本文主要是介绍BVS:多强联手,李飞飞也参与的超强仿真数据生成工具,再掀数据狂潮 | CVPR 2024,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BEHAVIOR Vision Suite(BVS)是一个新型工具包,旨在系统评估和全面理解计算机视觉模型。研究人员能够在场景、对象和相机级别控制各种参数,有助于创建高度定制的数据集。来源:晓飞的算法工程笔记 公众号
论文: BEHAVIOR Vision Suite: Customizable Dataset Generation via Simulation

- 论文地址:https://arxiv.org/abs/2405.09546
- 论文代码:https://behavior-vision-suite.github.io
Introduction
大规模数据集和基准在过去十年中推动了计算机视觉研究。在这些数据集和基准的驱动下,每年都有数千个模型和算法提出来解决不同的感知挑战,例如对象检测、分割、动作识别、视频理解等。尽管取得了成功,但真实世界数据集面临固有的局限性。首先,对象/像素级的GT标签要么成本高昂(例如,分割掩码),要么不准确(例如,深度感知),因此每个真实数据集通常都只有有限的标签,阻碍了使用同一输入执行各种感知任务的计算机视觉模型的发展和评价。即使在标注可行和准确的情况下,真实世界数据集也受到源图像可用性的限制。例如,从互联网或真实传感器中很难获得交通意外或低光条件的图像。最后,这些真实世界数据集一旦收集完成,就无法轻易改变数据分布。因此,研究人员很难进行定制实验,导致模型经常过拟合数据集,最终导致整个基准过时。
为了避免这一限制,研究人员和从业者想出了各种方法来生成合成数据集以补充真实数据。在室内场景理解领域,3D重建数据集提供了一个有前途的途径,可以从任意视点和自由(几何)注释生成源图像。然而,由于3D重建技术的不完美性,渲染出的图像并不是非常逼真。由于每个场景都是静态布局,这些数据集在相机轨迹之外提供的自定义能力非常有限。最近的合成室内数据集(通常由3D艺术家设计)不仅提供了自由的几何和语义注释,而且还支持对象布局的重新配置,因为对象通常是独立的CAD模型。然而,这些数据集不能保证物理上的合理性,因为对象的穿透和悬浮经常发生,并且除了更改对象姿态之外,并不能提供定制能力。另一方面,3D模拟器通过其基础物理引擎保证了物理上的合理性,允许用户自定义关节配置和更高级的对象状态,如“煮熟”或“切片”。然而,与之前提到的合成数据集相比,这些3D模拟器通常面向具体AI和机器人研究人员,因此它们缺乏照片般的逼真感(通常是由于速度限制),并且不提供生成计算机视觉研究人员定制图像/视频数据集的现成工具。
