本文主要是介绍预训练是什么?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
预训练是什么?
图像领域的预训练
在介绍图像领域的预训练之前,我们首先介绍下卷积神经网络(CNN),CNN 一般用于图片分类任务,并且CNN 由多个层级结构组成,不同层学到的图像特征也不同,越浅的层学到的特征越通用(横竖撇捺),越深的层学到的特征和具体任务的关联性越强(人脸-人脸轮廓、汽车-汽车轮廓)

由此,当领导给我们一个任务:阿猫、阿狗、阿虎的图片各十张,然后让我们设计一个深度神经网络,通过该网络把它们三者的图片进行分类。
对于上述任务,如果我们亲手设计一个深度神经网络基本是不可能的,因为深度学习一个弱项就是在训练阶段对于数据量的需求特别大,而领导只给我们合计三十张图片,显然这是不够的。
虽然领导给我们的数据量很少,但是我们是否可以利用网上现有的大量已做好分类标注的图片,比如 ImageNet 中有 1400 万张图片,并且这些图片都已经做好了分类标注。
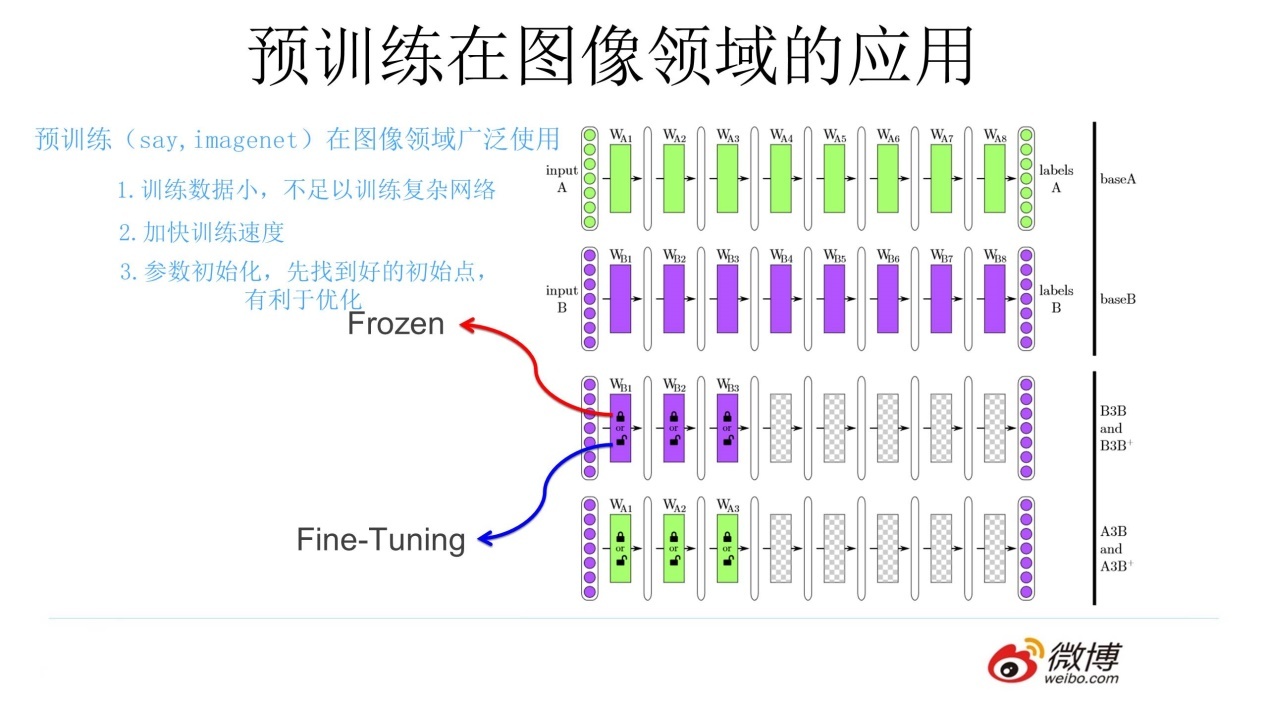
上述利用网络上现有图片的思想就是预训练的思想,具体做法就是:通过 ImageNet 数据集我们训练出一个模型 A,由于上面提到 CNN 的浅层学到的特征通用性特别强,可以对模型 A 做出一部分改进得到模型 B(两种方法):
-
冻结:浅层参数使用模型 A 的参数,高层参数随机初始化,浅层参数一直不变,然后利用领导给出的 30 张图片训练参数
-
微调:浅层参数使用模型 A 的参数,高层参数随机初始化,然后利用领导给出的 30 张图片训练参数,但是在这里浅层参数会随着任务的训练不断发生变化
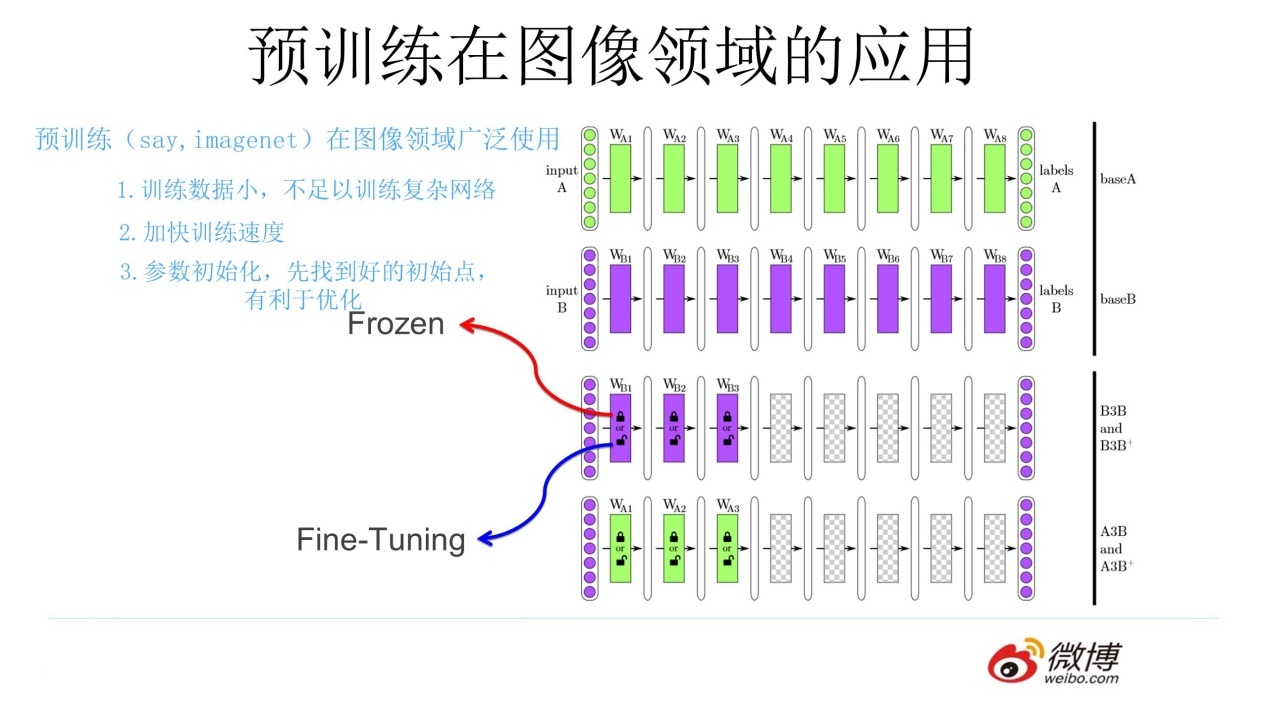
