulint scanned_lsn;byte* checkpoint_buf; /*本log group保存checkpoint信息的缓冲区*/UT_LIST_NODE_T(log_group_t) log_groups;
}log_group_t;
上面结构定义中的spaceid是对应fil0fil中的fil_space_t结构,一个fil_space_t结构可以管理多个文件fil_node_t,关于fil_node_t参见这里。
3.1.1LSN与组内偏移
在log_goup_t组内日志模块当中,其中比较重要的是关于LSN与组内偏移之间的换算关系。在组创建时,会对lsn和对应lsn_offset做设置,假如 初始化为 group lsn = 1024, group lsn_offset = 2048,group由3个10240大小的文件组成,LOG_FILE_HDR_SIZE = 2048, 我们需要知道buf lsn = 11240对应的组内offset的偏移是多少,根据log_group_calc_lsn_offset函数可以得出如下公式:group_size = 3 * 11240;
相对组起始位置的LSN偏移 = (buf_ls - group_ls) + log_group_calc_size_offset(lsn_offset ) = (11240 - 1024) - 0 = 10216;
lsn_offset = log_group_calc_lsn_offset(相对组起始位置的LSN偏移 % group_size) = 10216 + 2 * LOG_FILE_HDR_SIZE = 14312;
这个偏移一定是加上了文件头长度的。
3.1.2 file_header_bufs
file_header_bufs是一个buffer缓冲区数组,数组长度和组内文件数是一致的,每个buf长度是2048。其信息结构如下:
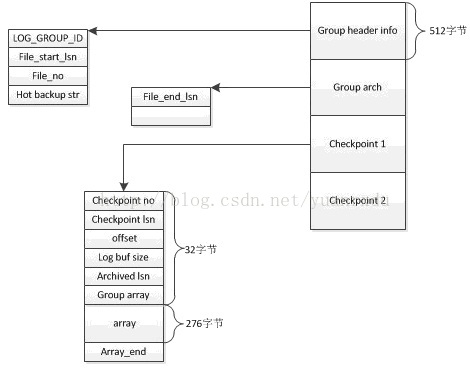
log_group_id 对应log_group_t结构中的id
file_start_lsn 当前文件其实位置数据对应的LSN值
File_no 当前的文件编号,一般在archive file头中体现
Hot backup str 一个空字符串,如果是hot_backup,会填上文件后缀ibackup。
File_end_ls 文件结尾数据对应的LSN值,一般在archive file文件中体现。
3.2 checkpoint
checkpoint是日志的检查点,其作用就是在数据库异常后,redo log是从这个点的信息获取到LSN,并对检查点以后的日志和PAGE做重做恢复。那么检查点是怎么生成的呢?当日志缓冲区写入的日志LSN距离上一次生成检查点的LSN达到一定差距的时候,就会开始创建检查点,创建检查点首先会将内存中的表的脏数据写入到硬盘,让后再将redo log buffer中小于本次检查点的LSN的日志也写入硬盘。在log_group_t中的checkpoint_buf,以下是它对应字段的解释:
LOG_CHECKPOINT_NO checkpoint序号,
LOG_CHECKPOINT_LSN 本次checkpoint起始的LSN
LOG_CHECKPOINT_OFFSET 本次checkpoint相对group file的起始偏移量
LOG_CHECKPOINT_LOG_BUF_SIZE redo log buffer的大小,默认2M
LOG_CHECKPOINT_ARCHIVED_LSN 当前日志归档的LSN
LOG_CHECKPOINT_GROUP_ARRAY 每个log group归档时的文件序号和偏移量,是一个数组
3.3 log_t
重做日志的写入、数据刷盘、建立checkpoint和归档操作都是通过全局唯一的,log_sys进行控制的,这是个非常庞大而又复杂的结构,定义如下:
typedef struct log_struct
{byte pad[64]; /*使得log_struct对象可以放在通用的cache line中的数据,这个和CPU L1 Cache和数据竞争有和
