本文主要是介绍hive on spark 的架构和常见问题 - hive on spark 使用的是 yarn client 模式还是 yarn cluster 模式?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
hive on spark 的架构和常见问题 - hive on spark 使用的是 yarn client 模式还是 yarn cluster 模式?
1. 回顾下 spark 的架构图和部署模式
来自官方的经典的 spark 架构图如下:
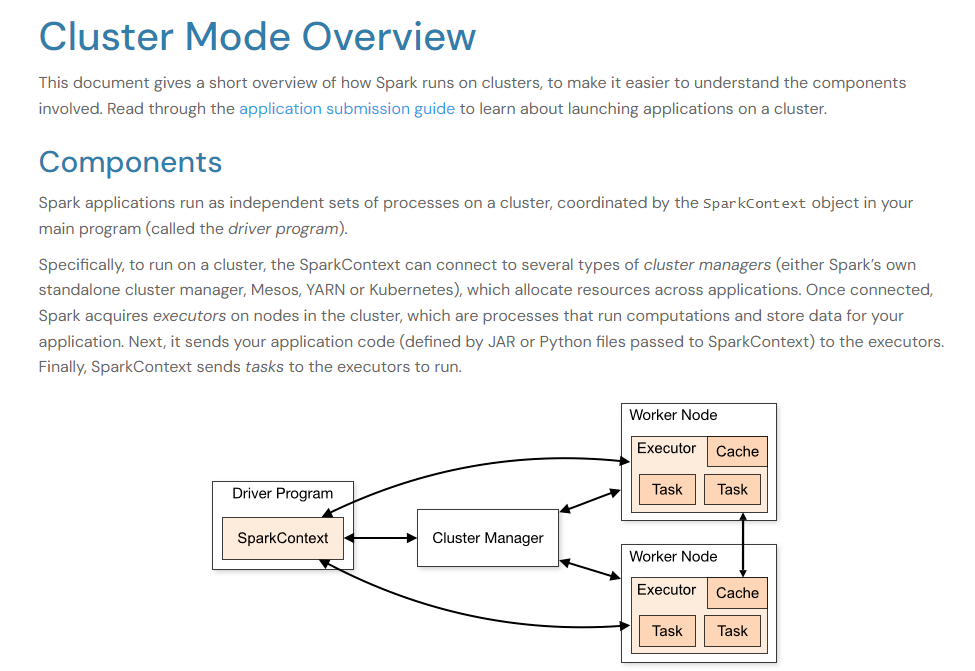
上述架构图,从进程的角度来讲,有四个角色/组件:
- Cluster manager:An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN, Kubernetes)
- Worker node: Any node that can run application code in the cluster
- Driver program:The process running the main() function of the application and creating the SparkContext
- Executor: A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors.
- 上述四个角色中,Cluster manager 和 Worker,是常驻的静态的资源管理器,是独立于 spark 应用程序之外的;
- 上述四个角色中,driver 和 executor,是每个 spark 应用程序的运行时动态视图,用户提交的每个 spark 应用程序,都会向资源管理器申请资源,并在申请获得的资源中启动 driver 和 exector 对应的 jvm 进程;
- spark 支持多种资源管理器,常见的有 standalone/yarn/k8s/mesos,其中 mesos 目前已经 deprecated 了;
- spark deploy mode: spark部署模式:当用户(或框架)提交 spark 应用程序时(从client 客户端提交),上述 driver 角色可以运行在客户端进程中,也可以运行在从资源管理器申请获得的资源中启动的 jvm 进程中,前者被 spark 称为 client 模式,而后者被 spark 称为 cluster 模式;
- 用户可以在 spark-defaults.conf 等配置文件中,通过参数 spark.submit.deployMode 指定具体的部署模式;
- 用户也可以在使用 spark-sumbmit 脚本提交 spark 作业时,通过参数 --deploy-mode,指定具体的部署模式;
- Spark is agnostic to the underlying cluster manager. As long as it can acquire executor processes, and these communicate with each other, it is relatively easy to run it even on a cluster manager that also supports other applications (e.g. Mesos/YARN/Kubernetes).
