本文主要是介绍算法设计与分析 实验3 回溯法求地图填色问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、实验目的
二、背景知识
三、实验内容
四、算法思想
未优化的回溯算法
节点选择-最小剩余值准则(MRV)
节点选择-最多约束准则(DH)
颜色选择-最少约束选择
数据结构的选择
向前探查
颜色轮换(贪心置换)
五、代码描述
简单回溯算法实现
MRV&& DH算法实现
最少约束值准则(颜色)算法实现
向前探查算法实现
颜色轮换算法实现
六、实验结果和分析
得到一个可行解
得到全部可行解
自行生成地图涂色以及分析
七、实验结论
一、实验目的
1. 掌握回溯法算法设计思想。
2. 掌握地图填色问题的回溯法解法。
二、背景知识
为地图或其他由不同区域组成的图形着色时,相邻国家/地区不能使用相同的颜色。我们可能还想使用尽可能少的不同颜色进行填涂。一些简单的“地图”(例如棋盘)仅需要两种颜色(黑白),但是大多数复杂的地图需要更多颜色。
每张地图包含四个相互连接的国家时,它们至少需要四种颜色。1852年,植物学专业的学生弗朗西斯·古思里(Francis Guthrie)于1852年首次提出“四色问题”。他观察到四种颜色似乎足以满足他尝试的任何地图填色问题,但他无法找到适用于所有地图的证明。这个问题被称为四色问题。长期以来,数学家无法证明四种颜色就够了,或者无法找到需要四种以上颜色的地图。直到1976年德国数学家沃尔夫冈·哈肯(Wolfgang Haken,生于1928年)和肯尼斯·阿佩尔(Kenneth Appel,1932年-2013年)使用计算机证明了四色定理,他们将无数种可能的地图缩减为1936种特殊情况,每种情况都由一台计算机进行了总计超过1000个小时的检查。他们因此工作获得了美国数学学会富尔克森奖。在1990年,哈肯成为伊利诺伊大学高级研究中心的成员,他现在是该大学的名誉教授。
四色定理是第一个使用计算机证明的著名数学定理,此后变得越来越普遍,争议也越来越小。更快的计算机和更高效的算法意味着今天您可以在几个小时内在笔记本电脑上证明四种颜色定理。
三、实验内容
1. 用4色填色下面的这个小规模地图,测试算法的正确性。将其转换为平面图,每个地区表示为一个顶点,相邻地区用边连接,对这个图的顶点着色,并且相邻的两个顶必须使用不同的颜色。
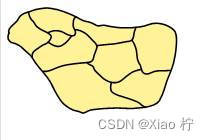
图1 测试算法正确性的小规模地图
2. 分别读入附件中的3个图文件le450_5a.col, le450_15b.col, le450_25a.col,其中,le450_5a.col中的图用5色着色,le450_15b.col中的图用15色着色,le450_25a.col中的图用25色着色,测试3个图文件对应的算法运行时间,并将着色结果输出到文本中(按照顶点序号输出每个顶点的颜色,每个颜色占1行,颜色用1, 2, 3, …表示,着色结果文件名为相应的图文件名加上后缀out,即分别为le450_5a.col.out, le450_15b.col.out, le450_25a.col.out),运行附件中的check.exe程序测试着色结果是否正确。在公共的Linux服务器上测试该项实验内容,实验课时检查,步骤如下:
(i) 在文件资源管理器中打开ftp://hpc.szu.edu.cn,输入用户名algo,密码szu@1983,在当前目录下新建一个子目录,目录名为自己学号,将算法代码重命名为a.cpp,将算法代码和3个图文件都上传到该目录中。
(ii) 打开Windows PowerShell,执行命令ssh algo@hpc.szu.edu.cn,输入密码szu@1983;再执行命令ssh A1,登录到A1机器上;进入自己的目录,执行命令g++ -O3 -fopenmp -o a.out a.cpp生成可执行程序a.out,再执行命令./a.out运行算法程序。
(iii) 在4分钟内完成该项测试,必须保证着色结果正确,可以只测试3个图文件中的部分图文件,尽可能优化算法,提高算法效率。
3. 随机产生不同规模的图,用4色着色,分析算法效率与图规模的关系。
四、算法思想
描述回溯法思想求解地图填色问题的思想,采用了哪些方法以提高算法效率。
未优化的回溯算法
首先使用简易回溯算法,用4色填色下面的这个小规模地图,测试算法的正确性。对于给定的地图,我先将其 转换为平面图,每个地区表示为一个顶点,相邻地区用边连接,方便后续对地图的处理,抽象化后的地图如下所示。
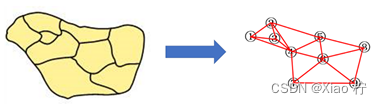
回溯算法描述
回溯法的思想就是从根结点出发深度探索解空间树。当探索到某一结点时,判断该结点是否包含问题的解。如果包含,就从该结点出发继续探索下去,如果该结点不包含问题的解,则向其祖先结点回溯。
算法实现
拓展当前节点,并对当前节点进行搜索
判断当前节点是否存在可行解,如果存在则进入c,如果不存在,则回溯上一节点,并进入a
判断是否搜索结束,如果结束则直接输出结果并停止搜索;如果未结束,则进入a
当全部搜索完毕后仍不存在可行解,则输出无解
代码模板格式
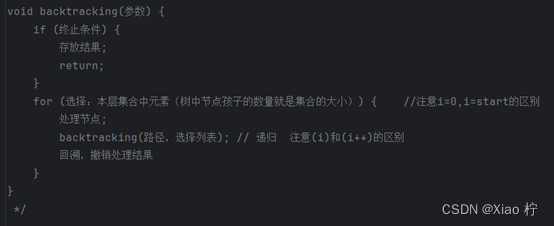
回溯算法的优化
由于朴素的回溯算法效率太低,并无法在短时间内找到可行解,因此我们需要想办法优化回溯算法,提高回溯效率。
在本实验中,我主要从节点选择,颜色选择以及数据结构选择三个方面来考虑剪枝优化的方法。
节点选择-最小剩余值准则(MRV)
算法描述
在节点选择方面,我优先考虑的使最小剩余值准则,即MRV。
MRV算法的内核在于在每次选择变量时,会优先选择剩余可选颜色数量最少的未染色节点进行搜索,即选择当前可用颜色最少的节点,这样便可以达到在进行搜索分层的早期尽可能减少搜索分支的数量,但不满足涂色要求(即满足剪枝条件)时,将其直接剪掉,省去了许多后面分支多的无用比较,从而大幅减少搜索空间,达到提高算法的效率。

