本文主要是介绍如何调用讯飞星火认知大模型的API以利用其卓越功能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
讯飞星火认知大模型,作为科大讯飞精心打造的一款人工智能模型,在自然语言理解和生成方面展现出了卓越的能力。这款模型通过深度学习技术和大量数据的训练,具备了强大的语言理解、文本生成和对话交互等功能。
一、模型功能概述
讯飞星火认知大模型能够为用户提供个性化的信息服务,包括但不限于语音识别、文本分析、自动翻译以及智能问答等。它在多个应用场景中都能发挥出色,如在智能客服系统中准确理解用户问题,或在内容创作领域协助生成高质量的文章或报告。
讯飞星火提供了三种不同的API模型供用户选择:Spark3.5 Max、Spark Pro、Spark Lite。这些模型均具备不同的性能和功能特点,以满足不同用户的需求。目前,这些模型都提供了免费的调用额度,供用户试用和体验。
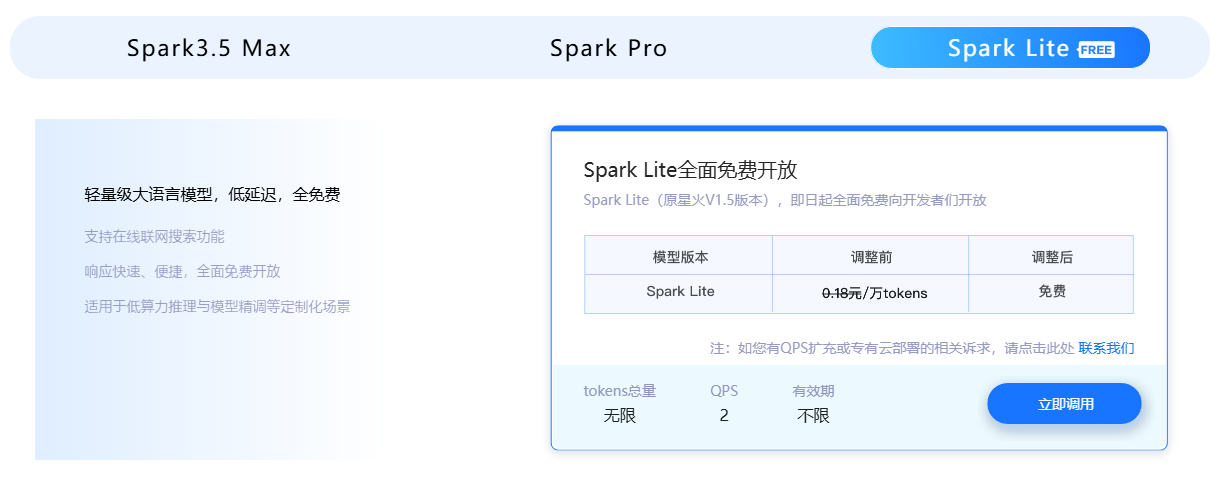
讯飞星火Lite API永久免费开放!

讯飞星火Pro/Max API免费赠送200万tokens,相当于三百万汉字。
链接:https://xinghuo.xfyun.cn/sparkapi?ch=gjaa
通过本文你能力学到:
- Python调用方式
作为广泛使用的编程语言,Python提供了方便的接口来调用讯飞星火的API。您可以通过官方文档获取Python SDK,并按照指南进行调用。 - 其他调用方式
除了Python,讯飞星火也支持其他编程语言的调用方式。您可以在官方文档中查找对应的SDK或API接口,以适应您的开发需求。
Spark3.5 Max/Spark Pro/Spark Lite的区别
讯飞星火Spark3.5 Max:最强大的星火大模型版本,效果最优支持联网搜索、天气、日期等多个内置插件核心能力全面升级,各场景应用效果普遍提升支持System角色人设与FunctionCall函数调用。讯飞星火Spark3.5 Max所有套餐价格:

讯飞星火Spark Pro:专业级大语言模型,兼顾模型效果与性能。数学、代码、医疗、教育等场景专项优化支持联网搜索、天气、日期等多个内置插件。覆盖大部分知识问答、语言理解、文本创作等多个场景。讯飞星火Spark Pro所有套餐价格:
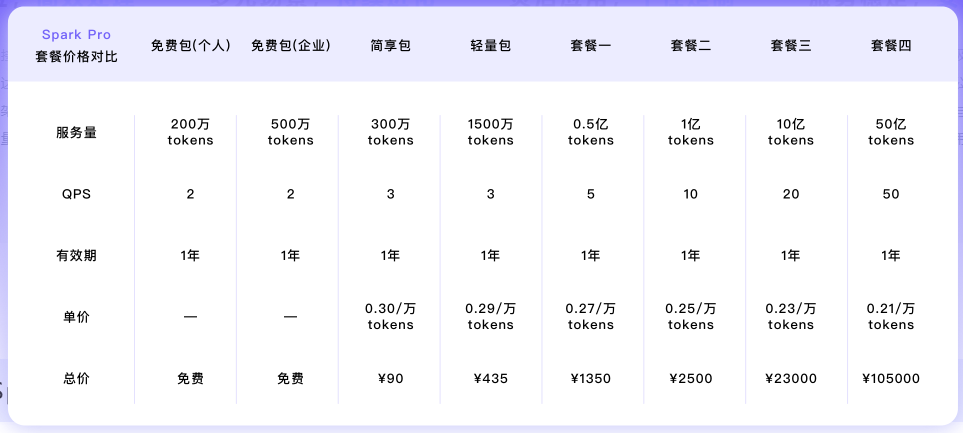
讯飞星火 Spark Lite:轻量级大语言模型,低延迟,全免费。支持在线联网搜索功能,响应快速、便捷,全面免费开放,适用于低算力推理与模型精调等定制化场景。Spark Lite免费向大家开放!

支持的能力
API调用支持的方式
支持的方式有:WebAPI、安卓、IOS、Windows、Linux等多种方式。

注意事项:
关于Web接口的说明:
必须符合 websocket 协议规范(rfc6455)。
websocket握手成功后用户在60秒内没有发送请求数据,服务侧会主动断开。
