本文主要是介绍航行在水域:使用数据湖构建生产级 RAG 应用程序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

在 2024 年年中,创建一个令人印象深刻和兴奋的 AI 演示可能很容易。需要一个强大的开发人员,一些聪明的提示实验,以及一些对强大基础模型的API调用,你通常可以在一个下午建立一个定制的AI机器人。添加一个像 langchain 或 llamaindex 这样的库,使用 RAG 来增强您的LLM一些自定义数据 - 一个下午的工作可能会变成一个周末项目。
然而,投入生产是另一回事。您将需要一个可靠、可观察、可调和高性能的大规模系统。必须超越人为的演示场景,并考虑应用程序对代表所有实际客户行为的更广泛提示的响应。可能需要LLM访问丰富的特定领域知识语料库,而这些知识通常不存在于其预训练数据集中。最后,如果您将 AI 应用于准确性很重要的用例,则必须检测、监控和减轻幻觉。
虽然解决所有这些问题可能看起来令人生畏,但通过将基于 RAG 的应用程序解构为各自的概念部分,然后根据需要采取有针对性的迭代方法来改进每个部分,它变得更加易于管理。这篇文章将帮助您做到这一点。在本文中,我们将专门关注用于创建 RAG 文档处理管道的技术,而不是在检索时下游发生的技术。在此过程中,我们的目标是帮助生成式 AI 应用程序开发人员更好地为从原型到生产的旅程做好准备。
现代数据湖:AI 基础设施的重心
人们常说,在人工智能时代,数据是你的护城河。为此,构建生产级 RAG 应用程序需要合适的数据基础架构来存储、版本控制、处理、评估和查询构成专有语料库的数据块。由于 MinIO 采用数据优先的 AI 方法,因此对于此类项目,我们默认的初始基础结构建议是设置现代数据湖和向量数据库。虽然在此过程中可能需要插入其他辅助工具,但这两个基础架构单元是基础。它们将作为随后在将 RAG 应用程序投入生产时遇到的几乎所有任务的重心。
可以在此处找到基于 MinIO 构建的现代数据湖参考架构。此处提供了介绍此架构如何支持所有 AI/ML 工作负载的配套文件。
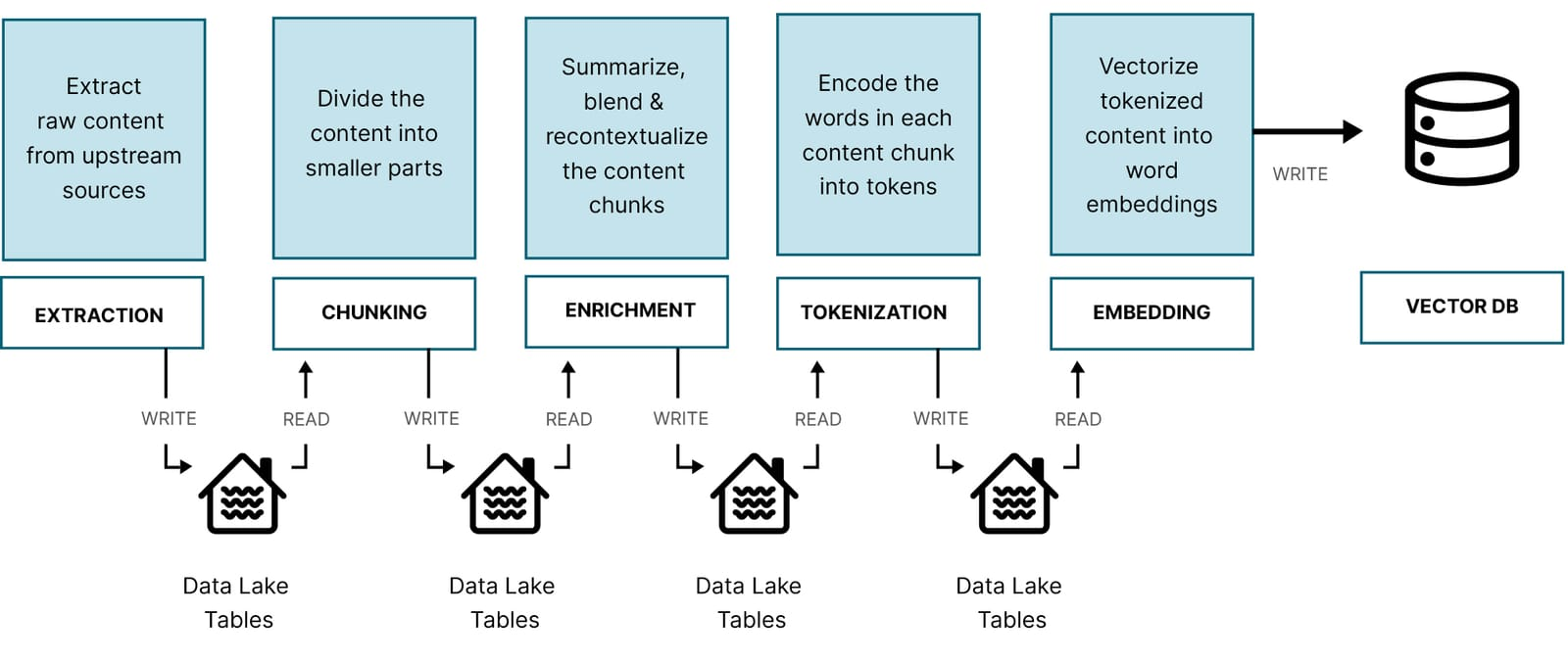
RAG:文档管道步骤
评估
构建生产级 RAG 应用程序的一个关键早期步骤是建立一个评估框架 - 通常简称为 evals。如果没有评估,您将无法可靠地了解系统的性能,知道哪些组件需要调整,或确定您是否取得了真正的进展。此外,evals 还充当强制函数,用于澄清您尝试解决的问题。以下是一些最常见的评估技术:
-
基于代码的启发式评估 - 使用各种度量(如输出令牌计数、关键字存在/不存在、JSON 有效性等)以编程方式对输出进行评分。这些通常可以使用常规单元测试的正则表达式和断言库进行确定性评估。
-
基于代码的算法评估 - 使用各种著名的数据科学指标对输出进行评分。例如,通过将提示重构为排名问题,您可以使用推荐系统中的常用评分函数,例如归一化贴现累积增益 (NDCG) 或平均倒数排名 (MRR)。相反,如果提示可以被描述为分类问题,那么精度、召回率和 F1 分数可能是合适的。最后,您可以使用 BLEU、ROUGE 和语义答案相似性 (SAS) 等度量将语义输出与已知的基本事实进行比较。
-
基于模型的评估 - 使用一个模型对另一个模型的输出进行评分,详见 Judging LLM-as-a-Judge 论文。这种技术越来越受欢迎,而且比人类的规模化要便宜得多。然而,在将项目从原型转移到生产的初始阶段,可靠地实施可能很棘手,因为在这种情况下,评估者LLM经常受到与底层系统本身类似的限制和偏见的影响。密切关注该领域的研究、工具和最佳实践,因为它们正在快速发展。
