本文主要是介绍CS162 Operating System-lecture2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

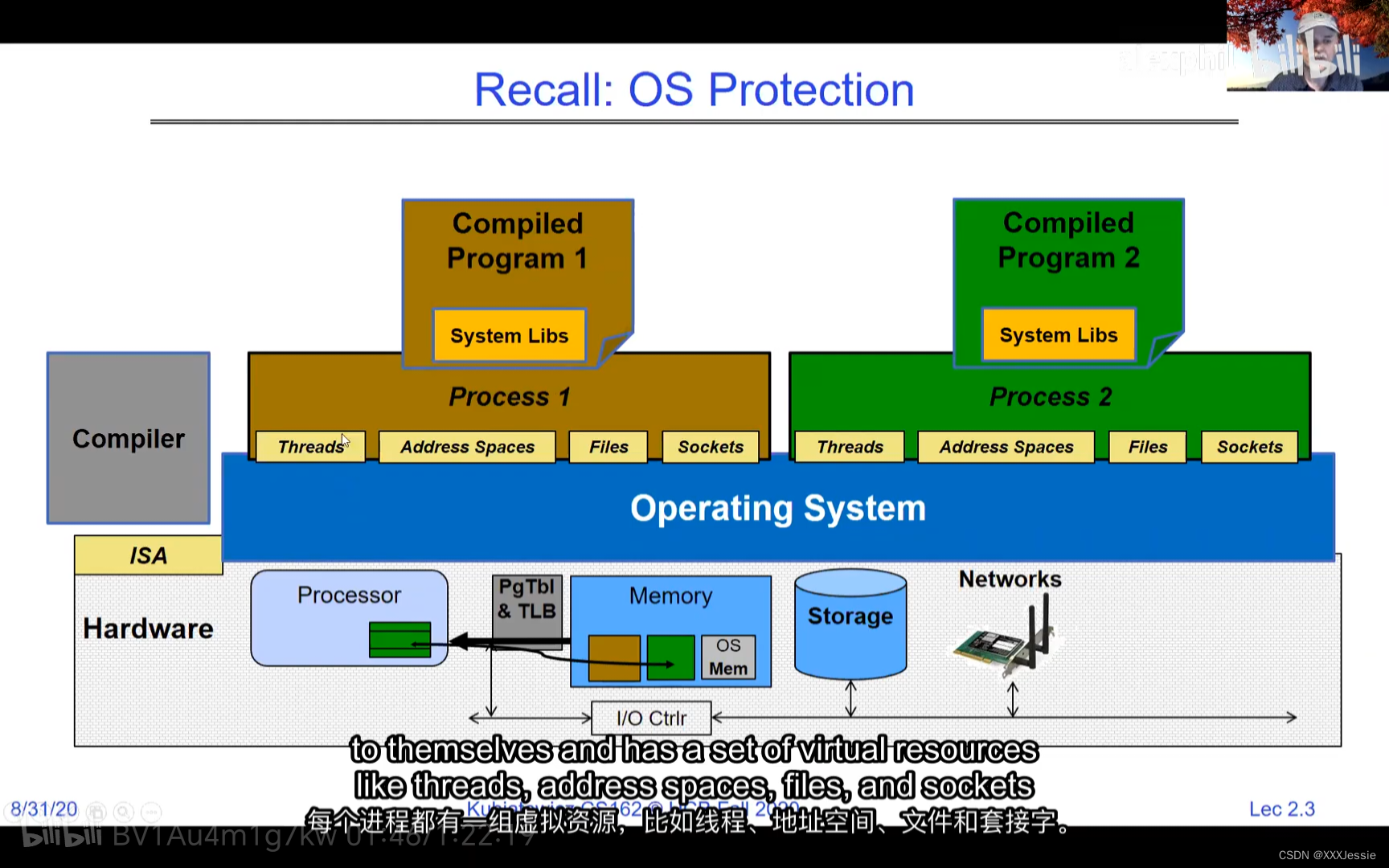
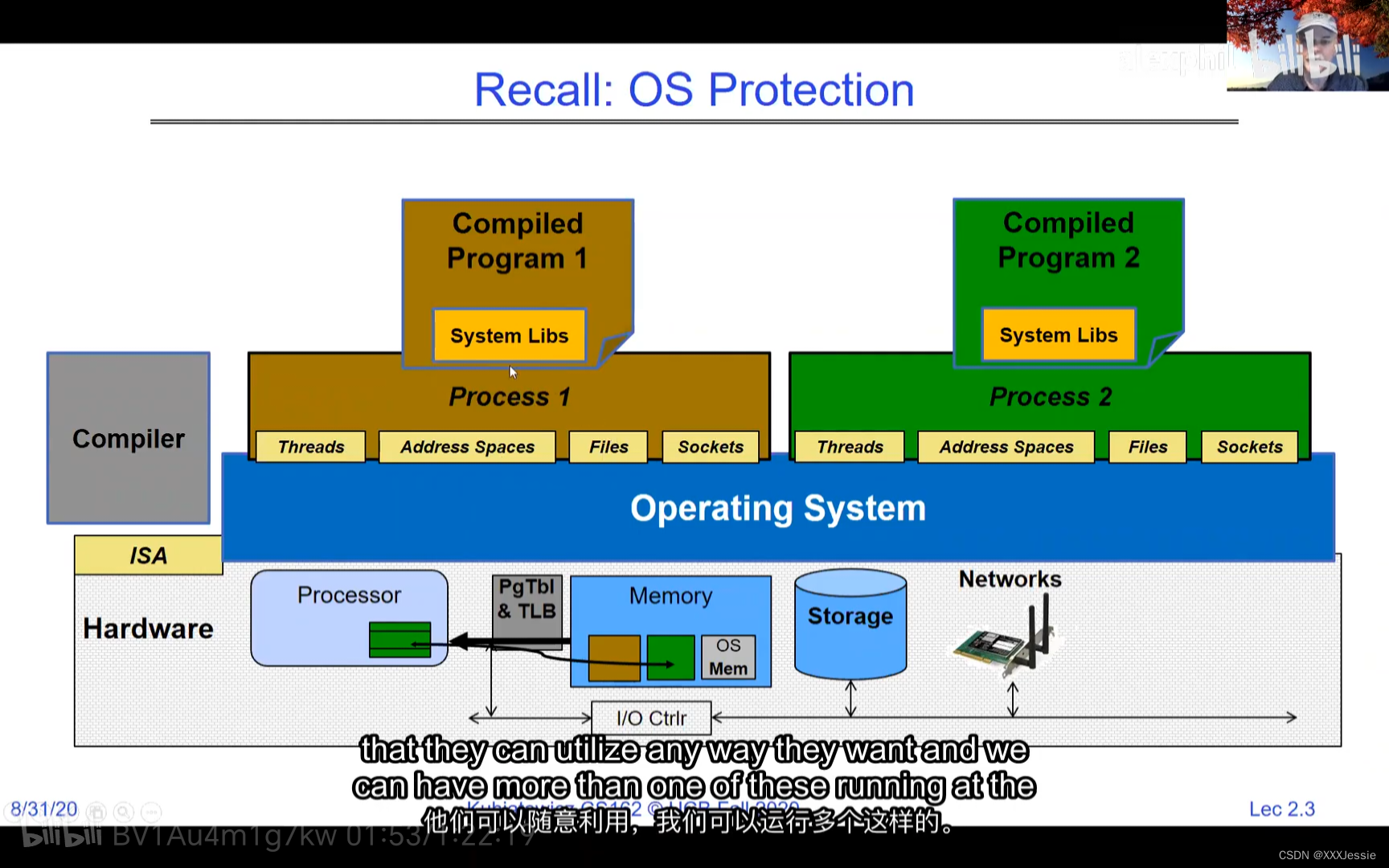





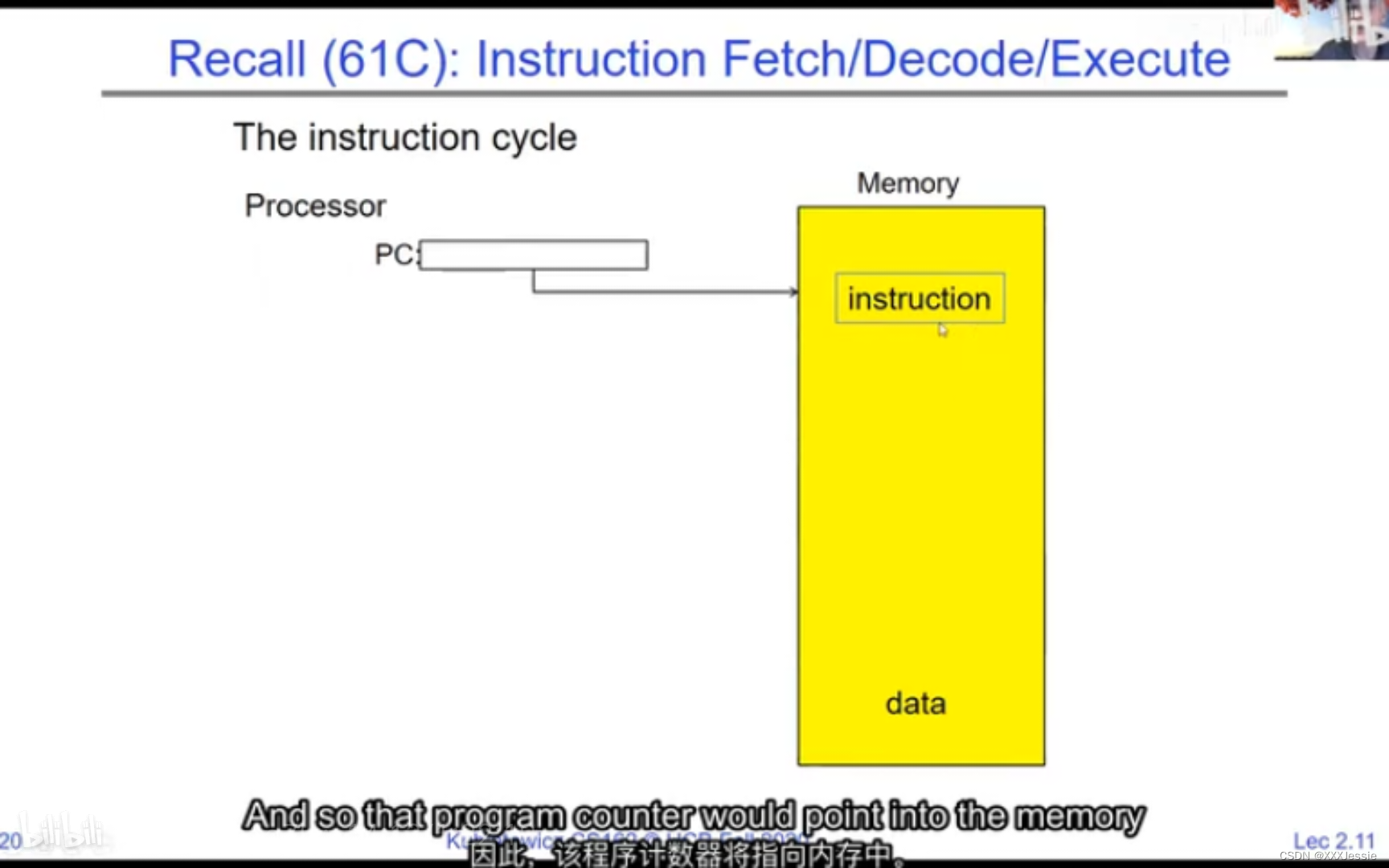
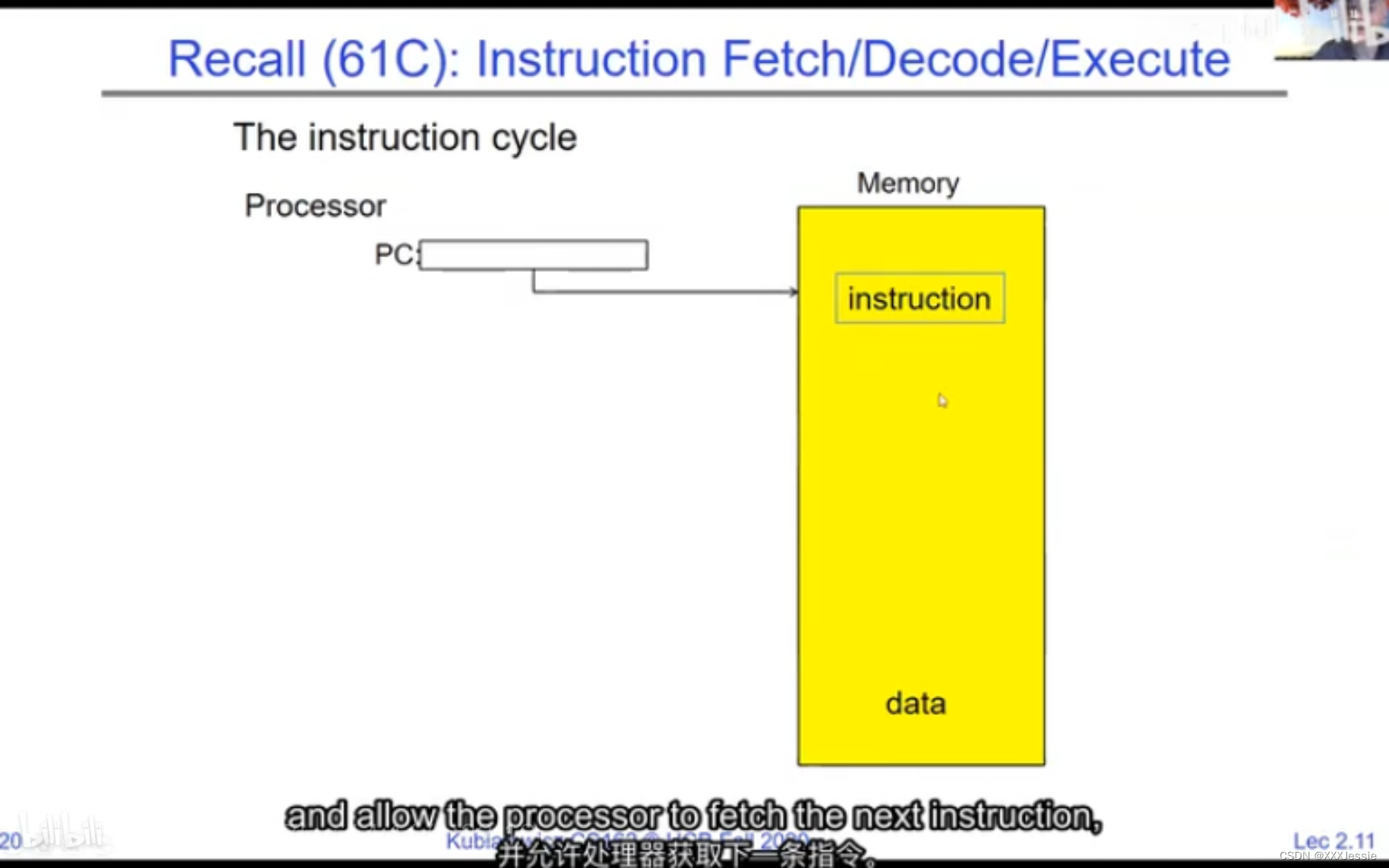
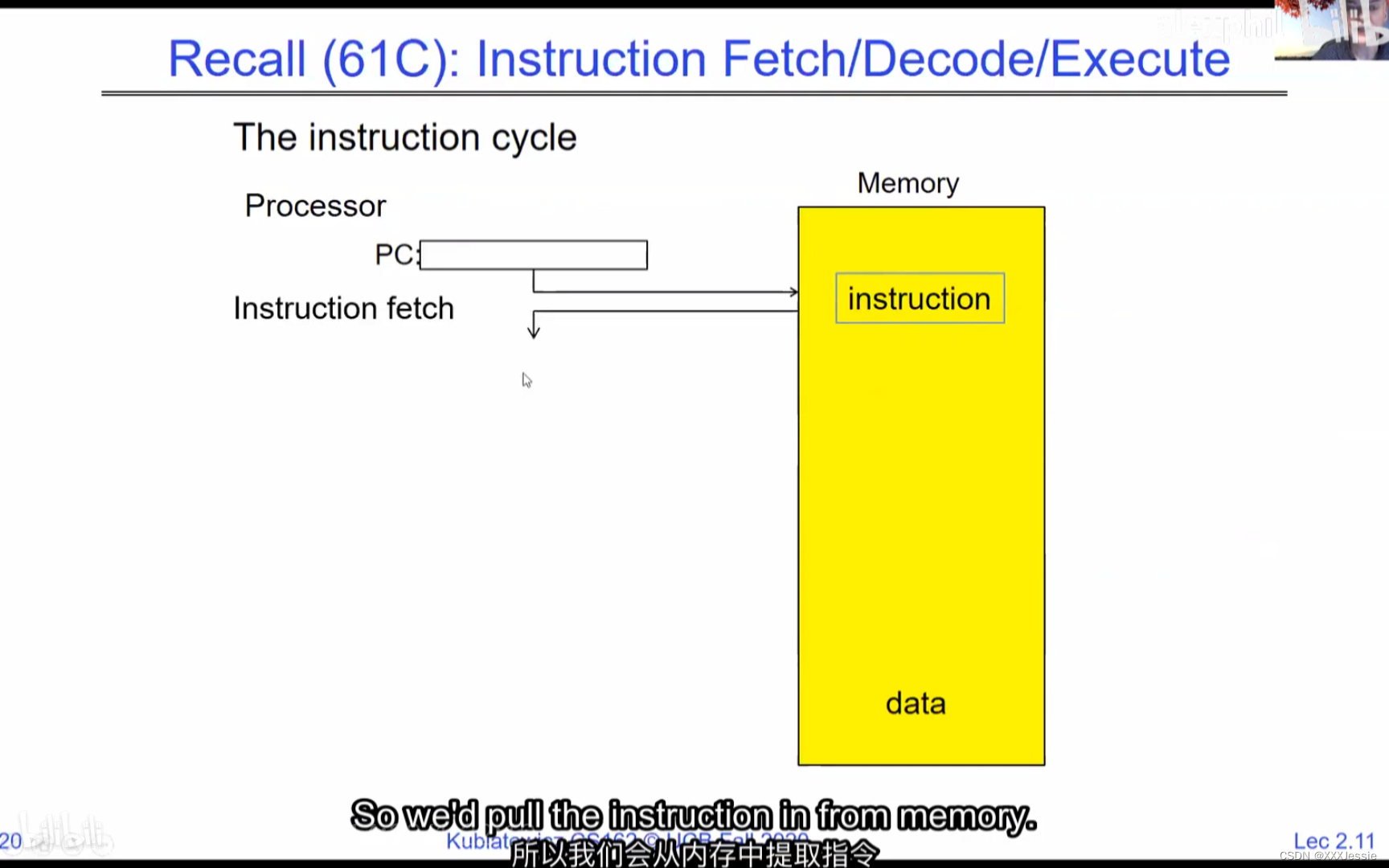
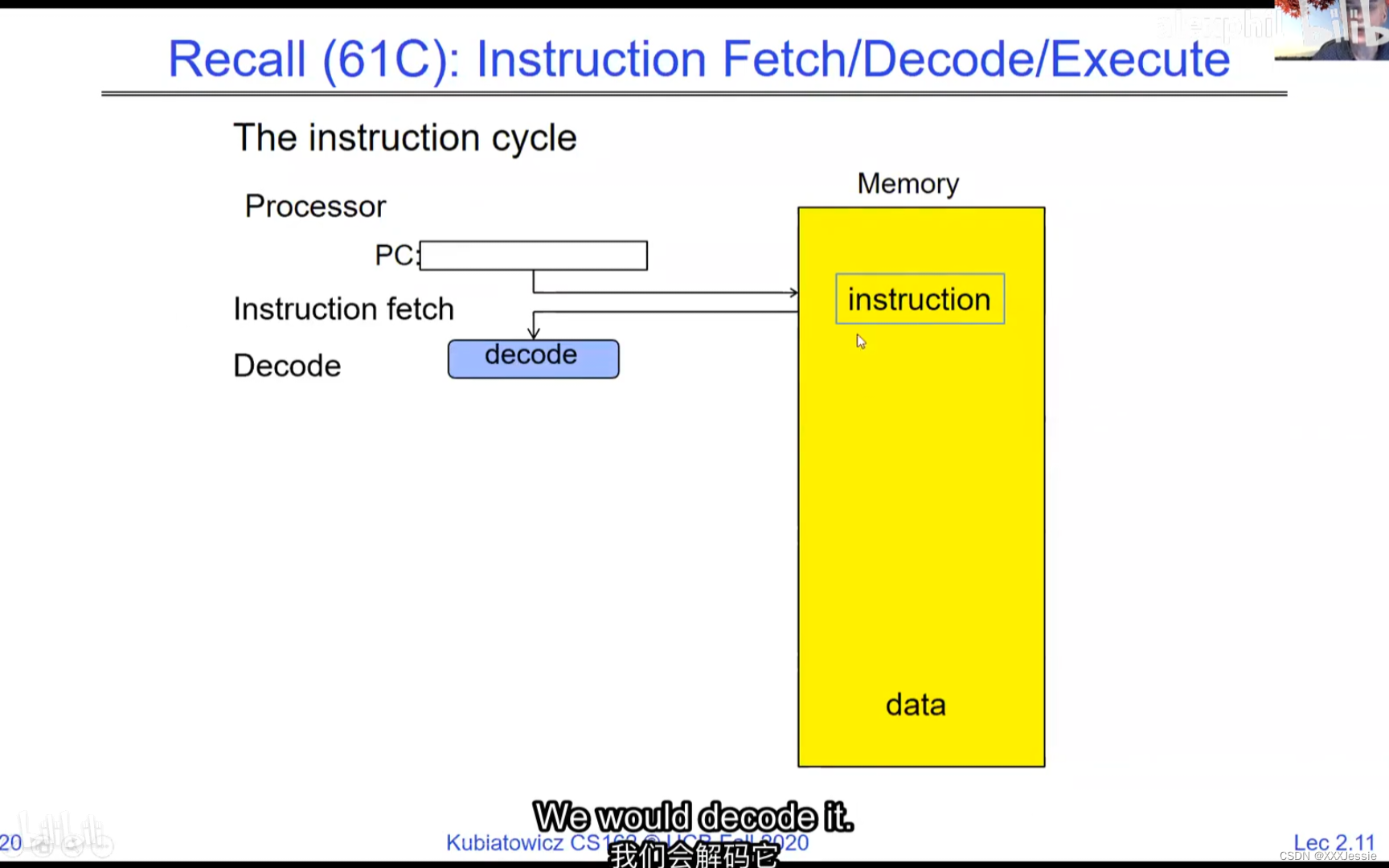
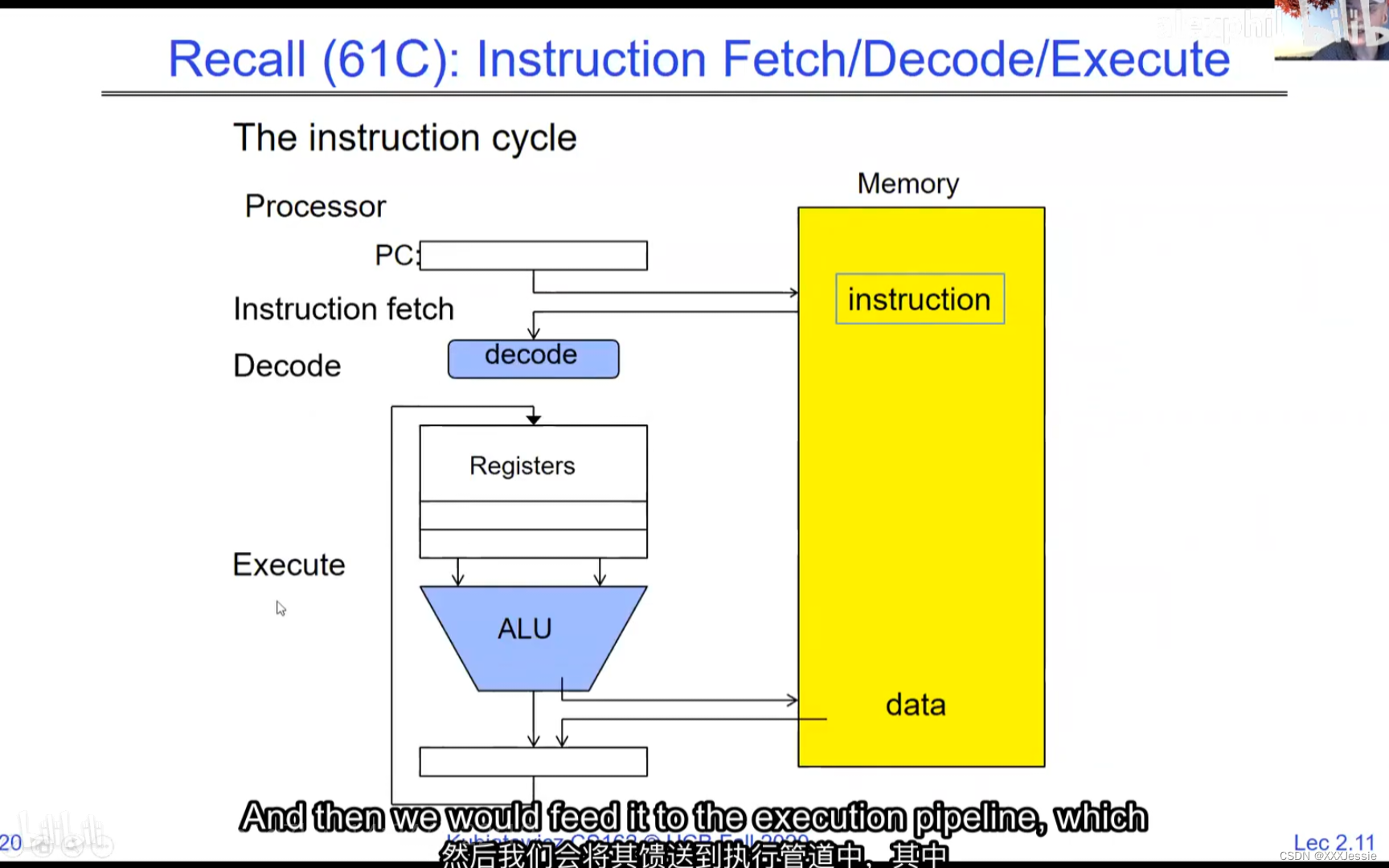
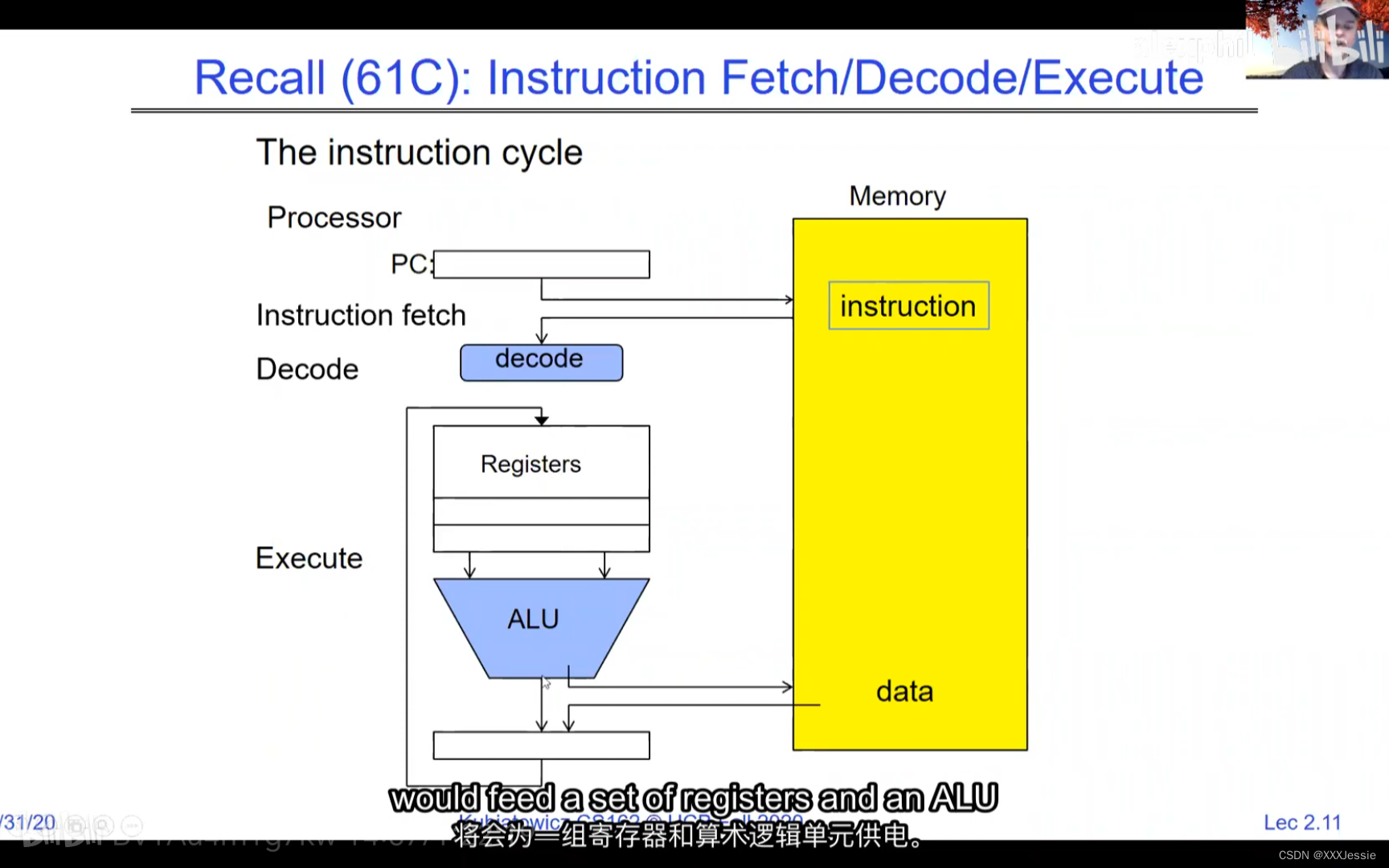
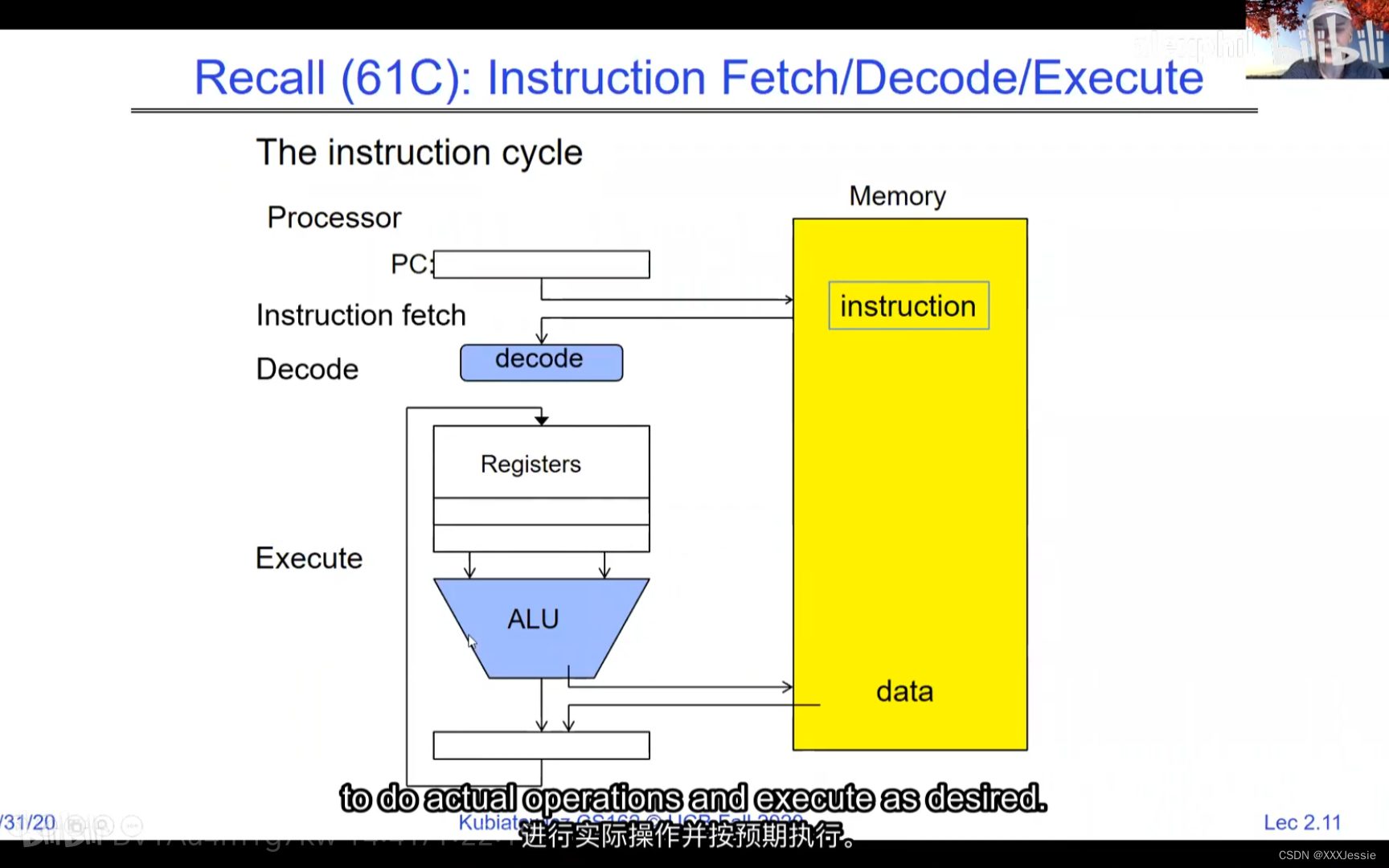