本接口默认采用短链接的模式,即接口每次将结果完整返回给用户后会主动断开链接,用户在下次发送请求的时候需要重新握手链接。
关于SDK的说明:
高效接入:SDK统一封装鉴权模块,接口简单最快三步完成SDK集成接入
稳定可靠: 统一连接池保障连接时效性,httpDNS保障请求入口高可用性
配套完善:支持多路并发用户回调上下文绑定,交互历史管理及排障日志回传收集
多平台兼容:覆盖Windows,Linux,Android,iOS以及其他交叉编译平台
关于tokens的说明(重要):
接口采用tokens方式计费。
tokens与词表、分词方案相关,没有精确的计算方式,但是接口会返回本次计费的tokens数(详见接口文档响应参数描述)。
接口计费会将请求text字段下所有的content内容均计费,开发者需要酌情考虑保留的历史对话信息数量,避免浪费tokens(最大的输入tokens见接口文档参数描述)。
关于文本审核说明(重要):
接口会对用户输入和AI输出内容进行文本审核,会对包括但不限于:(1) 涉及国家安全的信息;(2) 涉及政治与宗教类的信息;(3) 涉及暴力与恐怖主义的信息;(4) 涉及黄赌毒类的信息;(5) 涉及不文明的信息 的输入输出赋予错误码返回(详见错误码部分10013和10014说明)
在线调试
打开链接:https://xinghuo.xfyun.cn/sparkapi?ch=gjaa,选择在线调试:
然后,注册账号,选择一种方式登录,如下图:
创建一个应用,如下图:
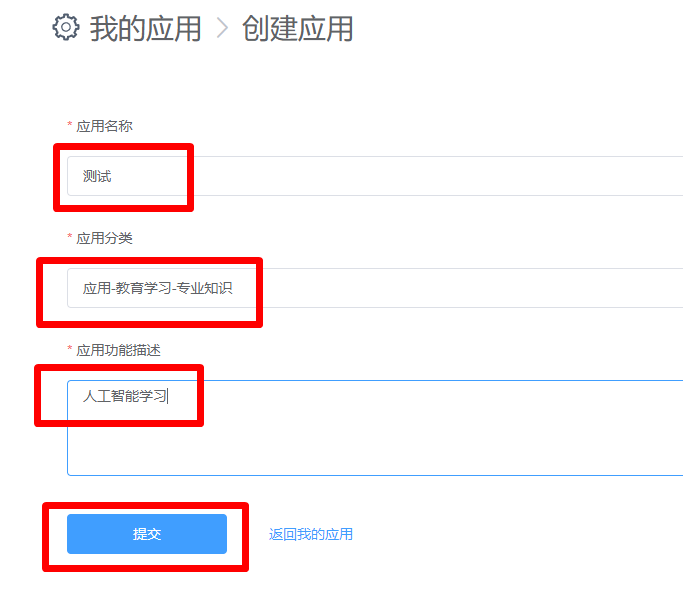
然后,我们填写内容,如下:

发现不能调用,为啥呢?我们还没有领取tokens,所以下一步先领取tokens。链接:https://xinghuo.xfyun.cn/sparkapi?scr=true,

选择我们刚才建立的应用测试,选择免费包,如下图:

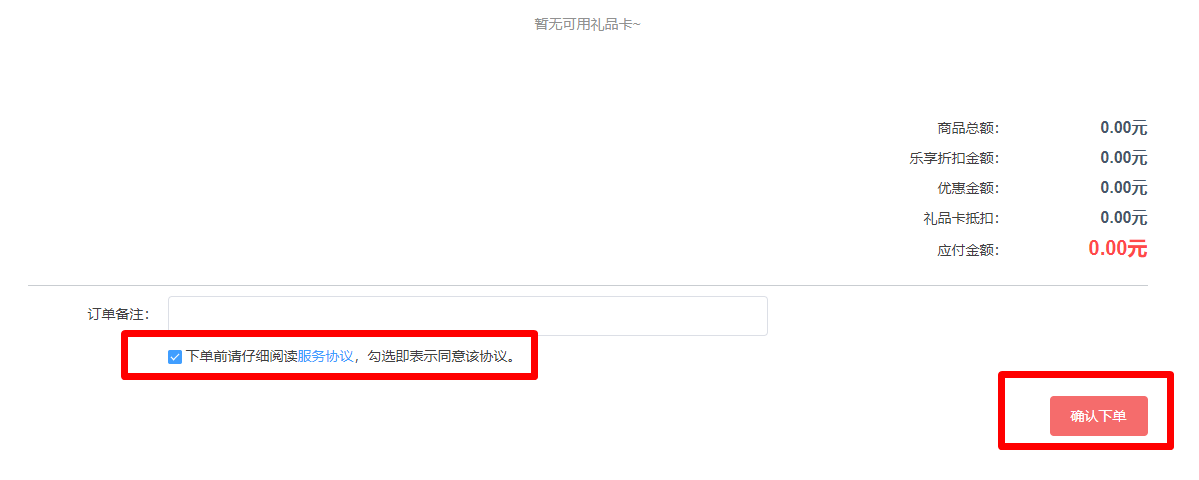
填写好后,下单即可!

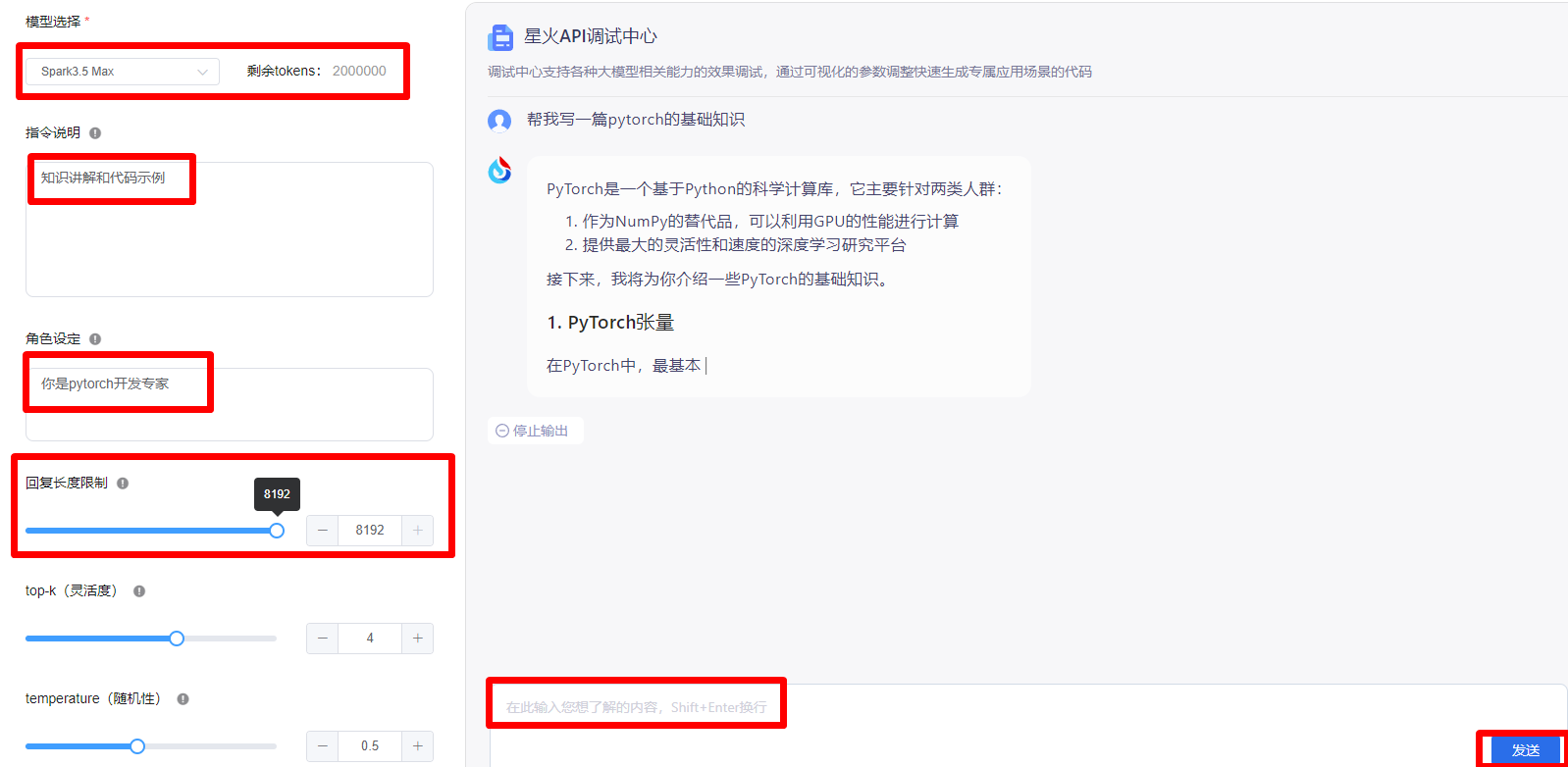
显示交易成功后,就可以调试了!选择模型,设置指令,角色设定,回复长度等。写完之后,就可以在输入框里填写你想要输出的内容。如下图:
星火认知大模型Web API调用文档
在上面完成在线调试后,点击更多服务信息查询,如下图:
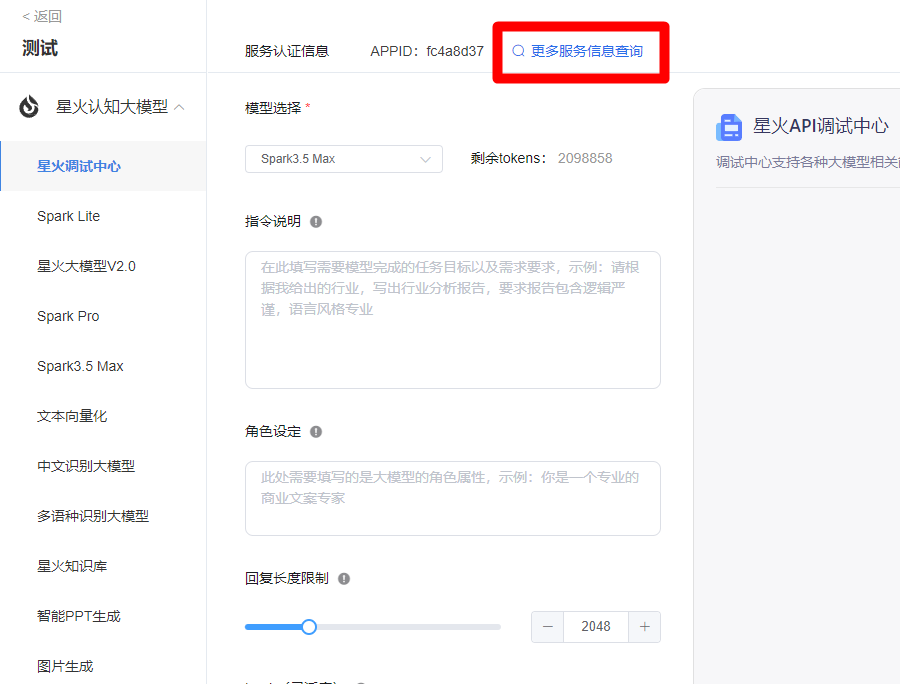
然后找到APP_ID、API_SECRET、API_KEY 等信息,如下图: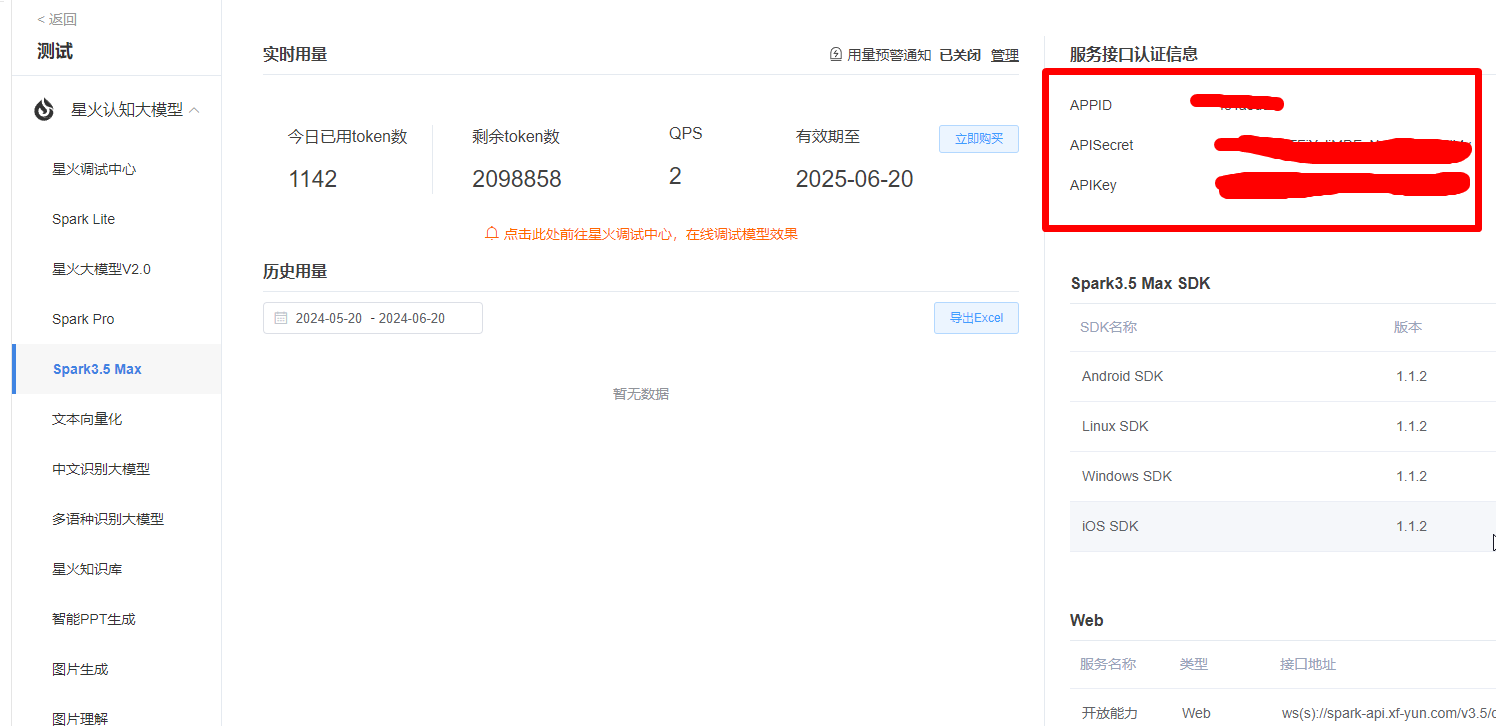
Python集成星火认知大模型示例
首先,安装PyPI上的包,在python环境中执行命令,命令如下:
pip install --upgrade spark_ai_python
然后,执行代码:
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage#星火认知大模型Spark3.5 Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
#星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看
SPARKAI_APP_ID = ''
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ''
#星火认知大模型Spark3.5 Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = 'generalv3.5'if __name__ == '__main__':spark = ChatSparkLLM(spark_api_url=SPARKAI_URL,spark_app_id=SPARKAI_APP_ID,spark_api_key=SPARKAI_API_KEY,spark_api_secret=SPARKAI_API_SECRET,spark_llm_domain=SPARKAI_DOMAIN,streaming=False,)messages = [ChatMessage(role="user",content='你好呀')]handler = ChunkPrintHandler()a = spark.generate([messages], callbacks=[handler])print(a)
输出结果:
generations=[[ChatGeneration(text="PyTorch是一个基于Python的科学计算库,主要用于深度学习研究和开发。它提供了两个高级功能:张量计算(类似于NumPy)和深度神经网络。以下是一些PyTorch基础知识:\n\n1. 安装PyTorch:\n\n```bash\npip install torch torchvision\n```\n\n2. 导入库:\n\n```python\nimport torch\n```\n\n3. 张量:\n\n张量是PyTorch中的基本数据结构,类似于多维数组。可以使用`torch.Tensor()`创建张量,或者使用`torch.randn()`创建一个随机张量。\n\n```python\n# 创建一个2x3的浮点数张量\nx = torch.Tensor([[1, 2, 3], [4, 5, 6]])\nprint(x)\n\n# 创建一个2x3的随机张量\ny = torch.randn(2, 3)\nprint(y)\n```\n\n4. 张量操作:\n\n张量支持各种操作,如加法、乘法、索引等。\n\n```python\n# 张量加法\nz = torch.add(x, y)\nprint(z)\n\n# 张量乘法\nz = torch.mul(x, y)\nprint(z)\n\n# 张量索引\nprint(x[:, 1])\n```\n\n5. 