本文主要是介绍真阳率(true positive rate)、假阳率(false positive rate),AUC,ROC,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
很早以前就知道这些概念了,不过由于跟自己的认知习惯不一样,所以碰到了还是经常会忘。于是索性把这些概念总结一下,以后再忘了也好找(其他的文章太啰嗦了,计算方法也写的不清不楚….)
另外我也会陆续更新一些其他的机器学习相关概念和指标,即是方便自己,也方便他人吧。
注意:本文将混用正负样本和阳性(+)阴性(-)这两套说法
真阳率、假阳率
这些概念其实是从医学那边引入到机器学习里面的,所以其思维逻辑多多少少会跟做机器学习的有点出入。我们去看病,化验单或报告单会出现(+)跟(-),其分别表型阳性和阴性。比如你去检查是不是得了某种病,阳性(+)就说明得了,阴性(-)就说明没事。
那么,这种检验到底靠不靠谱呢?科研人员在设计这种检验方法的时候希望知道,如果这个人确实得了病,那么这个方法能检查出来的概率是多少呢(真阳率)?如果这个人没有得病,那么这个方法误诊其有病的概率是多少呢(假阳率)?
具体来说,看下面这张表(摘自百度百科):
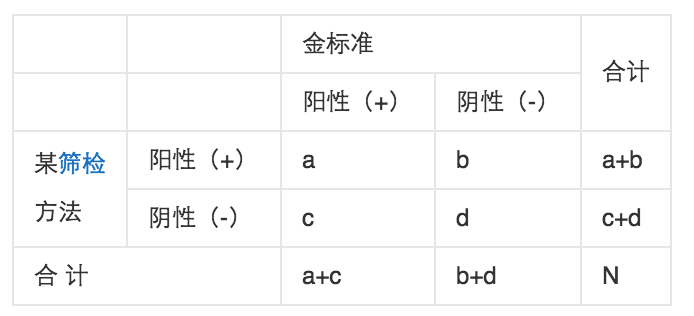
真阳率(True Positive Rate, TPR)就是:
含义是检测出来的真阳性样本数除以所有真实阳性样本数。
假阳率(False Positive Rate, FPR)就是:
含义是检测出来的假阳性样本数除以所有真实阴性样本数。
ROC(Receiver Operating Characteristic)
很简单,就是把假阳率当x轴,真阳率当y轴画一个二维平面直角坐标系。然后不断调整检测方法(或机器学习中的分类器)的阈值,即最终得分高于某个值就是阳性,反之就是阴性,得到不同的真阳率和假阳率数值,然后描点。就可以得到一条ROC曲线。
需要注意的是,ROC曲线必定起于(0,0),止于(1,1)。因为,当全都判断为阴性(-)时,就是(0,0);全部判断为阳性(+)时就是(1,1)。这两点间斜率为1的线段表示随机分类器(对真实的正负样本没有区分能力)。所以一般分类器需要在这条线上方。
画出来大概是长下面这样(转自这里):
AUC(Area Under Curve)
顾名思义,就是这条ROC曲线下方的面积了。越接近1表示分类器越好。
但是,直接计算AUC很麻烦,但由于其跟Wilcoxon-Mann-Witney Test等价,所以可以用这个测试的方法来计算AUC。Wilcoxon-Mann-Witney Test指的是,任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score(score指分类器的打分)。
方案一:
我们可以对于总样本中的M个正样本和N个负样本,组成M×NM×N个pair,如果某个pair正样本score大于负样本,则记1分,反之记0分,相等记0.5分。然后总分除以M×NM×N就是AUC的值了。复杂度O(M×N)O(M×N)
方案二:
基本思想一样,不过复杂度可以缩减到O((M+N)log(M+N))O((M+N)log(M+N))。
首先,我们将所有样本得分从大到小排序,则排名最高的样本rank为M+N,第二的为M+N-1,以此类推。然后我们将所有正样本的rank加和,其思想为:排名k的正样本至多比k-1个负样本的score要大。当我们将正样本的rank加和后,再减去(1+M)M/2(1+M)M/2,即正样本的个数,就是正样本score比负样本score大的pair个数。再除以O(M×N)O(M×N)就是AUC的值了,公式如下:
注意:对score相等的样本,需要赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是把所有这些score相等的样本的rank取平均。然后再使用上述公式。比如score为0.8的有两个样本,rank为7和8,则其最终代入公式的rank为7.5
这篇关于真阳率(true positive rate)、假阳率(false positive rate),AUC,ROC的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




![解决树莓派IOError: [Errno Invalid sample rate] -9997 采样率16K错误](/front/images/it_default.gif)