BVS旨在为计算机视觉研究人员提供一个强大而灵活的平台,以评估其模型在各种条件下的性能,并帮助他们了解模型的局限性。通过使用BVS,研究人员可以轻松生成大量数据集变体,而无需耗时耗力的数据收集和标注过程。这种能力允许系统地评估模型在连续参数上的性能,例如在不同光照条件下的对象检测,或不同相机设置下的场景理解。此外,BVS还可以帮助研究人员通过在模拟和真实世界之间建立可控的转移来评估模型。
总之,BEHAVIOR Vision Suite具有以下独特而理想的特点组合:
BVS提供图像/对象/像素级标签(场景图、点云、深度、分割等);BVS涵盖了各种室内场景和物体(8000多个物体,1000个场景实例,流体、软体等);BVS提供物理可信性和照片级真实感;BVS支持在对象模型、姿势、关节配置、语义状态、光照、纹理、材质、摄像机设置等方面的定制化;BVS包括易于使用的工具,用于生成新用例的定制数据。
为了展示BVS的实用性,论文展示了三个示例应用:
- 在不同条件下(例如光照和遮挡)参数化评估模型的鲁棒性;
- 在相同一组图像上评估不同类型的代表性计算机视觉模型;
- 为对象状态和关系预测进行
sim2real transfer的训练和评估。
BEHAVIOR Vision Suite
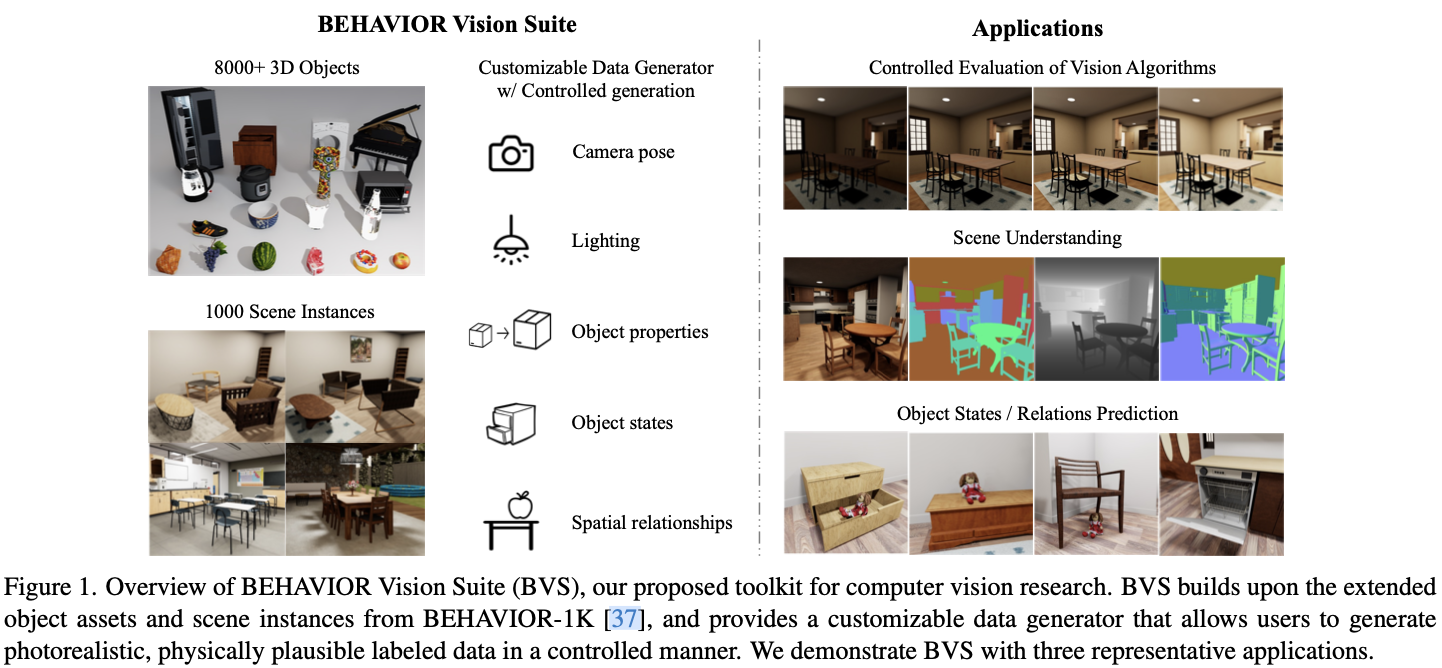
BEHAVIOR Vision Suite包含两个主要组件(图 1):扩展的BEHAVIOR-1K assets和可定制的数据集生成器。资产是基础,而生成器则利用这些资产创建视觉数据集,以满足下游任务的需要。
Extended BEHAVIOR-1K Assets
