本文主要是介绍42、基于神经网络的训练堆叠自编码器进行图像分类(matlab),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、训练堆叠自编码器进行图像分类的原理及流程
基于神经网络的训练堆叠自编码器进行图像分类的原理和流程如下:
-
堆叠自编码器(Stacked Autoencoder)是一种无监督学习算法,由多个自编码器(Autoencoder)堆叠在一起构成。每个自编码器由一个编码器和一个解码器组成,用于学习数据的有效表示。
-
在图像分类任务中,首先将输入图像通过编码器部分提取特征,然后通过解码器将提取的特征重构为原始图像。通过重复此过程多次,可以逐渐提高模型对数据的表示能力。
-
堆叠自编码器的训练过程包括以下步骤:
- 输入图像经过第一个编码器得到第一层的特征表示;
- 将第一层的特征表示输入到第二个编码器中,再经过解码器重构为原始图像,得到第二层的特征表示;
- 重复上述步骤直到所有的编码器和解码器都被训练完成。
-
训练堆叠自编码器的目标是最小化重构误差,即原始图像与重构图像之间的差异。通过反向传播算法来更新网络参数,使得重构误差最小化。
-
训练完成后,可以将堆叠自编码器的编码器部分作为特征提取器,将提取的特征输入到分类器中进行图像分类任务。
总的来说,基于神经网络的训练堆叠自编码器进行图像分类的流程是通过无监督学习训练多个自编码器,逐步从原始输入中提取特征,最终将提取的特征输入到分类器中进行图像分类任务。
2、 训练堆叠自编码器进行图像分类说明
说明1
具有多个隐含层的神经网络可用于处理复杂数据(例如图像)的分类问题。
每个层都可以学习不同抽象级别的特征。一种有效训练具有多个层的神经网络的方法是一次训练一个层。可以为每个所需的隐含层训练一种称为自编码器的特殊类型的网络。
说明2
训练具有两个隐含层的神经网络以对图像中的数字进行分类。首先,使用自编码器以无监督方式单独训练各隐含层。然后训练最终 softmax 层,并将这些层连接在一起形成堆叠网络,该网络最后以有监督方式进行训练。
3、数据集
说明
使用合成数据进行训练和测试。通过对使用不同字体创建的数字图像应用随机仿射变换来生成合成图像。
每个数字图像为 28×28 像素,共有 5000 个训练样本。可以加载训练数据,并查看其中一些图像。
图像的标签存储在一个 10×5000 矩阵中,其中每列都有一个元素为 1,指示该数字所属的类,该列中的所有其他元素为 0。请注意,如果第十个元素是 1,则数字图像是零。
1)加载训练数据到内存
代码
[xTrainImages,tTrain] = digitTrainCellArrayData;2)展示训练图片
代码
clf
figure(1)
for i = 1:25subplot(5,5,i);imshow(xTrainImages{i});
end试图效果

4、训练第一个自编码器
说明
在不使用标签的情况下基于训练数据训练稀疏自编码器
自编码器是一种神经网络,该网络会尝试在其输出端复制其输入。因此,其输入的大小将与其输出的大小相同。当隐藏层中的神经元数量小于输入的大小时,自编码器将学习输入的压缩表示。神经网络在训练前具有随机初始化的权重。因此,每次训练的结果都不同。
1)显式设置随机数生成器种子
代码
rng('default')2)设置自编码器的隐含层的大小。
说明:对于要训练的自编码器,最好使隐含层的大小小于输入大小。
代码
