本文主要是介绍Golang内存模型与分配机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简述
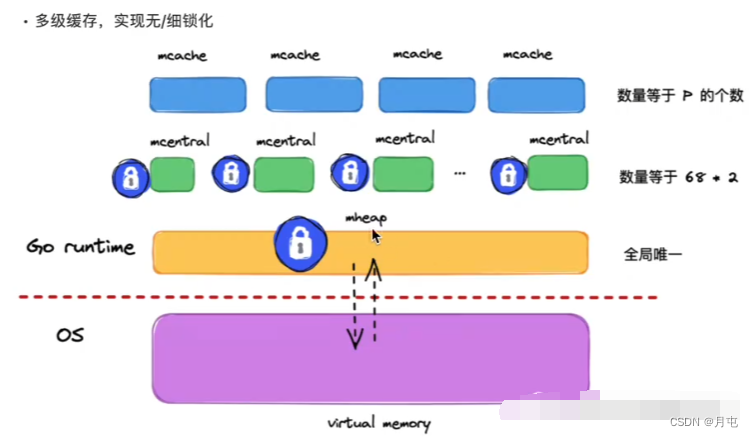
mheap为堆,堆和进程是一对一的;mcentral(小mheadp),mcahe(GMP的P私有),分配内存顺序由后向前。
在解决这个问题,Golang 在堆 mheap 之上,依次细化粒度,建立了mcentral、mcache 的模型,下面对三者作个梳理:
- mheap:全局的内存起源,访问要加全局锁
- mcentral:每种对象大小规格(全局共划分为68种)对应的缓存,锁的粒度也仅限于同一种规格以内
- mcache:每个P(正是GMP中的P)持有一份的内存缓存,访问时无锁
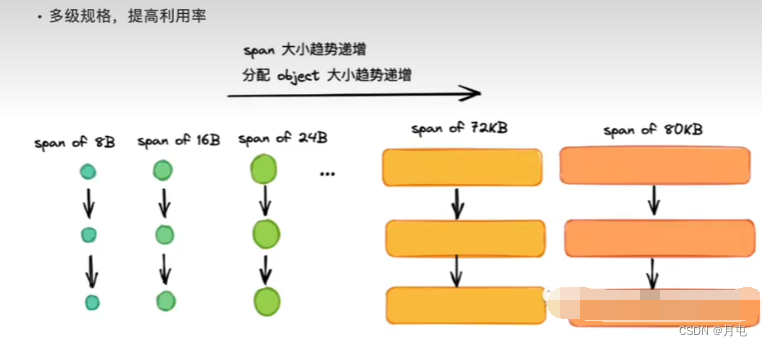
首先理下page和mspan两个概念∶
(1) page:最小的存储单元.
Golang 借鉴操作系统分页管理的思想,每个最小的存储单元也称之为页page,但大小为8 KB
(2) mspan:最小的管理单元.
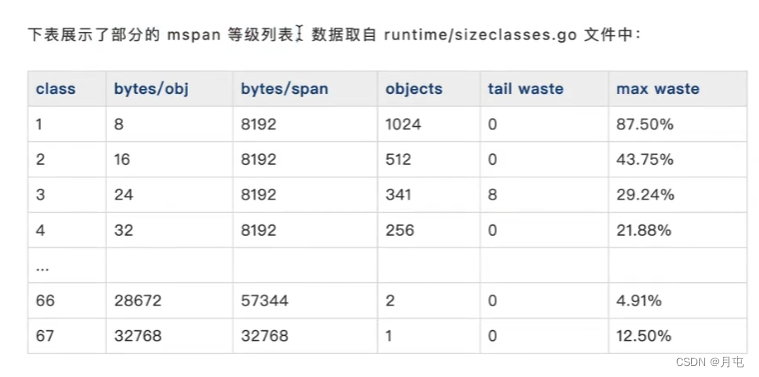
mspan 大小为 page 的整数倍,且8B到80 KB被划分为67种不同的规格,分配对象时,会根据大小映射到不同规格的mspan,从中获取空间.
于是,我们回头小节多规格mspan下产生的特点︰ - 根据规格大小,产生了等级的制度
- 消除了外部碎片,但不可避免会有内部碎片
- 宏观上能提高整体空间利用率
- 正是因为有了规格等级的概念,才支持mcentral实现细锁化
核心概念梳理
内存单元mspan
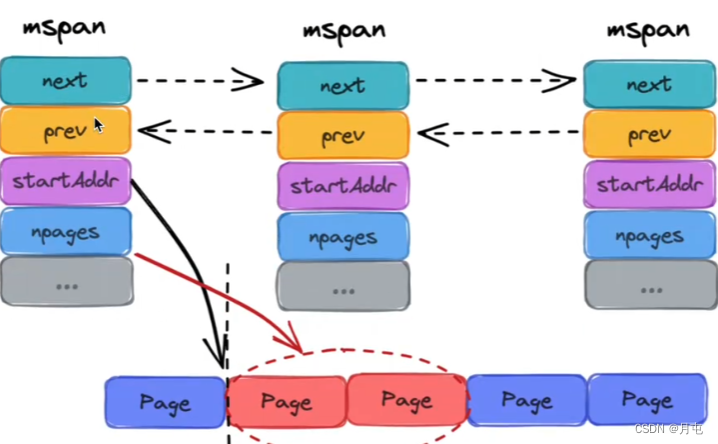
分点阐述mspan的特质:
- mspan是Golang内存管理的最小单元
- mspan大小是page的整数倍(Go 中的page 大小为8KB),且内部的页是连续的(至少在虚拟内存的视角中是这样)
- 每个mspan根据空间大小以及面向分配对象的大小,会被划分为不同的等级
- 同等级的mspan 会从属同一个mcentral,最终会被组织成链表,因此带有前后指针((prev、next)·- 由于同等级的mspan内聚于同一个mcentral,所以会基于同一把互斥锁管理
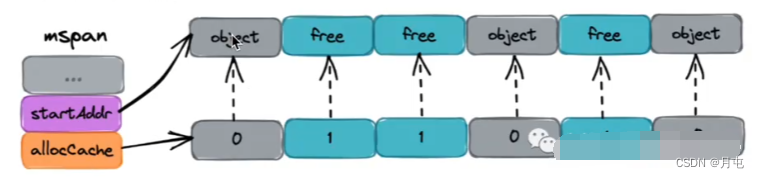
- mspan 会基于bitMap辅助快速找到空闲内存块(块大小为对应等级下的object大小),此时需要使用到Ctz64算法.