直接关系*/dulint lsn; /*log的序列号,实际上是一个日志文件偏移量*/ulint buf_free; /*buf可以写的位置*/mutex_t mutex; /*log保护的mutex*/byte* buf; /*log缓冲区*/ulint buf_size; /*log缓冲区长度*/ulint max_buf_free; /*在log buffer刷盘后,推荐buf_free的最大值,超过这个值会被强制刷盘*/ulint old_buf_free; /*上次写时buf_free的值,用于调试*/dulint old_lsn; /*上次写时的lsn,用于调试*/ibool check_flush_or_checkpoint; /*需要日志写盘或者是需要刷新一个log checkpoint的标识*/ulint buf_next_to_write; /*下一次开始写入磁盘的buf偏移位置*/dulint written_to_some_lsn; /*第一个group刷完成是的lsn*/dulint written_to_all_lsn; /*已经记录在日志文件中的lsn*/dulint flush_lsn; /*flush的lsn*/ulint flush_end_offset; /*最后一次log file刷盘时的buf_free,也就是最后一次flush的末尾偏移量*/ulint n_pending_writes; /*正在调用fil_flush的个数*/os_event_t no_flush_event; /*所有fil_flush完成后才会触发这个信号,等待所有的goups刷盘完成*/ ibool one_flushed; /*一个log group被刷盘后这个值会设置成TRUE*/os_event_t one_flushed_event; /*只要有一个group flush完成就会触发这个信号*/ulint n_log_ios; /*log系统的io操作次数*/ulint n_log_ios_old; /*上一次统计时的io操作次数*/time_t last_printout_time;ulint max_modified_age_async; /*异步日志文件刷盘的阈值*/ulint max_modified_age_sync; /*同步日志文件刷盘的阈值*/ulint adm_checkpoint_interval;ulint max_checkpoint_age_async; /*异步建立checkpoint的阈值*/ulint max_checkpoint_age; /*强制建立checkpoint的阈值*/dulint next_checkpoint_no;dulint last_checkpoint_lsn;dulint next_checkpoint_lsn;ulint n_pending_checkpoint_writes;rw_lock_t checkpoint_lock; /*checkpoint的rw_lock_t,在checkpoint的时候,是独占这个latch*/byte* checkpoint_buf; /*checkpoint信息存储的buf*/ulint archiving_state;dulint archived_lsn;dulint max_archived_lsn_age_async;dulint max_archived_lsn_age;dulint next_archived_lsn;ulint archiving_phase;ulint n_pending_archive_ios;rw_lock_t archive_lock;ulint archive_buf_size;byte* archive_buf;os_event_t archiving_on;ibool online_backup_state; /*是否在backup*/dulint online_backup_lsn; /*backup时的lsn*/UT_LIST_BASE_NODE_T(log_group_t) log_groups;
}log_t;
3.3.1各种LSN之间的关系和分析
从上面的结构定义可以看出有很多LSN相关的定义,那么这些LSN直接的关系是怎么样的呢?理解这些LSN之间的关系对理解整个重做日志系统的运作机理会有极大的信心。以下各种LSN的解释:lsn 当前log系统最后写入日志时的LSN
flush_lsn redolog buffer最后一次数据刷盘数据末尾的LSN,作为下次刷盘的起始LSN
written_to_some_lsn 单个日志组最后一次日志刷盘时的起始LSN
written_to_all_lsn 所有日志组最后一次日志刷盘是的起始LSN
last_checkpoint_lsn 最后一次建立checkpoint日志数据起始的LSN
next_checkpoint_lsn 下一次建立checkpoint的日志 数据起始的LSN,用log_buf_pool_get_oldest_modification获得的
archived_lsn 最后一次归档日志数据起始的LSN
