本文主要是介绍利用Python爬取天气数据并实现数据可视化,一个完整的Python项目案例讲解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

要使用Python爬取天气数据并进行制图分析分几个步骤进行:
-
选择数据源:首先,你需要找到一个提供天气数据的API或网站。一些常见的选择包括:OpenWeatherMap、Weatherbit、Weather Underground等。
-
安装必要的库:你需要安装
requests库来发送HTTP请求,以及matplotlib或seaborn等库来制图。如果你选择使用pandas来处理数据,还需要安装pandas。 -
发送请求并获取数据:使用
requests库向天气API发送请求,并解析返回的JSON或XML数据。 -
处理数据:将获取的数据转换为适合分析的形式,如pandas的DataFrame。
-
制图分析:使用
matplotlib或seaborn等库绘制图表,如折线图、柱状图、散点图等,来分析天气数据。
简化的示例流程:
1. 安装必要的库
pip install requests pandas matplotlib |
2. 发送请求并获取数据(以OpenWeatherMap为例)
首先,你需要在OpenWeatherMap上注册一个账户并获取一个API密钥。
import requests | |
import json | |
def fetch_weather_data(city, api_key): | |
url = f"http://api.openweathermap.org/data/2.5/weather?q={city}&appid={api_key}&units=metric" | |
response = requests.get(url) | |
response.raise_for_status() # 如果请求失败则抛出HTTPError异常 | |
data = response.json() | |
return data | |
# 示例:获取北京的天气数据 | |
city = 'Beijing' | |
api_key = 'YOUR_API_KEY' # 替换为你的API密钥 | |
weather_data = fetch_weather_data(city, api_key) |
3. 处理数据
import pandas as pd | |
def process_weather_data(data): | |
# 从JSON中提取你感兴趣的数据,例如温度和湿度 | |
temp = data['main']['temp'] | |
humidity = data['main']['humidity'] | |
# 你可以根据需要添加更多字段 | |
# 将数据放入DataFrame中(这里只是一个简单的例子,通常你会从API获取多天的数据) | |
df = pd.DataFrame({ | |
'Temperature (°C)': [temp], | |
'Humidity (%)': [humidity] | |
}) | |
return df | |
df = process_weather_data(weather_data) |
4. 制图分析
import matplotlib.pyplot as plt | |
def plot_weather_data(df): | |
# 绘制温度柱状图(这里只是一个简单的例子,你可以根据需要绘制不同类型的图表) | |
plt.bar(['Temperature'], df['Temperature (°C)'], color='blue') | |
plt.title('Weather Report for {}'.format(city)) | |
plt.xlabel('Parameter') | |
plt.ylabel('Value') | |
plt.xticks(rotation=45) | |
plt.show() | |
plot_weather_data(df) |
请注意,这个示例仅用于演示目的,并且仅包含了一个数据点的简单情况。在实际情况中,你可能会从API获取多天的天气数据,并对这些数据进行更复杂的分析和可视化。
全套Python学习资料分享:
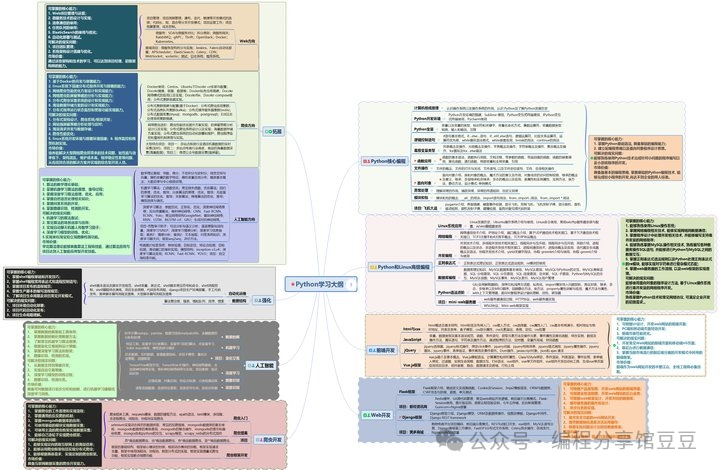
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
这篇关于利用Python爬取天气数据并实现数据可视化,一个完整的Python项目案例讲解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