- Deploy mode: Distinguishes where the driver process runs. In “cluster” mode, the framework launches the driver inside of the cluster. In “client” mode, the submitter launches the driver outside of the cluster.(Whether to deploy your driver on the worker nodes (cluster) or locally as an external client (client),default: client);
- spark.submit.deployMode:The deploy mode of Spark driver program, either “client” or “cluster”, Which means to launch driver program locally (“client”) or remotely (“cluster”) on one of the nodes inside the cluster;
2. hive on spark 使用的是 yarn client 模式还是 yarn cluster 模式?
- hive 作为跟 hadoop 紧密耦合的的一个重要组件,其调度运行作业使用的资源管理器,就是 yarn;
- hive 支持多种计算引擎,常见的有 mr/spark/tez,可以通过 set hive.execution.engine = mr/spark/tez 进行配置;
- 当 hive 应用使用 spark 引擎运行时,我们称之为 hive on spark;相对应地,当 spark 应用访问 hvie 数据源时,我们称之为 spark on hive;
- hive on spark 作业运行时,用户并没有明确指定部署模式,此时 hive on spark 作业,使用的是 client 模式还是 cluster 模式呢?
- 查看 hs2 源码可知,hive on spark 作业,是 hs2 进程作为 spark 客户端,通过调用 spark-submit 脚本提交的,而 spark 相关的配置参数,有一部分是用户通过 spark-defaults.conf 配置的,也有一部分是 hs2 代码写死了的配置;
- 查看 hs2 日志,可以看到动态生称的配置文件,比如 run/cloudera-scm-agent/process/5666-hive-HIVESERVER2/spark-defaults.conf,其中明确指定了spark.master=yarn, 而该配置文件中 spark.submit.deployMode 的值,取决于 spark-defaults.conf中的配置;
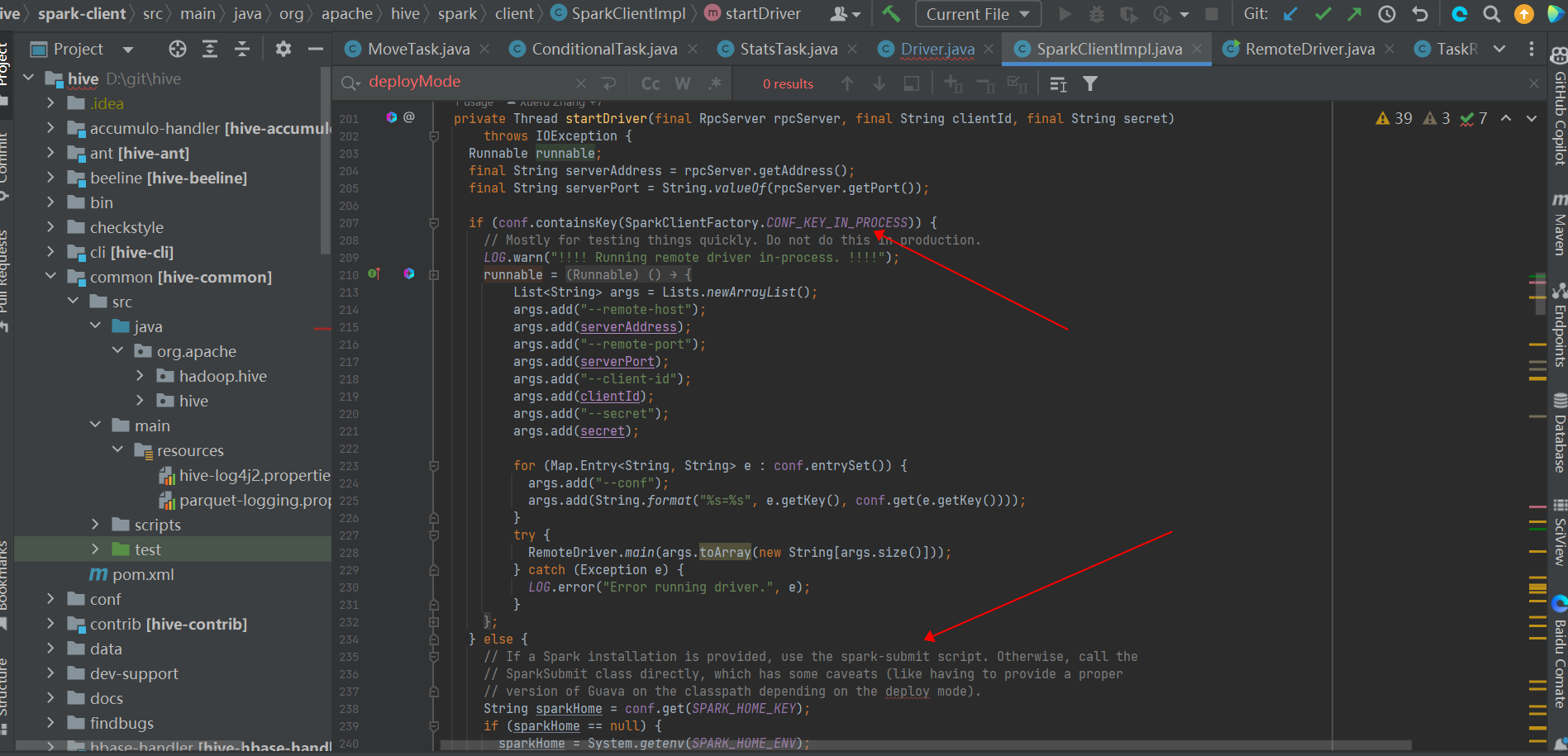
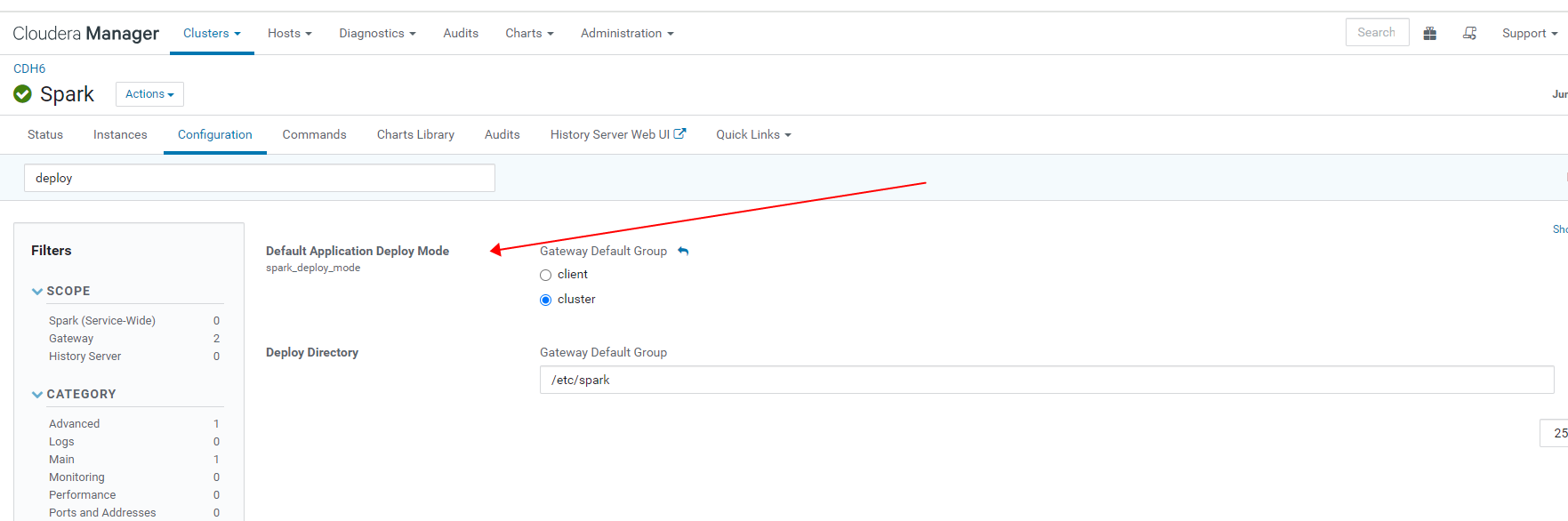
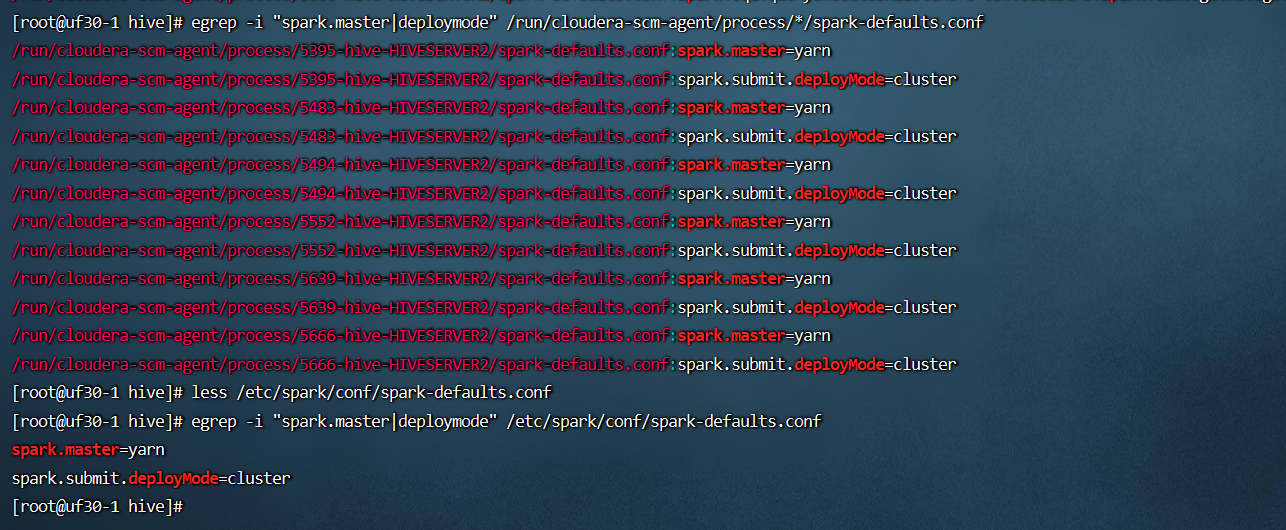
- 更进一步,在 beeline 中,通过命令 “set spark.submit.deployMode” 查看可知,hive on spark 的 deployMode 固定为 cluster,无论 spark-defauls.conf 中 spark.submit.deployMode 配置如何;
- 更进一步,在 beeline 中,通过命令 “set spark.submit.deployMode=client” 手动指定 hive on spark 的deployMode 为 client ,然后提交 hive on spark 作业,则这些作业会因为 spark jvm 进程启动失败而报错;

综上所述: - hive on spark 模式下,hs2 承载了 spark 客户端的角色,hs2 通过 spark-submit脚本提交 spark 作业;
- 无论用户如何配置 spark-defaults.conf, hive on spark 固定使用的都是 yarn cluster 模式;
- 如果用户在 beeline 中,通过命令 “set spark.submit.deployMode=client” 手动指定 hive on spark 的deployMode 为 client 后,则此后提交的 hive on spark 作业会因为 spark jvm 进程启动失败而报错;
- hs2 中,hive on spark 的两个核心的相关源码类是:org.apache.hive.spark.client.SparkClientImpl/org.apache.hive.spark.client.RemoteDriver;
- 通过命令 “set spark.submit.deployMode=client” 手动指定 hive on spark 的deployMode 为 client 后, hive on spark 作业 失败的日志如下:
ERROR : FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session 256f3dc9-c1a3-49f3-be2c-9ab81a8dd518_1: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error "Error: Could not create the Java Virtual Machine.","Error: A fatal exception has occurred. Program will exit."
