本文主要是介绍论文辅导 | 基于K-means聚类和ELM神经网络的养殖水质溶解氧预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
辅导文章

模型描述
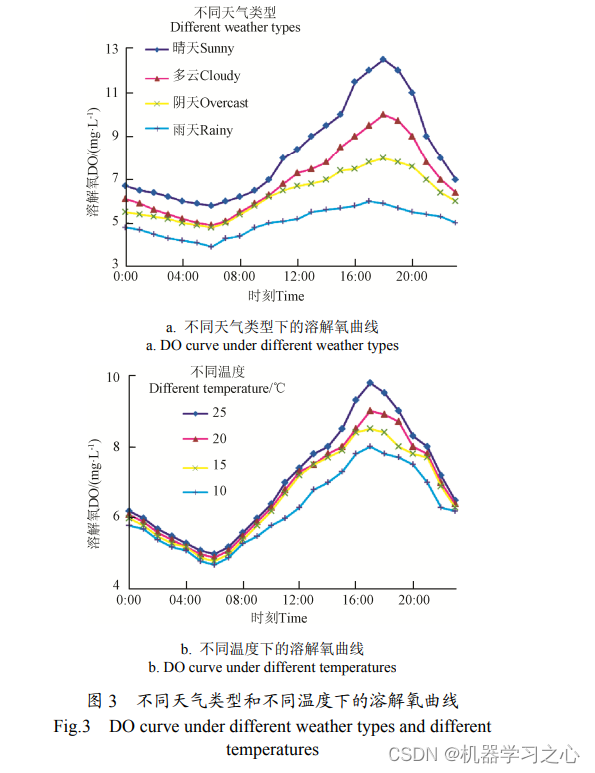
1)相似度统计量构造。数据归一化后,利用皮尔森相关系数确定环境因子权重,构造相似日的统计量-相似度。
2)K-means 聚类。根据相似度应用 K-means 聚类法对历史日数据样本聚类,找出合适样本,使得历史日样本被分为若干类。
3)预测日所属类别识别。以相似度最大的类别作为预测日的类别,形成训练样本。
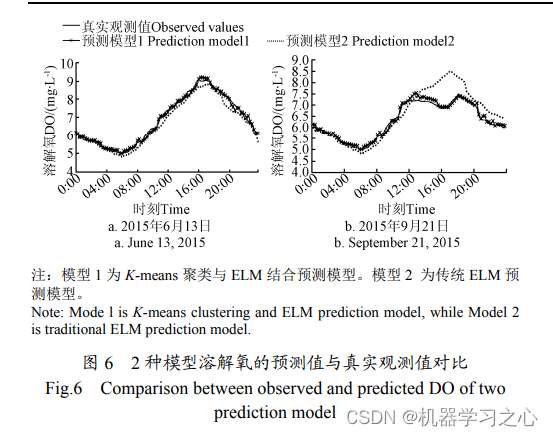
4)ELM 神经网络建模与预测。利用训练样本建立ELM 神经网络模型,利用测试样本对模型进行验证。最后,经过补偿及反归一化过程得出最后预测值。

预测效果
这篇关于论文辅导 | 基于K-means聚类和ELM神经网络的养殖水质溶解氧预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)