自动求导:\n\nPyTorch中的张量默认是可自动求导的,这对于训练神经网络非常有用。可以使用`.requires_grad_()`方法将张量设置为可求导。\n\n```python\n# 创建一个可求导的张量\nx = torch.ones(2, 2, requires_grad=True)\nprint(x)\n\n# 计算梯度\ny = x + 2\nz = y * y * 3\nout = z.mean()\nprint(out)\n\n# 反向传播\nout.backward()\nprint(x.grad)\n```\n\n6. 神经网络:\n\n使用`torch.nn`模块可以定义神经网络。首先定义一个继承自`torch.nn.Module`的类,然后实现`__init__()`和`forward()`方法。\n\n```python\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nclass Net(nn.Module):\n def __init__(self):\n super(Net, self).__init__()\n self.conv1 = nn.Conv2d(1, 6, 3)\n self.conv2 = nn.Conv2d(6, 16, 3)\n self.fc1 = nn.Linear(16 * 6 * 6, 120)\n self.fc2 = nn.Linear(120, 84)\n self.fc3 = nn.Linear(84, 10)\n\n def forward(self, x):\n x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))\n x = F.max_pool2d(F.relu(self.conv2(x)), 2)\n x = x.view(-1, self.num_flat_features(x))\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = self.fc3(x)\n return x\n\n def num_flat_features(self, x):\n size = x.size()[1:]\n num_features = 1\n for s in size:\n num_features *= s\n return num_features\n\nnet = Net()\nprint(net)\n```\n\n7. 训练神经网络:\n\n使用`torch.optim`模块中的优化器(如SGD、Adam等)来训练神经网络。在每个训练循环中,执行前向传播、计算损失、反向传播和优化器更新权重。