INFO : Completed executing command(queryId=hive_20240620154413_1ad26fe2-f2d5-4252-a609-b3b8d4ce2822); Time taken: 0.517 seconds
Error: Error while processing statement: FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session 256f3dc9-c1a3-49f3-be2c-9ab81a8dd518_1: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error "Error: Could not create the Java Virtual Machine.","Error: A fatal exception has occurred. Program will exit." (state=42000,code=30041)
- hs2 动态生成的 spark-default.conf,以及 hs2中启动 hive on spark 作业的相关日志,如下:
# hive on spark 相关配置-/run/cloudera-scm-agent/process/5666-hive-HIVESERVER2/spark-defaults.conf 包含:
spark.master=yarn
spark.submit.deployMode=cluster
spark.authenticate=true
spark.driver.log.dfsDir=/user/spark/driverLogs
spark.driver.log.persistToDfs.enabled=true
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.executorIdleTimeout=60
spark.dynamicAllocation.minExecutors=1
spark.dynamicAllocation.schedulerBacklogTimeout=1
spark.eventLog.enabled=true
spark.io.encryption.enabled=false
spark.network.crypto.enabled=false
spark.serializer=org.apache.spark.serializer.KryoSerializer
spark.shuffle.service.enabled=true
spark.shuffle.service.port=7337
spark.ui.enabled=true
spark.ui.killEnabled=true
spark.lineage.log.dir=/var/log/spark/lineage
spark.lineage.enabled=true
spark.eventLog.dir=hdfs://ns1/user/spark/applicationHistory
spark.yarn.historyServer.address=http://uf30-3:18088
spark.yarn.jars=local:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark/jars/*,local:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark/hive/*
spark.driver.extraLibraryPath=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/lib/native
spark.executor.extraLibraryPath=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/lib/native
spark.yarn.am.extraLibraryPath=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/lib/native
spark.yarn.config.gatewayPath=/opt/cloudera/parcels
spark.yarn.config.replacementPath={{HADOOP_COMMON_HOME}}/../../..
spark.yarn.historyServer.allowTracking=true
spark.yarn.appMasterEnv.MKL_NUM_THREADS=1
spark.executorEnv.MKL_NUM_THREADS=1
spark.yarn.appMasterEnv.OPENBLAS_NUM_THREADS=1
spark.executorEnv.OPENBLAS_NUM_THREADS=1
spark.extraListeners=com.cloudera.spark.lineage.NavigatorAppListener
spark.sql.queryExecutionListeners=com.cloudera.spark.lineage.NavigatorQueryListener# hs2中,hive on spark 相关日志:
2024-06-20 09:43:30,902 INFO org.apache.hive.spark.client.SparkClientImpl: [HiveServer2-Background-Pool: Thread-151785]: Loading spark defaults configs from: file:/run/cloudera-scm-agent/process/5666-hive-HIVESERVER2/spark-defaults.conf
2024-06-20 09:43:30,908 INFO org.apache.hive.spark.client.SparkClientImpl: [HiveServer2-Background-Pool: Thread-151785]: Running client driver with argv: /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark/bin/spark-submit --executor-cores 4 --executor-memory 2147483648b --principal hive/uf30-1@CDH.COM --keytab hive.keytab --jars /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-kryo-registrator-2.1.1-cdh6.3.2.jar --properties-file /tmp/spark-submit.6442647368541171349.properties --class org.apache.hive.spark.client.RemoteDriver /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-exec-2.1.1-cdh6.3.2.jar --remote-host uf30-1 --remote-port 54208 --remote-driver-conf hive.spark.client.future.timeout=60000 --remote-driver-conf hive.spark.client.connect.timeout=1000 --remote-driver-conf hive.spark.client.server.connect.timeout=900000 --remote-driver-conf hive.spark.client.channel.log.level=null --remote-driver-conf hive.spark.client.rpc.max.size=52428800 --remote-driver-conf hive.spark.client.rpc.threads=8 --remote-driver-conf hive.spark.client.secret.bits=256 --remote-driver-conf hive.spark.client.rpc.server.address=null --remote-driver-conf hive.spark.client.rpc.server.port=null