-
人工评估 - 要求人工领域专家提供他们的最佳答案通常是黄金标准。尽管这种方法既缓慢又昂贵,但不应忽视它,因为它对于获得洞察力和构建初始评估数据集非常宝贵。如果您想从所执行的工作中获得额外的里程,您可以使用 AutoEval Done Right 论文中详述的技术,用合成变体来补充您的人类专家生成的评估。
在决定使用哪种评估技术的同时,请考虑创建自定义基准评估数据集 - 通常用于 Hugging Face 排行榜(如 MMLU 数据集)的通用数据集。自定义评估数据集将包含各种提示及其理想响应,这些响应是特定于域的,并代表您的实际客户将输入到您的应用程序中的提示类型。理想情况下,人类专家可以协助创建评估数据集,但如果没有,请考虑自己做。如果你没有信心猜测可能出现什么提示,只需形成一个操作假设,然后继续前进,就好像它已经被验证了一样。随着更多数据的出现,您可以不断修改您的假设。
请考虑对 eval 数据集中每一行的输入提示应用约束,以便LLM答案具有具体的判断类型:二进制、分类、排名、数字或文本。混合判断类型将使您的评估值保持合理变化并减少输出偏差。Ceteris paribus,评估测试用例越多越好;但是,建议在此阶段关注质量而不是数量。最近在 LIMA: Less is More For Alignment 论文中对LLM微调的研究表明,即使是 1000 行的小型 eval 数据集也可以显着提高输出质量,前提是它们是真正更广泛人群的代表性样本。在 RAG 应用程序中,我们观察到使用由数十到数百行组成的 eval 数据集的性能改进。
虽然您可以临时开始手动运行评估,但在实施 CI/CD 管道以自动执行评估评分流程之前,请不要等待太久。每天运行 eval 或在连接到源代码存储库和可观测性工具的触发器上运行 eval 通常被视为 ML-ops 最佳实践。考虑使用开源 RAG 评估框架(如 ragas 或 DeepEval)来帮助您快速启动和运行。将数据湖用作包含版本化评估数据集和每次执行评估时生成的各种输出指标的表的真实来源。这些数据将提供有价值的见解,以便在项目后期使用,以进行战略性和高度针对性的改进。
数据提取器
您最初开始原型设计的 RAG 语料库很少足以让您投入生产。您可能需要不断使用其他数据来增强您的语料库,LLM以帮助减少幻觉、遗漏和有问题的偏见类型。这通常是通过构建提取器和加载器来逐案完成的,这些提取器和加载器将上游数据转换为可在下游文档管道中进一步处理的格式。
虽然试图通过收集比您需要的更多的数据来煮沸海洋的风险很小,但必须具有创造力并跳出框框思考您的公司可以访问的高质量信息来源。显而易见的可能性可能包括从存储在公司 OLTP 和数据仓库中的结构化数据中提取见解。还应考虑公司博客文章、白皮书、已发表的研究和客户支持查询等来源,前提是它们可以适当匿名化并清除敏感信息。向语料库中添加哪怕是少量高质量的域内数据,也很难夸大其性能的积极影响,所以不要害怕花时间探索、试验和迭代。以下是一些常用于引导高质量域内语料库的技术:
-
文档提取 - 专有 PDF、办公文档、演示文稿和 Markdown 文件可以成为丰富的信息来源。一个由开源和 SaaS 工具组成的庞大生态系统可用于提取这些数据。通常,数据提取器是特定于文件类型(JSON、CSV、docx 等)、基于 OCR 或由机器学习和计算机视觉算法提供支持的。从简单开始,仅根据需要增加复杂性。
-