内存单元等级spanClass
mspan根据空间大小和面向分配对象的大小,被划分为67种等级(1-67,实际上还有一种隐藏的0级,用于处理更大的对象,上不封顶)

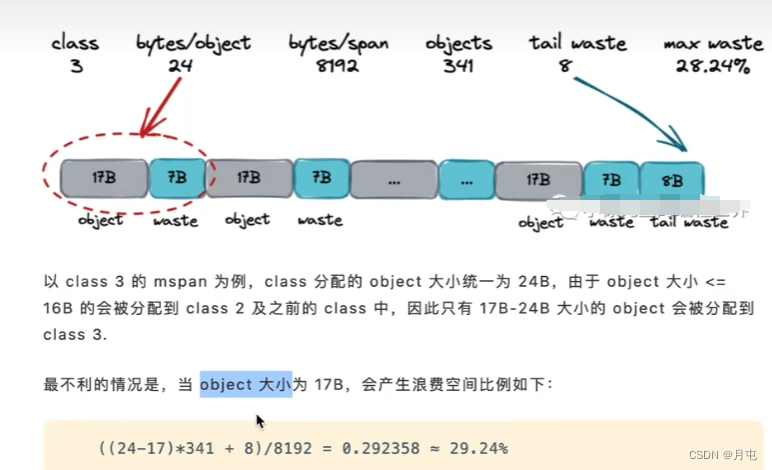
除了上面谈及的根据大小确定的mspan等级外,每个object还有一个重要的属性叫做nocan,标识了object是否包含指针,在gc时是否需要展开标记.
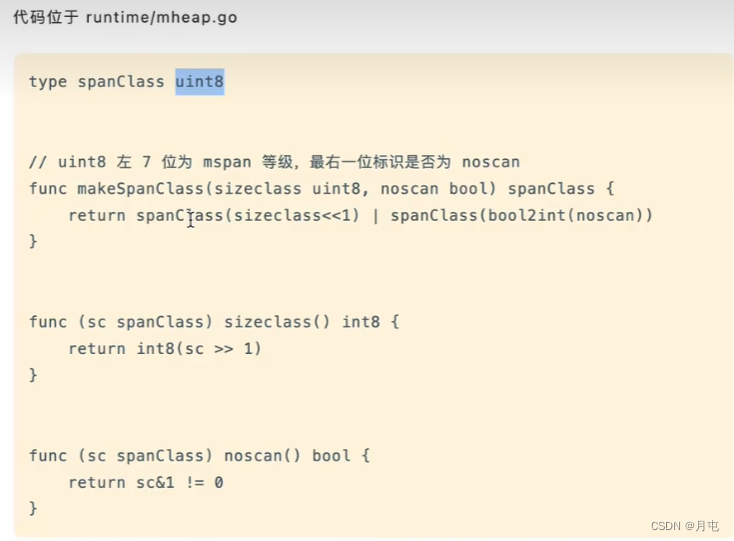
在Golang 中,会将span class + nocan两部分信息组装成一个uint8,形成完整的
spanClass 标识.8个 bit中,高7位表示了上表的span等级((总共67+1个等级,8个bit足够用了),最低位表示nocan信息.
线程缓存mcache
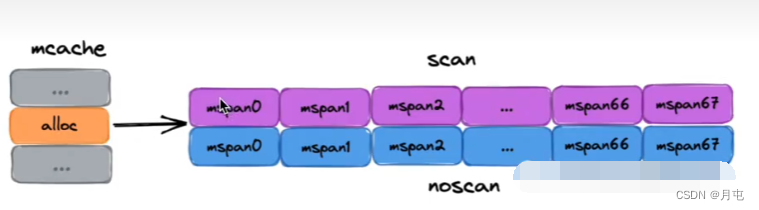
(1) mcache是每个Р独有的缓存,因此交互无锁
(2) mcache 将每种spanClass 等级的mspan各缓存了一个,总数为2 (nocan维度)*68(大小维度)=136
(3) mcache 中还有一个为对象分配器tiny allocator,用于处理小于16B对象的内存分配