2024-06-20 09:43:31,887 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: Warning: Ignoring non-spark config property: hive.spark.client.server.connect.timeout=900000
2024-06-20 09:43:31,887 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: Warning: Ignoring non-spark config property: hive.spark.client.rpc.threads=8
2024-06-20 09:43:31,887 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: Warning: Ignoring non-spark config property: hive.spark.client.future.timeout=60000
2024-06-20 09:43:31,887 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: Warning: Ignoring non-spark config property: hive.spark.client.connect.timeout=1000
2024-06-20 09:43:31,887 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: Warning: Ignoring non-spark config property: hive.spark.client.secret.bits=256
2024-06-20 09:43:31,888 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: Warning: Ignoring non-spark config property: hive.spark.client.rpc.max.size=52428800
2024-06-20 09:43:32,059 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:32 WARN spark.SparkConf: The configuration key 'spark.yarn.executor.memoryOverhead' has been deprecated as of Spark 2.3 and may be removed in the future. Please use the new key 'spark.executor.memoryOverhead' instead.
2024-06-20 09:43:32,059 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:32 WARN spark.SparkConf: The configuration key 'spark.yarn.driver.memoryOverhead' has been deprecated as of Spark 2.3 and may be removed in the future. Please use the new key 'spark.driver.memoryOverhead' instead.
2024-06-20 09:43:33,044 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO yarn.Client: Kerberos credentials: principal = hive/uf30-1@CDH.COM, keytab = hive.keytab
2024-06-20 09:43:33,531 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm71
2024-06-20 09:43:33,585 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO yarn.Client: Requesting a new application from cluster with 3 NodeManagers
2024-06-20 09:43:33,698 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO conf.Configuration: resource-types.xml not found
2024-06-20 09:43:33,698 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2024-06-20 09:43:33,719 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (20480 MB per container)
2024-06-20 09:43:33,720 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO yarn.Client: Will allocate AM container, with 2560 MB memory including 512 MB overhead
2024-06-20 09:43:33,720 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO yarn.Client: Setting up container launch context for our AM
2024-06-20 09:43:33,724 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO yarn.Client: Setting up the launch environment for our AM container
2024-06-20 09:43:33,745 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO yarn.Client: Preparing resources for our AM container
2024-06-20 09:43:33,805 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO yarn.Client: To enable the AM to login from keytab, credentials are being copied over to the AM via the YARN Secure Distributed Cache.