API 提取 - 公共和私有 API 可以是域内知识的丰富来源。此外,精心设计的基于 JSON 和 XML 的 Web API 已经具有一些内置结构,可以更轻松地在有效负载中执行有针对性的相关属性提取,同时丢弃任何被认为不相关的内容。一个由经济实惠的低代码和无代码 API 连接器组成的庞大生态系统可以帮助您避免为希望使用的每个 API 编写自定义 ETL——如果没有专门的数据工程师团队,这种方法可能难以维护和扩展。
-
Web Scrapers - 网页被认为是具有树状 DOM 结构的半结构化数据。如果你知道你要找什么信息,它在哪里,以及它所在的页面布局,你可以快速构建一个抓取工具来使用这些数据,即使没有一个有据可查的API。存在许多脚本库和低代码工具,为网络抓取提供有价值的抽象。
-
网络爬虫 - 网络爬虫可以遍历网页并构建递归 URL 列表。此方法可以与抓取结合使用,以根据您的条件扫描、汇总和过滤信息。在更大的范围内,这种技术可用于创建您自己的知识图谱。
-
无论您使用何种技术进行数据收集,都要抵制构建一次性脚本的冲动。相反,应用数据工程最佳做法,将提取器部署为可重复且容错的 ETL 管道,将数据降落在数据湖内的表中。确保每次运行这些管道时(源 URL 和提取时间等关键元数据元素)都会被捕获并标记在每条内容旁边。事实证明,元数据捕获对于下游数据清理、过滤、重复数据删除、调试和归因非常有价值。
分块
分块将大型文本样本减少为较小的离散片段,这些片段可以放入 LLM的上下文窗口中。虽然上下文窗口越来越大(允许在推理过程中填充更多内容块),但分块仍然是在准确性、召回率和计算效率之间取得适当平衡的重要策略。
有效的分块需要选择适当的块大小。较大的块大小往往会保留一段文本的上下文和语义含义,但代价是允许上下文窗口中出现更少的总块。相反,较小的块大小将允许将更多离散的内容块填充到 LLM的上下文窗口中。但是,如果没有额外的护栏,每条内容在从其周围上下文中删除时都会面临质量降低的风险。

除了块大小之外,您还需要评估各种分块策略和方法。以下是一些需要考虑的标准分块方法:
-
固定大小策略 - 在这种方法中,我们只需为内容块选择固定数量的令牌,并相应地将内容解构为更小的块。通常,使用此策略时,建议在相邻块之间进行一些重叠,以避免丢失太多上下文。这是最直接的分块策略,通常是一个很好的起点,然后再进一步冒险进入更复杂的策略。
-
动态大小策略 - 此方法使用各种内容特征来确定块的启动和停止位置。一个简单的例子是标点符号分块器,它根据特定字符(如句点和新行)的存在来拆分句子。虽然标点符号块可能适用于简单的简短内容(即推文、字符限制的产品描述等),但如果用于更长和更复杂的内容,它将有明显的缺点。
-
内容感知策略 - 内容感知分块器根据要提取的内容和元数据的类型进行调整,并使用这些特征来确定每个块的开始和停止位置。例如,HTML 博客的分块器使用标题标记来划定块边界。另一个例子可能是一个语义分块器,它将每个句子的成对余弦相似度分数与其前面的邻居进行比较,以确定上下文何时发生了重大变化,足以保证描述一个新块。
RAG 应用程序的最佳分块策略需要根据LLM上下文窗口长度、底层文本结构、文本长度和语料库中内容的复杂性进行调整。对各种分块策略进行大量试验,并在每次更改后运行评估,以更好地了解给定策略的应用程序性能。在数据湖表中对分块内容进行版本控制,并确保每个分块都具有世系信息,以便从上游数据提取步骤中追溯到原始内容及其各自的元数据。
富 集