中心缓存mcentral
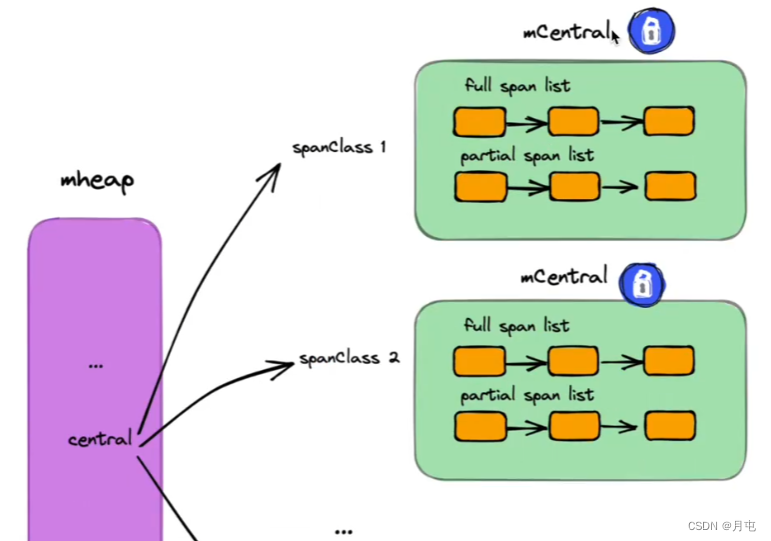
要点∶
(1)每个mcentral对应一种spanClass
(2)每个mcentral 下聚合了该spanClass 下的mspan
(3) mcentral 下的mspan分为两个链表,分别为有空间mspan链表partial和满空间mspan链表full
(4)每个mcentral一把锁

全局堆缓存mheap
要点︰
- 对于Golang上层应用而言,堆是操作系统虚拟内存的抽象·
- 以页(8KB)为单位,作为最小内存存储单元
- 负责将连续页组装成mspan
- 全局内存基于bitMap标识其使用情况,每个bit对应一页,为0则自由,为1则已被mspan组装·
- 通过heapArena 聚合页,记录了页到mspan的映射信息
- 建立空闲页基数树索引 radix tree index,辅助快速寻找空闲页
- 是mcentral 的持有者,持有所有spanClass 下的mcentral,作为自身的缓存
- 内存不够时,向操作系统申请,申请单位为heapArena (64M)