next_archived_lsn 下一次归档日志数据的其实LSN关系图如下:

3.3.2偏移量的分析
log_t有各种偏移量,例如:max_buf_free、buf_free、flush_end_offset、buf_next_to_write等。偏移和LSN不一样,偏移量是相对redo log buf其实位置的绝对偏移量,LSN是整个日志系统的序号。
max_buf_free 写入日志是不能超过的偏移位置,如果超过,将强制redo log buf写入磁盘
buf_free 当前日志可以写的偏移位置
buf_next_to_write 下一次redo log buf数据写盘的数据起始偏移,在所有刷盘IO完成后,其值和 flush_end_offset是一致的。
flush_end_offset 本次刷盘的数据末尾的偏移量,相当于刷盘时的buf_free,当flush_end_offset 超过max_buf_free的一半时会将未写入的数据移到 redobuffer的最前面,这时buf_free和buf_next_to_write都将做调整
大小关系图如下:
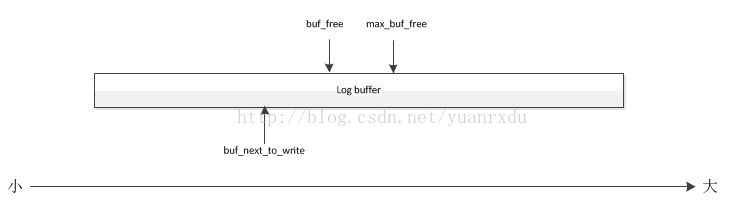
3.4内存结构关系图
4.日志写入和日志保护机制
innodb有四种日志刷盘行为,分别是异步redo log buffer刷盘、同步redo log buffer刷盘、异步建立checkpoint刷盘和同步建立checkpoint刷盘。在innodb中,刷盘行为是非常耗磁盘IO的,innodb对刷盘做了一套非常完善的策略。
4.1重做日志刷盘选项
在innodb引擎中有个全局变量srv_flush_log_at_trx_commit,这个全局变量是控制flushdisk的策略,也就是确定调不调用fsync这个函数,什么时候掉这个函数。这个变量有3个值。这三个值的解释如下:
0 每隔1秒由MasterThread控制重做日志模块调用log_flush_to_disk来刷盘,好处是提高了效率,坏处是1秒内如果数据库崩溃,日志和数据会丢失。
1 每次写入重做日志后,都调用fsync来进行日志写入磁盘。好处是每次日志都写入了磁盘,数据可靠性大大提高,坏处是每次调用fsync会产生大量的磁盘IO,影响数据库性能。
2 每次写入重做日志后,都将日志写入日志文件的page cache。这种情况如果物理机崩溃后,所有的日志都将丢失。
4.2日志刷盘保护
由于重做日志是一个组内多文件重复写的一个过程,那么意味日志如果不及时写盘和创建checkpoint,就有可能会产生日志覆盖,这是一个我们不愿意看到的。在innodb定义了一个日志保护机制,在存储引擎会定时调用log_check_margins日志函数来检查保护机制。简单介绍如下:
引入三个变量 buf_age、checkpoint_age和日志空间大小.
buf_age = lsn -oldest_lsn;
checkpoint_age =lsn - last_checkpoint_lsn;
日志空间大小 = 重做日志组能存储日志的字节数(通过log_group_get_capacity获得);
当buf_age >=日志空间大小的7/8时,重做日志系统会将red log buffer进行异步数据刷盘,这个时候因为是异步的,不会造成数据操作阻塞。
当buf_age >=日志空间大小的15/16时,重做日志系统会将redlog buffer进行同步数据刷盘,这个时候会调用fsync函数,数据库的操作会进行阻塞。
当 checkpoint_age >=日志空间大小的31/32时,日志系统将进行异步创建checkpoint,数据库的操作不会阻塞。
当 checkpoint_age == 日志空间大小时,日志系统将进行同步创建checkpoint,大量的表空间脏页和log文件脏页同步刷入磁盘,会产生大量的磁盘IO操作。数据库操作会堵塞。整个数据库事务会挂起。
5.总结
Innodb的重做日志系统是相当完备的,它为数据的持久化做了很多细微的考虑,它效率直接影响MySQL的写效率,所以我们深入理解了它便以我们去优化它,尤其是在大量数据刷盘的时候。假设数据库的受理的事务速度大于磁盘IO的刷入速度,一定会出现同步建立checkpoint操作,这样数据库是堵塞的,整个数据库都在都在进行脏页刷盘。避免这样的问题发生就是增加IO能力,用多磁盘分散IO压力。也可以考虑SSD这读写速度很高的存储介质来做优化。
这篇关于MySQL系列:innodb源码分析之重做日志结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