2024-06-20 09:43:33,810 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:33 INFO yarn.Client: Uploading resource file:/run/cloudera-scm-agent/process/5666-hive-HIVESERVER2/hive.keytab -> hdfs://ns1/user/hive/.sparkStaging/application_1716544959017_1620/hive.keytab
2024-06-20 09:43:34,091 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:34 INFO yarn.Client: Uploading resource file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-exec-2.1.1-cdh6.3.2.jar -> hdfs://ns1/user/hive/.sparkStaging/application_1716544959017_1620/hive-exec-2.1.1-cdh6.3.2.jar
2024-06-20 09:43:34,434 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:34 INFO yarn.Client: Uploading resource file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-kryo-registrator-2.1.1-cdh6.3.2.jar -> hdfs://ns1/user/hive/.sparkStaging/application_1716544959017_1620/hive-kryo-registrator-2.1.1-cdh6.3.2.jar
2024-06-20 09:43:34,771 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:34 INFO yarn.Client: Uploading resource file:/tmp/spark-6592d710-76fe-4804-9e14-6fa37e26747c/__spark_conf__4167604981797776583.zip -> hdfs://ns1/user/hive/.sparkStaging/application_1716544959017_1620/__spark_conf__.zip
2024-06-20 09:43:34,852 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:34 INFO spark.SecurityManager: Changing view acls to: hive
2024-06-20 09:43:34,853 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:34 INFO spark.SecurityManager: Changing modify acls to: hive
2024-06-20 09:43:34,854 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:34 INFO spark.SecurityManager: Changing view acls groups to:
2024-06-20 09:43:34,855 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:34 INFO spark.SecurityManager: Changing modify acls groups to:
2024-06-20 09:43:34,856 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:34 INFO spark.SecurityManager: SecurityManager: authentication enabled; ui acls disabled; users with view permissions: Set(hive); groups with view permissions: Set(); users with modify permissions: Set(hive); groups with modify permissions: Set()
2024-06-20 09:43:34,893 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:34 INFO conf.HiveConf: Found configuration file file:/etc/hive/conf.cloudera.hive/hive-site.xml
2024-06-20 09:43:35,013 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO security.YARNHadoopDelegationTokenManager: Attempting to login to KDC using principal: hive/uf30-1@CDH.COM
2024-06-20 09:43:35,017 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO security.YARNHadoopDelegationTokenManager: Successfully logged into KDC.
2024-06-20 09:43:35,028 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO security.HadoopFSDelegationTokenProvider: getting token for: DFS[DFSClient[clientName=DFSClient_NONMAPREDUCE_-350949835_1, ugi=hive/uf30-1@CDH.COM (auth:KERBEROS)]] with renewer yarn/uf30-1@CDH.COM
2024-06-20 09:43:35,056 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO hdfs.DFSClient: Created token for hive: HDFS_DELEGATION_TOKEN owner=hive/uf30-1@CDH.COM, renewer=yarn, realUser=, issueDate=1718847815048, maxDate=1719452615048, sequenceNumber=489988, masterKeyId=1416 on ha-hdfs:ns1
2024-06-20 09:43:35,059 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO security.HadoopFSDelegationTokenProvider: getting token for: DFS[DFSClient[clientName=DFSClient_NONMAPREDUCE_-350949835_1, ugi=hive/uf30-1@CDH.COM (auth:KERBEROS)]] with renewer hive/uf30-1@CDH.COM
2024-06-20 09:43:35,060 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO hdfs.DFSClient: Created token for hive: HDFS_DELEGATION_TOKEN owner=hive/uf30-1@CDH.COM, renewer=hive, realUser=, issueDate=1718847815056, maxDate=1719452615056, sequenceNumber=489989, masterKeyId=1416 on ha-hdfs:ns1
2024-06-20 09:43:35,106 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO security.HadoopFSDelegationTokenProvider: Renewal interval is 86400044 for token HDFS_DELEGATION_TOKEN
2024-06-20 09:43:35,168 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 WARN conf.HiveConf: HiveConf of name hive.enforce.bucketing does not exist
2024-06-20 09:43:35,206 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO yarn.Client: Submitting application application_1716544959017_1620 to ResourceManager