\n\n```python\n# 定义超参数\ninput_size = 784\nhidden_size = 500\nnum_classes = 10\nnum_epochs = 5\nbatch_size = 100\nlearning_rate = 0.001\n\n# 加载MNIST数据集\ntrain_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)\ntest_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=torchvision.transforms.ToTensor())\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)\ntest_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)\n\n# 定义模型、损失函数和优化器\nmodel = Net()\ncriterion = nn.CrossEntropyLoss()\noptimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)\n\n# 训练模型\nfor epoch in range(num_epochs):\n for i, (images, labels) in enumerate(train_loader):\n images = images.view(-1, 28*28)\n outputs = model(images)\n loss = criterion(outputs, labels)\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n if (i+1) % 100 == 0:\n print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, len(train_loader), loss.item()))\n```", message=AIMessage(content="PyTorch是一个基于Python的科学计算库,主要用于深度学习研究和开发。它提供了两个高级功能:张量计算(类似于NumPy)和深度神经网络。以下是一些PyTorch基础知识:\n\n1. 安装PyTorch:\n\n```bash\npip install torch torchvision\n```\n\n2. 导入库:\n\n```python\nimport torch\n```\n\n3. 张量:\n\n张量是PyTorch中的基本数据结构,类似于多维数组。可以使用`torch.Tensor()`创建张量,或者使用`torch.randn()`创建一个随机张量。\n\n```python\n# 创建一个2x3的浮点数张量\nx = torch.Tensor([[1, 2, 3], [4, 5, 6]])\nprint(x)\n\n# 创建一个2x3的随机张量\ny = torch.randn(2, 3)\nprint(y)\n```\n\n4. 