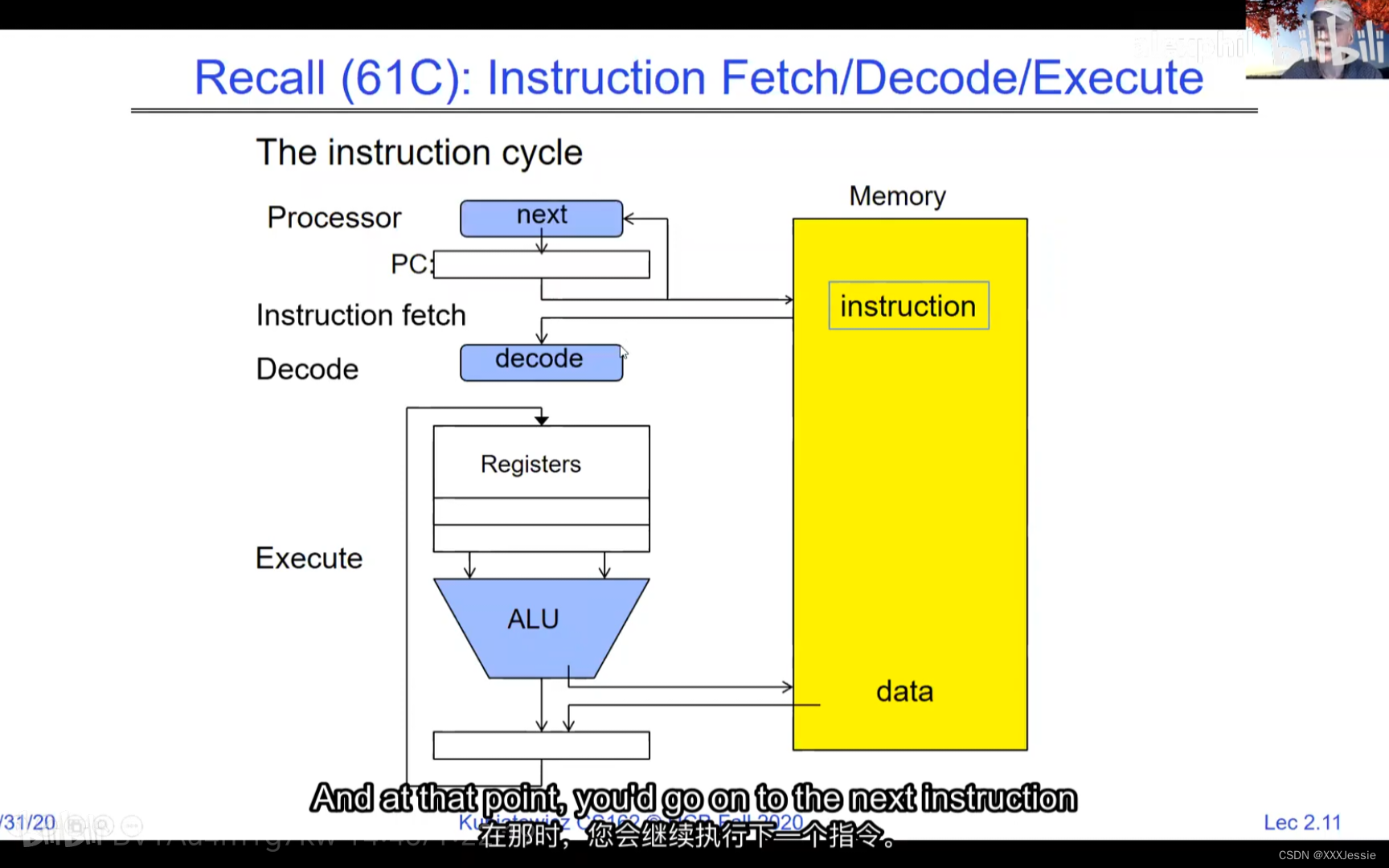
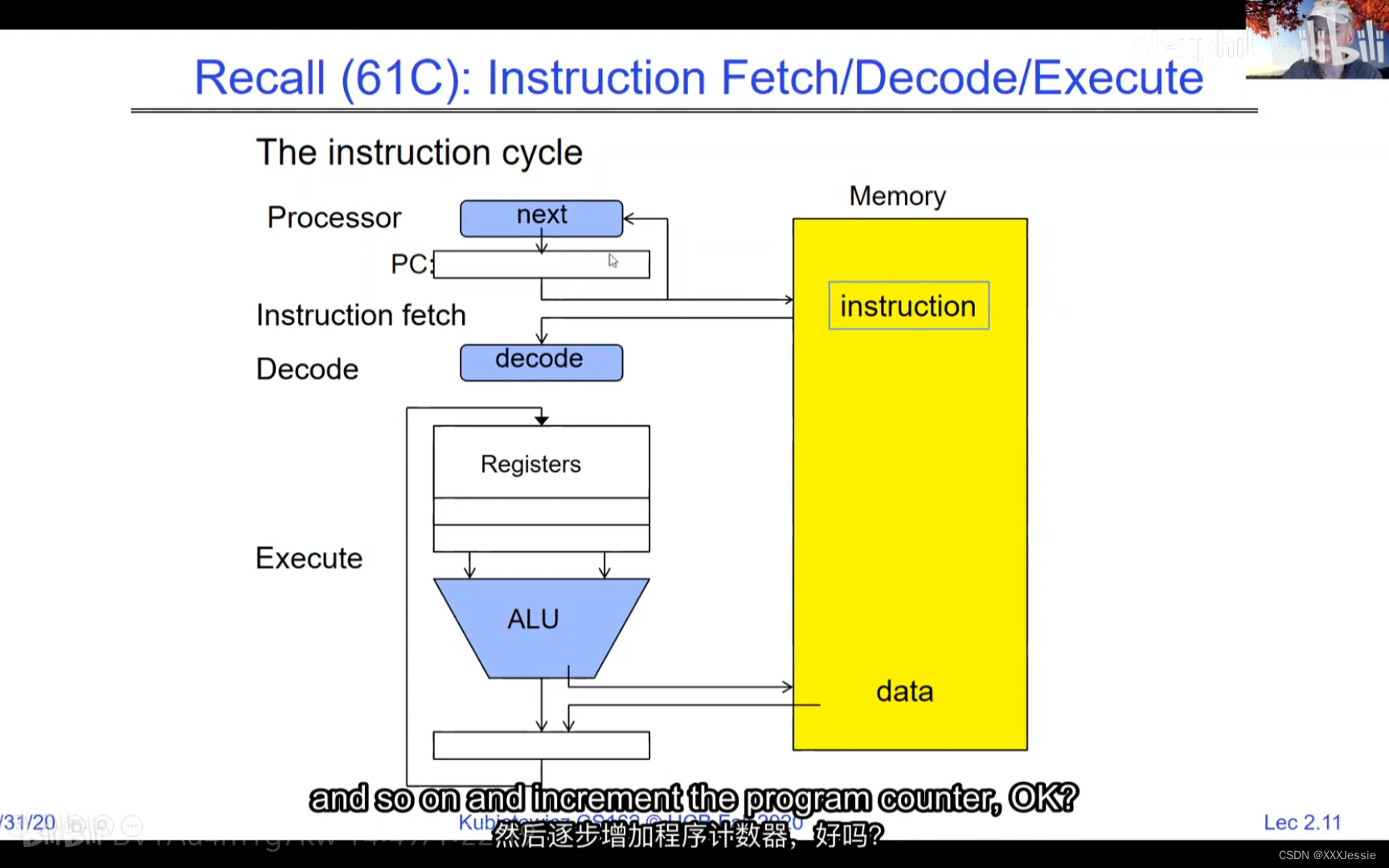








A tread is suspended or no longer executing when its state’s not loaded in registers the point states is pointed at some other thread .so the thread that’s suspended is actually siting in memory and not yet executing or not executing at all with some thing else is executing…so program counter is not pointing at the next execution from this thread because it’s pointing at the execution of the current thread