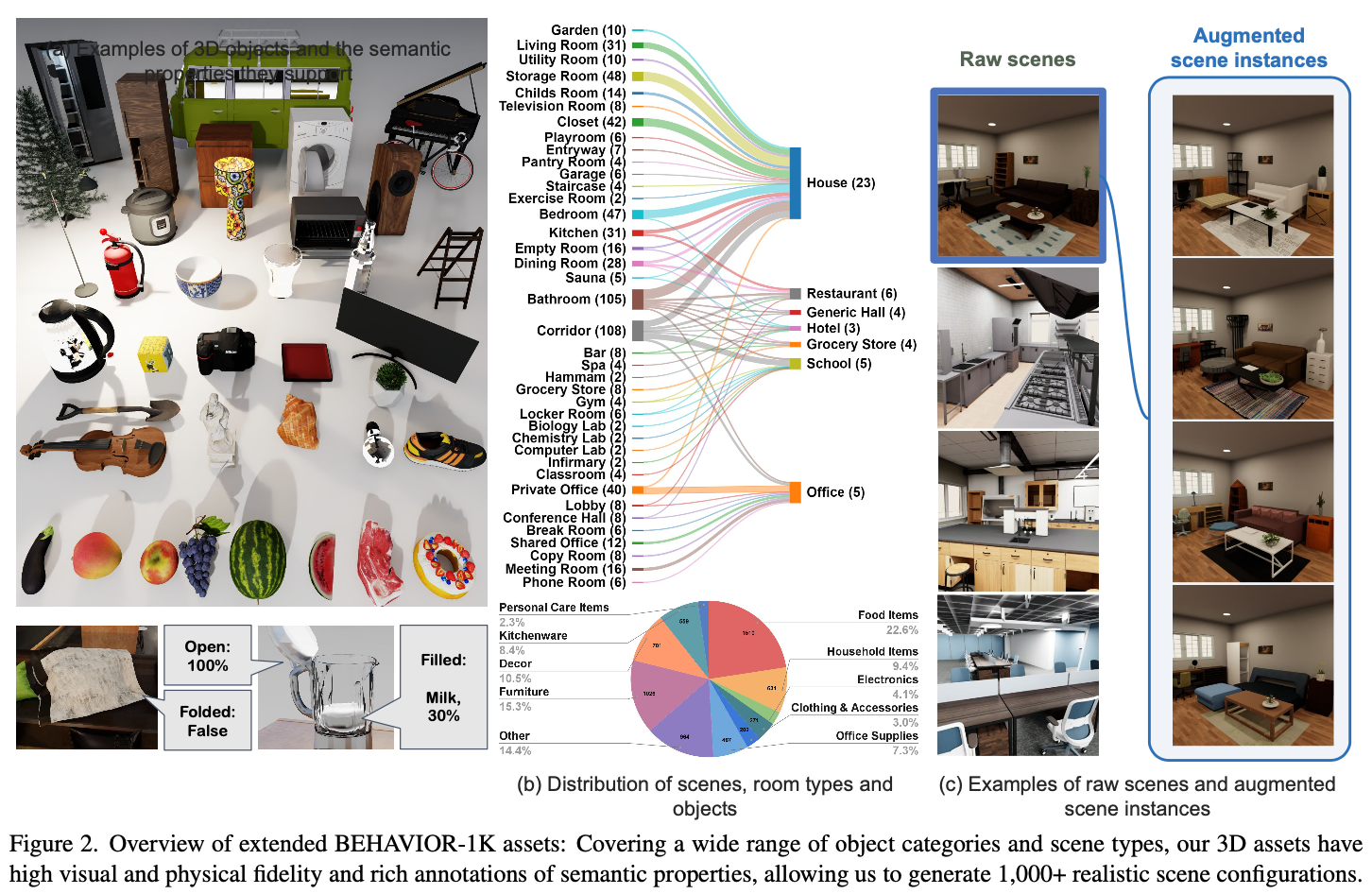
扩展后的BEHAVIOR-1K资产包括多样化的8,841个物体模型和1,000个场景实例,这些场景实例源自51个艺术家设计的场景。其中,2,156个物体模型是结构元素,如墙、地板和天花板,其余6,685个非结构化物品跨越1,937个类别,包括食物、工具、电子产品、服装和办公用品等。图2显示了这些类别的详细信息。这些场景主要是在室内,但也包括花园等室外元素,涵盖了多种环境:住宅(23个)、办公室(5个)、餐厅(6个)、超市(4个)、酒店(3个)、学校(5个)和通用礼堂(4个),以及论文研究实验室中的一个模拟公寓的虚拟副本。这些资产是作者一年的努力,为了增强其在计算机视觉中的适用性所取得的成果。
通过添加更多日常物品,将建筑结构分割为单独的物体以获得更精确的3D边界框标签,并自动生成切片食品,论文将物体集合从5,215扩展到8,841。此外,论文开发了通过改变家具物体模型和加入额外的日常物品生成多样化的场景变化的功能。后续,论文将会放出从51个原始场景增强而来的1000个场景实例。
为了提高物理真实感,使用V-HACD和CoACD来优化碰撞布局,并手动选择最佳参数以确保在物理精度、可用性保留和仿真效率之间取得平衡。对于超过2,000个物体,如果这种方法还不够,论文会手动设计它们的碰撞布局。