优化前搜索情况
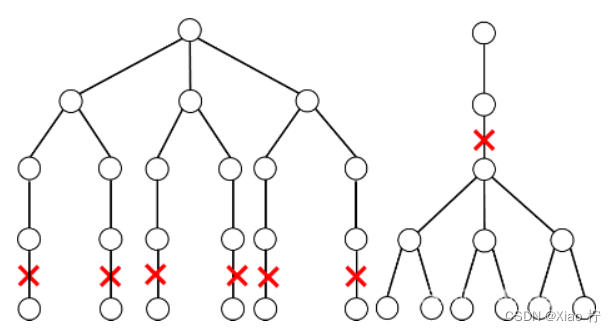
优化后搜索情况
无论是从那个点开始搜索,得到的可行解是不变的,因此从度数较大的点开始搜索可以提升运行效率
具体实现
初始化未染色的区域列表和每个区域的可选颜色列表。
计算每个未染色的区域的可选颜色数量,按照可选颜色数量从小到大排序(通过每个节点的度进行比较)。
选择可选颜色数量最小的未染色区域进行分支,尝试每个可选颜色,直到找到一种可行的颜色。
如果某个未染色区域的可选颜色数量为0,则回溯到上一个已染色的区域,并重新选择分支的颜色。
如果所有区域都已染色,则得到了问题的一个解。
节点选择-最多约束准则(DH)
算法描述
在节点选择方面,还有一个值得考虑的优化—最多约束准则DH
不难分析得出,度数较大的点的颜色是比较难填的,这是因为度数较大的点受其他点的约束比较大。如果相邻的节点的颜色很多是不相同的,那么该点剩余可以填涂的颜色将会很少,从而导致染色失败的可能性变大。