hiddenSize1 = 100;3)训练的自编码器的类型是稀疏自编码器
说明:该自编码器使用正则项来学习第一层中的稀疏表示。可以设置各种参数来控制这些正则项的影响:
L2WeightRegularization 控制 L2 正则项对网络权重(而不是偏置)的影响。这通常应该非常小。
SparsityRegularization 控制稀疏正则项的影响,该正则项会尝试对隐含层的输出的稀疏性施加约束。请注意,这与将稀疏正则项应用于权重不同。
SparsityProportion 是稀疏正则项的参数。它控制隐含层的输出的稀疏性。较SparsityProportion 值通常导致只为少数训练样本提供高输出,从而使隐藏层中的每个神经元“专门化”。例如,如果 SparsityProportion 设置为 0.1,这相当于说隐藏层中的每个神经元针对训练样本的平均输出值应该为 0.1。此值必须介于 0 和 1 之间。理想值因问题的性质而异。
现在训练自编码器,指定上述正则项的值代码
autoenc1 = trainAutoencoder(xTrainImages,hiddenSize1, ...'MaxEpochs',400, ...'L2WeightRegularization',0.004, ...'SparsityRegularization',4, ...'SparsityProportion',0.15, ...'ScaleData', false);
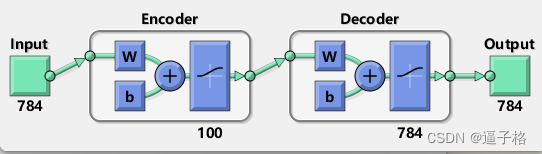
view(autoenc1)视图效果
说明:自编码器由一个编码器和一个解码器组成。编码器将输入映射为隐含表示,解码器则尝试进行逆映射以重新构造原始输入。

5、可视化第一个自编码器的权重
说明
自编码器的编码器部分所学习的映射可用于从数据中提取特征。编码器中的每个神经元都具有一个与之相关联的权重向量,该向量将进行相应调整以响应特定可视化特征。您可以查看这些特征的表示。
自编码器学习的特征代表了数字图像中的弯曲和笔划图案。
自编码器的隐含层的 100 维输出是输入的压缩版本,它汇总了对上面可视化的特征的响应。基于从训练数据中提取的一组向量训练下一个自编码器。首先,必须使用经过训练的自编码器中的编码器生成特征。
代码
figure(2)
plotWeights(autoenc1);
feat1 = encode(autoenc1,xTrainImages);视图效果

6、训练第二个自编码器
说明
以相似的方式训练第二个自编码器。主要区别在于使用从第一个自编码器生成的特征作为第二个自编码器中的训练数据。此外,您还需要将隐含表示的大小减小到 50,以便第二个自编码器中的编码器学习输入数据的更小表示。
代码
hiddenSize2 = 50;
autoenc2 = trainAutoencoder(feat1,hiddenSize2, ...'MaxEpochs',100, ...'L2WeightRegularization',0.002, ...'SparsityRegularization',4, ...'SparsityProportion',0.1, ...'ScaleData', false);
%使用 view 函数查看自编码器的图。
view(autoenc2)视图效果
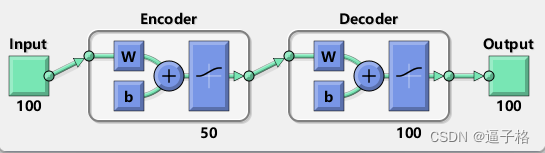
将前一组特征传递给第二个自编码器中的编码器,以此提取第二组特征
