本文主要是介绍数据结构(C语言版)-第一章绪论,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.1 什么是数据结构
数据结构是计算机科学中一个核心概念,它涉及到如何在计算机中有效地存储、组织和管理数据。数据结构的选择和设计直接影响到算法的效率和程序的性能。其基本要素包括数据元素(也称为节点或记录)、数据元素之间的关系,以及在此基础上定义的各种操作。
具体来说,数据结构可以分为以下几个关键方面:
- 逻辑结构:这是对数据元素之间逻辑关系的抽象描述,不依赖于数据在计算机中的实际存储方式。逻辑结构主要有以下几种类型:
- 线性结构:数据元素之间存在一对一的关系,如数组、链表、栈和队列。
- 树形结构:数据元素之间存在一对多的关系,如同一棵树的分支,如二叉树、堆等。
- 图形结构(或网状结构):数据元素之间存在多对多的关系,每个元素可以与多个其他元素相连,如无向图、有向图等。
- 物理结构(存储结构):指的是数据在计算机内存中的实际存储方式,这影响了数据的存取效率。常见的存储结构有顺序存储、链式存储、索引存储等。
- 数据运算:定义在特定数据结构上的操作,如查找、插入、删除、更新等。这些操作需要根据数据结构的特点来设计,以保证高效执行。
数据结构的重要性在于它能够帮助我们更好地组织大量数据,使得数据的存取、修改和搜索等操作更加高效。不同的应用场景会要求使用不同的数据结构,正确选择和设计数据结构是解决许多计算问题的关键。在计算机科学教育和实践中,数据结构是基础且核心的学科之一,对软件工程师、算法设计师等职业具有重要意义。
简单总结: 数据结构是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作等的学科。
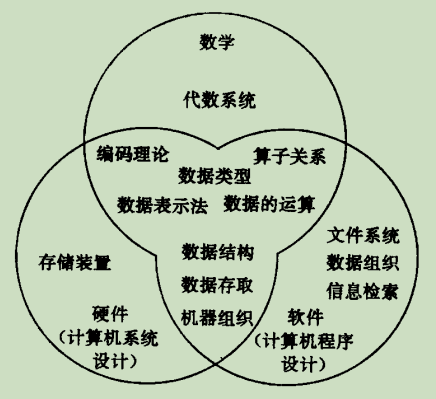
数据结构所处的位置
1. 2 基本概念和术语
-
数据 (Data): 是对客观事物的符号表示,是所有能被计算机处理的信息的总称。它可以是数字、字符、图像、声音等形式。
-
数据元素 (Data Element): 数据的基本单位,也是数据结构中的最小单位。它具有独立的意义,可以由一个或多个数据项组成。
-
数据项 (Data Item): 数据的不可分割的最小单位,是具有独立意义的最小数据单位。
-
数据对象 (Data Object): 具有相同性质的数据元素的集合。例如,所有学生的集合可以构成一个数据对象。
-
数据类型 (Data Type): 描述一组值的集合和可以在这组值上执行的操作的总称。数据类型分为原子类型和结构类型两大类。原子类型值不可再分,如整型、浮点型等;结构类型由基本类型或结构类型组合而成,如数组、结构体等。
-
抽象数据类型 (Abstract Data Type, ADT): 是一个数学模型及定义在该模型上的一组操作。它隐藏了数据的表示细节,只暴露操作接口,使得数据结构的设计更加模块化和易于理解。
-
逻辑结构 (Logical Structure): 从逻辑关系上描述数据元素之间的关系,不涉及物理存储细节。逻辑结构可以分为线性结构(如数组、链表)和非线性结构(如树、图)。
-
物理结构 (Physical Structure): 数据在计算机内存中的实际存储方式,如顺序存储、链式存储等。
-
操作 (Operations): 定义在数据结构上的一系列操作,如查找、插入、删除等,它们是用来实现数据结构功能的方法。
-
算法 (Algorithm): 是解决问题的步骤和方法,是数据结构的灵魂。数据结构和算法设计紧密相关,高效的数据结构往往需要高效的算法来配合使用。
-
多形数据类型 (polymorphic data type) , 是指其值的成分不确定的数据类型。例如,例
1-6 中定义的抽象数据类型 Triplet, 其元素 el e2 e3 可以是整数或字符或字符串,甚
至更复杂地由多种成分构成(只要能进行关系运算即可)。然而,不论其元素具有何种特
性,元素之间的关系相同,基本操作也相同。从抽象数据类型的角度看,具有相同的数学
抽象特性,故称之为多形数据类型。显然,需借助面向对象的程序设计语言如 C++ 等实
现之。本书中讨论的各种数据类型大多是多形数据类型,限于本书采用类 语言作为描
述工具,故只讨论含有确定成分的数据元素的情况。如例 1-6 中的 ElemSet 是某个确定
的、将由用户自行定义的、含某个关系运算的数据对象。
这些概念构成了数据结构研究的基础,理解它们有助于深入学习各种复杂的数据结构及其应用。
例如: 1-6 抽象数据类型三元组的定义:
ADT Triplet