如上图所示,若我们先将4、5、7、8、9先图上颜色,那么低于六色的涂色方案对于节点6便没有颜色可以进行填色了,此时就代表此路不通,不得不停止回溯,从而造成时间的浪费,因此,若先将节点6进行填色,就可以很好的避免这个问题
DH算法的原理是在每次选择变量时,优先选择对其他未染色区域具有最多约束的节点进行搜索,即选择当前影响力最大(度数最大)的变量。这样做的目的是为了尽可能地减少回溯的次数,同时也可以最大程度地减少邻接节点的分支数量,从而提高算法的效率。
具体实现
初始化未染色的区域列表和每个区域的度数列表。
计算每个未染色的区域度数数量,按照度数数量从大到小排序。
选择度数数量最多的未染色区域进行染色,尝试每个可选颜色,直到找到一种可行的颜色。
如果某个未染色区域的可选颜色数量为0,则回溯到上一个已染色的区域,并重新选择分支的颜色。
如果所有区域都已染色,则得到了问题的一个解。
颜色选择-最少约束选择
算法描述
与节点选择DH相反的是,我在颜色的选择方面应用的是最少约束值原则
最小约束值准则的原理是尽量少选周围结点可用的颜色,从而避免对周围结点造成约束。具体而言,对于一个还没有涂色的点,为了让这个点涂的颜色对邻接点的影响尽可能的小,既尽可能不会影响邻接点剩余可填涂颜色,应该优先涂邻接点不能涂而该点可以涂的颜色。这样做的目的是为了给邻接点尽可能多的可选颜色数,从而提高染色成功的可能性。
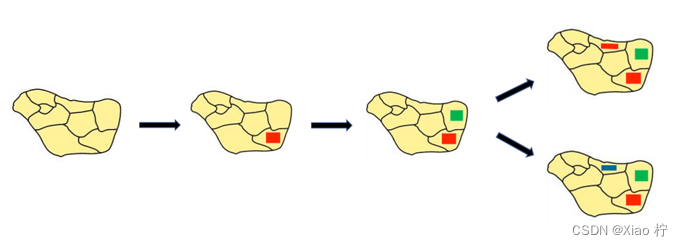
以上图为例,当对最上方的区域进行染色时,若我们选择一个新颜色蓝色,那么中间区域就只剩下一种颜色可以填涂,染色成功的可能性很低。若我们选择用过的红色,那么中间区域就有更多颜色可以选择,染色成功的可能性更高。
具体实现
对一个未涂色的点,先遍历邻接的点,对其邻接点不能涂的颜色进行计数。然后根据计数值从大到小对相应颜色进行排序,涂色点根据该顺序来选择涂什么颜色。
数据结构的选择
算法描述
对于存储图的数据结构,常见的由邻接表和邻接矩阵两种,存储方式的不同,数据存储与调取的方式也不同,因此如何选择合适的数据结构也将从一定程度上节省程序运行的时间,提高程序的性能。
对于邻接矩阵,其深度优先搜索的复杂度为O(n^2),且在寻找相邻区域时需要遍历所有区域,而对于邻接表而言,不仅可以直接获取到相邻区域,且其深度优先搜索的时间复杂度仅为O(n+e),e为图的边数,因此,使用邻接表存储边与边之间的关系,能够提升程序运行效率
具体实现