说明:训练数据中的原始向量具有 784 个维度。原始数据通过第一个编码器后,维度减小到 100 维。应用第二个编码器后,维度进一步减小到 50 维。您现在可以训练最终层,以将这些 50 维向量分类为不同的数字类。
代码
feat2 = encode(autoenc2,feat1);7、 训练最终 softmax 层
说明
训练 softmax 层以对 50 维特征向量进行分类。与自编码器不同,您将使用训练数据的标签以有监督方式训练 softmax 层。
代码
%说明:训练 softmax 层以对 50 维特征向量进行分类。与自编码器不同,您将使用训练数据的标签以有监督方式训练 softmax 层。
softnet = trainSoftmaxLayer(feat2,tTrain,'MaxEpochs',400);
%view 函数查看 softmax 层的图。
view(softnet)视图效果

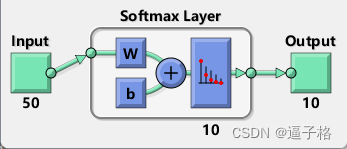
8、 形成堆叠神经网络
说明
已单独训练了组成堆叠神经网络的三个网络。可以查看已经过训练的三个神经网络 autoenc1、autoenc2 和 softnet。
1)形成用于分类的堆叠网络
代码
自编码器中的编码器已用于提取特征。可以将自编码器中的编码器与 softmax 层堆叠在一起,以形成用于分类的堆叠网络。
stackednet = stack(autoenc1,autoenc2,softnet);
% view 函数查看堆叠网络的图。该网络由自编码器中的编码器和 softmax 层构成。
view(stackednet)视图效果
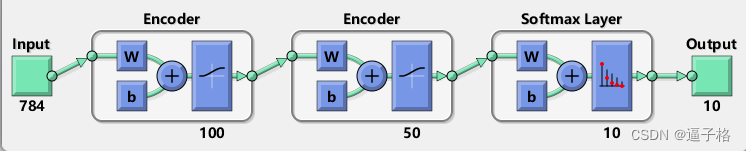
2)基于测试集计算结果
说明:基于测试集计算结果。要将图像用于堆叠网络,必须将测试图像重构为矩阵。这可以通过先堆叠图像的各列以形成向量,然后根据这些向量形成矩阵来完成。
代码
% 获取图片像素
imageWidth = 28;
imageHeight = 28;
inputSize = imageWidth*imageHeight;
% 加载测试图片
[xTestImages,tTest] = digitTestCellArrayData;% 堆叠图像的各列以形成向量,然后根据这些向量形成矩阵
xTest = zeros(inputSize,numel(xTestImages));
for i = 1:numel(xTestImages)xTest(:,i) = xTestImages{i}(:);
end
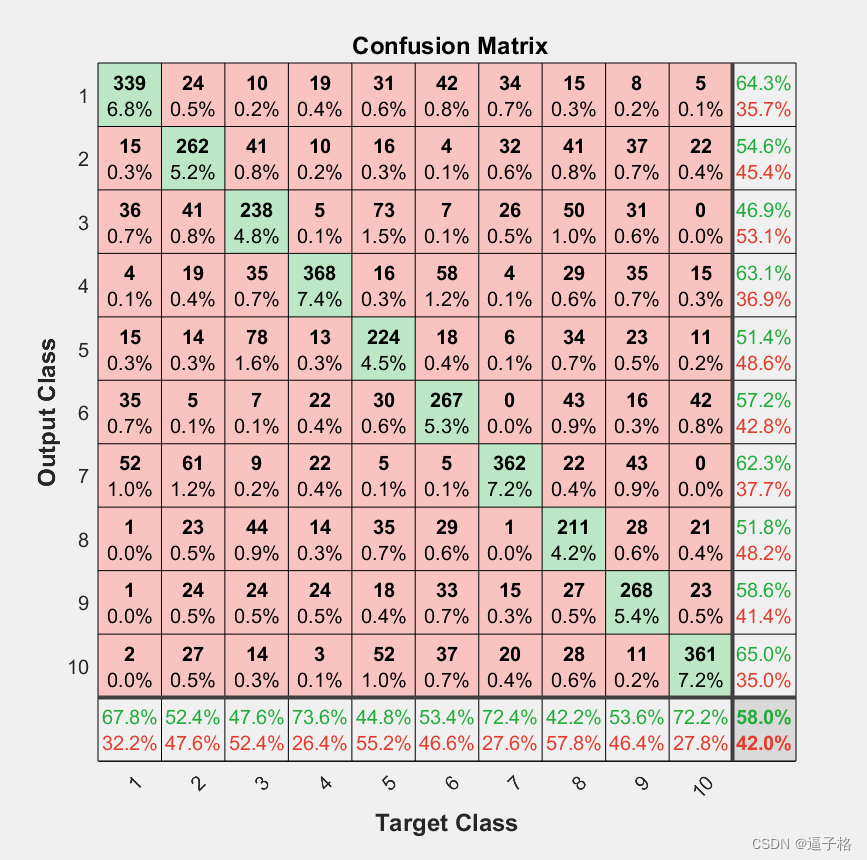
%使用混淆矩阵来可视化结果。矩阵右下角方块中的数字表示整体准确度。
y = stackednet(xTest);
plotconfusion(tTest,y);视图效果
9、 微调堆叠神经网络
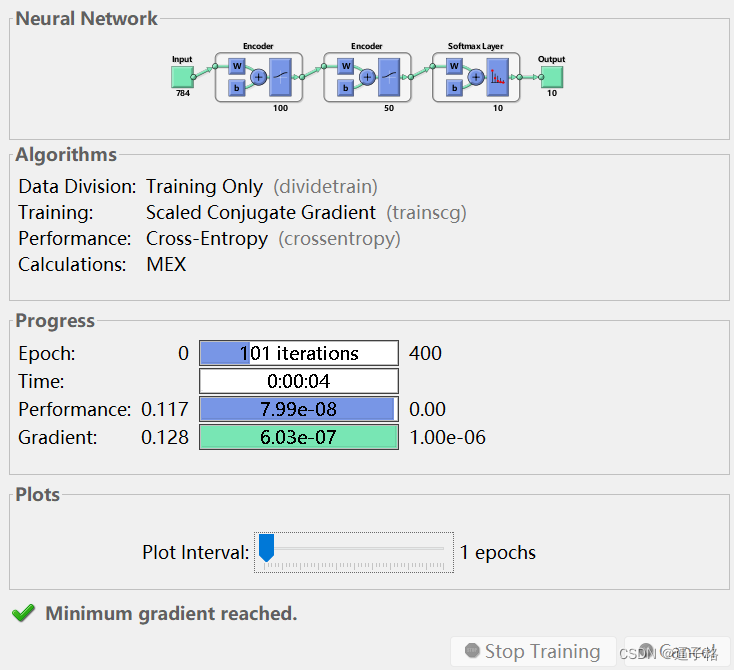
说明
通过对整个多层网络执行反向传播,可以改进堆叠神经网络的结果。此过程通常称为微调。通过以有监督方式基于训练数据重新训练网络来微调网络。将训练图像重构为矩阵,就像对测试图像所做的那样。
1)堆叠图像的各列以形成向量,然后根据这些向量形成矩阵
代码
xTrain = zeros(inputSize,numel(xTrainImages));
