本文主要是介绍Studying-代码随想录训练营day17| 654.最大二叉树、617合并二叉树、700.二叉搜索树中的搜索、98.验证二叉树搜索树,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第十七天,二叉树part05,进一步学习二叉树💪
654.最大二叉树
文档讲解:代码随想录最大二叉树
视频讲解:手撕最大二叉树
题目:
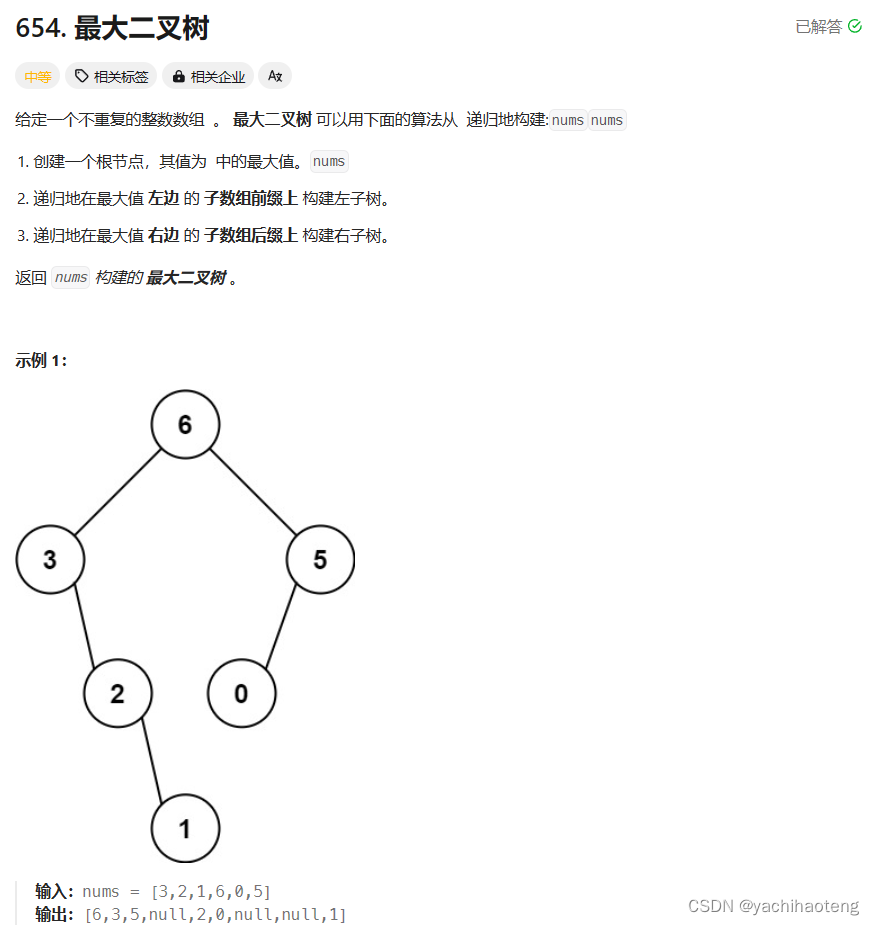
学习:本题与利用中序和后序序列构造二叉树有相同之处。依据题目要求,首先在数组里面找到最大值,作为根节点,然后划分左右区间对应根节点的左右子树。再分别在左右区间中找到最大值,作为根节点(中间节点),之后再次划分区间,进行下一轮循环。
代码:
//时间复杂度O(n^2)
//空间复杂度O(n^2)
class Solution {
public:TreeNode* constructMaximumBinaryTree(vector<int>& nums) {//终止条件if(nums.size() == 0) return nullptr;//单层递归逻辑//遍历数组中的最大值,作为根节点int index = 0; //保存下标for (int i = 0; i < nums.size(); i++) {if (nums[index] < nums[i]) index = i; //找到最大值下标}TreeNode* root = new TreeNode(nums[index]);//左区间vector<int> left(nums.begin(), nums.begin() + index);//右区间vector<int> right(nums.begin() + index + 1, nums.end());root->left = constructMaximumBinaryTree(left);root->right = constructMaximumBinaryTree(right);return root;}
};本题还可以采用下标的方式划分区间,避免创建一个新的数组。
代码:
//时间复杂度O(n^2)
//空间复杂度O(n)
class Solution {
private:// 在左闭右开区间[left, right),构造二叉树TreeNode* traversal(vector<int>& nums, int left, int right) {if (left >= right) return nullptr;// 分割点下标:maxValueIndexint maxValueIndex = left;for (int i = left + 1; i < right; ++i) {if (nums[i] > nums[maxValueIndex]) maxValueIndex = i;}TreeNode* root = new TreeNode(nums[maxValueIndex]);// 左闭右开:[left, maxValueIndex)root->left = traversal(nums, left, maxValueIndex);// 左闭右开:[maxValueIndex + 1, right)root->right = traversal(nums, maxValueIndex + 1, right);return root;}
public:TreeNode* constructMaximumBinaryTree(vector<int>& nums) {return traversal(nums, 0, nums.size());}
};注意:本题的终止条件不唯一,也可以判断nums.size() == 1,即找到叶子节点的时候终止判断。采取这种方式,递归的时候要注意不要把空区间传入函数当中。
617合并二叉树
文档讲解:代码随想录合并二叉树
视频讲解:手撕合并二叉树
题目:

学习:
- 本题主要在于两点:1.两个树需要同步进行遍历;2.每一步遍历的时候,进行两棵树,相同节点之间的判断。
- 判断过程中会出现三种情况:1.root1存在该节点,root2不存在,则可以把root1该节点包括该节点以下的所有节点加入创建的树中(root2该节点没有,这个节点以下的节点肯定就也没有);2.root2存在该节点,root1不存在,则可以把root2该节点包括该节点以下的所有节点加入创建的树中;3.root1和root2都存在该节点,则把两棵树该节点的val值相加,将该节点加入到树中,并继续向下遍历。