使用da存储邻接表,记录节点之间的关系
运行及测试
对问题1的小规模图进行测试,得到运行时间和可行方案数

以上数据证明,使用邻接表存储数据可以在正确性的保证下很好的优化程序的性能,减少程序运行的时间
向前探查
算法描述
可通过向前探查的方法,提前探知检查解的可行性,如果不存在可行解,直接进行剪枝并返回。
向前探查的原理是当某节点选择了一个颜色之后,则在邻接节点的可选颜色中,将该颜色删除。如果在删除的过程中发现删除后已经没有颜色可以填涂,那么就说明当前节点所选择的颜色不合法。这种方法可以提前知道某节点的选择是否正确,可以提前试错,从而提高算法的效率
具体实现
选择一个未染色区域进行染色。
对与该区域有约束关系的其他未染色区域的可选颜色列表中去掉该颜色。
如果某个未染色区域的可选颜色列表为空,则对于当前染色区域重新选择下一个颜色进行染色。
如果所有区域都已染色,则得到了问题的一个解。
颜色轮换(贪心置换)
算法描述
不同颜色下的各个涂色方案是对称的,一类答案和其他类答案是完全等效的。我们可以通过计算部分的答案,然后推测出对应的等效答案,从而减少搜索树的空间。
因此我一但固定下某一个点,便可映射出n-1(n为颜色个数)个可行解,因此在实际测试中,只需固定一个点,并将搜索出来的可行解个数乘以可用颜色数即可,这样一来,进行判断check的次数可以缩小至原来的1/n,同理实际运行时间也将大大降低。
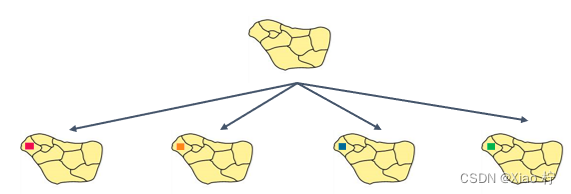
优化后只需进行一个分支的分析
同上,在固定一个点后,我们还可以接着对第二个节点进行划分,从而进一步提高算法的效率。
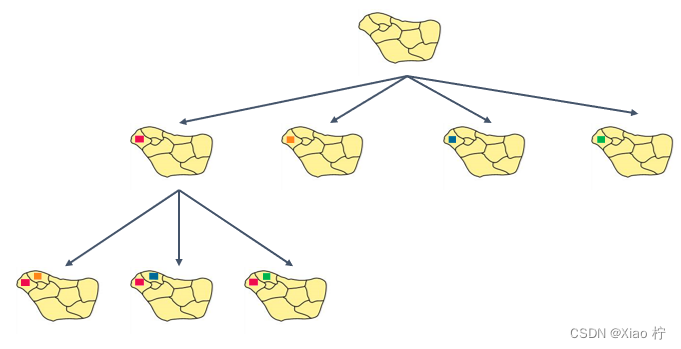
具体实现
根据自身的需求,可以选择固定一个点或多个点,并在回溯结束后对总方法数进行整数倍处理即可
五、代码描述
详细给出算法思想与实现代码之间的关系解释,不可直接粘贴代码(直接粘贴代码者视为该部分内容缺失)。
简单回溯算法实现
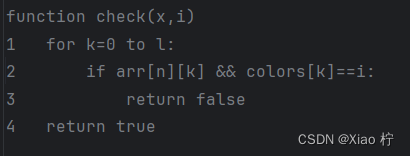
1)伪代码
回溯主方法伪代码

