本文主要是介绍【python】python葡萄酒国家分布情况数据分析pyecharts可视化(源码+数据集+论文)【独一无二】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

python葡萄酒国家分布情况数据分析pyecharts可视化(源码+数据集+论文)【独一无二】
目录
- python葡萄酒国家分布情况数据分析pyecharts可视化(源码+数据集+论文)【独一无二】
- 一、设计要求
- 功能点1:数据读取与展示
- 功能点2:数据筛选与保存
- 功能点3:数据可视化
- 二、设计思路
- 1. 数据读取
- 使用 `csv` 模块读取数据
- 使用 `pandas` 库读取数据
- 2. 数据清洗
- 删除缺失值
- 3. 数据处理
- 筛选特定数据并保存
- 总结
- 三、可视化分析
- 不同国家的葡萄酒数量分布
- 葡萄酒评分随价格的分布情况
- 不同评分等级的葡萄酒占比
- 价格和评分关系
- 国家葡萄酒数量进行分析
- 八个省份的葡萄酒数量
一、设计要求
该项目通过读取葡萄酒数据文件,进行数据分析和可视化,展示不同国家、评分和价格的葡萄酒分布情况。主要功能包括数据读取与展示、数据筛选与保存、以及数据可视化。
功能点1:数据读取与展示
- 读取CSV文件
- 使用
csv模块读取winemag-data.csv文件。 - 使用
pandas模块读取winemag-data.csv文件。
- 使用
- 显示特定行数据
- 使用
csv模块显示前15行、第20行到第25行、倒序输出最后10行的数据。 - 使用
pandas模块显示前15行、第20行到第25行、倒序输出最后10行的数据。
- 使用
- 数据描述
- 使用
pandas模块显示数据文件的信息(info方法)和描述性统计(describe方法)。
- 使用
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈
功能点2:数据筛选与保存
- 筛选US原产地葡萄酒数据
- 从数据中筛选出原产地为US的葡萄酒,并选择显示其描述、评分和价格字段。
- 保存筛选结果
- 将筛选出的US葡萄酒数据保存到新的CSV文件
us_wines.csv中。
- 将筛选出的US葡萄酒数据保存到新的CSV文件
功能点3:数据可视化
- 柱状图:不同国家的葡萄酒数量
- 创建柱状图显示不同国家的葡萄酒数量,设置标题为“不同国家的葡萄酒数量”。
- 箱线图:葡萄酒评分随价格的分布
- 创建箱线图显示葡萄酒评分随价格的分布,设置标题为“葡萄酒评分随价格的分布”。
- 饼状图:不同评分类别的葡萄酒占比
- 创建饼状图显示不同评分(低评分:80-84,中评分:85-89,高评分:90-100)类别的葡萄酒占比,设置标题为“不同评分类别的葡萄酒占比”。
- 散点图:价格与评分关系
- 创建散点图显示葡萄酒价格与评分的关系,设置标题为“价格与评分关系”。
- 环状图:五个国家的葡萄酒数量
- 创建环状图显示五个国家的葡萄酒数量,设置标题为“五个国家的葡萄酒数量”。
- 玫瑰图:八个省份的葡萄酒数量
- 创建玫瑰图显示八个省份的葡萄酒数量,设置标题为“八个省份的葡萄酒数量”。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈


👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈
二、设计思路
好的,结合上述代码,我们可以从数据读取、数据清洗和数据处理三个方面详细讲解代码的设计思路和实现过程。
1. 数据读取
数据读取是数据分析的第一步,代码中通过两种方式读取 CSV 文件的数据:使用 csv 模块和 pandas 库。
使用 csv 模块读取数据
import csvfilename = 'winemag-data.csv'
with open(filename, newline='', encoding='utf-8') as csvfile:reader = csv.reader(csvfile)data = list(reader)# 显示前15行数据
print("前15行数据:")
# 略 > 👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈# 显示第20行到第25行的数据
print("\n第20行到第25行的数据:")
# 略 > 👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈# 倒序输出最后10行的数据
print("\n倒序输出最后10行的数据:")