for i = 1:numel(xTrainImages)xTrain(:,i) = xTrainImages{i}(:);
end2)微调执行
代码
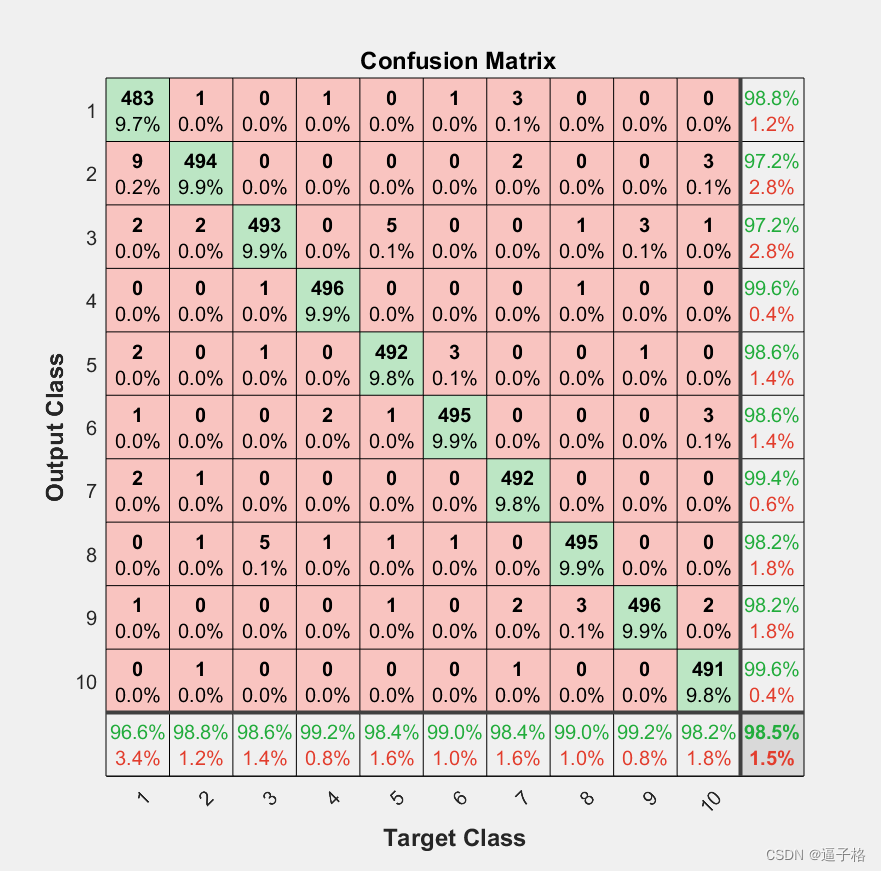
stackednet = train(stackednet,xTrain,tTrain);3) 使用混淆矩阵再次查看结果
代码
y = stackednet(xTest);
plotconfusion(tTest,y);视图效果
10、总结
在Matlab中基于神经网络的训练堆叠自编码器进行图像分类可以按照以下步骤进行:
-
数据准备:准备图像数据集,并对图像进行预处理,如缩放、归一化等操作。
-
构建自编码器模型:使用Matlab的深度学习工具箱(Deep Learning Toolbox)构建堆叠自编码器模型。根据需要的深度,堆叠多个自编码器,每个自编码器包括编码器和解码器部分。
-
定义训练参数:设置训练参数,包括学习率、迭代次数、优化器等。
-
训练模型:使用训练数据集对堆叠自编码器模型进行训练,通过计算重构误差来更新模型参数。
-
特征提取:训练完成后,提取编码器部分作为特征提取器,对数据进行特征提取。
-
构建分类器:使用Matlab内置的分类器算法(如支持向量机、K近邻等)或者构建深度学习的分类器模型,将提取的特征输入到分类器中进行图像分类。
-
模型评估:使用测试数据集对训练好的模型进行评估和性能测试,评估模型的准确率、召回率等指标。
总的来说,在Matlab中进行基于神经网络的训练堆叠自编码器进行图像分类的流程包括数据准备、模型构建、训练、特征提取、分类器构建和模型评估等步骤。通过这个过程,可以实现图像分类任务并得到准确的分类结果。
11、源代码
代码
%% 训练堆叠自编码器进行图像分类
%说明:具有多个隐含层的神经网络可用于处理复杂数据(例如图像)的分类问题。每个层都可以学习不同抽象级别的特征。
%一种有效训练具有多个层的神经网络的方法是一次训练一个层。可以为每个所需的隐含层训练一种称为自编码器的特殊类型的网络。
%说明:训练具有两个隐含层的神经网络以对图像中的数字进行分类。首先,使用自编码器以无监督方式单独训练各隐含层。然后训练最终 softmax 层,
%并将这些层连接在一起形成堆叠网络,该网络最后以有监督方式进行训练。
%% 数据集
%说明:使用合成数据进行训练和测试。通过对使用不同字体创建的数字图像应用随机仿射变换来生成合成图像。
%每个数字图像为 28×28 像素,共有 5000 个训练样本。可以加载训练数据,并查看其中一些图像。
%图像的标签存储在一个 10×5000 矩阵中,其中每列都有一个元素为 1,指示该数字所属的类,该列中的所有其他元素为 0。请注意,如果第十个元素是 1,则数字图像是零。
% 加载训练数据到内存
[xTrainImages,tTrain] = digitTrainCellArrayData;
% 展示训练图片
clf
figure(1)
for i = 1:25subplot(5,5,i);imshow(xTrainImages{i});
end
%% 训练第一个自编码器
%说明:在不使用标签的情况下基于训练数据训练稀疏自编码器
%自编码器是一种神经网络,该网络会尝试在其输出端复制其输入。因此,其输入的大小将与其输出的大小相同。当隐藏层中的神经元数量小于输入的大小时,自编码器将学习输入的压缩表示。
%神经网络在训练前具有随机初始化的权重。因此,每次训练的结果都不同。