2024-06-20 09:43:35,456 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO impl.YarnClientImpl: Submitted application application_1716544959017_1620
2024-06-20 09:43:35,461 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO yarn.Client: Application report for application_1716544959017_1620 (state: ACCEPTED)
2024-06-20 09:43:35,468 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO yarn.Client:
2024-06-20 09:43:35,469 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: client token: Token { kind: YARN_CLIENT_TOKEN, service: }
2024-06-20 09:43:35,469 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: diagnostics: AM container is launched, waiting for AM container to Register with RM
2024-06-20 09:43:35,469 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: ApplicationMaster host: N/A
2024-06-20 09:43:35,469 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: ApplicationMaster RPC port: -1
2024-06-20 09:43:35,469 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: queue: root.users.dap
2024-06-20 09:43:35,469 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: start time: 1718847815223
2024-06-20 09:43:35,469 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: final status: UNDEFINED
2024-06-20 09:43:35,469 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: tracking URL: http://uf30-3:8088/proxy/application_1716544959017_1620/
2024-06-20 09:43:35,469 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: user: hive
2024-06-20 09:43:35,474 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO util.ShutdownHookManager: Shutdown hook called
2024-06-20 09:43:35,476 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-c92c59a3-55ce-4aa1-9463-6ed42b4ddd99
2024-06-20 09:43:35,481 INFO org.apache.hive.spark.client.SparkClientImpl: [spark-submit-stderr-redir-HiveServer2-Background-Pool: Thread-151785]: 24/06/20 09:43:35 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-6592d710-76fe-4804-9e14-6fa37e26747c
2024-06-20 09:43:35,865 INFO org.apache.hive.spark.client.SparkClientImpl: [Driver]: Child process (spark-submit) exited successfully.
2024-06-20 09:43:40,157 INFO org.apache.hive.spark.client.SparkClientImpl: [HiveServer2-Background-Pool: Thread-151785]: Successfully connected to Remote Spark Driver at: uf30-1:38642
2024-06-20 09:43:48,053 INFO org.apache.hive.spark.client.SparkClientImpl: [Spark-Driver-RPC-Handler-0]: Received Spark job ID: 0 for client job c111431c-5a57-4bb4-9357-07d0e5948d79
3 hive on spark 常见问题
- 问题现象:部分 HIVE ON SPARK 作业报错失败,但重试有时候又能够成功,客户端报错: java.sql.SQLException…failed to create spark client for spark session xxx: java.util.concurrent.TimeoutException: client xxx timed out waiting for connection from the remote spark driver.
- 问题日志:hiveserver2 日志:“timed out waiting for remote spark driver to connect to hiveserver2. possible reasons include network issues, errors in remote driver, cluster has no available resources etc. please check yarn or spark driver;s logs for further information.”
- 问题日志:yarn 日志:container exited with a non-zero exit code 13. Error file: prelaunch.err. …java.util.concurrent.ExecutionException:javax.security.sasl.saslException: client closed before SASL negotiation finished.
- 问题原因:大量 HIVE ON SPARK 作业并发提交时, yarn 中对应队列上没有足够资源启动 spark 集群了,或者 hiveserver2/yarn/kdc 在高并发下的性能问题,造成了超时;
- 问题解决:业务侧可以减少并发调度的作业数,或者调小申请的spark资源的大小(spark.driver.memory/spark.executor.memory/spark.executor.cores 等);服务端可以增大对应队列的资源,也可以同步调大服务端超时参数以缓解问题,注意该超时参数 hive.spark.client.server.connect.timeout 需要在服务端更改并重启服务端才能生效,客户端更改时不会报错但是不会生效;
- 另外如有必要,需要同步更改黑白名单参数:hive.conf.restricted.list/hive.security.authorization.sqlstd.confwhitelist/hive.security.authorization.sqlstd.confwhitelist.append);
- 相关参数:
服务端参数 hive.spark.client.server.connect.timeout:默认90秒:Timeout for handshake between Hive client and remote Spark driver. Checked by both processes.
服务端参数 hive.spark.client.future.timeout: 默认 60秒:Timeout for requests from Hive client to remote Spark driver.
客户端参数 hive.spark.client.connect.timeout:默认一秒:Timeout for remote Spark driver in connecting back to Hive client
这篇关于hive on spark 的架构和常见问题 - hive on spark 使用的是 yarn client 模式还是 yarn cluster 模式?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