论文通过标注实际光源对象(如灯具和吊灯)来增强照明的真实感,以模仿真实世界的照明效果。为了获得更详细的语义属性,论文标注了适当的容器填充体积(例如杯子、锅)和液体来源/汇聚位置(例如水龙头、下水道、喷雾器),使得能够在场景中实现流体的实际生成。如果场景对象无法自由移动(例如它们在物理上支撑其他物体),论文对其进行了标注。杂乱的物体被明确标注,这使它们可以被替换为其它的杂乱物品。
总的来说,论文设计了这些资产来构造定制数据生成的强大基础,搭配功能化组织来允许准确的对象随机化,并且通过注释在对象和场景级别提供了大量可修改的参数。
Customizable Dataset Generator
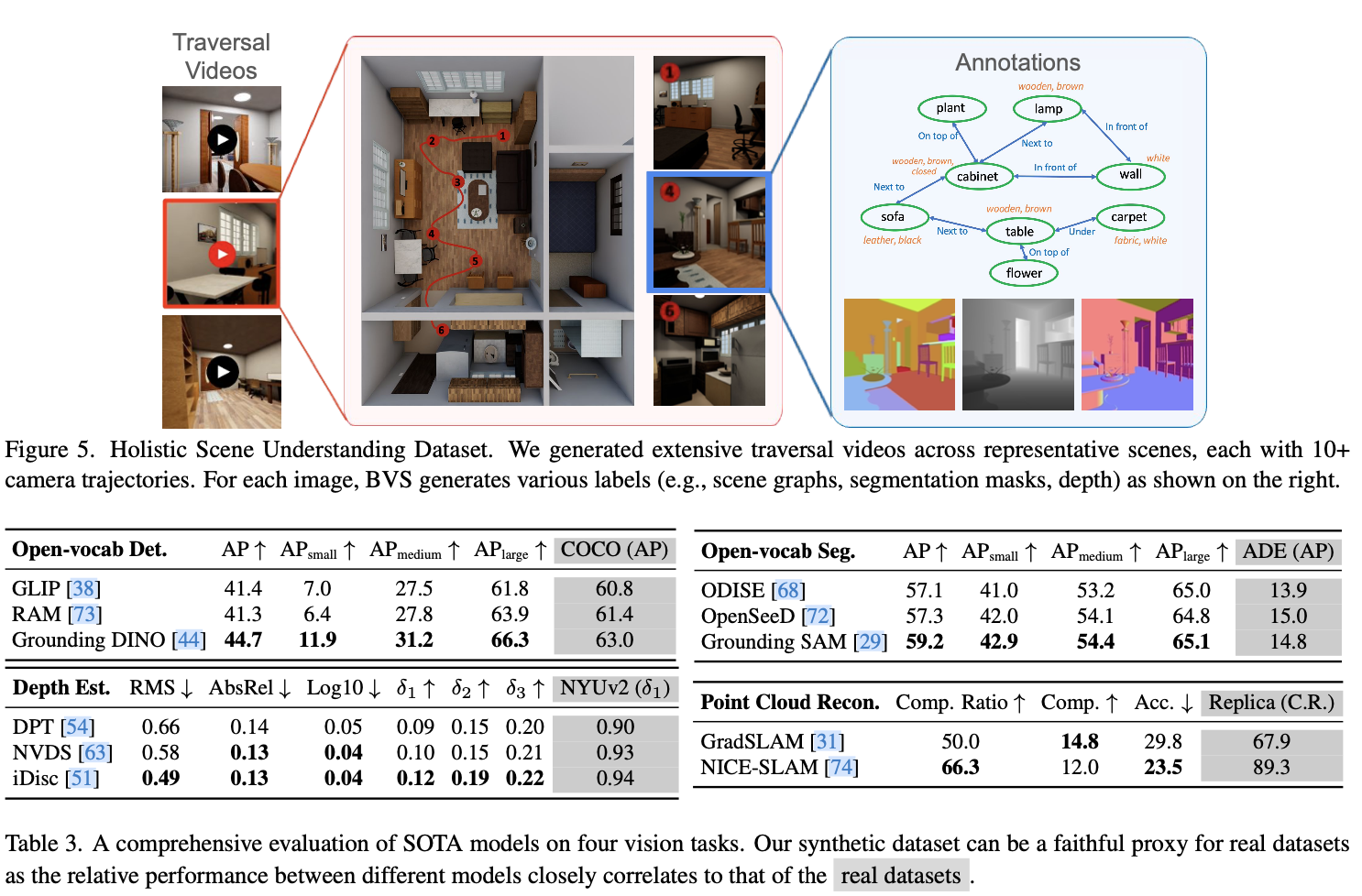
可定制的数据集生成器,即BEHAVIOR Vision Suite的软件组件,旨在生成符合特定规格要求的合成数据集。它基于OmniGibson,利用NVIDIA Omniverse的逼真实时渲染器和OmniGibson的过程化采样功能,生成满足任意要求的定制图像和视频。无需额外付费,即可生成的数据集包括丰富、全面的注释,比如分割掩膜、2D/3D边界框、深度、表面法线、流场和点云。关键是,它能赋予用户对数据集生成过程的广泛控制,在保证物理可信度的同时,指定场景布局、对象状态、摄像机角度和光照条件等要求。
- Capabilities
生成器具有以下功能:
- 场景对象随机化:可以用替代对象替换场景内视觉和功能相似的对象,这种随机化显著改变了场景的外观,同时保持了布局的语义完整性。
