本文主要是介绍【可控图像生成系列论文(二)】MimicBrush 港大、阿里、蚂蚁集团合作论文解读2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【可控图像生成系列论文(一)】简要介绍了论文的整体流程和方法,本文则将就整体方法、模型结构、训练数据和纹理迁移进行详细介绍。

1.整体方法
MimicBrush 的整体框架如下图所示。为了实现模仿编辑,作者设计了一种具有双扩散模型的架构,并以自监督的方式进行训练。视频数据本身包含自然一致的内容,同时也展示了视觉变化,例如同一只狗的不同姿势。
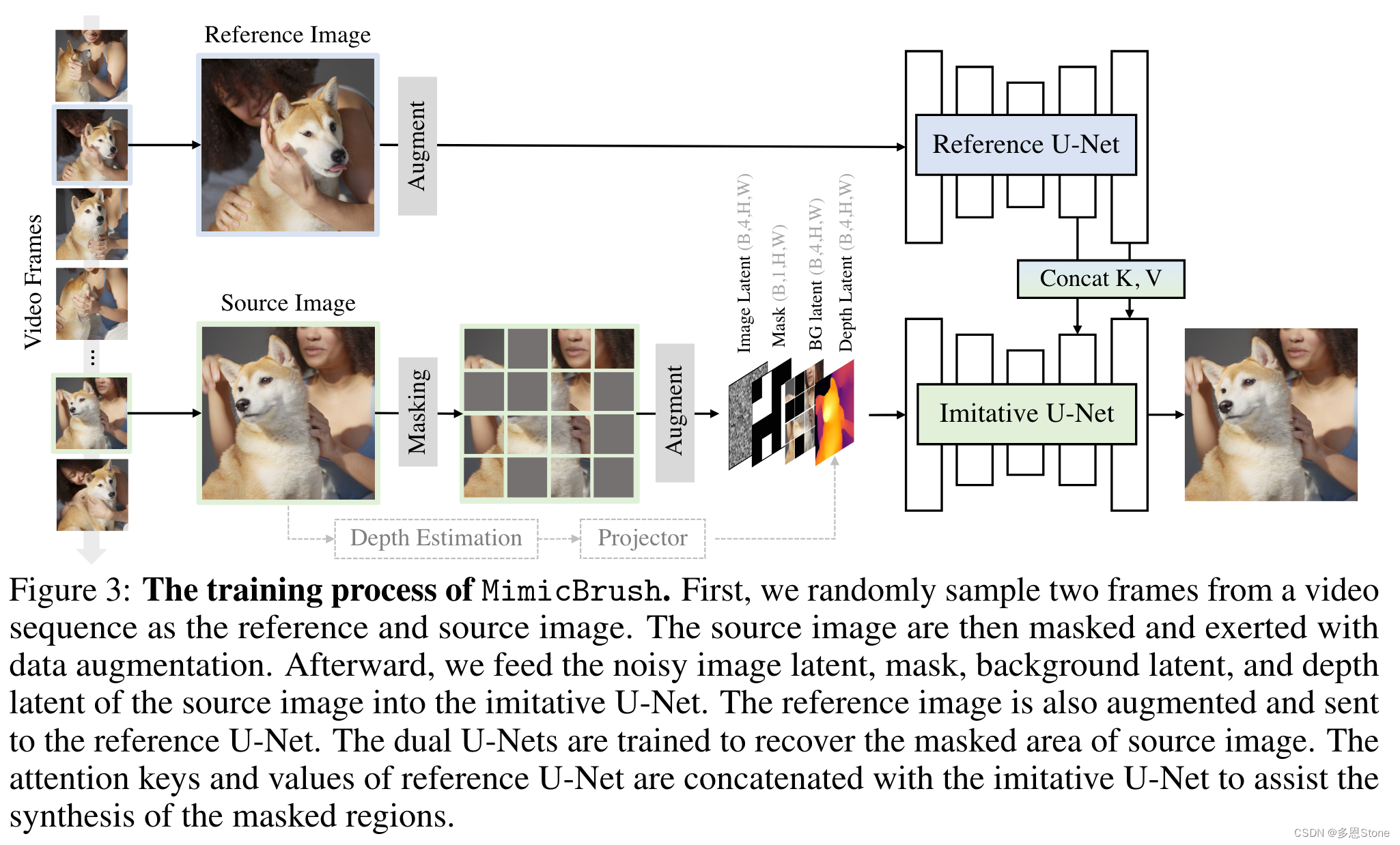
- 因此,作者从视频片段中随机选择两个帧作为 MimicBrush 的训练样本。一帧作为源图像,作者在其某些区域上进行遮罩。另一帧作为参考图像,帮助模型恢复被遮罩的源图像。
- 通过这种方式,MimicBrush 学会了定位相应的视觉信息(例如狗的脸),并将其重新绘制到源图像的遮罩区域中。
- 为了确保重新绘制的部分能够与源图像和谐融合,MimicBrush 还学习将视觉内容转移到相同的姿势、光照和视角下。
- 值得注意的是,这样的训练过程是基于原始视频片段进行的,不需要文本或跟踪注释,并且可以通过大量视频轻松扩展。
- MimicBrush 利用双分支的 U-Nets,即模仿 U-Net 和参考 U-Net,分别以源图像和参考图像为输入。这两个 U-Nets 在注意力层中共享它们的键和值,并被训练以从参考图像中寻找指示来复原被遮罩的源图像。
- 作者还对源图像和参考图像进行数据增强,以增加它们之间的区别。
- 同时,从未被遮罩的源图像中提取深度图,并将其作为可选条件添加到模仿 U-Net 中。通过这种方式,在推理过程中,用户可以决定是否启用源图像的深度图,以保留原始源图像中物体的形状。
2.模型结构
框架主要包括模仿 U-Net、参考 U-Net 和深度模型。
模仿 U-Net
- 模仿 U-Net 是基于 stable diffusion-1.5-inpainting1 模型初始化的。它以一个具有 13 个通道的张量作为输入。
- 图像潜变量(4 个通道)负责从初始噪声一步步扩散到输出潜变量代码。作者还连接了一个二进制遮罩(1 个通道)以指示生成区域,以及被遮罩源图像的背景潜变量(4 个通道)。此外,作者将深度图投射到一个(4 通道)深度潜变量,以提供形状信息。
- 原始 U-Net 还通过交叉注意力接收 CLIP 2 文本嵌入作为输入。在本研究中,作者用从参考图像中提取的 CLIP 图像嵌入替换了它。
- 按照之前的研究 3 4,作者在图像嵌入之后添加了一个可训练的投射层。为了简化图示,图 3 中未包含此部分。在训练期间,模仿 U-Net 和 CLIP 投射层的所有参数都是可优化的。