判断函数伪代码
2)运行测试
对实验中给定的地图进行涂色测试,未优化的回溯在0.108s内求得全部解共480个

涂色正确性检验
首先遍历整个点集,确保所有点均已染色。在此基础上,枚举每个点以及其邻接点,如果每个点与其邻接点均不同色,那么染色方案就合法。
通过检验,480 个结果全部正确。证明回溯算法具有正确性。
大规模数据测试
完成小规模数据的填涂后,尝试对其进行大数据涂色,但运行得知对于附件中的题图,并不能在短时间内运行结束,因此对其优化及其重要
| 地图 | le450_5a | le450_15b | le450_25a |
| 运行时间 | > 3h | > 3h | > 3h |
MRV&& DH算法实现
MRV伪代码实现
每次都在所有节点中寻找一个没有被访问且可选数量最小的区域进行分支,尽可能的让分支产生的位置远离根节点
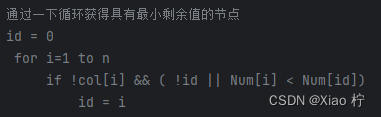
DH伪代码实现
统计每个节点的度数,并将每个节点按照度数进行排序后,选择度数数量最多的未染色区域进行涂色,尽可能减少分支

二者合并
对于MRV和DH,优先考虑MRV进行剪枝,其次在考虑DH进行选择
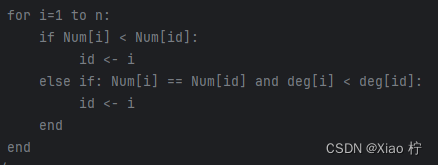
最少约束值准则(颜色)算法实现
遍历一个点邻接的点,对其不能涂的颜色计数,对计数数组进行排序,根据其从大到小进行涂色

向前探查算法实现
通过剪枝方案获得未染色区域后,更新与该节点相邻接的其他节点的可选颜色,接着判断是否还有颜色可选,可以则继续回溯,否则恢复可选列表,回到上一层遍历

颜色轮换算法实现
程序中只需固定第一点的颜色,并从第二点开始遍历搜索,在最终结果乘以颜色数量即可
优化:
对固定的那一点的邻接点进行分析判断,可以减少分支,提高搜索效率