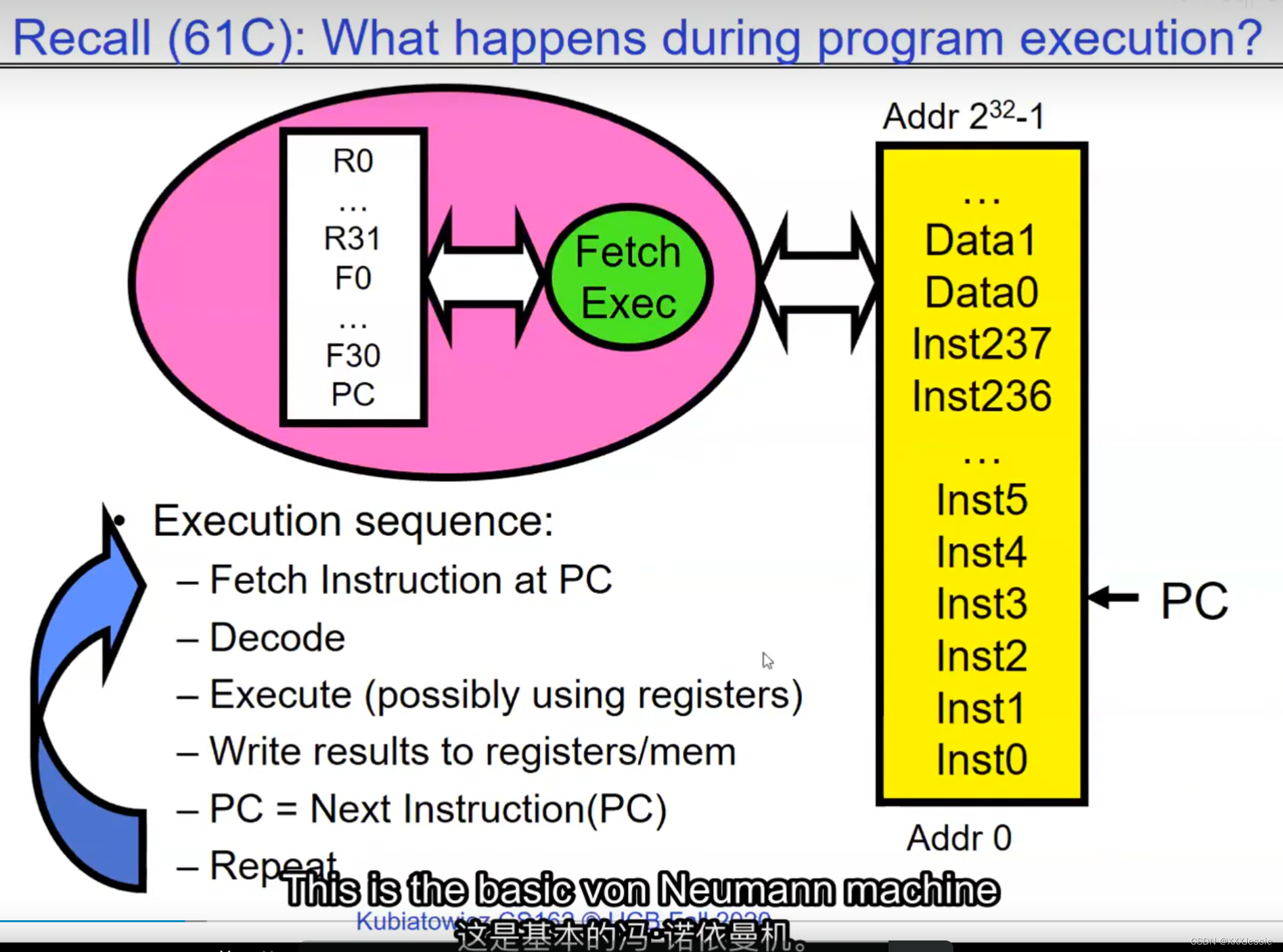

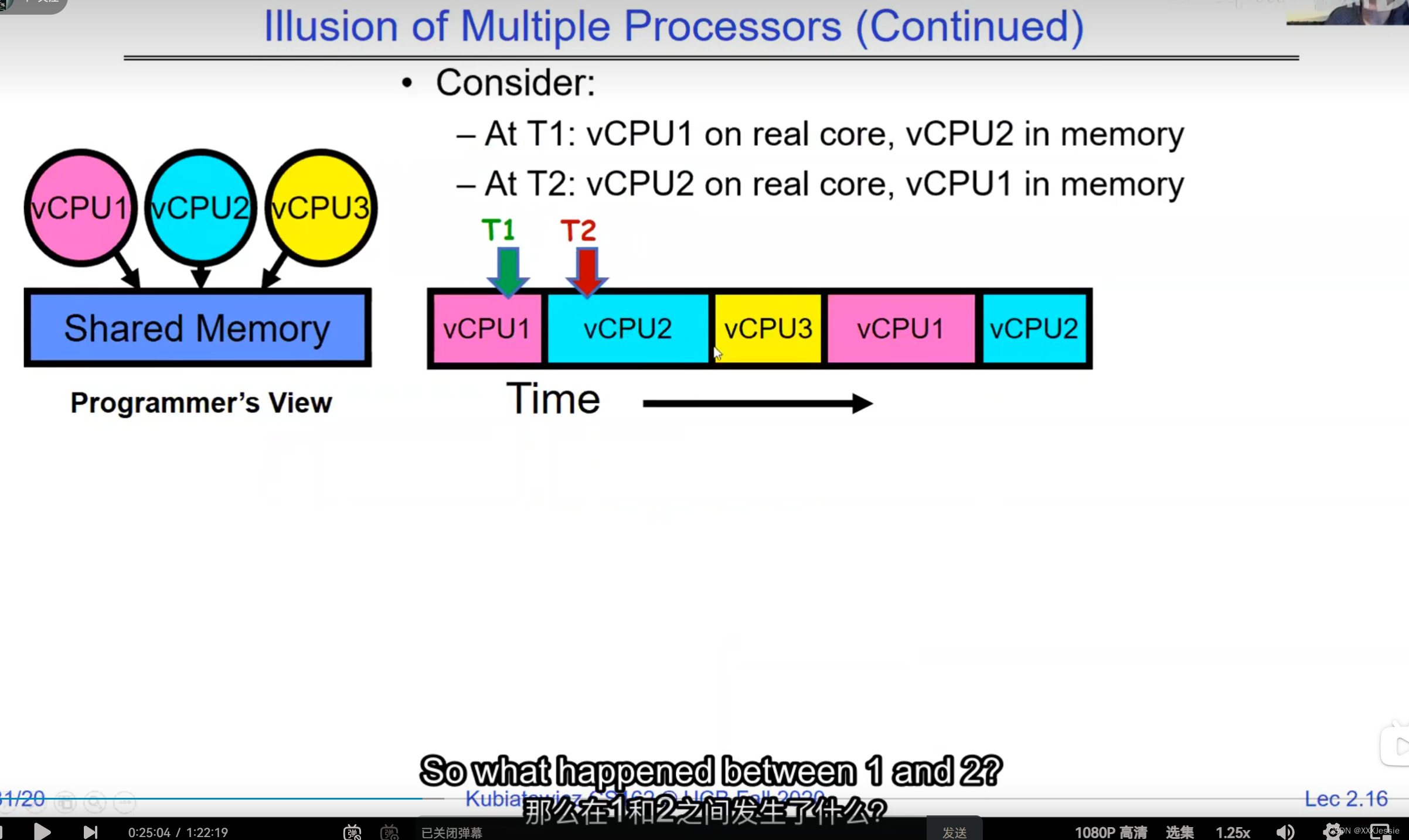
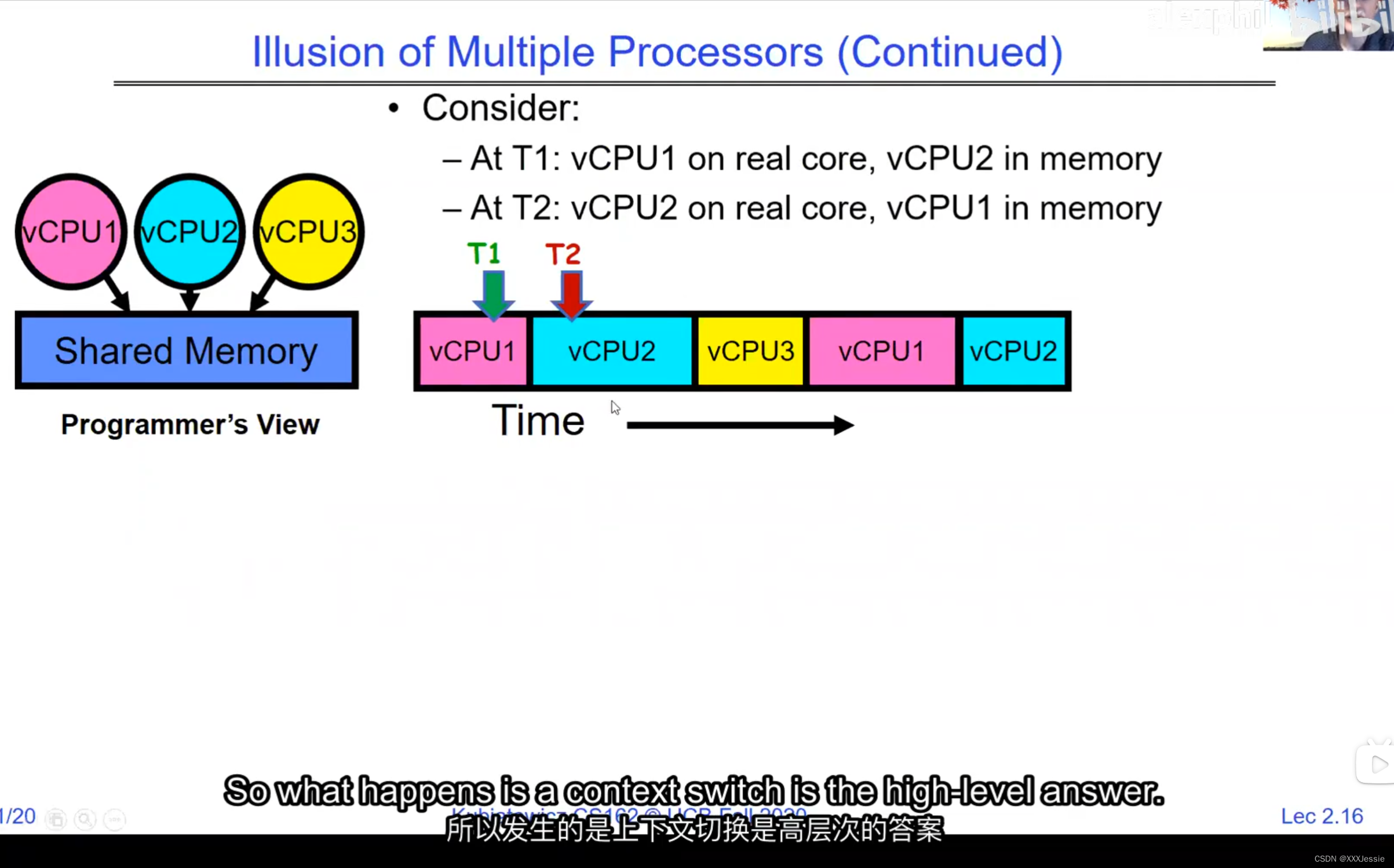
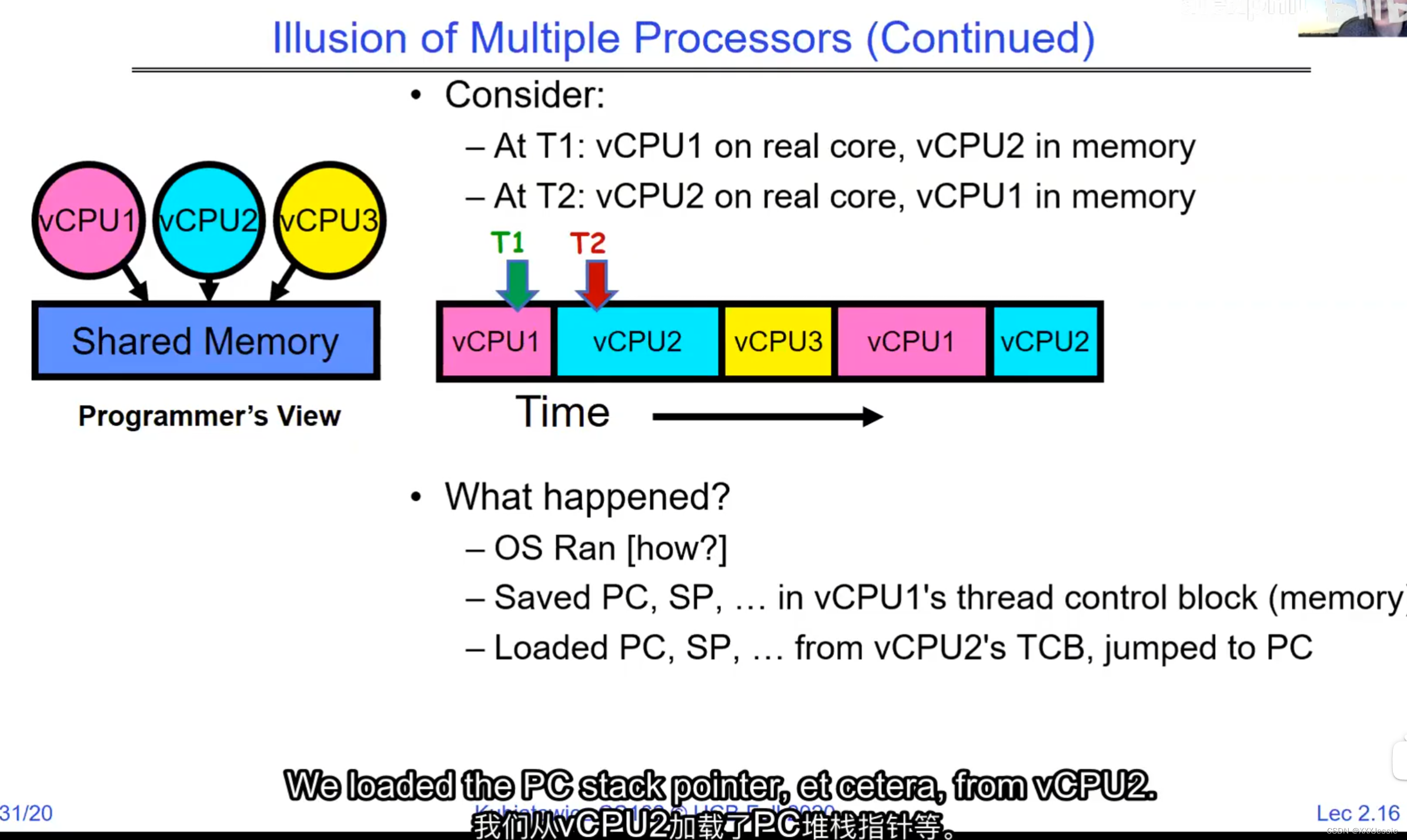
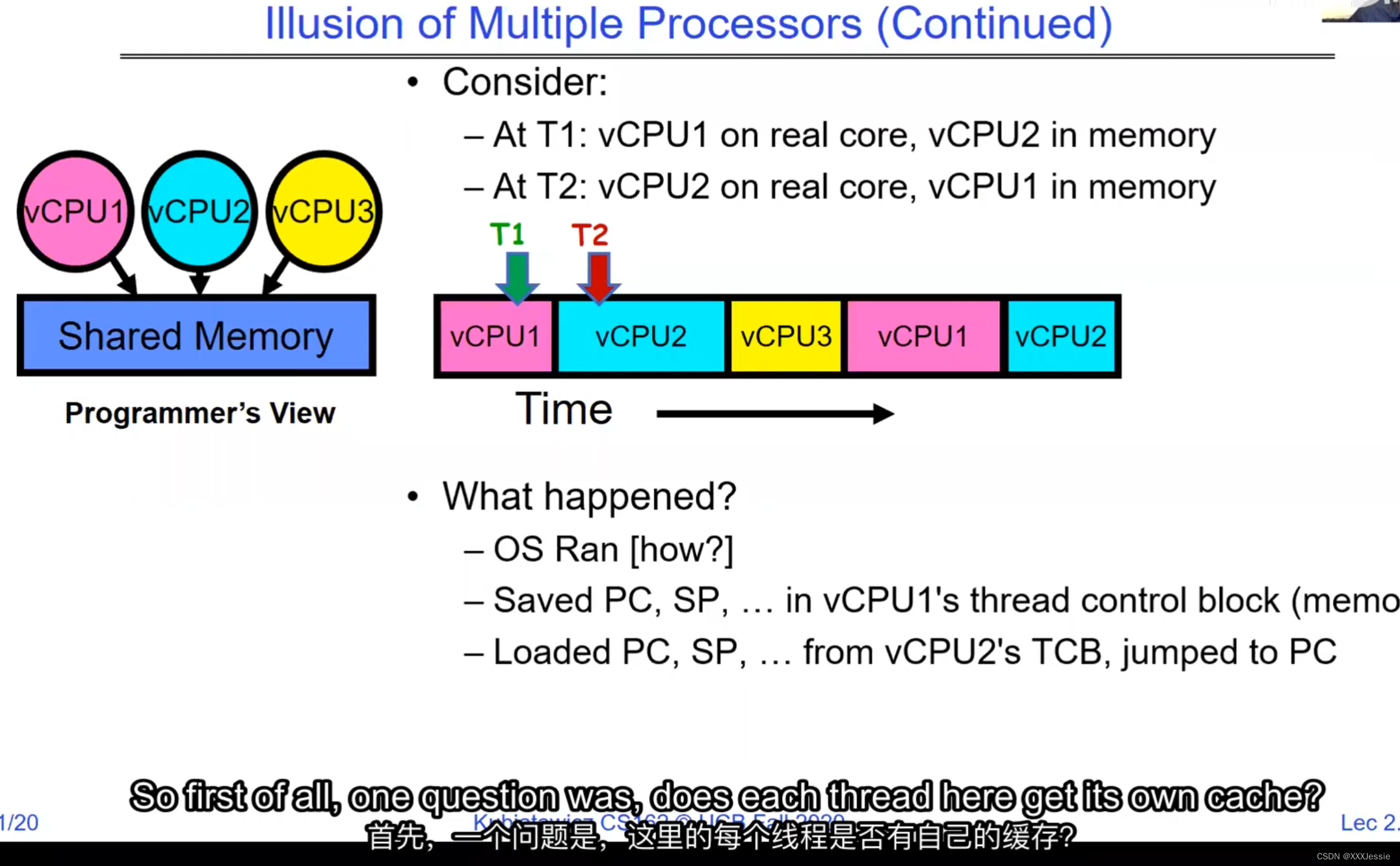
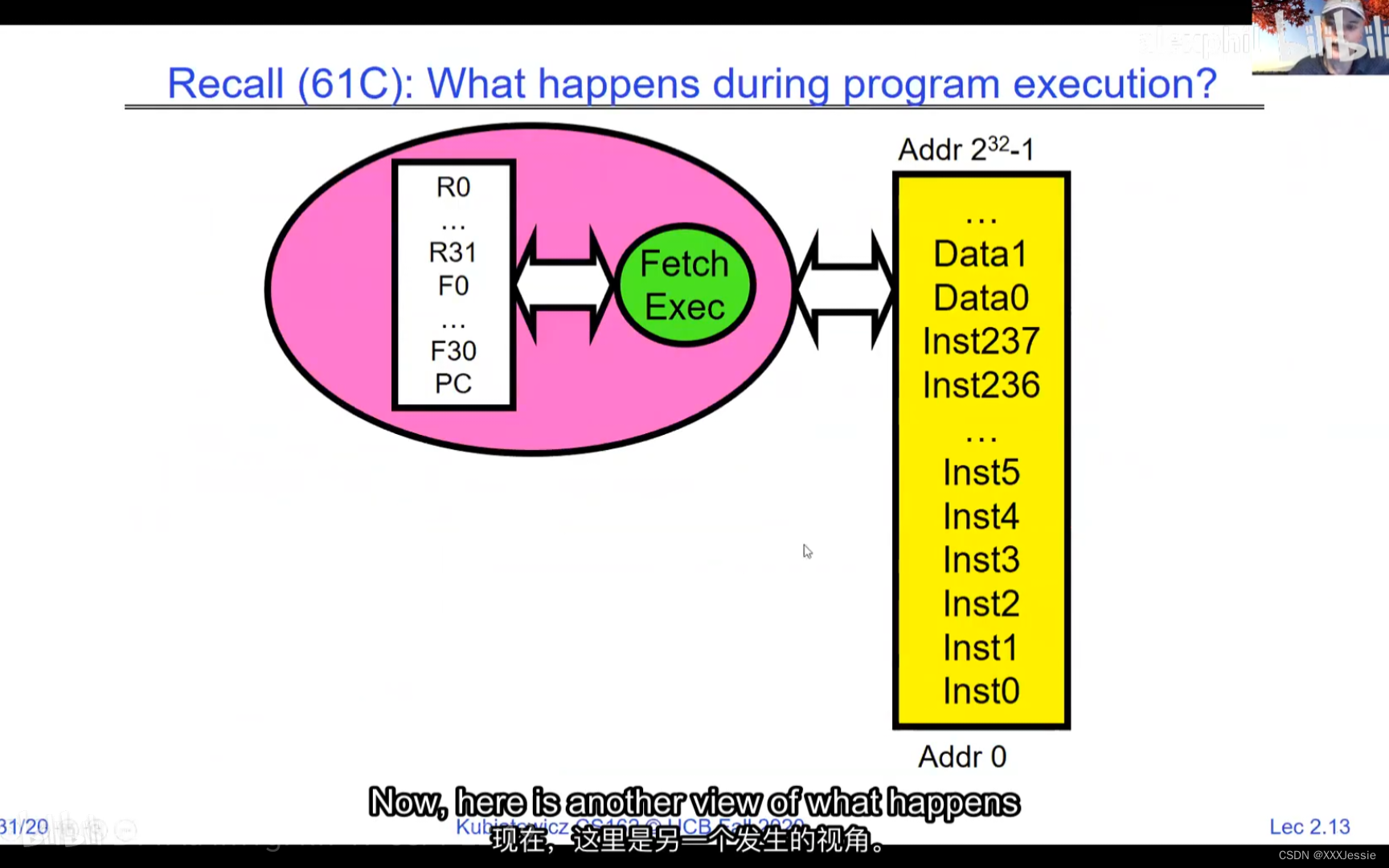
one cache for core
Addresses available for a 32-bit processor, by the way, are vast—two to the 32nd is approximately four billion. 10 to the 64 is 18 quadrillion, so that’s a lot of addresses. If you think of the address space as all potential places the processor could access, there are ones backed by DRAM, associated with some state. What happens when you read or write to an address? It could act like regular memory, ignore the write entirely, cause an I/O operation (memory-mapped I/O), or trigger an exception (like a page fault if there’s no memory assigned to that process). Writing to memory could communicate with another program.
