本文主要是介绍机器学习案例|使用机器学习轻松预测信用卡坏账风险,极大程度降低损失,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01、案例说明
对于模型的参数,除了使用系统的设定值之外,可以进行再进一步的优化而得到更好的结果。RM提供了几种参数优化的方法,能够让整体模型的效率提高。而其使用的概念,仍然是使用计算机强大的计算能力,对于不同的参数组合进行准确度评估,使用硬算的方式选出最优的参数。这个也是机器学习里面的另外一个特点与优势。
本案例讨论的是:对于信用卡公司需要判断客户会不会变成坏账(Default),从而预先防范,比如降低信用额度或是加速催缴欠款,而减低未来可能损失的风险。可以使用现有数据中已知的结果建立模型之后,对于未知的数据进行模型预测。整体模型如下图所示:
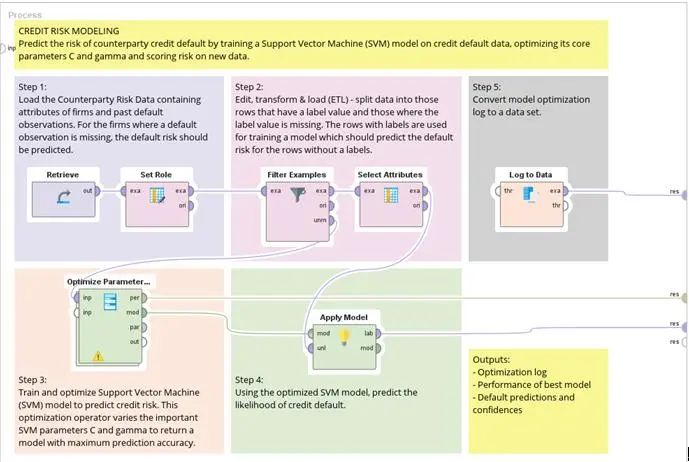
02、数据资料
做法仍然如同前面一样,先将数据读入之后,进行观察。共有424个数据值,包括了20个实数值的属性,其中除了有确定的坏账记录之外还有部份数据是属于未知,这个就是需要预测的目标值。
数据本身并没有缺失,并且基本上种类都是匹配的。通过使用散点矩阵图形观察,各个属性之间并没有显著的相关性。唯一需要考虑的是,因为其中的数值范围,差异比较大,所以如果是使用某些模型,可能需要将数据做常态化的操作。但是如果使用的是支持向量机,可以处理不同数量级的数字(通过核函数映射),基本上可以不需做常态化的转换,所以在数据的整理上面,可以直接的使用。
03、操作流程
Step1读入数据
这个操作是将数据读入,并且进行观察,确定数据不需要做其他的操作。第2个是将数据中坏账的属性设定为目标值,作为操作的对象。
Step2 数据整理
这个部分2个算子,第一个Filter Example是将数据分成有目标值的已知数据和没有目标值的未知数据,这个的操作直接可以使用其参数的设定,但是要注意,这个部分的参数设定,需要先选择参数中的 “Condition Class” 才能作设定,而系统的缺省设定是 “(Custom-Filters)” ,如下图所示:
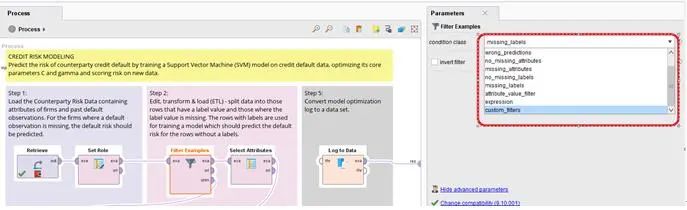
第2个是将未知的数据,将其目标值取消,而作为模型预测的结果判断。这边也有一个小技巧,与其将所有的需要参数都选入,简单的方式是将不需要的参数作为选择的标准,再做一个相反的设定,这样更为简洁,如下图所示:
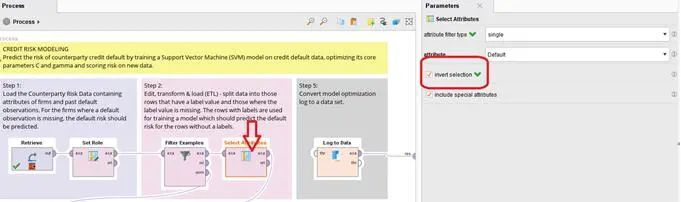
Step3: 模型建立/优化
这个部分是最关键的部分,使用这个操作,是一种将依照我们所选取的参数,将其所有的可能性做一个组合之后,全部的进行测试,依照其效果的优劣,选出最优化的模型,作为输出的结果,如下图所示:
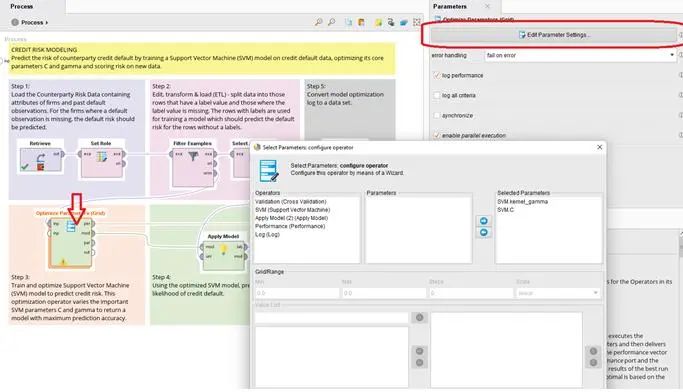
通过对于这个算子的参数设定,可以选取模型中不同参数来做优化。其中参数可以设定数值范围和精度都能够设定。系统依照所有的组合,进行每一次的运算产生出最好的参数值。这种运算方式,如同设定一个2D 的网格,系统在每一个节点进行运算,所以这种参数优化的方式称作为网格式(Grid)。