空闲也索引pageAlloc
数据结构背后的含义:
- mheap 会基于bitMap标识内存中各页的使用情况,bit位为0代表该页是空闲的,为1代表该页已被mspan占用.
-
- 每棵基数树聚合了16 GB内存空间中各页使用情况的索引信息,用于帮助 mheap快速找到指定长度的连续空闲页的所在位置
- mheap持有214 棵基数树,因此索引全面覆盖到 214*16 GB = 256 T的内存空间.
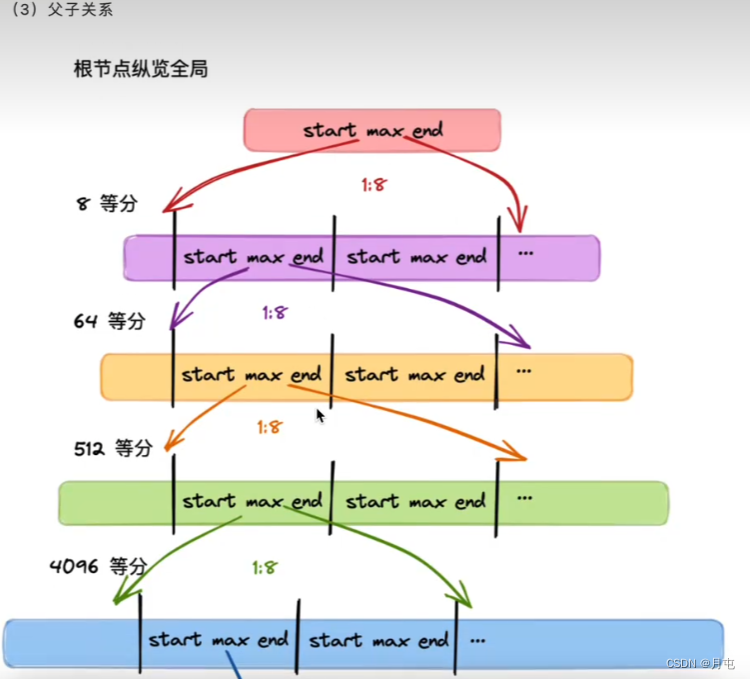
- 每个父 pallocSum有8个子pallocSum
- 根pallocSum总览全局,映射的 bitMap范围为全局的16 GB空间(其max最大值为221,因此总空间大小为221*8KB=16GB) ;
- 从首层向下是一个依次八等分的过程,每一个pallocSum映射其父节点bitMap范围的八分之一,因此第二层pallocSum的 bitMap 范围为16GB/8 = 2GB,以此类推,第五层节点的范围为16GB /(84) = 4 MB,已经很小
- 聚合信息时,自底向上.每个父pallocSum聚合8个子pallocSum的start、max、end信息,形成自己的信息,直到根pallocSum,坐拥全局16 GB的start、max、end 信息
- mheap寻页时,自顶向下.对于遍历到的每个pallocSum,先看起start 是否符合,是则寻页成功;再看max是否符合,是则进入其下层孩子pallocSum中进一步寻访;最后看end和下一个同辈pallocSum 的start聚合后是否满足,是则寻页成功.
每层节点
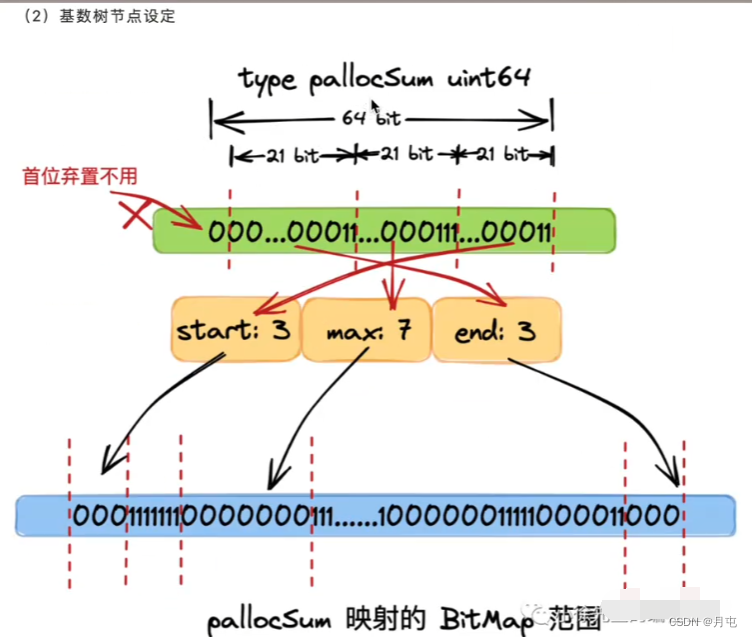
基数树中,每个节点称之为PallocSum,是一个uint64类型,体现了索引的聚合信息,包含以下四部分:
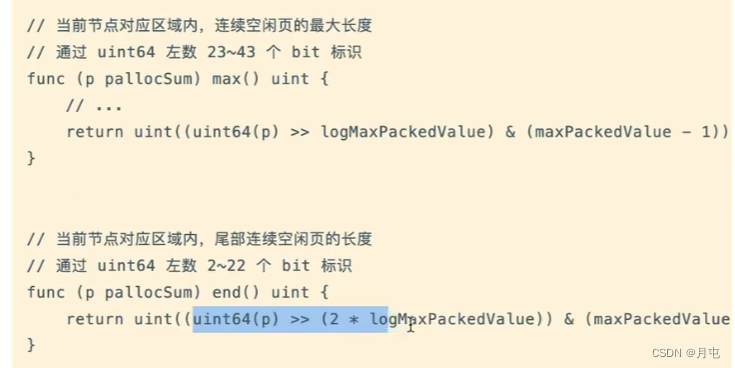
- start:最右侧21个bit,标识了当前节点映射的 bitMap 范围中首端有多少个连续的0 bit(空闲页),称之为start;
- max:中间21个bit,标识了当前节点映射的 bitMap范围中最多有多少个连续的0 bit(空闲页),称之为max;
- end:左侧21个 bit,标识了当前节点映射的 bitMap范围中最末端有多少个连续的0 bit(空闲页),称之为end.
- 最左侧一个bit,弃置不用