参考 U-Net
- 最近,一些研究 5 6 7 8 9 10 证明了利用额外的 U-Net 从参考图像中提取细粒度特征的有效性。
- 在本研究中,作者应用了类似的设计并引入了一个参考 U-Net。它是基于标准 stable diffusion-1.5 11 初始化的。它采用参考图像的 4 通道潜变量来提取多层次特征。
- 参考 12,作者在中间和上采样阶段将参考特征注入模仿 U-Net,通过将其键和值与模仿 U-Net 连接起来,如下公式所示。
Attention = softmax ( Q i ⋅ cat ( K i , K r ) T d k ) ⋅ cat ( V i , V r ) \text{Attention} = \text{softmax}\left( \frac{Q_i \cdot \text{cat}(K_i, K_r)^T}{\sqrt{d_k}} \right) \cdot \text{cat}(V_i, V_r) Attention=softmax(dkQi⋅cat(Ki,Kr)T)⋅cat(Vi,Vr) - 通过这种方式,模仿 U-Net 可以利用参考图像的内容来完成源图像的遮罩区域。
深度模型
- 作者利用 Depth Anything 13 来预测未遮罩源图像的深度图作为形状控制,这使 MimicBrush 能够进行纹理迁移。
- 作者冻结了深度模型并添加了一个可训练的映射器,将预测的深度图(3 通道)投射到深度潜变量(4 通道)。
- 在训练期间,作者设定以 0.5 的概率将深度模型的输入设为全零图。因此,用户在推理过程中可以选择是否启用形状控制。
3.训练数据
- 训练数据选择的要点:
- 首先,保证源图像和参考图像之间存在对应关系。
- 其次,作者预计源图像和参考图像之间会有很大的变化,这对于寻找视觉对应关系的稳健性至关重要。
- 如何确保“对应关系”?(数据选择)
- 在训练过程中,作者对同一视频中的两帧进行采样。参考前人的研究14,作者使用SSIM 15作为衡量视频帧之间的相似性的指标。
- 作者丢弃相似性过大或过小的帧(图片)对,以确保所选图像对包含语义对应和视觉变化。
- 训练数据来源:
- 作者从 Pexels 16 等开源网站收集了10万个高分辨率视频。
- 为了进一步扩大训练样本的多样性,还使用SAM 17数据集,该数据集包含1000万张图像和10亿个对象掩码。作者通过对来自SAM的静态图像应用强数据增强来构建伪帧,并利用对象分割结果来掩蔽源图像。
- 在训练期间,视频和SAM数据的采样部分为70%,而默认情况下为30%。
如上图所示,训练数据中的源图像和参考图像都通过了一定的数据增强后,再被分别送入 U-Net 中。
- 那么具体的数据增强是如何做的?