张量操作:\n\n张量支持各种操作,如加法、乘法、索引等。\n\n```python\n# 张量加法\nz = torch.add(x, y)\nprint(z)\n\n# 张量乘法\nz = torch.mul(x, y)\nprint(z)\n\n# 张量索引\nprint(x[:, 1])\n```\n\n5. 自动求导:\n\nPyTorch中的张量默认是可自动求导的,这对于训练神经网络非常有用。可以使用`.requires_grad_()`方法将张量设置为可求导。\n\n```python\n# 创建一个可求导的张量\nx = torch.ones(2, 2, requires_grad=True)\nprint(x)\n\n# 计算梯度\ny = x + 2\nz = y * y * 3\nout = z.mean()\nprint(out)\n\n# 反向传播\nout.backward()\nprint(x.grad)\n```\n\n6. 神经网络:\n\n使用`torch.nn`模块可以定义神经网络。首先定义一个继承自`torch.nn.Module`的类,然后实现`__init__()`和`forward()`方法。\n\n```python\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nclass Net(nn.Module):\n def __init__(self):\n super(Net, self).__init__()\n self.conv1 = nn.Conv2d(1, 6, 3)\n self.conv2 = nn.Conv2d(6, 16, 3)\n self.fc1 = nn.Linear(16 * 6 * 6, 120)\n self.fc2 = nn.Linear(120, 84)\n self.fc3 = nn.Linear(84, 10)\n\n def forward(self, x):\n x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))\n x = F.max_pool2d(F.relu(self.conv2(x)), 2)\n x = x.view(-1, self.num_flat_features(x))\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = self.fc3(x)\n return x\n\n def num_flat_features(self, x):\n size = x.size()[1:]\n num_features = 1\n for s in size:\n num_features *= s\n return num_features\n\nnet = Net()\nprint(net)\n```\n\n7. 