六、实验结果和分析
每个实验内容的实验结果,以及对实验结果的比较分析和综合概括。
附录中三组数据的涂色
说明:为避免实验误差,每组测试均进行了十次,最终结果取平均值
得到一个可行解
全优化的情况下所需的时间
| 地图 | le450_5a | le450_15b | le450_25a |
| 运行时间 | 18ms | 312ms | <1ms |
可见,在进行多次优化后,求个大规模数据中的一个解答案还是比较迅速的
不同的剪枝方案下附录地图所需的时间以及回溯调用的次数分析
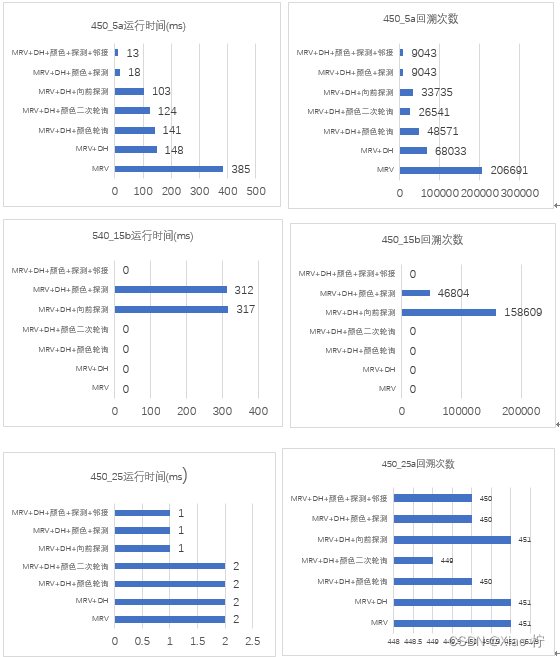
从上述的六张数据图我们可以发现,在经历了各种剪枝方案的叠加优化后,总体花费的时间逐渐减少,并且回溯的次数也在不断下降,证明了剪枝方案的正确性。
450-15这幅图的数据比较的特殊,只有在“MRV+DH+向前探查”和“MRV+DH+颜色轮询+向前探查”这两个剪枝组合下才能在可接受的时间内找到可行解,主要与向前探查优化有关,说明在某些情况下,特定的优化方法是必不可少的。
对于450-5这幅图,各个剪枝策略在上面都表现的比较好,在加上一些剪枝策略后运行时间及回溯次数都有所降低,比较有代表性。
得到全部可行解
全优化情况下附录地图得到全部可行解
| 地图 | le450_5a | le450_15b | le450_25a |
| 运行时间 | 2671ms | >3h | >3h |
| 解的个数 | 3840 | >109 | >109 |
经过优化后的回溯算法可以轻松求出450点图的五色填色问题,但当面对于更大规模的图数据时,由于可选颜色过多以及其他条件,解的个数过大,依旧不能再可接受范围内求解出来
不同剪枝优化情况下得到le450_5a地图全部解的时间
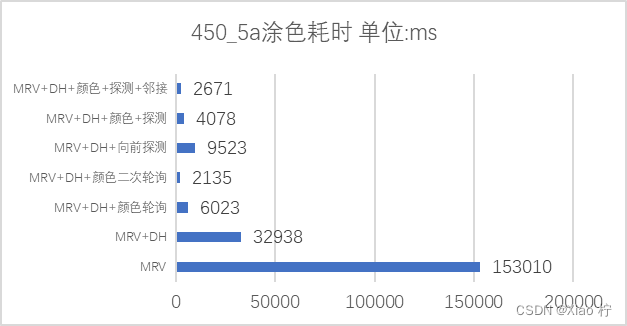
从上图中我们可以看出,可以看到经过各种剪枝策略之后,找到全部解所用的时间大体上逐渐减少。可见颜色轮询对于提升算法性能有一个比较好的促进作用,在于其可以让程序总体复杂度降低一个数量级。
总的来说,在使用MRV、DH、向前探测 、颜色选择、使用邻接表这5 种优化后,程序从一开始的长时间无法得出一个可行解优化到了现在能在短时间内找出大量可行解,算法的效率得到极大提升。
3) 结果正确性测试
读取文件,忽略前33行文本解释后,在第34行记录节点和边的个数,随后开始输入边的信息