%显式设置随机数生成器种子。
rng('default')
%设置自编码器的隐含层的大小。对于要训练的自编码器,最好使隐含层的大小小于输入大小。
hiddenSize1 = 100;
%训练的自编码器的类型是稀疏自编码器。该自编码器使用正则项来学习第一层中的稀疏表示。可以设置各种参数来控制这些正则项的影响:
%L2WeightRegularization 控制 L2 正则项对网络权重(而不是偏置)的影响。这通常应该非常小。
%SparsityRegularization 控制稀疏正则项的影响,该正则项会尝试对隐含层的输出的稀疏性施加约束。请注意,这与将稀疏正则项应用于权重不同。
%SparsityProportion 是稀疏正则项的参数。它控制隐含层的输出的稀疏性。较低的 SparsityProportion 值通常导致只为少数训练样本提供高输出,从而使隐藏层中的每个神经元“专门化”。例如,如果 SparsityProportion 设置为 0.1,这相当于说隐藏层中的每个神经元针对训练样本的平均输出值应该为 0.1。此值必须介于 0 和 1 之间。理想值因问题的性质而异。
%现在训练自编码器,指定上述正则项的值。
autoenc1 = trainAutoencoder(xTrainImages,hiddenSize1, ...'MaxEpochs',400, ...'L2WeightRegularization',0.004, ...'SparsityRegularization',4, ...'SparsityProportion',0.15, ...'ScaleData', false);
%自编码器由一个编码器和一个解码器组成。编码器将输入映射为隐含表示,解码器则尝试进行逆映射以重新构造原始输入。
view(autoenc1)
%% 可视化第一个自编码器的权重
%自编码器的编码器部分所学习的映射可用于从数据中提取特征。编码器中的每个神经元都具有一个与之相关联的权重向量,该向量将进行相应调整以响应特定可视化特征。您可以查看这些特征的表示。
%自编码器学习的特征代表了数字图像中的弯曲和笔划图案。
%自编码器的隐含层的 100 维输出是输入的压缩版本,它汇总了对上面可视化的特征的响应。基于从训练数据中提取的一组向量训练下一个自编码器。首先,必须使用经过训练的自编码器中的编码器生成特征。
figure(2)
plotWeights(autoenc1);
feat1 = encode(autoenc1,xTrainImages);
%% 训练第二个自编码器
%说明:以相似的方式训练第二个自编码器。主要区别在于使用从第一个自编码器生成的特征作为第二个自编码器中的训练数据。此外,您还需要将隐含表示的大小减小到 50,以便第二个自编码器中的编码器学习输入数据的更小表示。
hiddenSize2 = 50;
autoenc2 = trainAutoencoder(feat1,hiddenSize2, ...'MaxEpochs',100, ...'L2WeightRegularization',0.002, ...'SparsityRegularization',4, ...'SparsityProportion',0.1, ...'ScaleData', false);
%使用 view 函数查看自编码器的图。
view(autoenc2)
%将前一组特征传递给第二个自编码器中的编码器,以此提取第二组特征。