{数据对象 (Data Objects): 表示ADT所包含的数据元素的集合。对于一个三元组ADT,数据对象可以被定义为集合D = {e1, e2, e3 | e1, e2, e3 ∈ ElemSet},这意味着三元组包含三个元素e1、e2、e3,这些元素都来自于某个特定的元素集合ElemSet。数据关系 (Data Relationships): 描述数据元素之间存在的特定关系。在三元组的上下文中,数据关系可能体现为元素之间的逻辑联系或排序规则,例如,可能为空集(意味着没有直接定义的关系),也可能定义特定的比较关系(如e1 < e2,e2 > e3等),这取决于ADT的具体应用场景。基本操作 (Basic Operations): 是定义在数据对象上的操作集,用于实现ADT的功能。对于三元组ADT,基本操作可能包括但不限于:Ini Triplet(&r.T, vl, v2, v3) 操作结果:构造了三元组 T, 元素 el,e2 e3 分别被赋以参数 vl,v2 v3 的值。DestroyTriplet(&r.T) 操作结果:三元组 被销毁。Get(T, i, &r.e) 初始条件:三元组 已存在, l¾i¾3操作结果:用 返回 的第 元的值。Put(&r.T, i ,e) 初始条件:三元组 已存在, l¾i¾3操作结果:改变 的第 元的值为IsAscending(T) 初始条件:三元组 已存在。操作结果:如果 个元素按升序排列,则返回 1, 否则返回IsDescending(T) 初始条件:三元组 已存在。操作结果:如果 个元素按降序排列,则返回 1, 否则返回Max(T, &r.e) 初始条件:三元组 已存在。操作结果:用 返回 个元素中的最大值。Min(T, &r.e) 初始条件:三元组 已存在。操作结果:用 返回 个元素中的最小值。
}ADT Triplet
案例代码
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h> // 定义三元组结构体
typedef struct {int first;int second;int third;
} Triplet;// 初始化三元组
Triplet* tripletCreate(int v1, int v2, int v3) {Triplet* t = (Triplet*)malloc(sizeof(Triplet));if(t) {t->first = v1;t->second = v2;t->third = v3;}return t;
}// 销毁三元组(释放内存)
void tripletDestroy(Triplet* t) {free(t);
}// 获取元素
int tripletGetElement(const Triplet* t, int index) {if(!t) return -1;switch(index) {case 1: return t->first;case 2: return t->second;case 3: return t->third;default: return -1; // 或者可以抛出错误}
}// 检查是否升序
bool tripletIsAscending(const Triplet* t) {return t && (t->first <= t->second && t->second <= t->third);
}// 检查是否降序
bool tripletIsDescending(const Triplet* t) {return t && (t->first >= t->second && t->second >= t->third);
}// 获取最大值
int tripletGetMax(const Triplet* t) {return t ? (t->first > t->second ? (t->first > t->third ? t->first : t->third) : (t->second > t->third ? t->second : t->third)) : -1;
}// 获取最小值
int tripletGetMin(const Triplet* t) {return t ? (t->first < t->second ? (t->first < t->third ? t->first : t->third) : (t->second < t->third ? t->second : t->third)) : -1;
}int main() {Triplet* t = tripletCreate(3, 2, 1);printf("Max: %d, Min: %d\n", tripletGetMax(t), tripletGetMin(t));printf("Is Ascending: %s\n", tripletIsAscending(t) ? "Yes" : "No");printf("Is Descending: %s\n", tripletIsDescending(t) ? "Yes" : "No");tripletDestroy(t);return 0;
}
1. 3 抽象数据类型的表示与实现
简单的C语言代码, 省略…
1. 4 算法和算法分析
1. 4. 1 算法
算法 (algorithm) 是对特定问题求解步骤的一种描述,它是指令的有限序列,其中每
一条指令表示一个或多个操作;此外,一个算法还具有下列 个重要特性:
(1) 有穷性 一个算法必须总是(对任何合法的输入值)在执行有穷步之后结束,且每一步都可在有穷时间。内完成。
(2) 确定性 算法中每一条指令必须有确切的含义,读者理解时不会产生二义性。并且,在任何条件下,算法只有惟一的一条执行路径,即对千相同的输入只能得出相同的输出。