依据此,本题采用前序遍历最为合适,逻辑最清晰,当然采用别的遍历方式也都可以创建。
代码:
//时间复杂度O(min(m,n))
//空间复杂度O(min(m,n))
class Solution {
public:TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {//终止条件,当其中一颗树的节点为空时,返回另一棵树的所有节点,且不需要往下遍历了//注意两个树都为空的话,也是满足第一个判断条件,只不过返回的root2为空if (root1 == nullptr) return root2;if (root2 == nullptr) return root1;//确定单层递归条件,创建一个新的树TreeNode* root = new TreeNode(0);//前序遍历的方式,两个树同步进行遍历root->val = root1->val + root2->val;root->left = mergeTrees(root1->left, root2->left);root->right = mergeTrees(root1->right, root2->right);return root;}
};代码:迭代法也能够进行求解,创建两个队列,同步进行遍历即可。
class Solution {
public:TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) {if (t1 == NULL) return t2;if (t2 == NULL) return t1;queue<TreeNode*> que;que.push(t1);que.push(t2);while(!que.empty()) {TreeNode* node1 = que.front(); que.pop();TreeNode* node2 = que.front(); que.pop();// 此时两个节点一定不为空,val相加node1->val += node2->val;// 如果两棵树左节点都不为空,加入队列if (node1->left != NULL && node2->left != NULL) {que.push(node1->left);que.push(node2->left);}// 如果两棵树右节点都不为空,加入队列if (node1->right != NULL && node2->right != NULL) {que.push(node1->right);que.push(node2->right);}// 当t1的左节点 为空 t2左节点不为空,就赋值过去if (node1->left == NULL && node2->left != NULL) {node1->left = node2->left;}// 当t1的右节点 为空 t2右节点不为空,就赋值过去if (node1->right == NULL && node2->right != NULL) {node1->right = node2->right;}}return t1;}
};700.二叉搜索树中的搜索
文档讲解:代码随想录二叉搜索树中的搜索
视频讲解:手撕二叉搜索树中的搜索
题目:
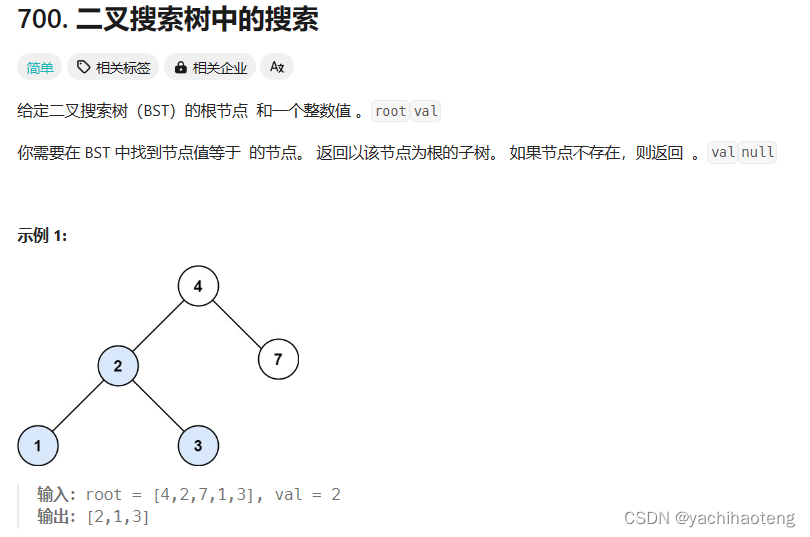
学习:二叉搜索树是二叉树中十分重要的一种类型,它的特点如下:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树。
依据这个特点,二叉搜索树和普通搜索树的遍历方式是不同的,二叉搜索树本身就自带了遍历的顺序 ,依据值的大小选择遍历的路径。
代码:
//时间复杂度O(n)
//空间复杂度O(n)
class Solution {
public:TreeNode* searchBST(TreeNode* root, int val) {//终止条件if(root == nullptr) return nullptr;//确定单层递归逻辑if (root->val == val) return root;else if (root->val > val) {return searchBST(root->left, val);}else {return searchBST(root->right, val);}}