这边我们使用的是支持向量机的模型,其中所设定的参数,可以参考相关支持向量机的基本理论。对于使用径向核函数(Radial Kernel),其中的Gamma值和相关的容忍值C,可以有不同的设定而得到不同的结果。这个就是我们希望能通过参数优化的方式,来做到最合适的参数组合。如果不同的核函数,会有不同的参数需要优化。
如果将这个算子打开,其中内部分为两个算子,一个是我们熟悉的交叉验证,而第二个是一个日志记录。前一个没有太多的悬念,而后一个可以再进一步的探讨。
我们可以观察到,在交叉检验的步骤之后,其中准确度(Per)的端口输出与日志记录(Log)连接。如果再细看日志记录其中,它会将每一次的不同参数组合的检测结果保存,而其所设定的记录参数是我们在整个参数优化的过程中所更改的参数,而通过这个记录可以把变化过程中相关的参数设定和结果完全保存。在此有两点特别值得说明,第一这是系统保存在内存的空间,所以不需要另外给予文件名(但是也可以用文件名而保存到硬盘上);第二是系统的参数是通过Meta-Data的传送,所以能够知道是相对于何种模型的参数而进行设定。
Step4: 模型使用
优化模型的操作最后的输出,就是最优模型,可以通过 Mod的端口使用。所以直接的可以将之前未知的数据,直接导入并且使用Apply Model的操作判断未知数据的结果。
Step5: 日志输出
我们可以通过将原来在优化参数的操作中所保存的日志记录,通过直接将其输出,观察到其所有在参数和结果之间的整个过程。
04、结果说明
这个部分的输出,也是很值得观察。虽然只有三个对外的连接点,却有五个输出的页面,如下图所示:
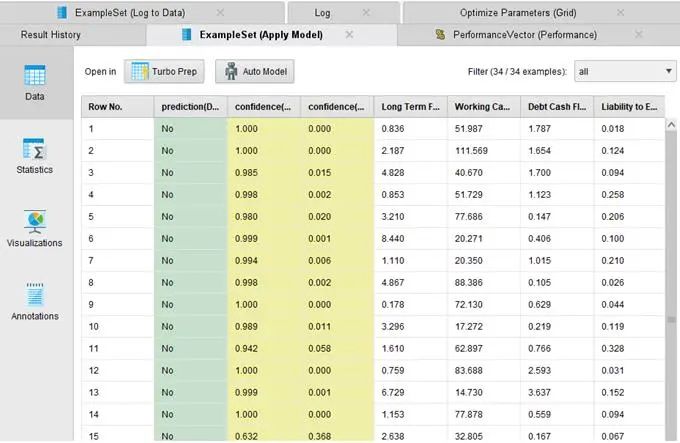
其中主要是前三个结果:一个是日志的输出,可以观察到其优化过程中所有参数和效果之间的数据;第二个是对于最优化的模型其准确度的输出,作为我们模型使用的依据;第三个是对于未知数据,使用最优化模型之后,来预测其结果。
后面2个的输出页面,是作为参考,但是值得注意的是其中对于Optimize Parameters(Grid)的输出。可以通过观察,看到如果使用其顺序是依照正常的方式,先计算固定C然后变动Gamma,之后再进行下一组,系统虽然是采用了并行计算,但是其顺序仍然逐步进行,所以结果数据是依照顺序的表现,如下图所示:

这个部分,解决了很多在机器学习使用上面会碰到的问题。到底何种参数的设定是一个最优化的参数?这里再一次展示计算机的硬实力,就是它的计算能力。通过对于不同的参数组合,全部给予计算,再来选择最优化的一个参数,而并不是依照任何的公式或者是其他的做法,这边也表示出机器学习的另外的特点。
关于 Altair RapidMiner
Altair RapidMiner 数据分析与人工智能平台,是 Altair 澳汰尔公司旗下仿真、HPC 和数据分析三块主营业务中的解决方案,它在数据分析领域最早实现将自动化数据科学、文本分析、自动特征工程和深度学习等多种功能同时集成的一站式数据分析平台,帮助用户解决从数据清洗、准备、数据科学建模到模型管理和部署,同时又支持数据和流数据的实时分析可视化的数据分析平台。
欲了解更多信息,欢迎关注公众号:Altair RapidMiner
这篇关于机器学习案例|使用机器学习轻松预测信用卡坏账风险,极大程度降低损失的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






