本文主要是介绍M6-中文多模态预训练模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
M6:一种中文的多模式预训练机
目录:
-
回顾
-
方法
-
下游应用程序
-
可扩展到具有万亿个参数的模型
1. 回顾
多模态预训练
模型架构:
l 基于transformer
l 单流或者双流
图像特征:
l 目标特征
l Patch特征
l 原始像素
下游任务:
l 理解:VQA,检索
l 生成:图像字幕
对M6的预期
l 在中文语料库上的预训练模型
l 兼容理解和生成任务
l 与图像文本和明文任务兼容
l 与文本和图像生成兼容
2.方法
M6概述
规模:
Dense模型:0.3B参数量(M6-Base)/10B参数量(M6-Large)
Sparse MoE模型:M6-100B&M6-1T
动机:多模态+多任务(理解与生成)
结构:transformer Block
预训练:多任务预训练
M6结构:

M6 10B
l 添加图层并增加隐藏图层的大小
l 在分布式设备上拟合该模型的策略:
l 混合精度(O2级)
l 激活检查点
l 零优化器和零卸载
l 使用梯度积累来减少gpu之间的通信时间
M6 100B的挑战
-
如何降低沟通成本
-
GPU内存的限制(swap in/out, Zero, CPU offload)
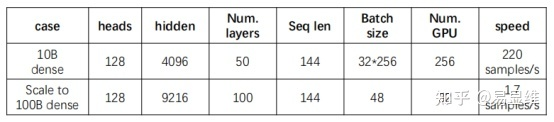


M6 100B
l 在whale框架上实现的
l 梯度校验点、XLA、通信优化、混合精度等。
l 128A100s上的1440个samples。
l 与M6-10B相比的LM损失使用了大约一半的训练时间


3. 下游应用
图像字幕

可视化QA

自然语言的下游任务

图象生成
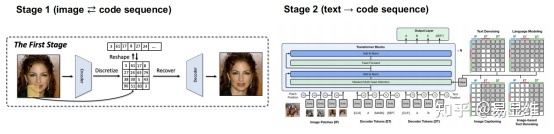
使用两阶段策略,根据输入文本生成图像:
阶段1训练一个VQGAN,将图像编码为破坏代码表示,并高保真地将代码序列解码回图像。
阶段2训练M6根据输入文本作为上下文生成代码序列。
用于文本到图像生成的M6

文本到图像的生成(反事实的)

4. 缩放到三百分之一模型
训练三百分之一模型:
资源:480 NVIDIA V100-32GB gpu
实现:由带宽为100gb的RDMA网络连接的单gpu工人集群。
优化:Adafactor (vs. Adam),为了避免训练的不稳定性,我们使用了较小的学习率和权值初始化
专家原型

辅助平衡损失是有帮助的吗?

辅助损失有助于平衡每个专家的分配,但对模型性能影响很大。为了节省向后内存成本,与Switch&Gshard相比,我们消除了辅助损失。
1t模型的有效性

与M6相关的Papers
M6-base, 10B & 100B: M6: A Chinese Multimodal Pretrainer (KDD 21’)
M6-1T: Exploring Sparse Expert Models and Beyond (arxiv)
Image generation: UFC-BERT: Unifying Multi-Modal Controls for Conditional Image Synthesis (arxiv)
这篇关于M6-中文多模态预训练模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