- 物理真实姿态生成:生成器可以按程序改变对象的物理状态,以满足某些条件,包括:
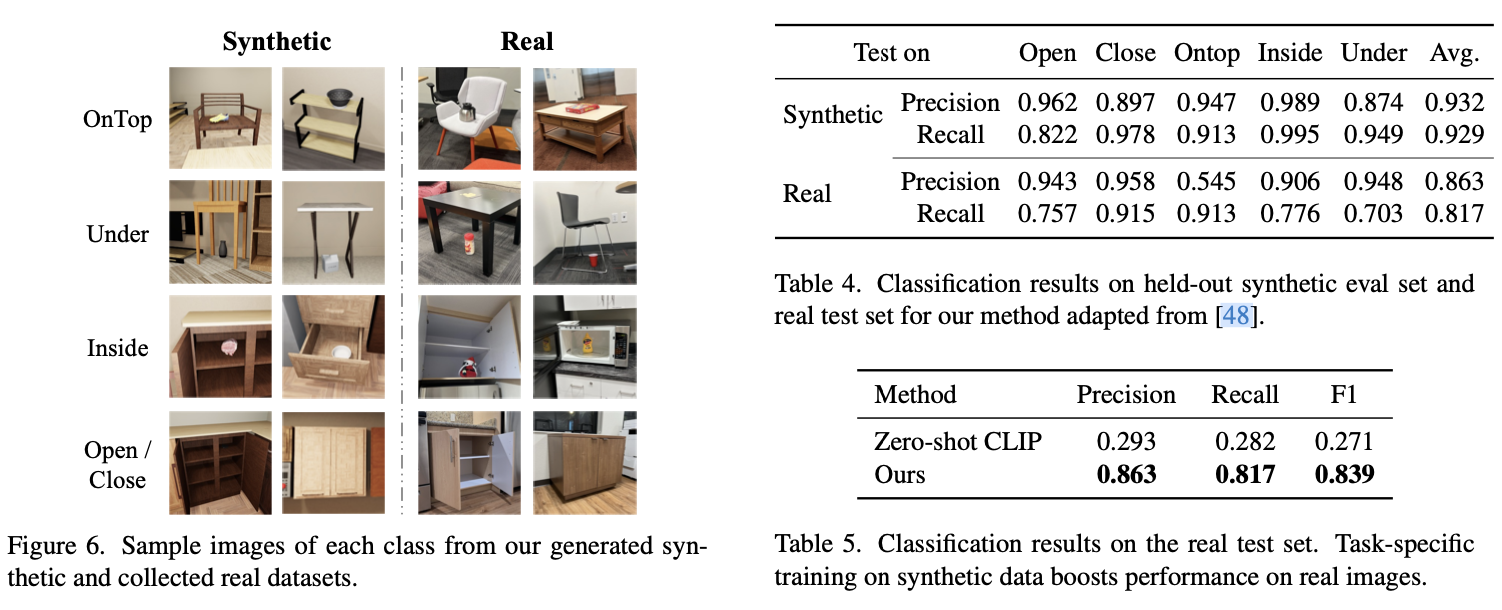
1)以某种方式将对象放置在场景中的其他对象上(例如,内部、顶部或底部),2)打开或关闭关节式对象,3)向容器中灌入流体,4)折叠或展开布料。生成器可以为相同的条件生成多个有效配置,并确保物理可信度。 - 丰富的谓语标注:除了通常的标签(语义和实例分割、边界框、表面法线、深度等),生成器还提供注释,包括对象的一元状态(例如,一个关节式对象是否打开或一个器具是否打开)、两个对象之间的二元谓语(例如,对象是否触碰、位于另一个对象的顶部或旁边)、对象与物质之间的二元谓语(例如,对象是否被物质填充/覆盖/浸透)以及连续标签(例如,关节式对象的开放程度、容器的填充比例)。
- 相机姿态和轨迹采样:在
3D场景中找到合适的相机姿态是渲染流程中具有挑战性且关重要的一步:相机不应该被遮挡,并且应该对准感兴趣的主体。生成器使用占据网格和手工启发式方法来生成既满足这些约束条件又符合静态相机姿态和合理行走轨迹的数据集,以生成图像或场景行走的视频数据。 - 可配置的渲染:通过用户友好的
API,生成器允许对渲染参数进行定制,包括光照和相机具体设置,例如光圈和视角。
- Dataset Generation
BVS数据集中的图像可以按以下步骤生成:
- 从用户配置的场景类别中选择
