本文主要是介绍《Python 机器学习》作者新作:从头开始构建大型语言模型,代码已开源,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ChatGPT狂飙160天,世界已经不是之前的样子。
更多资源欢迎关注

自 ChatGPT 发布以来,大型语言模型(LLM)已经成为推动人工智能发展的关键技术。
近期,机器学习和 AI 研究员、畅销书《Python 机器学习》作者 Sebastian Raschka 又写了一本新书 ——《Build a Large Language Model (From Scratch)》,旨在讲解从头开始构建大型语言模型的整个过程,包括如何创建、训练和调整大型语言模型。

最近,Sebastian Raschka 在 GitHub 上开源了这本新书对应的代码库。
项目地址:https://github.com/rasbt/LLMs-from-scratch/tree/main?tab=readme-ov-file
对 LLM 来说,指令微调能够有效提升模型性能,因此各种指令微调方法陆续被提出。Sebastian Raschka 发推重点介绍了项目中关于指令微调的部分,其中讲解了:
-
如何将数据格式化为 1100 指令 - 响应对;
-
如何应用 prompt-style 模板;
-
如何使用掩码。

《Build a Large Language Model (From Scratch)》用清晰的文字、图表和示例解释每个阶段,从最初的设计和创建,到采用通用语料库进行预训练,一直到针对特定任务进行微调。
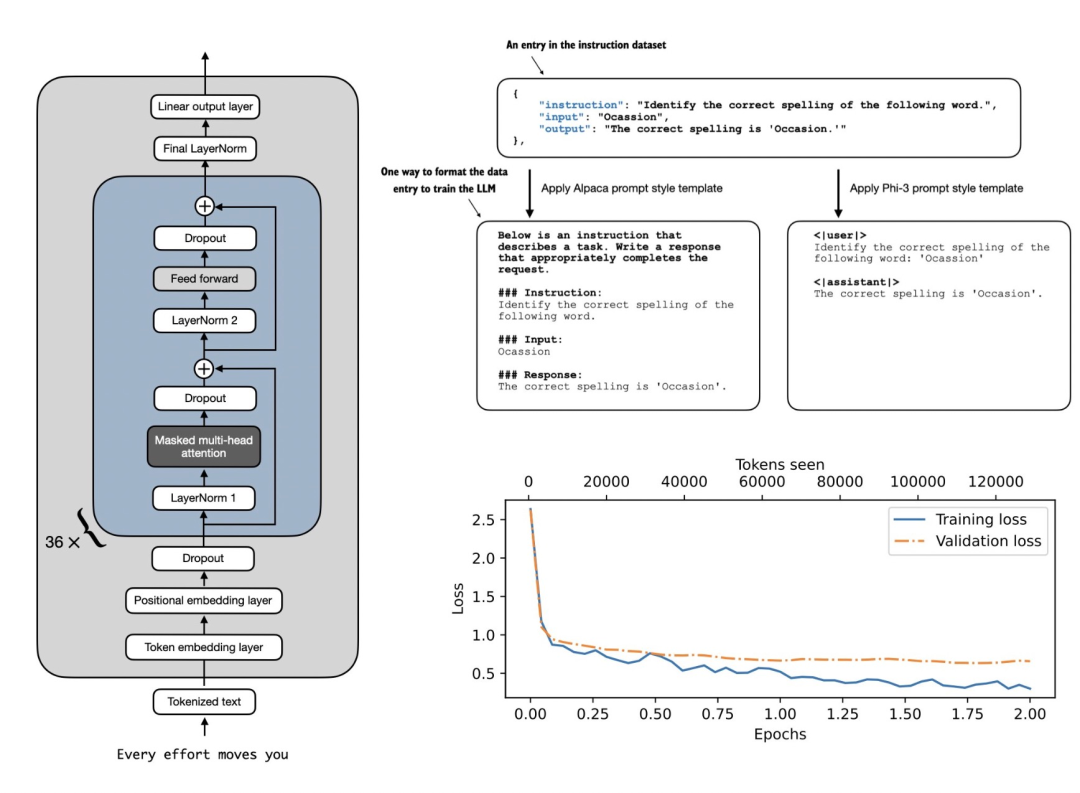
具体来说,新书和项目讲解了如何:
-
规划和编码 LLM 的所有部分;
-
准备适合 LLM 训练的数据集;
-
使用自己的数据微调 LLM;
-
应用指令调整方法来确保 LLM 遵循指令;
-
将预训练权重加载到 LLM 中。
作者介绍

个人主页:https://sebastianraschka.com/
Sebastian Raschka 是一名机器学习和人工智能研究员,曾在威斯康星大学麦迪逊分校担任统计学助理教授,专门研究深度学习和机器学习。他让关于 AI 和深度学习相关的内容更加容易获得,并教人们如何大规模利用这些技术。
此外,Sebastian 热衷于开源软件,十多年来一直是一个充满热情的开源贡献者。他提出的方法现已成功应用于 Kaggle 等机器学习竞赛。
除了编写代码,Sebastian 还喜欢写作,并撰写了畅销书《Python Machine Learning》(《Python 机器学习》)和《Machine Learning with PyTorch and ScikitLearn》。
这篇关于《Python 机器学习》作者新作:从头开始构建大型语言模型,代码已开源的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