feat2 = encode(autoenc2,feat1);
%训练数据中的原始向量具有 784 个维度。原始数据通过第一个编码器后,维度减小到 100 维。应用第二个编码器后,维度进一步减小到 50 维。您现在可以训练最终层,以将这些 50 维向量分类为不同的数字类。
%% 训练最终 softmax 层
%说明:训练 softmax 层以对 50 维特征向量进行分类。与自编码器不同,您将使用训练数据的标签以有监督方式训练 softmax 层。
softnet = trainSoftmaxLayer(feat2,tTrain,'MaxEpochs',400);
%view 函数查看 softmax 层的图。
view(softnet)
%% 形成堆叠神经网络
%已单独训练了组成堆叠神经网络的三个网络。可以查看已经过训练的三个神经网络 autoenc1、autoenc2 和 softnet。
view(autoenc1)
view(autoenc2)
view(softnet)
%自编码器中的编码器已用于提取特征。可以将自编码器中的编码器与 softmax 层堆叠在一起,以形成用于分类的堆叠网络。
stackednet = stack(autoenc1,autoenc2,softnet);
% view 函数查看堆叠网络的图。该网络由自编码器中的编码器和 softmax 层构成。
view(stackednet)
%基于测试集计算结果。要将图像用于堆叠网络,必须将测试图像重构为矩阵。这可以通过先堆叠图像的各列以形成向量,然后根据这些向量形成矩阵来完成。
% 获取图片像素
imageWidth = 28;
imageHeight = 28;
inputSize = imageWidth*imageHeight;
% 加载测试图片
[xTestImages,tTest] = digitTestCellArrayData;% 堆叠图像的各列以形成向量,然后根据这些向量形成矩阵
xTest = zeros(inputSize,numel(xTestImages));
for i = 1:numel(xTestImages)xTest(:,i) = xTestImages{i}(:);
end
%使用混淆矩阵来可视化结果。矩阵右下角方块中的数字表示整体准确度。
y = stackednet(xTest);
plotconfusion(tTest,y);
%% 微调堆叠神经网络
%说明:通过对整个多层网络执行反向传播,可以改进堆叠神经网络的结果。此过程通常称为微调。
%通过以有监督方式基于训练数据重新训练网络来微调网络。将训练图像重构为矩阵,就像对测试图像所做的那样。
% 堆叠图像的各列以形成向量,然后根据这些向量形成矩阵
xTrain = zeros(inputSize,numel(xTrainImages));
for i = 1:numel(xTrainImages)xTrain(:,i) = xTrainImages{i}(:);
end
% 微调执行
stackednet = train(stackednet,xTrain,tTrain);
% 使用混淆矩阵再次查看结果。
y = stackednet(xTest);
plotconfusion(tTest,y);这篇关于42、基于神经网络的训练堆叠自编码器进行图像分类(matlab)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