基数树节点

heapArena
- 每个heapArena包含8192个页,大小为8192* 8KB = 64 MB
- **heapArena记录了页到msplan的映射.**因为GC时,通过地址偏移找到页很方便,但找到其所属的mspan不容易.因此需要通过这个映射信息进行辅助.
- heapArena是mheap向操作系统申请内存的单位(64MB)

对象分配流程
下面来串联 Golang中分配对象的流程,不论是以下哪种方式,最终都会殊途同归步入mallocgc方法中,并且根据3.1小节中的策略执行分配流程:
- new(T)
- &T{}
- make(xxxx)
分配流程总览
Golang中,依据 object的大小,会将其分为下述三类∶
- tiny微对象(0-16B)
- small小对象(16B-32KB)
- large大对象(32KB—)
不同类型的对象,会有着不同的分配策略,这些内容在mallocgc方法中都有体现.
核心流程类似于读多级缓存的过程,由上而下,每一步只要成功则直接返回.若失败,则由下层方法兜底.
对于微对象的分配流程︰
(1)从P专属mcache 的tiny 分配器取内存(无锁)
(2)根据所属的spanClass,从Р专属mcache 缓存的mspan中取内存(无锁)
(3)根据所属的spanClass 从对应的mcentral中取 mspan填充到mcache,然后从mspan中取内存(spanclass粒度锁)
(4)根据所属的spanClass,从 mheap 的页分配器 pageAlloc取得足够数量空闲页组装成mspan填充到mcache,然后从mspan中取内存(全局锁)
(5) mheap向操作系统申请内存,更新页分配器的索引信息,然后重复(4) .
对于小对象的分配流程是跳过〔1)步,执行上述流程的(2) - (5)步;
对于大对象的分配流程是跳过(1)-(3)步,执行上述流程的(4) - (5)步.
主干方法,mallocgc
微对象分配


小对象分配

大对象分配

tiny分配
每个Р独有的mache 会有个微对象分配器,基于 offset线性移动的方式对微对象进行分配,每16B成块,对象依据其大小,会向上取整为2的整数次幂进行空间补齐,然后进入分配流程.
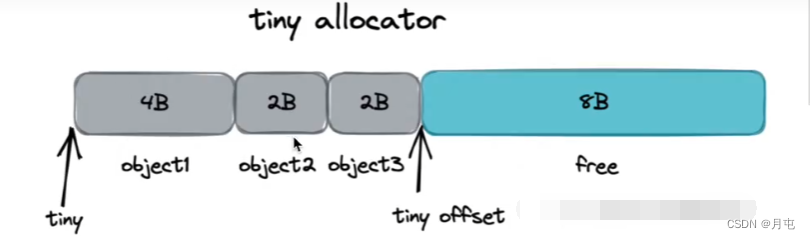

mcache分配

在mspan中,基于Ctz64算法,根据 mspan.allocCache 的 bitMap信息快速检索到空闲的object块,进行返回.

