本文主要是介绍面向黑灰产治理的恶意短信变体字还原第6名方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

前段时间组织同学们参加了面向黑灰产治理的恶意短信变体字还原比赛,获得了第6名。方案如下:
赛题链接:面向黑灰产治理的恶意短信变体字还原 竞赛 - DataFountain
赛题任务描述:本任务类似于机器翻译,需要针对恶意短信中的变体字进行还原。恶意垃圾短信为了跳过安全检测会将字符变成变体的字符,需要采用深度学习建模的方法将测试集中新出现的短信变体字还原为正常信息文本,即不含有变体字、干扰字符,所有变体字部分应使用常见简体汉字、字符来表示,同时需要保证不包含变体字的正常文本不受影响。
比赛数据集示例:
变体句子:噂儆的碦戸:其鎃祝册茺贈镐888葒笣!禛朲对弈佰捆任你選!嶺:http://url.cn/5aLeqP2
还原后:尊敬的客户:棋牌注册充赠高888红包!真人对弈百款任你选!领:url.cn5aLeqP2
比赛评测方案:
评测指标1:
BLEU得分:计算参赛团队处理后的还原文本与人工标注文本的BLEU值。
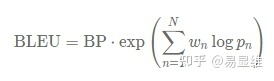
N=4,其中:

评测指标2:
f1值:指标按如下标准定义,变体字还原结果正确计为TP,变体字漏检计为FN,变体字还原错误或正常文字被错误还原计为FP。
比赛中会同时计算评测指标1和评测指标2,最终结果将二者得分相加计算平均值作为最终排名的得分。
模型要求:考虑到模型会在移动终端上使用,所以参赛团队在做算法选择时要综合考虑模型的资源占用和推理耗时,模型大小的上限不能超过400MB,CPU(Intel® Xeon® CPU E5-2630 v4 @ 2.20GHz)上的平均单条推理耗时不能超过300ms。最终模型大小和推理耗时会做为决赛成绩的加分项决定最终排名。
技术路线:
1.baseline:采用两层堆叠的transformer的Encoder作为基础模型,对编码后的文本进行特征提取。然后接分类层和softmax函数进行分类,分类的类别数为词表的大小,也就是进行字符级别的分类,预测每个字符最有可能被分类成哪一个字符。

2.输入输出对齐:因为是字符级别的分类,所以要求输入的input和输出的label必须长度一致,也就是对于输入的每个字符,都需要有相应的分类标签与之对应。但题目所给的训练数据的input和label并非长度一致的,因此需要一个文本对齐的方法。
文本对齐的方法是:遍历input和label中的字符,找出其中的同音或型近字,将同音/型近字进行一一对应,并将两对同音/型近字中间的部分进行对应,中间部分input的字符串和label中对应的字符串长度不一的,将较短的字符串使用空字符串补齐至长度和较长的字符串相同长度。
如何判断是否是同音/型近字:求出两个字的拼音/笔画的最长公共子串的长度,使用该长度除以较长字符串的长度得到音近/型近得分,根据设定的阈值来判断是否为音近/型近字。
3.特征构造:由于变体字中存在大量的同音字替换,因此在生成字的embedding时,同时生成了拼音的embedding,将两个embedding进行concat输入模型。Embedding是通过字和拼音训练后保存到本地的。
首先将一句话中每个字符转成数字序列,然后将其中的中文也全部转为,数字序列,对两个序列使用word2vec训练出嵌入向量,将字的向量和拼音的向量连接到一起,并保存到本地,一个字对应一个200维的Embedding。
4.循环构造训练数据,进行数据增强:首先通过固定长度的滑动窗口分别选中训练集和测试集的词语,根据笔画和拼音的最大公共子串的长度判断出是否是变体字,需要人工筛查一遍,创建出造错表。再使用边训练边造错的方法,使用0.85的概率从训练集中随机抽取训练数据进行训练,使用0.15的概率将训练集的label进行造错,每个句子造错不超过三个。这样尽可能地保证模型可以学到造错表所有的错误。
最终排名:

B榜成绩第8,提交代码后,主办方复现过程中,排名提升到第6。
这篇关于面向黑灰产治理的恶意短信变体字还原第6名方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