在许多情况下,在 RAG 期间为检索编制索引的内容块在上下文上与应用程序在生产中遇到的实际提示不同。例如,如果您正在构建一个 AI 问答机器人,您可能拥有庞大的专有信息语料库,其中包含大量客户查询的正确答案。然而,在原始形式中,你的语料库不太可能以问答对的形式预先组织,这对于基于相似性的嵌入检索是理想的。在此示例中,如果在检索时,我们天真地在语料库中搜索语义上与入站客户问题相似的原始内容块,则可能会遇到检索结果集的次优相关性。这是因为我们正在比较上下文不同的项目(即问题与答案)的相似性。幸运的是,解决方案相对简单:我们可以利用 LLMs 的力量来丰富我们可能的答案——也就是原始内容块——通过将它们重新置于假设问题中。然后,我们将这些假设问题索引到我们的向量数据库中,以便后续检索。此技术称为假设文档嵌入 (HyDE),说明了在文档处理管道中用于LLMs扩充数据的强大功能。下面是对已知squad_v2数据集中的某些内容使用此技术的示例:
System Prompt: Given the provided snippet of text, generate three hypothetical questions that could be asked about it. Each question must be able to be answered using the information within the referenced snippet of text and only that information. Be concise.User Prompt: “At the 52nd Annual Grammy Awards, Beyoncé received ten nominations, including Album of the Year for I Am... Sasha Fierce, Record of the Year for "Halo", and Song of the Year for "Single Ladies (Put a Ring on It)", among others. She tied with Lauryn Hill for most Grammy nominations in a single year by a female artist. In 2010, Beyoncé was featured on Lady Gaga's single "Telephone" and its music video. The song topped the US Pop Songs chart, becoming the sixth number-one for both Beyoncé and Gaga, tying them with Mariah Carey for most number-ones since the Nielsen Top 40 airplay chart launched in 1992. "Telephone" received a Grammy Award nomination for Best Pop Collaboration with Vocals.”Response: Here are some questions that could be asked based on the provided text:
* How many nominations did Beyoncé receive at the 52nd Annual Grammy Awards?