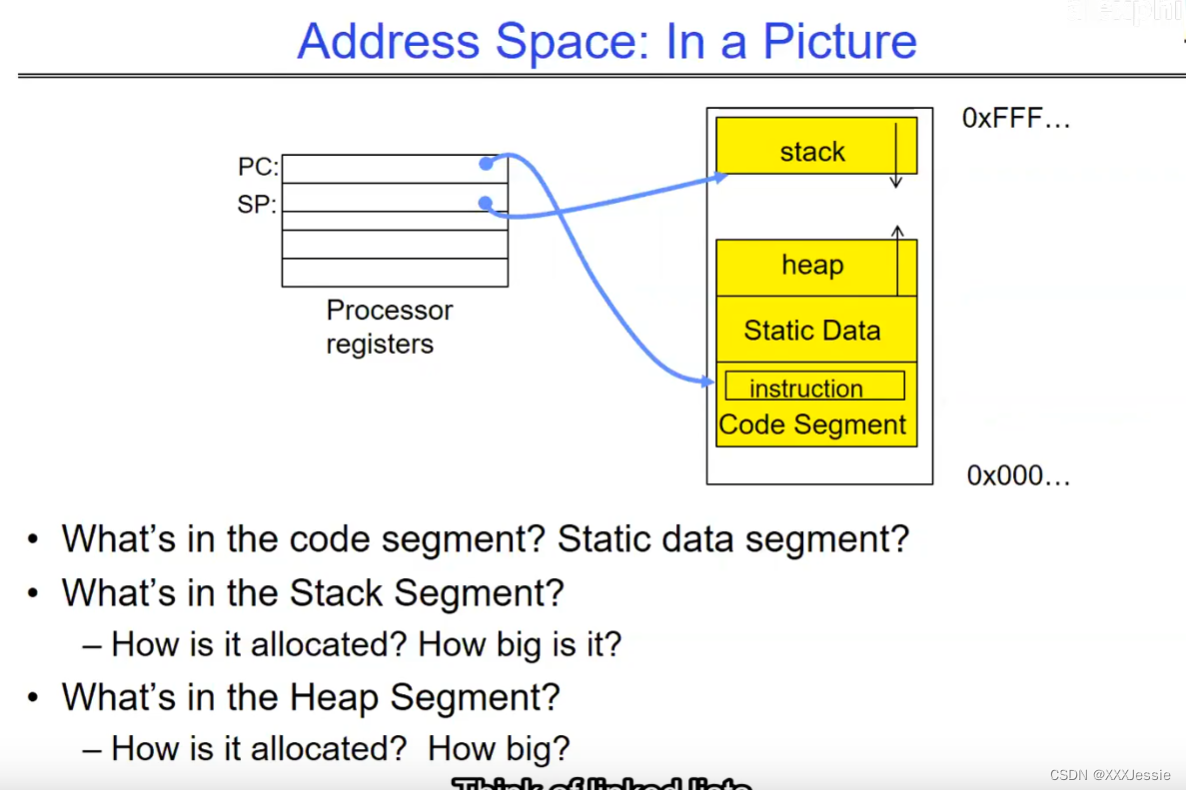
In a picture, the address space looks like this: the processor registers (including the program counter and stack pointer) point to various addresses—PC fetches from these addresses to execute instructions. Our threading and protection model will involve accessing this address space. What’s in the code segment? Code. Static data segment? Static variables, global variables, and string constants. Stack segment? Local variables and function calls’ recursive states, pushing variables on and off. Stack can grow with page faults, adding memory dynamically. Heap segment? Allocations made with malloc, like structures, linked lists, etc.
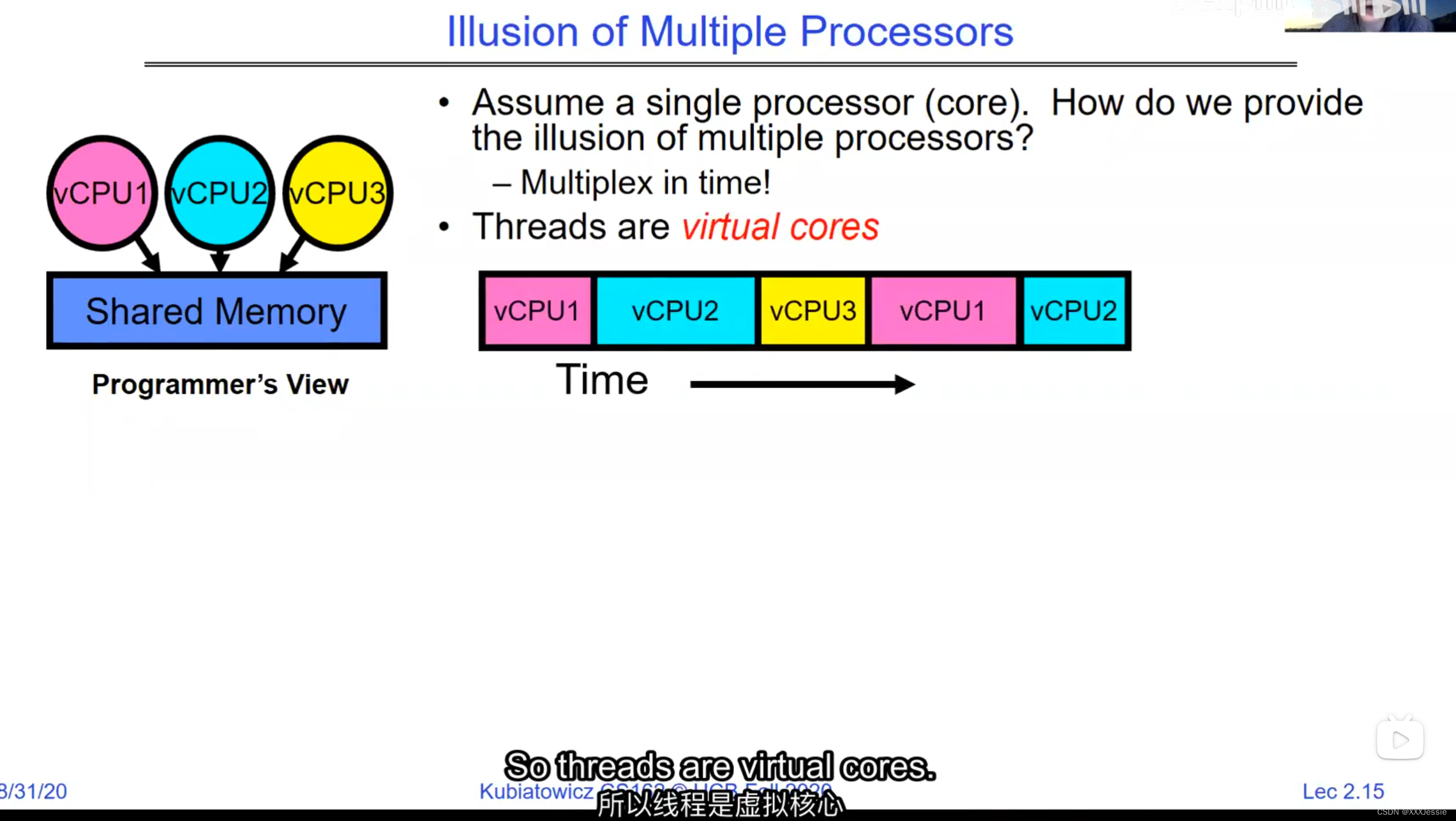
Threads in the same address space share everything except registers. Threads can overwrite each other’s stacks if they’re in the same address space, a design feature. Separate processes can prevent this. OS virtualization tries to make sharing as safe as possible. Security-wise, threads sharing memory can read/write each other’s data or keys, even overwrite the OS—a problem in early PCs, Macs, and early Windows. Modern systems aim for better security against bugs, ensuring a buggy software doesn’t crash everything else.
This approach was risky in early computing and some embedded systems, macOS, Windows 3.1, and Windows ME. It’s used less in modern systems for security reasons.
当然,请看以下的中文翻译,涉及计算机术语:
32位处理器可用的地址非常之多,例如2的32次方约为40亿。而2的64次方则为18千万亿,这是非常庞大的地址空间。如果把地址空间看作处理器可以访问的所有潜在位置,其中一些由DRAM支持,并与某些状态相关联。当您读取或写入一个地址时会发生什么呢?它可以像常规内存一样工作,完全忽略写入操作,引发I/O操作(内存映射I/O),或者触发异常(例如如果该进程未分配内存则会发生页面故障)。向内存写入数据可能会与另一个程序通信。
在图像中,地址空间如下所示:处理器寄存器(包括程序计数器和堆栈指针)指向各种地址。程序计数器从这些地址获取指令来执行。我们的线程和保护模型将涉及访问这个地址空间。代码段中有什么?代码。静态数据段中有什么?静态变量、全局变量和字符串常量。堆栈段中有什么?局部变量和函数调用的递归状态,将变量压入堆栈和弹出。堆栈可以通过页面故障动态增长,动态添加内存。堆段中有什么?通过malloc分配的内存,例如结构体、链表等。
在同一地址空间中的线程除了寄存器外共享所有内容。如果线程在同一地址空间中,它们可以互相覆盖堆栈,这是一种设计特性。单独的进程可以防止这种情况发生。操作系统的虚拟化尝试使共享尽可能安全。就安全性而言,共享内存的线程可以读取/写入彼此的数据或密钥,甚至覆盖操作系统,这在早期PC、Mac和早期Windows中曾是一个问题。现代系统力求更好的安全性,以防止错误的软件导致系统崩溃。
这种方法在早期计算机和某些嵌入式系统以及macOS、Windows 3.1和Windows ME中存在风险。出于安全考虑,现代系统使用较少。
Certainly! Here’s the complete English sentence structured from the provided text:
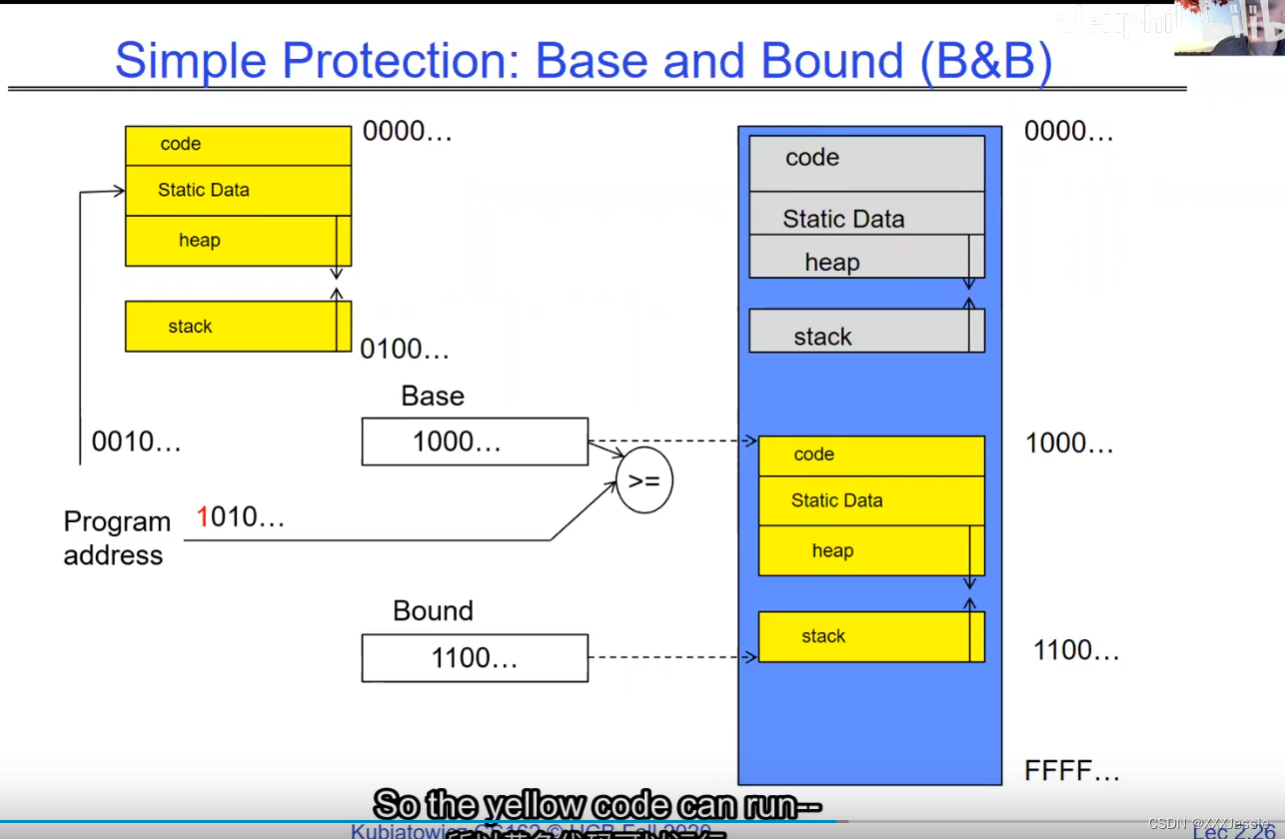
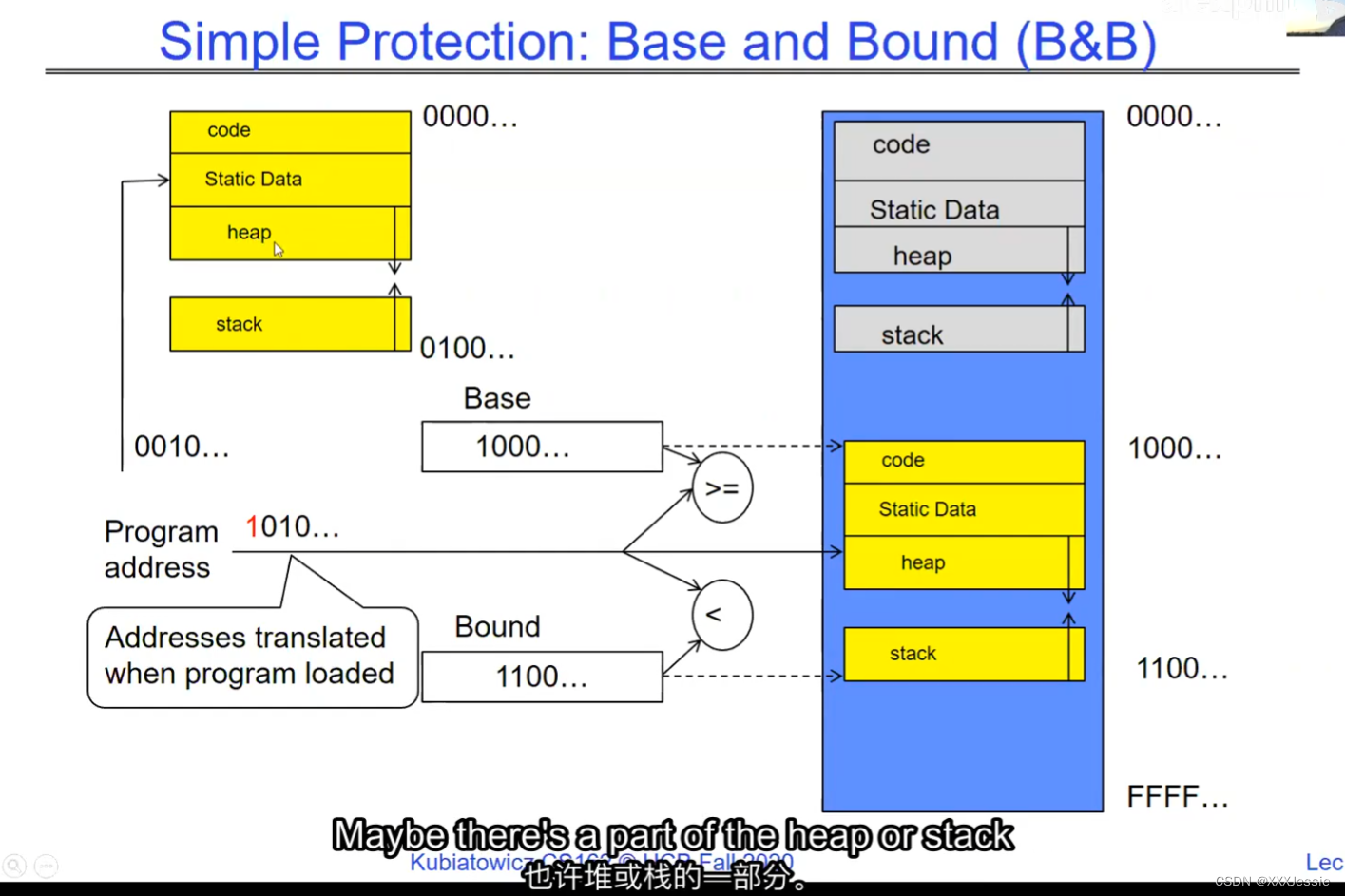
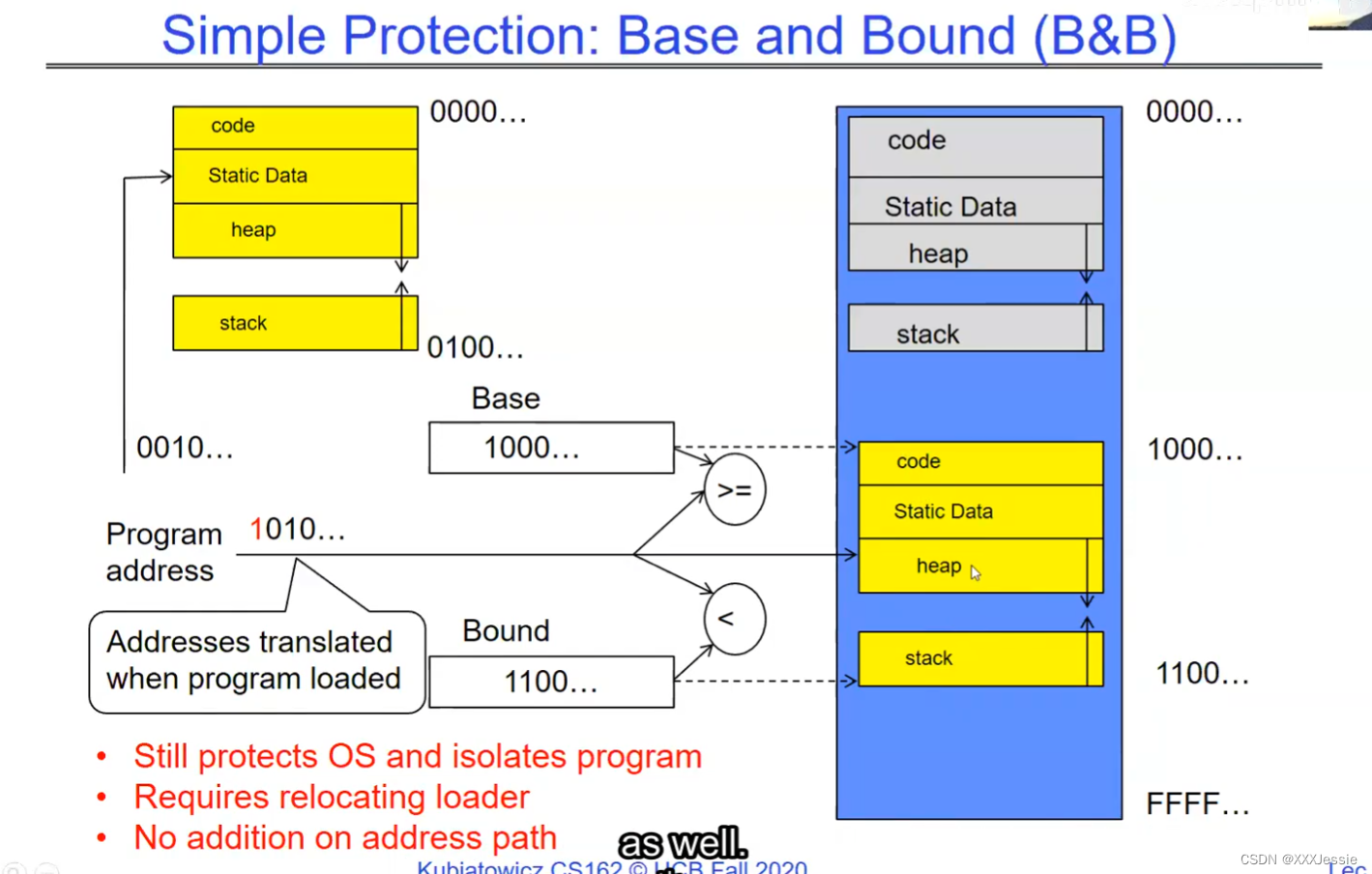
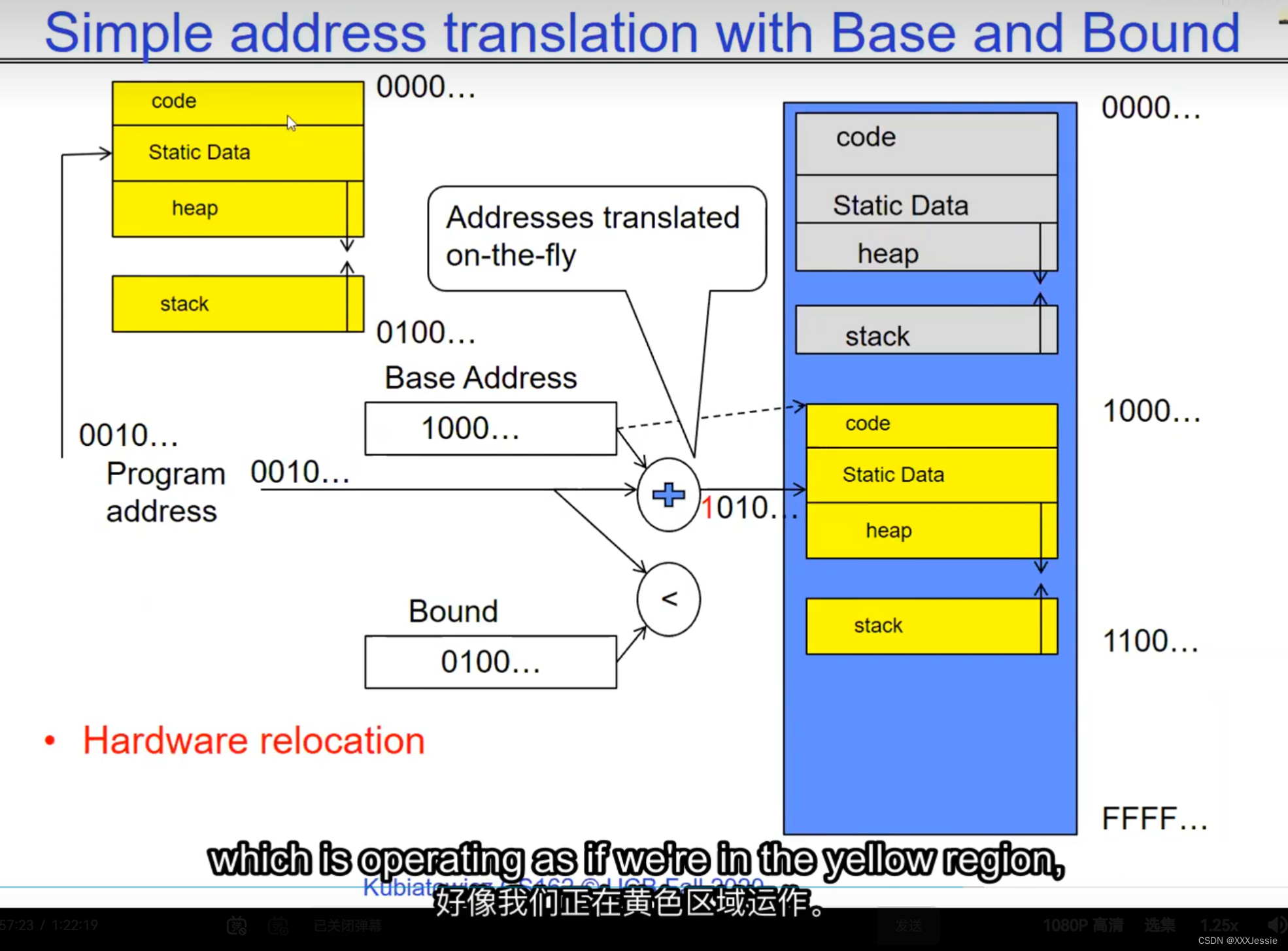
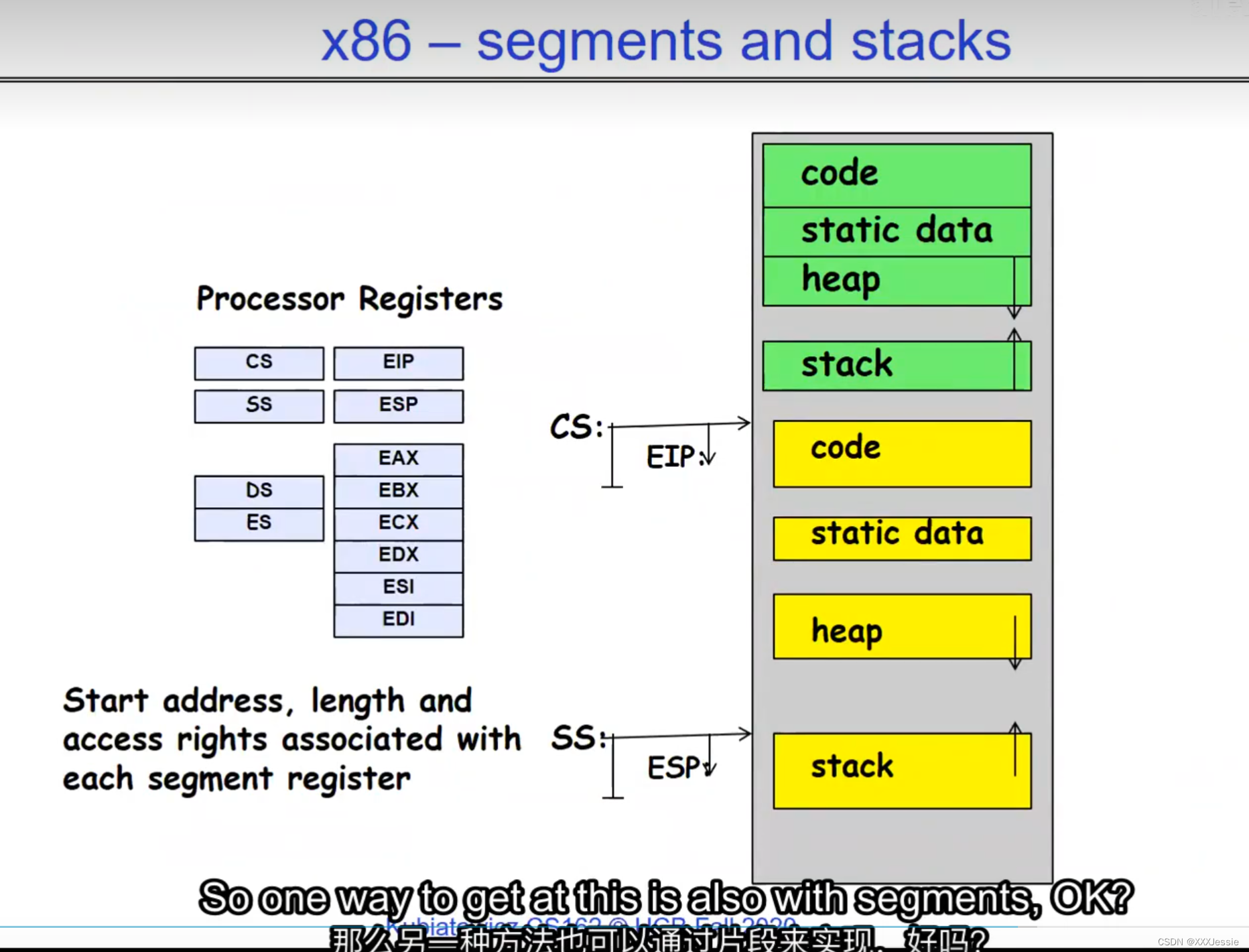
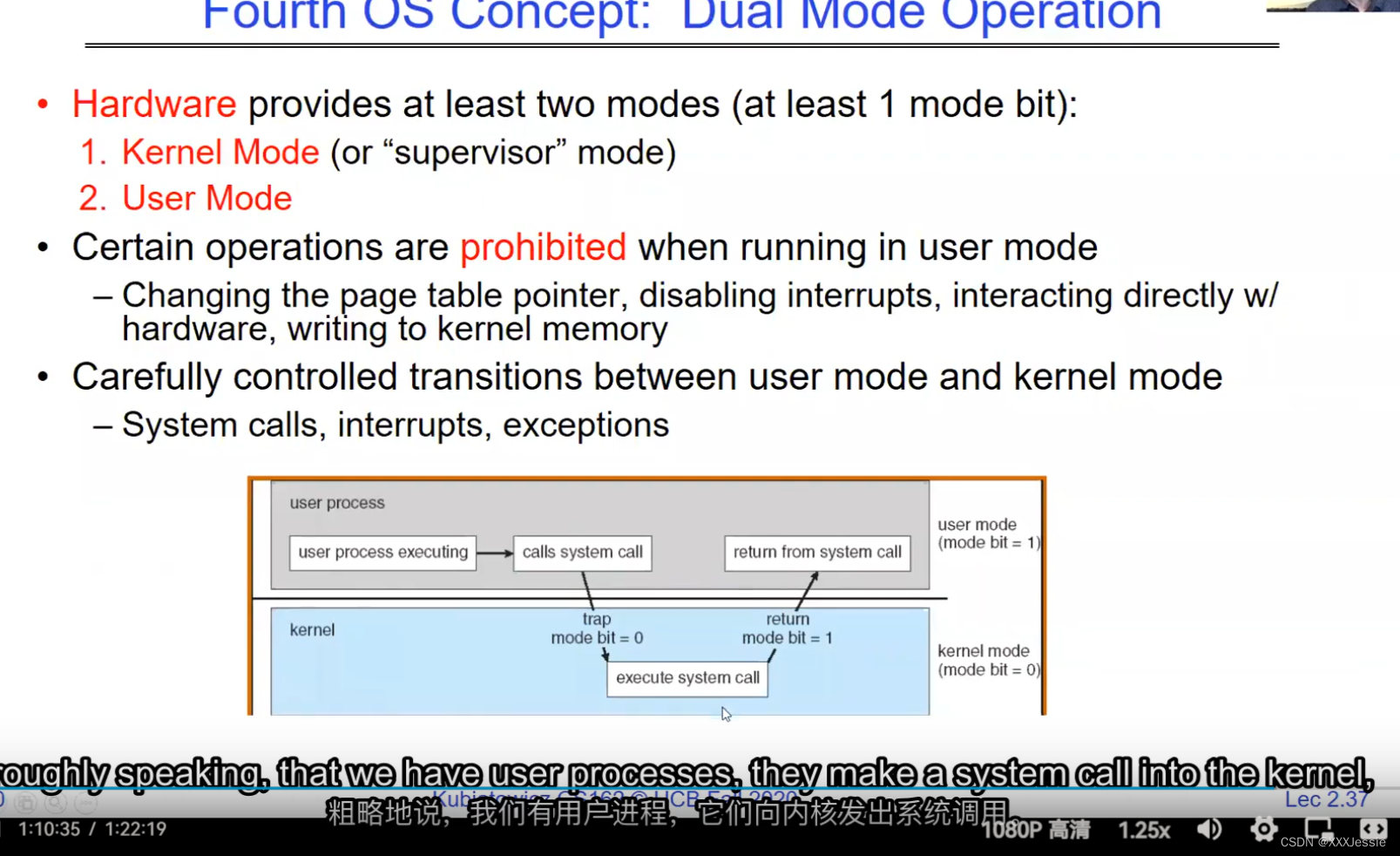
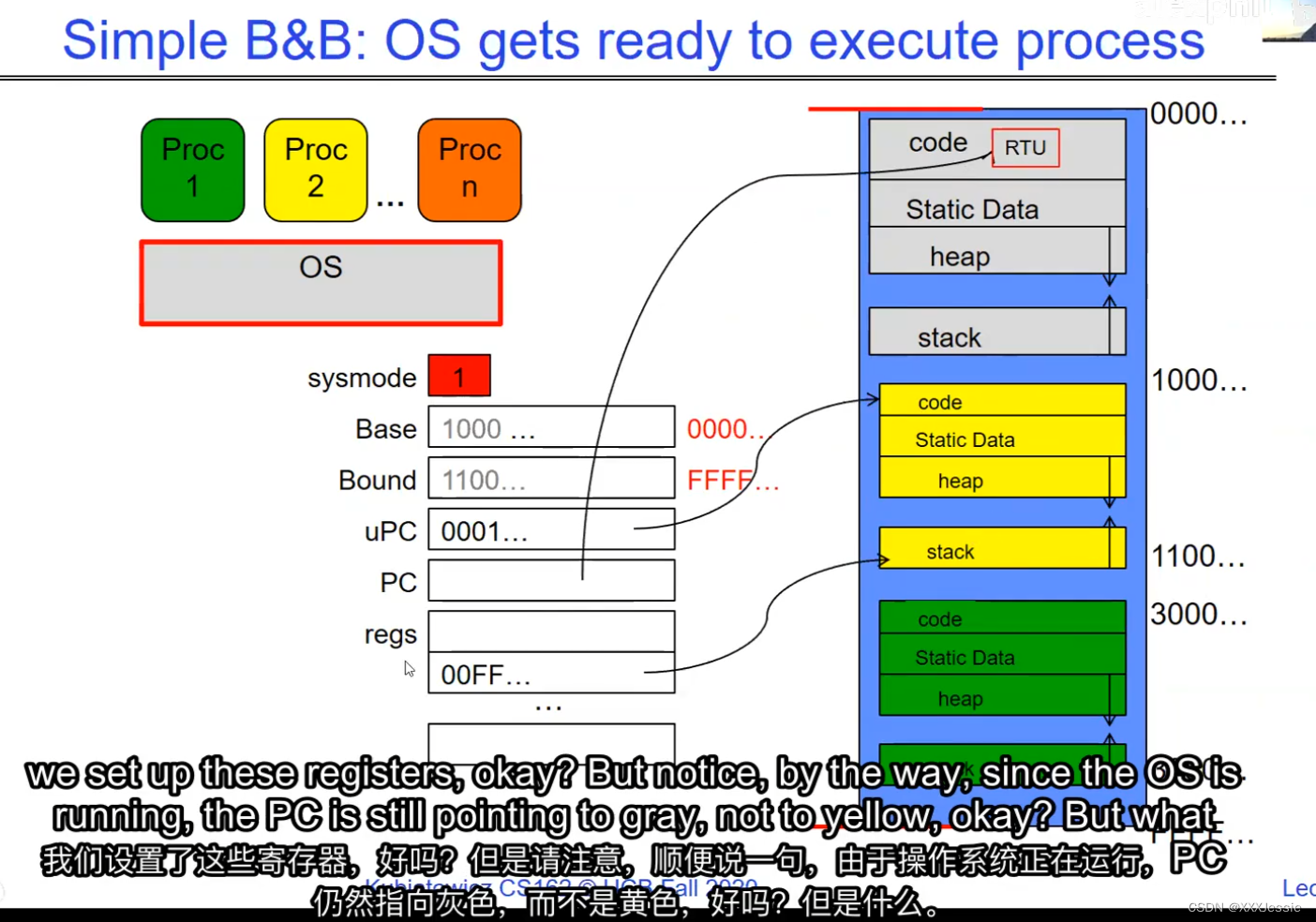
"Compromising the operating system generally causes it to crash. Of course, security— you want to limit the scope of what malicious software can do. Privacy— I want to limit each thread to the data it’s supposed to access. I don’t want my cryptographic keys or my secrets to be leaked. And also fairness— I don’t want a thread like that one that decided to compute the last digit of pi to suddenly be able to take all of the CPU at the expense of everybody else. Okay, so there’s lots of reasons for protection, and the OS must protect user programs from one another. Okay, prevent threads owned by one user from impacting threads owned by another one. Um, alright, so let’s see if we can do better. Okay, so what can the hardware do to help the OS protect itself from programs? Well, here’s a very simple idea— in fact, very simple, so simple that little tiny IoT devices can do this with very few transistors— and the idea is what I’m going to call ‘base and bound’. So, what we’re going to do is we’re going to have two registers, a base register and a bound register, and what those two registers talk about is what part of memory is the yellow thread allowed to access. Okay, what part of memory is the yellow thread allowed to access? Now, we’re still going to call this by the way I’ve got this uh, sorry, zero at the top and ffff at the bottom, I’ve swapped this for you guys but um, we are going to be able to put two addresses, one in base and a length or an address in bound depending on how you do it. And now we’re gonna see whether we can limit yellow’s span to just the uh, those range of addresses. Okay, we’re still gonna say the address space is from zero to all f’s, it’s just that a big chunk of that address space is not available to the yellow thing. Okay, and so what happens here is a program address that fits somewhere in the valid part of the program— what really happens is the program has been relocated, it’s been loaded from disk and relocated to this portion of memory, one zero zero, and so now when the program starts executing, it’s working with program counters that are in the say one zero one zero range which is kind of right, uh, where the code is, and hardware is going to do a quick comparison to say, ‘Is this program counter greater than base or is it and is it less than bound?’ Okay, and these are not physical, uh, excuse me, these are still physical addresses, these are not virtual addresses yet, we’ll get to that in a moment, okay, and this allocation size is uh, challenging to change in this particular model, okay, because in order to get something bigger we might end up having to copy a lot of the yellow to some other part of memory that’s bigger so you can see that this is just a very primitive and simple thing, okay, but what it does do is it gives us protection so the yellow code can run, it could do all it wants inside the yellow part of the address space, but it can’t mess up the operating system or anybody else’s code, okay, all right, and uh, whether base and bound are inclusive or not, that’s sort of a simple matter of whether you include equals or not so let’s not worry about this obviously base is inclusive in the way I’ve shown it here, um, so the other thing is for every time we do a, uh, lookup we make sure that we’re less than bound so it’s not inclusive on the top in this particular figure, and greater than or equal to base and if that’s true we allow it to go through and if it’s not true then we uh, do something like kill the thread off or something okay, now, the address here has been translated if you look this is what it might look like on disk it’s got, you know, it’s code starts at address zero there’s some static data after the code, maybe there’s a part of the heap or stack that’s going to be in there once it’s loaded but in some sense it looks like everything started zero and however when we load it into memory we relocate all the code so that it starts at address 1000 is runnable from that point and as a result things, uh, execute properly so this is a compiler-based loader-based relocation okay but it allows the OS to protect and isolate okay it needs a relocating loader now this by the way was what a lot of early systems did is they did relocation okay and had some basin bound possibilities to work so for instance the early some of the early machines by cray had this this behavior okay notice also that we’re using the program counter directly out of the processor without train changing in any so we’re not changing any of the the latency through transistors because we’re not adding any uh extra translation overhead as well okay and the gray part up here might be the OS yes now if you remember in 61c we talked about relocation um so for instance if you do a jump and link to the printf routine um what that translates into is a relocatable code where maybe the gel op code is uh hard-coded but the printf address is not until things get actually loaded and then this gets filled out so this might be a relative address until the linker and loader pulls it into memory okay all right so we can do this with the loader okay but a number of you have started to ask more and more about virtual memory well here’s another version of virtual memory that is actually well it’s uh the previous one was a hardware feature because in hardware we’re preventing uh the program when it’s running in user mode or as a user from accessing the OS so that’s a hardware-based check okay it’s not software all right now the uh a slight variation on the basin bound is this one where we actually uh put a hardware adder in here okay and this hardware adder one way to think of this is that addresses are actually translated on the fly so now we take our yellow thing off disk and we load it into memory and it might still be at address 1000 but the difference is that the program is now the program counter is now uh executing as if it were operating in this uh code that starts from zero but in fact what happens is by adding the base address to the program counter we get a translated address that’s now up in the space where yellow actually is okay all right so this particular uh version of this is uh it’s very simple and it doesn’t require page tables or complicated translation okay so this is a hardware relocation so on the fly the program counter which is operating as if we’re in the yellow region we add a base to it and the thing we actually use to look up in dram is the uh new address the physical address that we get from this virtual address added to the base pointer okay and can the program touch the OS once again no because if the program address goes negative we can catch that uh and so that would be below the base address and if it goes too too large above the bound then we would also be outside of yellow and so we basically protect uh the system against the yellow okay and so um once again we’re