本文主要是介绍“AUTOSAR Nvm_WriteAll()掉电无法正常更新Nvm数据” 问题分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、问题现象
- 再掉电时调用Nvm_WriteAll()函数后,再重新上电,发现下电前更新得NvmBlock数据未被正确更新到Nvm中。
- 掉电时直接调用Nvm_WriteBlock()函数,可以正常更新指定得NvmBlock块。
2、排查
- NvM_InterWriteAll()函数有被正常执行。
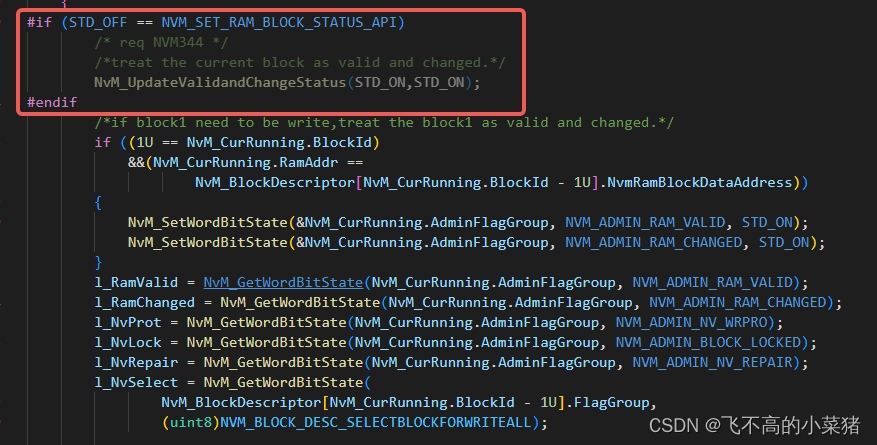
- NvM_InterWriteAll()函数中调用得NvM_UpdateValidandChangeStatus(STD_ON,STD_ON)函数被屏蔽了,无法正常执行。
- NvM_UpdateValidandChangeStatus(STD_ON,STD_ON)作用:Update Validand Change Status。
- 当该函数不执行时,会直接跳过所有得NvmBlock块,更新标志直接被设置成OFF。
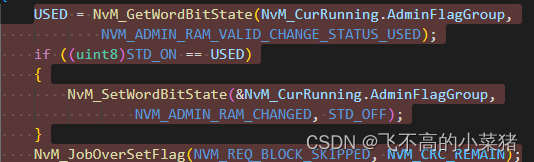
3、NvM_UpdateValidandChangeStatus(STD_ON,STD_ON)作用
- 该函数在写NvmBlock时用于更新对应得RAM状态,用于NVM识别是否需要更新NvmBlock。
- 该函数通过宏NVM_SET_RAM_BLOCK_STATUS_API 决定是否使用。
- NVM_SET_RAM_BLOCK_STATUS_API = FALSE:该函数可以被正常调用。
- 影响:NvMSetRamBlockStatusApi = FALSE,则 NvM_WriteAll() 会将所有 NVRAM Block对应的RAM内容拷贝到 NV Block中。
- NVM_SET_RAM_BLOCK_STATUS_API = TRUE :该函数被屏蔽。
- 影响:
- NVM_SET_RAM_BLOCK_STATUS_API = TRUE,只有 RAM Block的内容发生变化的RAM内容被写到 NV Memory中。
- 此时需要注意:
- 每当Nvm Block对应的 RAM内容发生变化时,用户必须调用 NvM_SetRamBlockStatus(BlockID, TRUE),告诉 NvM 模块在 NvM_WriteAll()时要处理该 Nvm Block。
- 如果在Nvm Block对应的 RAM内容发生变化时,用户不调用 NvM_SetRamBlockStatus(BlockID, TRUE,那么在调用Nvm_WriteAll()时,该对应的Nvm Block将不会被更新。
- 好处: 可以加快NvM_WriteAll()的速度。
- 影响:
- NVM_SET_RAM_BLOCK_STATUS_API = FALSE:该函数可以被正常调用。
4、提升NvM_WriteAll()速度的办法
- NVM_SET_RAM_BLOCK_STATUS_API 配置为 TRUE,通过调用NvM_SetRamBlockStatus(NvMBlock_ID, TRUE)通知Nvm更新数据时,只更新数据发生改变的NvmBlock。
- NvMBlockUseCRCCompMechanism配置为TRUE,通过比较上次写入数据的CRC与想要更新的数据的CRC进行对比,当CRC不变时,直接跳出写操作。
- 该操作有一个弊端:当RAM数据发生变化,但是CRC不变的情况下,那么对应的RAM数据将不会被更新。
这篇关于“AUTOSAR Nvm_WriteAll()掉电无法正常更新Nvm数据” 问题分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