* For which album was Beyoncé nominated for Album of the Year at the 52nd Annual Grammy Awards?
* Which song earned Beyoncé a nomination for Record of the Year at the 52nd Annual Grammy Awards?如果使用由长格式和/或主题复杂内容组成的语料库,请考虑进行额外的预处理以预先总结内容块,从而降低其语义维度。在检索时,您可以查询块摘要的嵌入,然后将非摘要文本替换为上下文窗口插入。在对大型、复杂和/或经常变化的语料库进行 RAG 时,此方法可提高相关性。
代币化
2024 年的大型语言模型通常是基于 Transformer 的神经网络,它们本身无法理解书面文字。传入的原始文本被转换为标记,然后是针对矩阵乘法运算优化的高维嵌入向量。此入站过程通常称为编码。反向出站过程称为解码。许多人LLMs只会使用与他们训练相同的标记化方案进行推理。因此,了解所选代币化策略的基础知识至关重要,因为它可能会产生许多微妙的性能影响。
尽管有简单的字符和单词级标记化方案,但在撰写本文时,几乎所有最先进的LLMs方法都使用子单词标记器。因此,我们在这里只关注这一类分词器。
子字分词器递归地将单词分解为更小的单位。这使他们能够理解词汇外的单词,而不会过多地增加词汇量 - 这是训练表现和泛化到看不见的文本的能力LLM的关键考虑因素。
目前使用的一种流行的子字标记化方法是字节对编码 (BPE)。在高层次上,BPE 算法的工作方式如下:
-
将单词拆分为子单词单位的标记,并将其添加到词汇表中。每个标记表示一个子词,该子词由训练语料库中常见相邻字符模式的相对频率控制。
-
将上述步骤中的常见令牌对替换为表示该对的单个令牌,并将其添加到词汇表中。
-
递归地重复上述步骤。
BPE 标记化通常是 RAG 应用程序的一个很好的起点,因为它适用于许多用例。但是,假设您有大量高度专业化的领域语言,这些语言在用于所选模型的预训练语料库的词汇表中没有很好地表示。在这种情况下,请考虑研究替代的标记化方法,或者探索微调和低秩适应,这超出了本文的范围。上述受限词汇问题可能表现为在为医学、法律或晦涩的编程语言等专业领域构建的应用程序中性能不佳。更具体地说,它将在包含高度专业化的语言/行话的提示中普遍存在。根据需要,使用存储在数据湖中的 eval 数据集对不同的标记化方案及其各自的性能进行试验。请记住,分词器、嵌入和语言模型通常是紧密耦合的,因此更改其中一个可能需要更改其他模型。
结论
基于 MinIO 对象存储构建的现代数据湖 - 为自信地将基于 RAG 的应用程序投入生产提供了基础基础设施。这样一来,您就可以创建 eval 和特定于域的 eval 数据集,这些数据集可以在 Data Lake 表中存储和版本控制。使用这些评估,根据需要反复评估和增量改进 RAG 应用程序文档管道的每个组件(提取器、分块器、扩充和分词器),以构建生产级文档处理管道。
这篇关于航行在水域:使用数据湖构建生产级 RAG 应用程序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