still doing checks here now can i touch onto the programs no because the bound catches it so one way to get at this is also with segments okay so in the x86 code or x86 hardware we have segments like the code segment the stack segment etc which are hardware registers that have the basin bound coded in that segment so a code segment is something which has a physical starting point and a length and then the actual instruction pointer that’s running is an offset inside of that segment so the code segment is very much like this base inbound because we do this addition on the fly and checking for the uh the bound okay and the question about where does the base address how do we decide what the base address is how do we decide what the bound is well that’s the os is basically doing a best fit of the current things it’s trying to run into the existing memory now a different idea which they did bring up in 61c which everybody’s clearly familiar with is this idea of address based translation so notice that what we just did was a very primitive version of translation where we took every address coming out of the processor and we added to it a base and we checked it against the bound and that translation now is just add a base and check about but um the thing we could do that’s even more sophisticated is we could take every address that comes out of the processor and go through some arbitrarily complicated translator and have it look up things in memory so uh if you look at uh how that might be so let’s think for a moment what was the biggest issue with this so there’s several issues not the least of which to grow the space for the yellow process or thread i haven’t told you how to distinguish those yet we would have to um copy the yellow thing somewhere else okay and and what we’re going to do is then when yellow finishes and goes away we’ve got a hole we’ve got a fill and so there’s a serious fragmentation problem so we’ll talk more about that in an upcoming lecture but what we’re going to do is we’re going to break the address space which is all of the dram into a bunch of equal sized chunks all pages are the same size so it’s really easy to place each page in memory and the hardware is going to translate using a page table okay this is 61c okay special hardware registers are going to store a pointer to the page table and we’re going to treat memory as a bunch of page size frames and we can put any page into any frame
抱歉,我误解了你的意思。以下是上面那段英文文本的中文翻译:
“破坏操作系统通常会导致其崩溃,这是肯定的。安全性:你想限制恶意软件可以做的事情的范围。隐私:我希望限制每个线程只能访问其应访问的数据。我不希望我的加密密钥或秘密泄露。此外,公平性:我不希望像那个决定计算圆周率最后一位的线程突然能够占据所有的CPU,而牺牲其他人。好的,保护有很多原因,操作系统必须保护用户程序免受彼此的影响。好的,防止一个用户拥有的线程影响另一个用户拥有的线程。嗯,好吧,我们来看看硬件能做些什么来帮助操作系统保护自己免受程序的影响。嗯,这是一个非常简单的想法,事实上,非常简单,以至于即使是非常少的晶体管也可以做到这一点。这个想法就是我称之为盆地边界。所以我们将有两个寄存器,一个基址寄存器和一个边界寄存器,这两个寄存器谈论的是黄线程被允许访问的内存的哪一部分。好的,黄线程被允许访问的内存的哪一部分?现在我们还是要称之为,顺便说一句,我有这个,抱歉,顶部的零,底部的FFFF。我已经为你们交换了这个,但是我们要能够在基址和边界中放置两个地址,或者地址中的一个地址,取决于你如何做。现在我们要看看是否可以将黄线程的跨度限制在地址的范围之内。我们仍然会说地址空间是从零到所有F,只是这个地址空间的一个大块不可用于黄色的东西。所以这里发生的是程序地址会适应程序的有效部分,实际发生的事情是,程序已经被重新定位,它已经被从磁盘加载并重新定位到内存的这一部分,100。所以现在当程序开始执行时,它正在处理程序计数器,这些程序计数器位于,比如说,100的范围内,代码所在的地方,硬件将进行快速比较,以判断该程序计数器是否大于基址,或者它是否小于边界,好的,这些不是物理地址,不好意思,这些仍然是物理地址,我们稍后会谈到这一点。好的,这种分配大小是,嗯,在这种特定的模型中改变是具有挑战性的,好吧,因为为了获得更大的东西,我们可能最终不得不复制很多黄色到内存的某个其他部分,这样你就可以看到这只是一个非常原始和简单的东西,但是它确实能给我们提供保护,所以黄色的代码可以运行。它可以在地址空间的黄色部分内做任何它想做的事情,但它不能搞乱操作系统或其他任何人的代码,好的?好吧,不管基址和边界是否包含在内,这在于是否包含等号,所以我们不要担心这一点,显然,基址在我这里所示的方式上是包含的,嗯,所以每次我们进行查找时,我们确保它小于边界,所以在这个特定的图中,顶部不包括是不包括的,比如说。大于或等于基址,如果为真,则允许其通过,如果不为真,则,嗯,做一些像杀死线程之类的事情,好吧?现在这里的地址已经被翻译了,如果你看,这是它在磁盘上可能看起来的样子,它的代码从地址0开始。在代码之后有一些静态数据。也许在加载后,堆或栈的一部分会在那里。但从某种意义上说,它看起来像一切都从零开始。然而,当我们加载到内存时,我们重新定位所有的代码,以便从地址100开始,并且可以从那一点运行。结果,事情正常执行。这是一个基于编译器的,基于加载器的重新定位,好的?但它允许操作系统保护和隔离,好吧,它需要一个重定位的加载器。现在,顺便说一句,这正是许多早期系统所做的,它们进行了重定位,好的?并且有一些基本的盆地边界可能性来工作。例如,克雷早期的一些机器就有这种行为,好的?还要注意的是,我们直接使用了处理器中的程序计数器,而没有在任何转换过程中增加任何额外的转换延迟,因此,我们不会改变任何东西,嗯,没有通过晶体管,因为我们没有增加任何额外的转换延迟。嗯,这里的灰色部分可能是操作系统,是的。现在,如果你还记得61C,我们谈过重新定位,好的?例如,如果你对printf例程进行跳转和链接,那么这将被转换为可重定位代码,其中可能GEL操作码是硬编码的,但printf地址不是,直到实际加载的时候,这些就填充了出来。所以这可能是一个相对地址,直到链接器和加载器将其拉入内存。好的,好的。我们可以通过加载器来做到这一点,好吧?但是你们中的一些人已经开始越来越多地询问关于虚拟内存的问题。嗯,这是虚拟内存的另一种版本,实际上,好的,前一个版本是硬件特性,因为在硬件上,我们在用户模式下或作为用户时防止程序访问操作系统,所以这是硬件检查,好的。”
Certainly! Here’s the text organized into complete English sentences without the timestamps:
"We’re going to execute a return from interrupt or return to user, and that’s going to start us running the yellow code. Now, the question is, why does the stack grow up in these diagrams? That’s because I’ve got 0x0000 and 0xFFFF reversed, so the lower part of the address is up top here and the higher part is on the bottom. Sorry about that. But notice, right now the kernel has full access to everything.