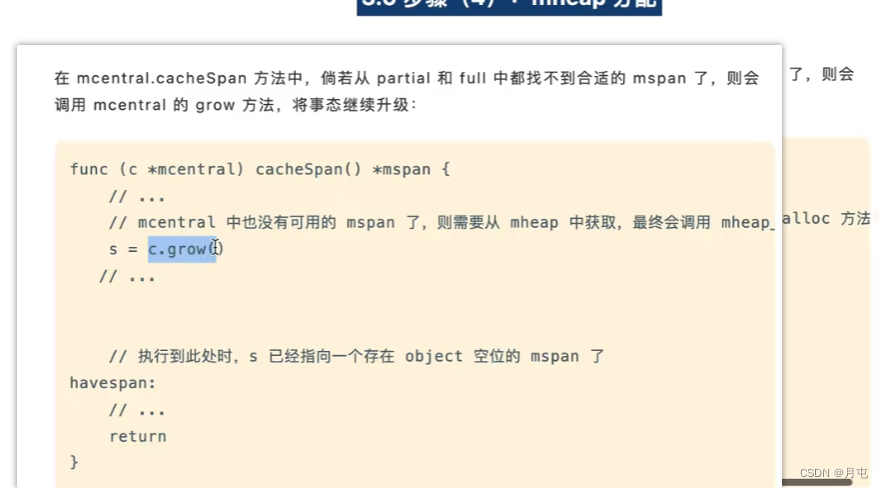
mcentral分配
当mspan无可用的object内存块时,会步入mcache.nextFree方法进行兜底.


mcentral.cacheSpan方法中,会加锁(spanClass 级别的sweepLocker),分别从 partial和full中尝试获取有空间的mspan:

mheap分配


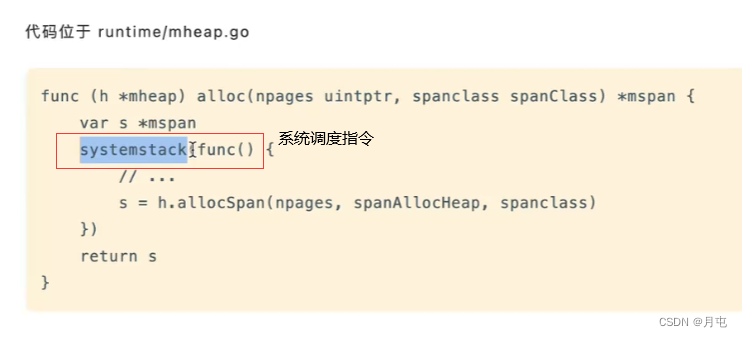

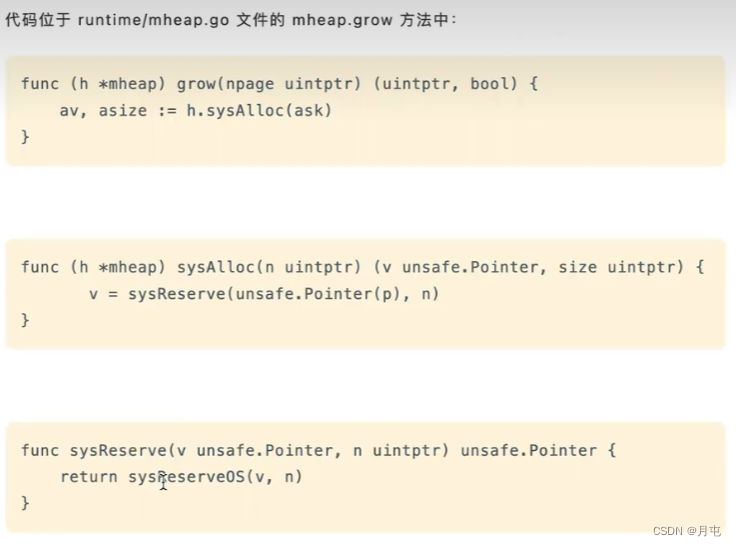
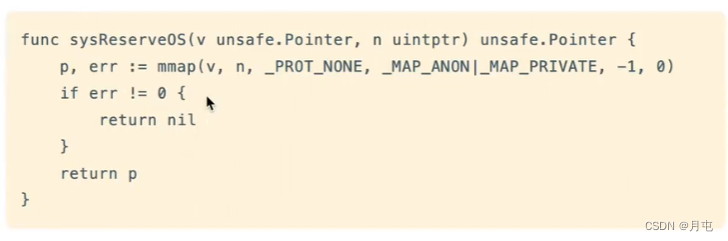
操作系统申请
倘若mheap中没有足够多的空闲页了,会发起mmap系统调用,向操作系统申请额外的内存空间.
基数树寻页




这篇关于Golang内存模型与分配机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