};本题采取迭代法,可以更加的直观,因为本题不需要使用额外的数据结构,存储节点。
代码:
//时间复杂度O(n)
//空间复杂度O(1)
class Solution {
public:TreeNode* searchBST(TreeNode* root, int val) {while (root != NULL) {if (root->val > val) root = root->left;else if (root->val < val) root = root->right;else return root;}return NULL;}
};98.验证二叉搜索树
文档讲解:代码随想录验证二叉搜索树
视频讲解:手撕验证二叉搜索树
题目:
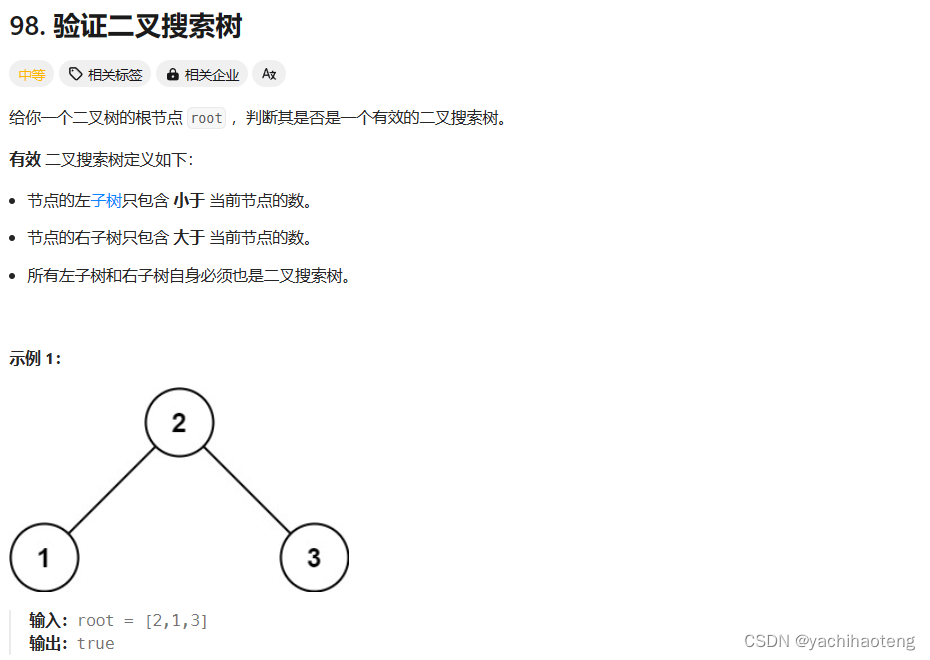
学习:本题可以利用到二叉搜索树一个重要的特性。由于二叉搜索树的特点,对二叉搜索树进行中序遍历,得到的数组是一个递增序列。
依据上序特点,我们可以通过中序遍历二叉树,把每个节点值加入到数组当中,最后判断数组是否是一个递增数组,如果是递增数组的话,则是一个二叉搜索树,否则就不是一个二叉搜索树。
代码:
//时间复杂度O(n)
//空间复杂度O(n)
class Solution {
private:vector<int> vec;void traversal(TreeNode* root) {if (root == NULL) return;traversal(root->left);vec.push_back(root->val); // 将二叉搜索树转换为有序数组traversal(root->right);}
public:bool isValidBST(TreeNode* root) {vec.clear(); // 不加这句在leetcode上也可以过,但最好加上traversal(root);for (int i = 1; i < vec.size(); i++) {// 注意要小于等于,搜索树里不能有相同元素if (vec[i] <= vec[i - 1]) return false;}return true;}
};采取这种方法比较直观,但事实上我们在中序遍历的过程中,就可以进行前后两个节点之间值的大小判断了,只要遍历过程中,存在前节点的值小于后节点的值,则说明不是二叉搜索树,直到遍历完所有的节点。
代码:注意这里要初始化一个最小值,由于本题给出的最小值能够达到INT_MIN,所以我们要设置一个更小的值LONG_MIN。
class Solution {
public:long long compa = LONG_MIN; // 因为后台测试数据中有int最小值bool isValidBST(TreeNode* root) {if (root == nullptr) return true;bool left = isValidBST(root->left);//中序遍历,验证遍历的元素是不是从小到大if (compa >= root->val) return false;compa = root->val;bool right = isValidBST(root->right);return left && right;}
};本题也可以采用双指针的方法,一个指向前节点,一个指向后节点,这样能够避免设置最小值,增加鲁棒性,应对更多的情况。
//时间复杂度O(n)
//空间复杂度O(n)
class Solution {
public:TreeNode* pre = NULL; // 用来记录前一个节点bool isValidBST(TreeNode* root) {if (root == NULL) return true;bool left = isValidBST(root->left);if (pre != NULL && pre->val >= root->val) return false;pre = root; // 记录前一个节点bool right = isValidBST(root->right);return left && right;}
};总结
今天主要是对树的理解进一步加强,同时学习到如何运用一个二叉树中的重要类别二叉搜索树。
这篇关于Studying-代码随想录训练营day17| 654.最大二叉树、617合并二叉树、700.二叉搜索树中的搜索、98.验证二叉树搜索树的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