If we now do a return to user, what’s going to happen is that we’re going to activate this yellow one. Okay, so the privileged instruction is to set up these special registers like the base and bound registers, and so on. Notice we’ve set base to the beginning, we’ve set bound to the end, we’ve set up some special registers, we’ve set up the user PC, and we’re going to do the return to user mode. That’s going to basically do two things: one, it’s going to take us out of system mode, which is going to activate these base and bounds, and it’s going to cause the user’s PC to be swapped in for the existing kernel PC. And now all of a sudden after I do that, voila, we’re running in user mode.
“我们将执行从中断返回或返回到用户,这将开始我们运行黄色代码。现在,问题是,为什么栈在这些图中成长?这是因为我把0x0000和0xFFFF颠倒了,所以地址的下半部分在上面,而上半部分在下面。很抱歉。但请注意,现在内核可以完全访问所有内容。
如果我们现在返回给用户,会发生的是我们会激活这个黄色的。特权指令是设置这些特殊寄存器,比如基本寄存器和绑定寄存器,等等。注意我们设置了base到开始,我们设置了bound到结束,我们设置了一些特殊的寄存器,我们设置了用户PC,我们要返回到用户模式。那基本上会做两件事:,它会带我们离开系统模式,它会激活这些base和bounds,它会导致用户的PC被替换为现有的内核PC。我这样做之后,我们突然在用户模式下运行
Why do I say we’re running in user mode? The answer is that right now, because we’re in user mode, the base and bound are active, and so the code that’s running can’t get out of this little container. Alright.
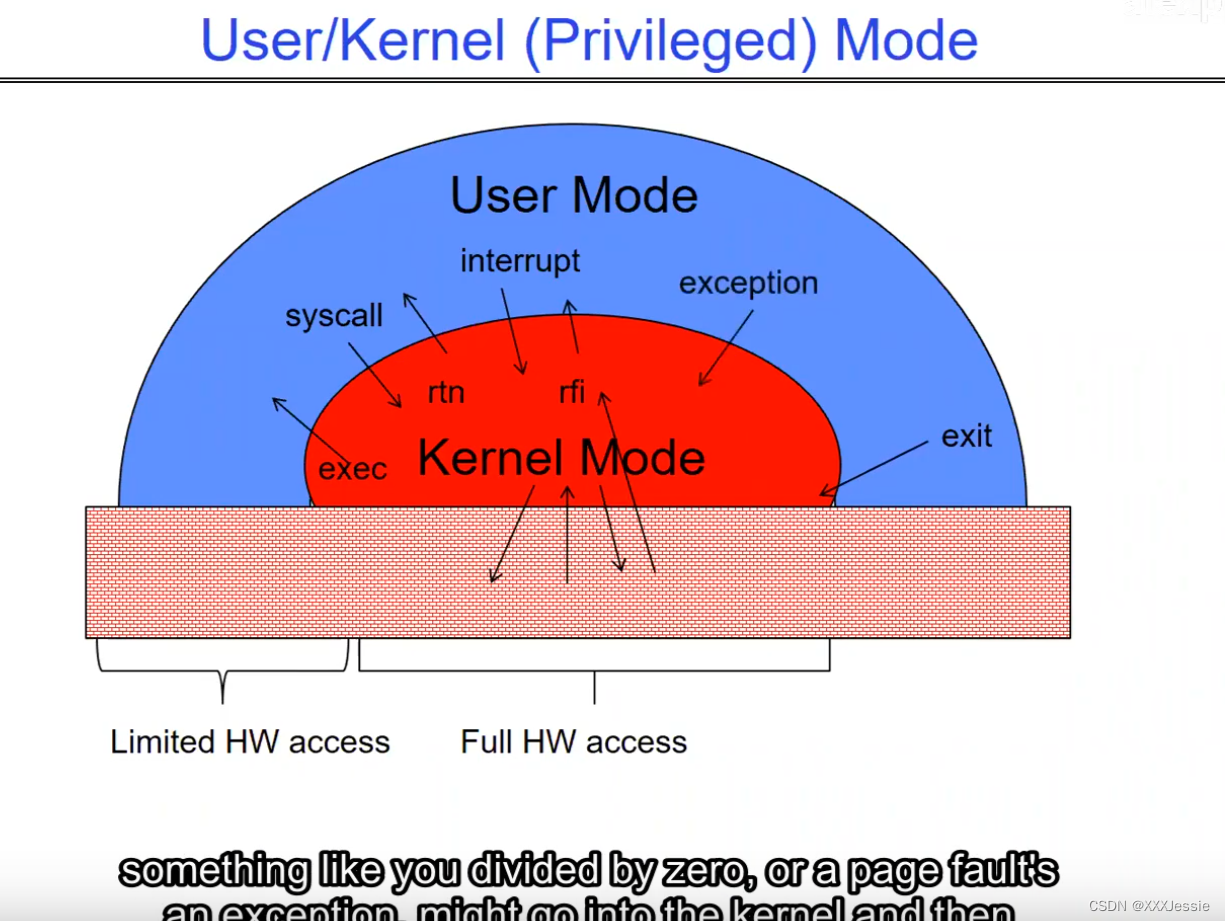
Coming back, so how does the kernel now switch? So now we’ve got this guy running, what do we do? Well, we’re going to have to take an interrupt of some sort and say switch to a different process. Okay, so the first question we have to ask before we figure out what the switching is involved is how do we return to the system? Alright, and I showed you some opportunities there a little moment ago, but we have three. So, for instance, system call is one where the process requests a system service that actually takes it into the kernel. Another is an interrupt. Okay, this is the case where an asynchronous event like a timer goes off and takes us into the kernel. And a third one is like a trap or an exception. It turns out that these could be examples where we get a page fault or where we divide by zero.
为什么我说运行在用户模式?答案是现在,因为我们在用户模式,base和bound是活动的,所以运行的代码不能从这个小容器中出来。好吧。
回到问题上来,那么内核现在如何切换呢?现在这家伙跑了,我们该怎么办?好吧,我们需要一个中断然后切换到另一个进程。好的,在我们弄清楚切换涉及到什么之前我们要问的第一个问题是我们如何回到系统?好的,我刚才给你们展示了一些机会,但是我们有三个。因此,例如,系统调用是进程请求系统服务,系统服务实际将其带入内核的一种调用。另一个是打断。这种情况下,异步事件,比如定时器,将我们带入内核。第三个就像是陷阱或例外。事实证明,这些可能是我们遇到缺页或者除以零的例子。
Now, the interesting question that’s on an interesting question in chat which I don’t have a lot of time to answer right now is what if a program needs to do something that can only be done in kernel mode? The answer is you’ve got to be really careful. So, one answer would be you can’t; you’ve got to do only the things that are provided as APIs from the kernel. That’s why the set of system calls is so important, to make sure it’s general enough for what you want to do. The second answer gets much more interesting, which is typically not something we talk about at this term in 162, but we could maybe, and that’s where we have an interface for downloading specially checked code into the kernel to run in kernel mode in a way that it doesn’t compromise the security. But that’s a pretty interesting topic for a different lecture.
现在,有趣的问题是关于聊天中的一个有趣问题我现在没有太多时间来回答如果一个程序需要做一些只有在核心态才能做的事情呢?答案是你必须非常小心。一个答案是,你不能;您只需执行内核以api形式提供的操作。这就是为什么系统调用的集合如此重要,以确保它对你想要做的事情足够通用。第二个答案变得更有趣,这通常不是我们在162节中讨论的,但我们可能会讨论,那就是我们有一个接口,可以下载经过特殊检查的代码到内核中,在内核模式下运行,它不会损害安全性。但这是一个很有趣的话题。
So we’re getting close to those topics, so let’s continue. Here’s our example: the yellow code’s running, and if you notice, the program counter again is in the yellow code. And so on. How do we return to the system? Maybe an interrupt or I/O or other things we’ll say an interrupt for this. And what happens at that point is we’re now back in the kernel. So notice that we’re at system mode, we’re running, the PC is the interrupt vector of the timer, and we’ve got these registers from the yellow which have been saved as a result of going into the interrupt. And so what we’re going to do is we’re going to save them off into the thread control block, we’re going to load from the thread control block for green. Okay, and then here’s by the way somewhere in the kernel is the yellow thread control block and then voila, we return to user and now the green one’s running.
因此,我们可以调用这些东西中的任何一个:系统调用、中断或陷阱异常,以进入内核,以便我们可以进行切换。假设我们做了一个中断。这些都是未经编程的控制传输。那么这是如何工作的呢?我们将在下一讲中讨论更多关于这个的内容,但它的工作方式是,将中断中断变成内核中定义良好的部分,我们实际上会让那个中断(定时器中断)在一个表中查找,当操作系统启动时,我们放在那里,并选择中断处理程序。那个中断处理程序现在会运行,并决定是否该从进程a切换到进程b,顺便说一下,这是一周左右的课的主题。
因此,我们可以调用这些东西中的任何一个:系统调用、中断或陷阱异常,以进入内核,以便我们可以进行切换。假设我们做了一个中断。这些都是未经编程的控制传输。那么这是如何工作的呢?我们将在下一讲中讨论更多关于这个的内容,但它的工作方式是,将中断中断变成内核中定义良好的部分,我们实际上会让那个中断(定时器中断)在一个表中查找,当操作系统启动时,我们放在那里,并选择中断处理程序。那个中断处理程序现在会运行,并决定是否该从进程a切换到进程b,顺便说一下,这是一周左右的课的主题。
We’re now officially out of time, but I want to leave you with one more concept: what if we want to run many programs? So now we have this basic mechanism to switch between user processes in the kernel. The kernel can switch among the processes, we can protect them, but these are all kind of mechanisms without sort of policy, right? So what are some questions like how do we decide which one to run, how do we represent user processes in the operating system, how do we pack up the process and set it aside, how do we get a stack and heap, et cetera, et cetera. All of these are interesting things that we’re going to cover. And you know, aren’t we wasting a lot of memory? All of these things.
Okay, and so there is a process control block, just like the thread control block. Don’t worry, we’ll get to that. But that’s where we saved the process state and inside of that will be the thread control blocks for all the threads that are there. And then the scheduler is this interesting thing which some might argue this is the operating system, which is every time or tick it says it looks at all the ready processes, picks one, runs it, and then the next time or tick it runs the next one and so on. And part of that process is unload and reload, unload and reload with some task called the scheduler selecting which is the right one based on some policies.
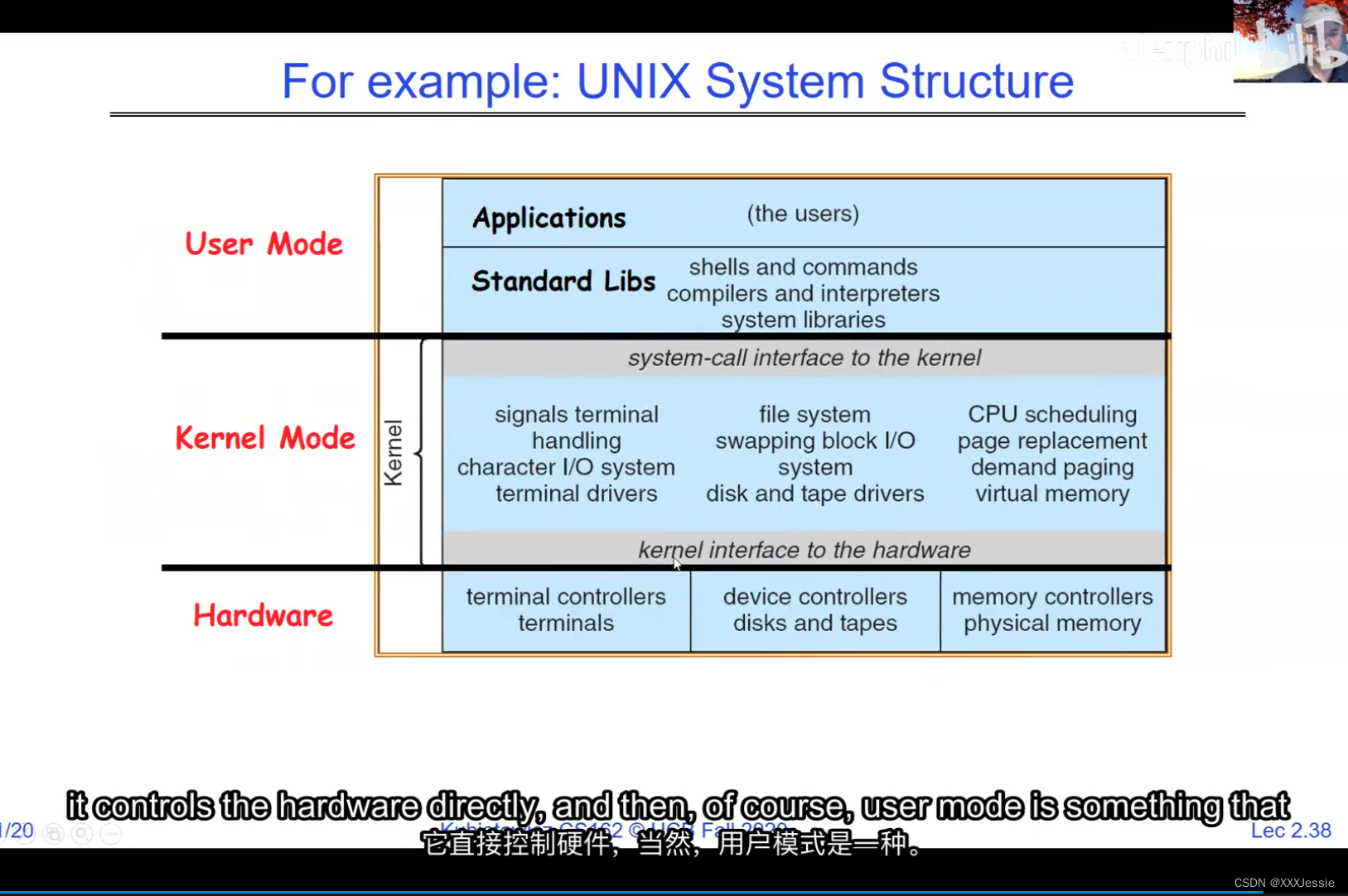
Alright, so we are done for today. So in conclusion, there are four fundamental OS concepts we talked about today: the execution context, which is a thread, okay, this is what you learned about in 61C, didn’t call it a thread because it wasn’t properly virtualized yet but it’s basically something with program counter, registers, execution flags, stack. We talked about the address space is the visible part of the to a processor, it’s the visible part of the addresses and once we start adding translation in now we can make protected address spaces which are protected against other processes. We talked about a process being a protected address space with one or more threads and we talked about how the dual mode operation of the processor hardware is what allows us to multiplex processes together and give us a nice secure model.
我们现在正式超时了,但我想留给你另外一个概念:如果我们想运行多个程序怎么办?所以现在我们有了在内核中切换用户进程的基本机制。内核可以在进程之间切换,我们可以保护它们,但这些都是没有策略的机制,对吧?有一些问题,比如我们如何决定运行哪一个,我们如何在操作系统中表示用户进程,我们如何打包进程并把它放在一边,我们如何得到堆栈和堆,等等。这些都是我们将要讲到的有趣的东西。我们是不是浪费了很多内存?所有这些。
这里有一个过程控制块,就像线程控制块一样。别担心,我们会讲到的。但那是我们保存进程状态的地方在那里面是所有线程的线程控制块。然后调度器是一个有趣的东西有些人可能会说这是操作系统,每次它都会检查所有就绪的进程,选择一个,运行它,然后下一次它会运行下一个进程,以此类推。这个过程的一部分是卸载和重新加载,卸载和重新加载一些任务叫做调度器根据一些策略选择正确的任务。
好了,今天就讲到这里。总之,我们今天讨论了四个基本的操作系统概念:执行上下文,它是一个线程,这是你在61C中学到的,不叫它线程,因为它还没有被正确虚拟化,但它基本上是一些有程序计数器,寄存器,执行标志,堆栈的东西。我们说过地址空间是处理器可见的部分,它是地址可见的部分一旦我们开始添加转换现在我们可以保护地址空间免受其他进程的攻击。我们讲过一个进程是一个受保护的地址空间有一个或多个线程我们讲过处理器硬件的双模式操作是什么让我们可以把多个进程放在一起并给我们一个很好的安全模型。


在这里插入图片描述




这篇关于CS162 Operating System-lecture2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