通过上述的讲解,对图像预训练做个总结(可参照上图):对于一个具有少量数据的任务 A,首先通过一个现有的大量数据搭建一个 CNN 模型 A,由于 CNN的浅层学到的特征通用性特别强,因此在搭建一个 CNN 模型 B,其中模型 B 的浅层参数使用模型 A 的浅层参数,模型 B 的高层参数随机初始化,然后通过冻结或微调的方式利用任务 A 的数据训练模型 B,模型 B 就是对应任务 A 的模型。
预训练的思想
有了图像领域预训练的引入,我们在此给出预训练的思想:任务 A 对应的模型 A 的参数不再是随机初始化的,而是通过任务 B 进行预先训练得到模型 B,然后利用模型 B 的参数对模型 A 进行初始化,再通过任务 A 的数据对模型 A 进行训练。注:模型 B 的参数是随机初始化的。
案例
要去做一个猫狗分类任务,但只给100 张猫和狗的图片去进行模型训练,然后给一张图片让分出是猫还是狗,这样的问题是无法解决的,因为只有一百张图片训练出的模型,精度是非常的低的精度很低
但是,假设这时候知道个,有人做过的通过10w 张鹅和鸭的图片做了一个模型 A
因为原理上来说,深度学习模型的浅层是通用的(都是横竖撇捺)
模型 A,10w个鹅和鸭训练的模型,有100 层的 CNN
任务 B:100 张猫和狗的图片,分类 --》 通过冻结(浅层参数不变)和微调(浅层参数会跟着任务 B 训练而改变),尝试使用 A 的前 50 /100 层去完成任务 B
总结
练而改变),尝试使用 A 的前 50 /100 层去完成任务 B
总结
一个任务 A,一个任务 B,两者极其相似,任务 A 已经训练处一个模型 A,使用模型 A 的浅层参数去训练任务 B,得到模型 B
这篇关于预训练是什么?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!