# 略 > 👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈- 读取文件:使用
open函数打开 CSV 文件,并使用csv.reader读取文件内容。 - 转换为列表:将读取到的数据转换为列表,方便后续操作。
- 显示特定行:通过列表切片操作显示特定行的数据,包括前15行、第20行到第25行,以及倒序的最后10行。
使用 pandas 库读取数据
import pandas as pd# 略 > 👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈# 显示前15行数据
print("\n前15行数据:")
print(df.head(15))# 显示第20行到第25行的数据
# 略 > 👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈# 倒序输出最后10行的数据
print("\n倒序输出最后10行的数据:")
print(df.tail(10)[::-1])
- 读取文件:使用
pandas.read_csv读取 CSV 文件,返回一个 DataFrame 对象。 - 显示数据信息和描述性统计:使用
df.info()和df.describe()分别显示数据的基本信息和描述性统计。 - 显示特定行:通过
df.head()、df.iloc[]和df.tail()[::-1]显示前15行、第20行到第25行以及倒序的最后10行数据。
2. 数据清洗
数据清洗是数据处理的重要一步,目的是确保数据的完整性和质量,去除或修正缺失、错误或不一致的数据。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈
删除缺失值
df = df.dropna(subset=['points', 'price'])
- 删除缺失值:使用
pandas提供的dropna方法,删除points和price列中包含缺失值的行,确保数据的完整性。
3. 数据处理
数据处理包括对数据的筛选、转换和保存等操作,以便后续的分析和可视化。
筛选特定数据并保存
# 略 > 👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈
us_wines.to_csv('us_wines.csv', index=False)print("\n筛选出的US葡萄酒数据已保存到us_wines.csv文件中")
- 筛选数据:使用布尔索引筛选出原产地为 US 的葡萄酒,并选择
description、points和price列。 - 保存数据:将筛选后的数据保存到新的 CSV 文件
us_wines.csv中,便于后续使用。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈
总结
整个代码从数据读取、数据清洗到数据处理,循序渐进地对葡萄酒数据进行全面的操作:
- 数据读取:通过
csv模块和pandas库读取数据,了解数据的基本结构和内容。 - 数据清洗:删除
points和price列中包含缺失值的行,确保数据完整性。 - 数据处理:筛选出特定条件下的数据并保存,为后续分析和可视化做好准备。
通过这些步骤,能够有效地对葡萄酒数据进行清洗和处理,确保数据质量并为进一步的分析奠定基础。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈
三、可视化分析
使用了 Pyecharts 库对葡萄酒数据进行了多种类型的可视化展示,以便从多个角度全面了解数据的特征和趋势。Pyecharts 是一个基于 Python 的数据可视化库,能够生成丰富多样的图表,包括柱状图、箱线图、饼状图、散点图、环状图和玫瑰图。
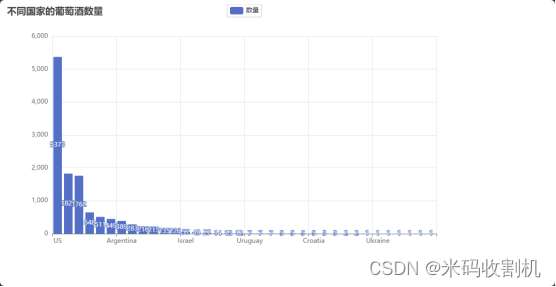
不同国家的葡萄酒数量分布
柱状图用于展示不同国家的葡萄酒数量分布。通过统计每个国家的葡萄酒数量,并在图表中以柱状形式展示,可以直观了解各个国家在葡萄酒生产中的份额。这种展示方式清晰明了,有助于快速识别出主要的葡萄酒生产国,为市场份额分析提供基础数据。
bar = (Bar().add_xaxis(df['country'].value_counts().index.tolist()).add_yaxis("数量", df['country'].value_counts().tolist()).set_global_opts(title_opts=opts.TitleOpts(title="不同国家的葡萄酒数量"))
)
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈
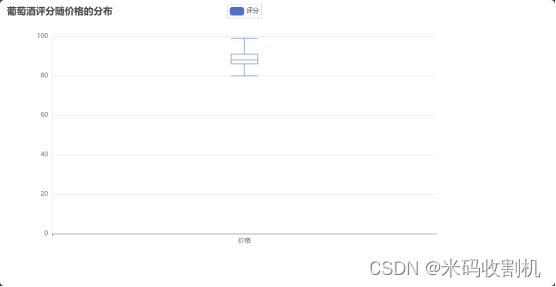
葡萄酒评分随价格的分布情况
箱线图用于展示葡萄酒评分随价格的分布情况。通过箱线图,可以观察到数据的分布情况、中位数、四分位数以及异常值。这种图表有助于揭示价格与评分之间的潜在关系,帮助消费者和生产者理解价格对评分的影响,从而优化定价策略和质量管理。
boxplot = Boxplot()
boxplot.add_xaxis(["价格"])
boxplot.add_yaxis("评分", boxplot.prepare_data([df['points'].tolist()]))
boxplot.set_global_opts(title_opts=opts.TitleOpts(title="葡萄酒评分随价格的分布"))
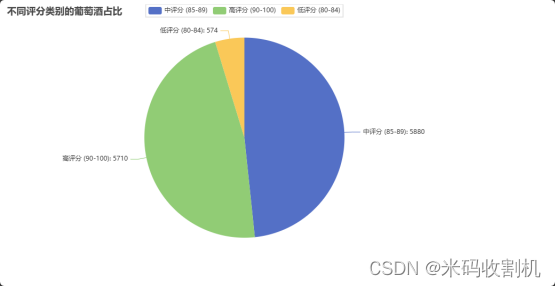
不同评分等级的葡萄酒占比
饼状图将评分分为三类:低评分(80-84)、中评分(85-89)和高评分(90-100),并展示各类评分的葡萄酒占比。通过这种分类展示,用户可以清晰了解不同评分等级的葡萄酒在数据集中所占的比例,有助于了解市场对不同评分葡萄酒的需求和接受度。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈
bins = [80, 84, 89, 100]
labels = ['低评分 (80-84)', '中评分 (85-89)', '高评分 (90-100)']
df['rating_category'] = pd.cut(df['points'], bins=bins, labels=labels, right=False)
rating_counts = df['rating_category'].value_counts()
pie = (Pie()# 略.....# 略......set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}", position="outside"))
)
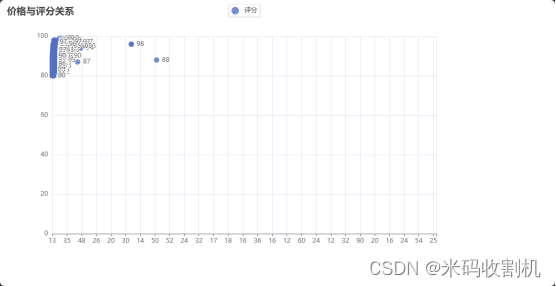
价格和评分关系
散点图展示了价格与评分的关系。通过在散点图中展示价格和评分的具体数据点,可以观察到价格与评分之间的分布趋势和聚集情况。这种图表有助于进一步验证价格是否在一定程度上反映了葡萄酒的评分,为消费者选购葡萄酒提供参考。
scatter = (Scatter()# 略.....# 略......set_global_opts(title_opts=opts.TitleOpts(title="价格与评分关系"))
)
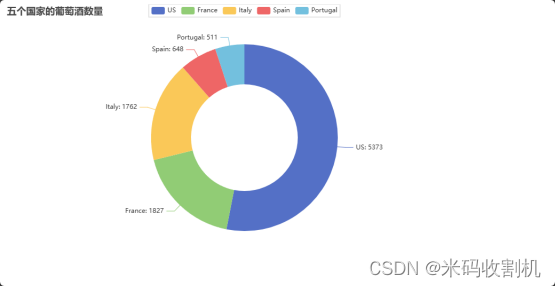
国家葡萄酒数量进行分析
环状图选择了前五个国家的葡萄酒数量进行分析。通过对主要葡萄酒生产国的数据进行环状图展示,用户可以直观了解这些国家的市场份额和竞争情况,为国际市场战略制定提供数据支持。
top_countries = df['country'].value_counts().nlargest(5)
ring = (Pie()# 略.....# 略......set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}", position="outside"))
)
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈
八个省份的葡萄酒数量
玫瑰图分析了前八个省份的葡萄酒数量。通过选取葡萄酒数量最多的八个省份,并在玫瑰图中进行展示,用户可以直观了解这些省份在葡萄酒生产中的重要地位。这种分析有助于揭示主要葡萄酒生产区域的分布情况,为区域市场分析和策略制定提供参考。
top_provinces = df['province'].value_counts().nlargest(8)
rose = (Pie().add("", [list(z) for z in zip(top_provinces.index.tolist(), top_provinces.tolist())], radius=["30%", "75%"], rosetype="radius")# 略.....# 略.....
)

👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 葡萄酒 ” 获取。👈👈👈
这篇关于【python】python葡萄酒国家分布情况数据分析pyecharts可视化(源码+数据集+论文)【独一无二】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