- 为了增加源图像和参考图像之间的变化,作者施加了较强的数据增强。
- 除了应用激进的颜色抖动、旋转、调整大小和翻转外,作者还实现了随机投影变换来模拟更强的变形。
4. 评估任务-纹理迁移

- 纹理迁移需要严格保持源对象的形状,并且仅迁移参考图像的纹理/图案。
- 为此任务,作者启用了深度图作为附加条件。与寻求语义对应的部分组合不同,在此任务中作者对完整对象进行遮罩,因此模型只能发现纹理(参考)和形状(源)之间的对应关系。
- 作者还制定了 inter-ID 和 inner-ID 两类。
- 前者涉及30个来自Pexels 18 的具有大变形的样本,比如将豹纹迁移到图4中的帽子上。
- 后者包含DreamBooth 19 数据集中额外的30个示例。作者遵循与部分组合相同的数据格式和评估指标。
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022 ↩︎
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021. ↩︎
X. Chen, L. Huang, Y. Liu, Y. Shen, D. Zhao, and H. Zhao. Anydoor: Zero-shot object-level image customization. CVPR, 2024. ↩︎
H. Ye, J. Zhang, S. Liu, X. Han, and W. Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. arXiv:2308.06721, 2023. ↩︎
L. Zhang. Reference-only controlnet. https://github.com/Mikubill/sd-webui-controlnet/ discussions/1236, 2023. ↩︎
L. Hu, X. Gao, P. Zhang, K. Sun, B. Zhang, and L. Bo. Animate anyone: Consistent and controllable image-to-video synthesis for character animation. CVPR, 2024. ↩︎
Z. Xu, J. Zhang, J. H. Liew, H. Yan, J.-W. Liu, C. Zhang, J. Feng, and M. Z. Shou. Magicanimate: Temporally consistent human image animation using diffusion model. In CVPR, 2024. ↩︎
M. Chen, X. Chen, Z. Zhai, C. Ju, X. Hong, J. Lan, and S. Xiao. Wear-any-way: Manipulable virtual try-on via sparse correspondence alignment. arXiv:2403.12965, 2024. ↩︎
S. Zhang, L. Huang, X. Chen, Y. Zhang, Z.-F. Wu, Y. Feng, W. Wang, Y. Shen, Y. Liu, and P. Luo. Flashface: Human image personalization with high-fidelity identity preservation. arXiv:2403.17008, 2024. ↩︎
Z. Xu, M. Chen, Z. Wang, L. Xing, Z. Zhai, N. Sang, J. Lan, S. Xiao, and C. Gao. Tunnel try-on: Excavating spatial-temporal tunnels for high-quality virtual try-on in videos. arXiv:2404.17571, 2024. ↩︎
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022 ↩︎
Z. Xu, J. Zhang, J. H. Liew, H. Yan, J.-W. Liu, C. Zhang, J. Feng, and M. Z. Shou. Magicanimate: Temporally consistent human image animation using diffusion model. In CVPR, 2024. ↩︎
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. In CVPR, 2024. ↩︎
X. Chen, Z. Liu, M. Chen, Y. Feng, Y. Liu, Y. Shen, and H. Zhao. Livephoto: Real image animation with text-guided motion control. arXiv:2312.02928, 2023 ↩︎
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity. TIP, 2004. ↩︎
The best free stock photos, royalty free images & videos shared by creators. https://www. pexels.com, 2024 ↩︎
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al. Segment anything. In ICCV, 2023 ↩︎
The best free stock photos, royalty free images & videos shared by creators. https://www. pexels.com, 2024 ↩︎
N. Ruiz, Y. Li, V. Jampani, Y. Pritch, M. Rubinstein, and K. Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In CVPR, 2023 ↩︎
这篇关于【可控图像生成系列论文(二)】MimicBrush 港大、阿里、蚂蚁集团合作论文解读2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