51个原始场景之一(比如一个办公室)。场景对象是使用同一类别的实例进行随机化的。 - 根据用户配置,确定要向场景中添加的附加对象。
- 使用基于用户指定要求的姿势生成能力来放置对象。这可能包括在特定区域制造混乱(例如,给冰箱装满易腐食品)或单独操纵对象状态(例如,打开柜子或用水覆盖桌子)以进行谓语预测。
- 生成相机姿态(或一系列姿态作为相机轨迹),以及根据用户的规格随机化场景的光照参数和相机的内参。
- 渲染图像(或一系列图像)并记录它与用户请求的所有相关标签一起,包括附加模态(深度/分割等)、边界框以及谓词和对象状态值。
Applications and Experiments
Parametric Model Evaluation
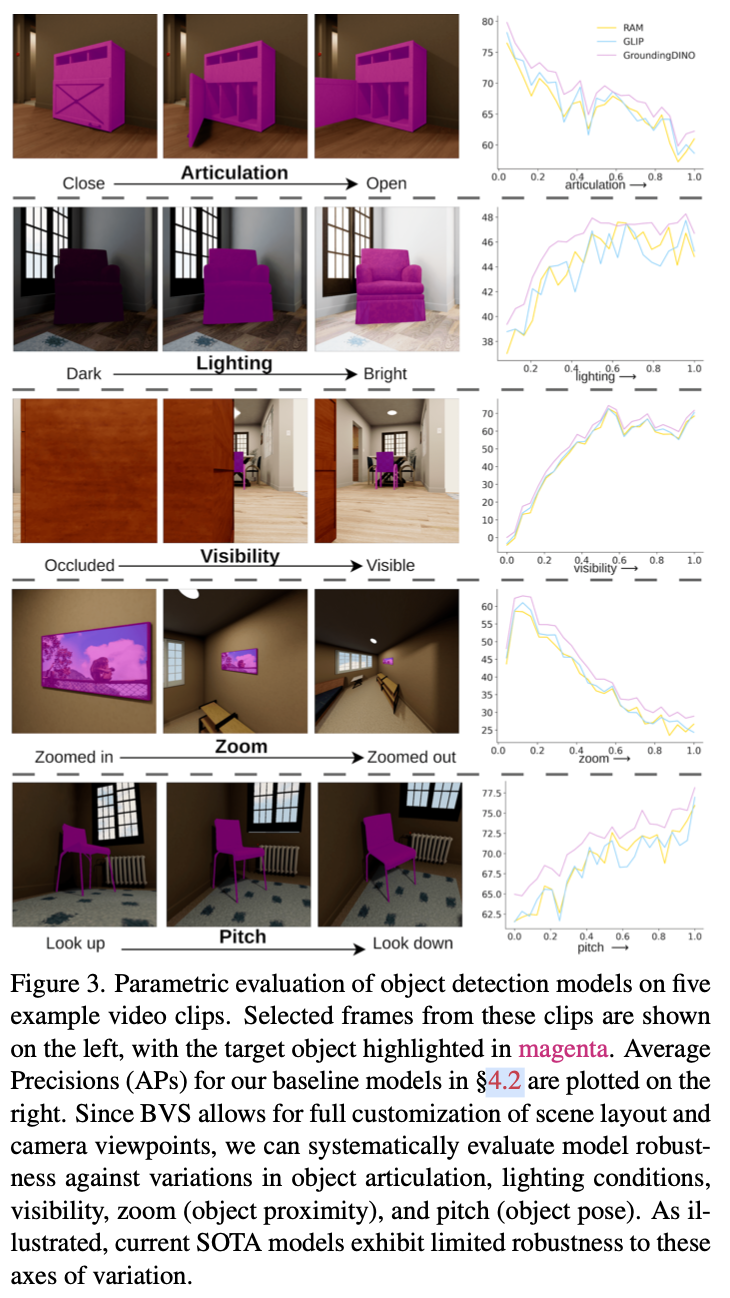
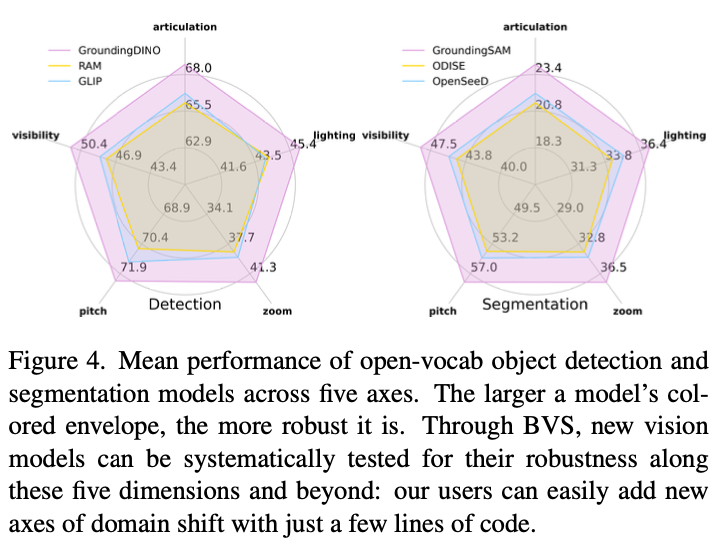
Holistic Scene Understanding
Object States and Relations Prediction
如果本文对你有帮助,麻烦点个赞或在看呗
更多内容请关注 微信公众号【晓飞的算法工程笔记】
这篇关于BVS:多强联手,李飞飞也参与的超强仿真数据生成工具,再掀数据狂潮 | CVPR 2024的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