训练神经网络:\n\n使用`torch.optim`模块中的优化器(如SGD、Adam等)来训练神经网络。在每个训练循环中,执行前向传播、计算损失、反向传播和优化器更新权重。\n\n```python\n# 定义超参数\ninput_size = 784\nhidden_size = 500\nnum_classes = 10\nnum_epochs = 5\nbatch_size = 100\nlearning_rate = 0.001\n\n# 加载MNIST数据集\ntrain_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)\ntest_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=torchvision.transforms.ToTensor())\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)\ntest_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)\n\n# 定义模型、损失函数和优化器\nmodel = Net()\ncriterion = nn.CrossEntropyLoss()\noptimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)\n\n# 训练模型\nfor epoch in range(num_epochs):\n for i, (images, labels) in enumerate(train_loader):\n images = images.view(-1, 28*28)\n outputs = model(images)\n loss = criterion(outputs, labels)\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n if (i+1) % 100 == 0:\n print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, len(train_loader), loss.item()))\n```"))]] llm_output={'token_usage': {'question_tokens': 7, 'prompt_tokens': 7, 'completion_tokens': 1359, 'total_tokens': 1366}} run=[RunInfo(run_id=UUID('7ff2abd7-11af-44da-b91d-6650c3ccfa0a'))]这篇关于如何调用讯飞星火认知大模型的API以利用其卓越功能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