(3) 可行性 一个算法是能行的,即算法中描述的操作都是可以通过已经实现的基本运算执行有限次来实现的。
(4) 输入 一个算法有零个或多个的输入,这些输入取自于某个特定的对象的集合。
(5) 输出 一个算法有一个或多个的输出,这些输出是同输入有着某些特定关系的量。
1. 4. 2 算法设计的要求
通常设计一个“好”的算法应考虑达到以下目标。
-
正确性 (Correctness): 算法必须能够产生正确的结果,对于所有合法的输入都能得出预期的输出。这是算法设计的最基本要求。
-
效率 (Efficiency):
- 时间效率 (Time Efficiency): 算法执行的时间应尽可能短。常用大O符号(O(n))来分析算法的时间复杂度,追求在最坏情况下的最优或近似最优解。
- 空间效率 (Space Efficiency): 算法使用的内存或其他资源应尽量少。空间复杂度同样可以用大O符号来衡量。
-
可读性 (Readability): 算法应易于理解,以便于其他人阅读和维护。良好的命名规范、清晰的逻辑结构和必要的注释都是提高可读性的关键。
-
健壮性 (Robustness): 算法应对非法输入或异常情况有妥善处理,避免崩溃或产生误导性结果。合理的错误处理和边界条件检查是增强健壮性的常见手段。
-
效率与低存傩量需求: 通俗地说戈效率指的是算法执行的时间。对于同一个问
题如果有多个算法可以解决,执行时间短的算法效率高。存储量需求指算法执行过程中
所需要的最大存储空间。效率与低存储量需求这两者都与问题的规模有关。求 100 个人
的平均分与求 1000 个人的平均分所花的执行时间或运行空间显然有一定的差别。
扩展的一些要求:
-
可扩展性 (Scalability): 随着输入规模的增长,算法仍能有效工作。好的算法设计应考虑到数据量增加时的性能表现。
-
通用性/灵活性 (Generality/Flexibility): 算法应尽可能设计得通用,以便于稍作调整就能应用于相似问题的不同场景。
-
模块化 (Modularity): 复杂的算法应分解成多个小的、相互独立的模块,每个模块完成单一任务,便于理解、测试和重用。
-
可验证性 (Verifiability): 算法的结果应该是可验证的,即存在一种方法可以证明算法对于任何给定的输入都产生了正确的输出。
-
最优性 (Optimality): 在某些情况下,追求算法的最优解,如在最短路径问题中寻找最短路径,或者在搜索问题中寻找最少步数的解决方案。
遵循这些原则,结合具体问题的特性,可以帮助设计出既高效又实用的算法。在实际应用中,需要根据具体情况权衡各项要求,有时可能需要牺牲某一方面的性能以换取其他方面的优势。
1. 4. 3 算法效率的度量
算法执行时间需通过依据该算法编制的程序在计算机上运行时所消耗的时间来度
量。而度量一个程序的执行时间通常有两种方法。
(1) 事后统计的方法 因为很多计算机内部都有计时功能,有的甚至可精确到毫秒
级,不同算法的程序可通过一组或若干组相同的统计数据以分辨优劣。但这种方法有两
个缺陷:一是必须先运行依据算法编制的程序;二是所得时间的统计量依赖于计算机的硬
件、软件等环境因素,有时容易掩盖算法本身的优劣。因此人们常常采用另一种事前分析
估算的方法。
(2) 事前分析估算的方法 一个用高级程序语言编写的程序在计算机上运行时所消
耗的时间取决于下列因素:
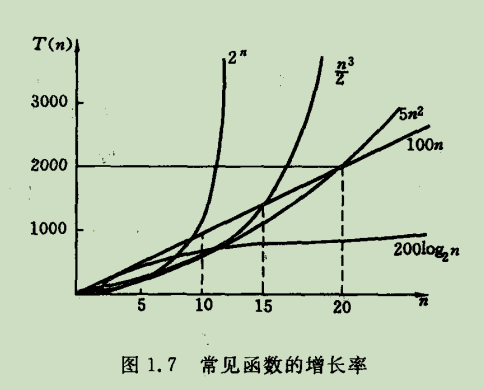
1. 依据的算法选用何种策略; 2. 问题的规模,例如求 100 以内还是 1000 以内的素数;3. 书写程序的语言,对千同一个算法,实现语言的级别越高,执行效率就越低; 4. 编译程序所产生的机器代码的质量; 5. 机器执行指令的速度。
一般情况下,对一个问题(或一类算法)只需选择一种基本操作来讨论算法的时间复杂度即可,有时也需要同时考虑几种基本操作,甚至可以对不同的操作赋予不同权值,以
反映执行不同操作所需的相对时间,这种做法便于综合比较解决同一问题的两种完全不
同的算法。
1. 4. 4 算法的存储空间需求
类似于算法的时间复杂度,本书中以空间复杂度 (space complexity) 作为算法所需存
储空间的量度,记作
S(n) = O(f(n)) 0-6.)
其中 为问题的规模(或大小)。一个上机执行的程序除了需要存储空间来寄存本身所用
指令、常数、变量和输入数据外,也需要一些对数据进行操作的工作单元和存储一些为实
现计算所需信息的辅助空间。若输入数据所占空间只取决于问题本身,和算法无关,则只
需要分析除输入和程序之外的额外空间,否则应同时考虑输入本身所需空间(和输入数据
的表示形式有关)。若额外空间相对于输入数据量来说是常数,则称此算法为原地工作.
拓展的学习内容
- 数据结构这个概念被扩充到包括网络、集合代数论、格、关系等方面,从而变成了现在称之为《离散结构》的内容。
- 1968 年美国唐· 欧· 克努特教授开创了“数据结构”的最初体系,他所著的《计算机程序设计技巧》第一卷《基本算法》是第一本较系统地阐述数据的逻辑结构和存储结构及其操作的著作。
这篇关于数据结构(C语言版)-第一章绪论的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








