本文主要是介绍数据库原理(关系数据库规范化理论)——(4),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、关系模式规范化的必要性
1.关系可能出现的问题
- 数据冗余大;
- 插入异常;
- 删除异常;
- 更新异常;
2.关系模式应满足的基本要求
- 元组的每个分量必须是不可分割的数据项;
- 数据库中的数据冗余应尽可能少;
- 不要出现插入异常;
- 不要出现删除异常;
- 不要出现更新异常;
- 数据库设计应考虑查询要求,数据组织要合理。
二、函数依赖及关系的范式
1.函数依赖类型
(1)完全函数依赖:

(2)部分函数依赖:
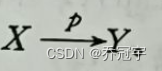
(3)传递函数依赖:

2.关系的范式及其规范化
范式指数据依赖满足一定约束的关系模式。
范式的判定条件与规范化
(1)1NF
在一个关系模式R中,如果R的每一个属性都是不可再分的数据项,则称R属于1NF。
(2)2NF
在一个关系模式R中,如果R属于1NF,且它的每一个非主属性都完全依赖于候选码,则R属于第二范式,简单来说就是要有用于识别的id或索引。
(3)3NF
如果一个关系模式R属于2NF,并且每个非主属性都不传递函数依赖于候选码,则R属于第三范式,简单的说就是一张表中存储一类信息时,在一张表中关联其他表中数据时,只需要关联主键即可。
(4)BCNF
如果关系模式R(U,F)属于1NF,若F中任一函数依赖且
时,X必含有R的一个候选码,则R属于BCNF,简单地说就是要判断存储信息是否存在和合理,注意,满足BCNF的必然满足3NF。
三、函数依赖的公理系统
函数依赖的公理系统是指用来推导和证明函数依赖的一组基本原则和规则。以下是常见的函数依赖的公理系统:
-
自反性:如果X是关系R的子集,则X -> X。
-
扩展性:如果X -> Y,那么对于任何关系的扩展R',都有X -> Y。
-
传递性:如果X -> Y且Y -> Z,那么X -> Z。
-
合并性:如果X -> Y且X -> Z,那么X -> YZ。
-
分解性:如果X -> YZ,那么X -> Y且X -> Z。
-
析取性:如果X -> Y且X -> Z,那么X -> YZ。
-
交换性:如果X -> YZ,那么X -> ZY。
这些公理可以用来推导和证明函数依赖的性质和关系。通过应用这些公理,可以建立函数依赖的理论框架,并使用它来分析和优化数据库设计和查询优化。
四、关系模式的分解
这里会和函数依赖的公理系统结合来出大题(很难我不会),感兴趣或时间充足可以自行在b站上搜索相关视频学习,这里不进行复习。
这篇关于数据库原理(关系数据库规范化理论)——(4)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