在判断是否完成涂色的代码区域打开一个文件,将所得到的涂色方案写入进去,实现伪代码如下

随即便会生成对应的.out文件

进入check程序输入对应的图名称,便会自动进行判断,若直接显示使用的颜色数量,说明结果是正确的。
Le450_5a.col

Le450_15b.col

Le450_25a.col
自行生成地图涂色以及分析
通过随机数,自行生成了不同规格的地图,对于每个地图,均将程序运行 10 次并取平均值作为实际值。对于每次比较时,均需要保证其余变量的值不变,在有解的情况下,分析统计作表如下:
点的规模对运行时间的影响
我们固定使用的颜色数为4个,并且边密度固定为0.05,分别改变点的个数为450、600、750、900。
不同点的规模下的运行时间
| 点的规模n | 450个点 | 600个点 | 750个点 | 900个点 |
| 运行时间(s) | 4.51 | 7.95 | 11.72 | 17.34 |
不同点的规模下的运行时间及其对数
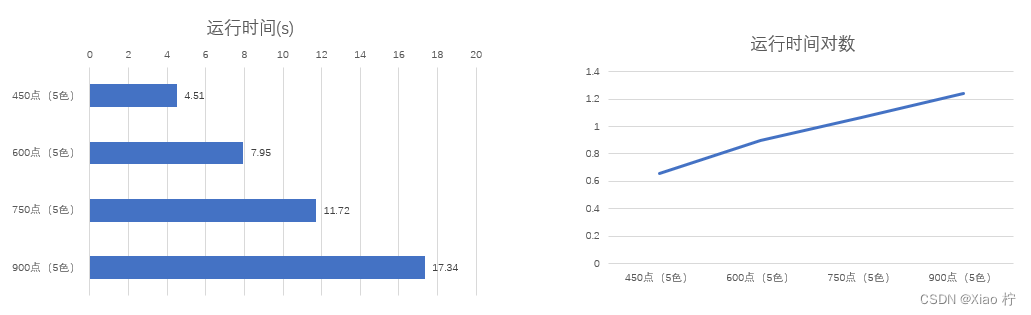
当地图中的节点规模较小时,搜索树的规模也相对较小,因此小规模的图的搜索时间要比大规模的图少得多。以图14为例,当地图规模以线性级增长时,时间消耗大致呈指数型增长。此外,随着节点规模的增加,指数增长速率放缓,这是由于多种剪枝策略在处理大规模数据时能够更有效地优化搜索过程。
边密度对运行时间的影响
我们固定点的规模为200个,并且颜色数量固定为5,分别改变边密度为0.05、0.06、0.07、0.08。
不同边密度下的运行时间
| 边密度 | 0.05 | 0.06 | 0.07 | 0.08 |
| 运行时间(ms) | 5310 | 1630 | 350 | 12 |
不同边密度下的运行时间及其对数
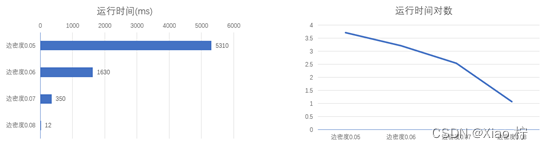
由上图可知,随着边密度的增大,运行时间呈指数级下降。这是因为边密度越大,剪枝效率越高。除此之外,边密度的增加对点的染色造成了更多的约束,使得找到可行解更加困难,所以程序在早期就进行了回溯,没有进入更深层次的搜索,找到的可行解数量也大大减少,故运行时间越来越短
七、实验结论
从算法解决问题的角度写从该实验得到的客观结论。
在本次实验中,我使用了回溯法对地图填色问题进行了求解,首先是朴素即未进行优化的回溯法,发现在面对小规模的数据下,能在较快的时间内得到准确的结果,但在大规模数据下无法再可接受的时间内得出结果。为了提高算法效率,使得回溯法能有一个大范围的使用,我提出了五种算法优化和一种结构优化,分别是(1)MRV (2)DH (3)最少约束值(4)向前探查 (5)颜色轮询以及采用邻接表结构进行存储,并在不同范围的地图数据中进行实验探究,分析其效率,最后得出结论,朴素回溯在经历了剪枝优化后,可在短时间内得到大量的可行解,算法效率得到大大的提升
思考:明明四色原则上可解决所有地图涂色问题,但对附件地图数据涂色,为什么填涂颜色超过了四色?
关于这个问题,我们首先看一看图17。这是一个5阶完全图,如果只用4种颜色的话就会出现下述情况,最后一个点无论填涂什么颜色都会与邻接点冲突。所以对于5阶完全图,只用4种颜色填色是不可行的,至少也要5种不同的颜色。
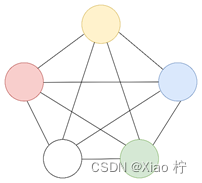
如图18所示,我们反观附录数据中的信息,450-5这幅图中含有175个5阶完全子图,450-15这幅图中含有40个15阶完全子图,450-25这幅图中含有13个25阶完全子图,所以它们分别至少需要5种、15种、25种颜色才能找到合法的染色方案,故填涂颜色超过了四色。与此同时,由于大量的完全子图的存在,使用回溯法进行地图染色非常的困难,所以我们需要设计不同的剪枝方案来提高算法的效率。



但是这并不能说明四色定理是错的,这是因为四色定理是应用于平面地图中,而平面地图中不含有4阶以上的完全图(Kuratowski定理——5阶完全图是最小的非平面图),附录中给出的地图不是平面地图,所以填涂的颜色超过了四色。
这篇关于算法设计与分析 实验3 回溯法求地图填色问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






