本文主要是介绍【AI+编程】工作日常场景随时可以AI编程,记一个问答SQL快速导出数据日常示例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天有个场景,我们有个老项目,由于历史原因差不多1年多没使用了,恰巧客户紧急情况要使用。因为当时没有需求,所以V1.0上线后 就没做更新。
需求很简单:我们假定 项目问题表、客户表、问题答案表, 实时查询 客户 问题答案结果导出excel给客户。 由于时间紧张,客户10分钟后就要用。如果用JAVA代码,其实就是poi的一个导出,时间来不及,这里临时用sql处理解决。
下面是假定表结构,实际场景和它类似。 直接问chatGPT
CREATE TABLE `db_question` (`id` bigint NOT NULL AUTO_INCREMENT,`question_name` varchar(50) DEFAULT NULL COMMENT '问题名称',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;CREATE TABLE `db_member` (`id` bigint NOT NULL AUTO_INCREMENT,`name` varchar(50) DEFAULT NULL COMMENT '姓名',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;CREATE TABLE `db_answer` (`id` bigint NOT NULL AUTO_INCREMENT,`question_id` bigint DEFAULT NULL,`answer` varchar(50) DEFAULT NULL COMMENT '答案',`member_id` bigint DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4;
mysql中 我想导出 客户、问题答案 ,其中问题作为 表头,
答案作为内容。请提供SQL
答案:
为了实现你需要的操作,即以问题名称作为表头,答案作为内容导出,你可以通过JOIN操作连接三个表,然后利用动态SQL语句进行行转列转换(PIVOT)。MySQL 并不直接支持 PIVOT 操作,这种转换通常需要使用 CASE 语句或动态SQL来处理。下面是一种使用动态SQL来实现的方法:
首先,我们将通过动态SQL构建一个查询,该查询会根据问题名称动态生成列头。
然后,在动态生成的SQL语句中利用JOIN把db_member、db_question和db_answer连接起来,并根据question_id和member_id进行匹配,以输出每个成员对应的问题答案。
请注意,因为MySQL不直接支持PIVOT操作,所以我们需要自己构造这个过程。下面是具体实现的步骤:
SET @sql = NULL;
SELECTGROUP_CONCAT(DISTINCTCONCAT('MAX(CASE WHEN q.question_name = ''',q.question_name,''' THEN a.answer END) AS `',q.question_name, '`')) INTO @sql
FROM db_question AS q;SET @sql = CONCAT('SELECT m.name, ', @sql, ' FROM db_member AS mLEFT JOIN db_answer AS a ON m.id = a.member_idLEFT JOIN db_question AS q ON a.question_id = q.idGROUP BY m.name');PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
这段SQL代码首先会构造一个动态的SELECT语句,其中包含了所有问题作为列头。然后通过执行这个动态生成的SQL,你可以得到一个表格,表中的每一行表示一个成员,对应每个问题的答案作为列数据。请注意替换代码中的question_name、answer、并确保它们的列名正确无误。
此代码片段先构造一个SELECT语句,该语句动态地将问题名作为列头,并聚合每个成员的答案到对应的列。需要注意,为了确保代码的正确执行,数据库用户需要有执行动态SQL的权限。
执行结果:
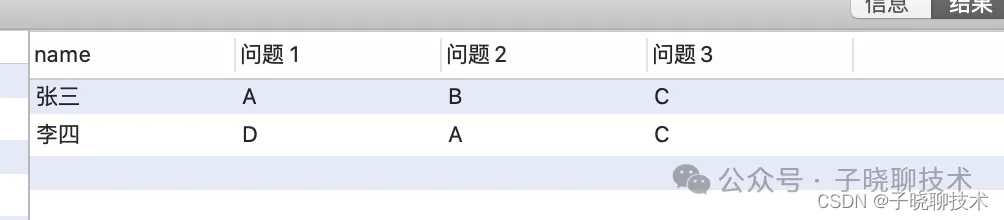
虽然我以前就知道mysql用group_concat用法,但自己手动拼写还是比较费时间的。直接问chatGPT, 不到2分钟这个问题就解决了。
不要把日常工作和AI分开,把AI当成工作生活的一部分。
原文链接:【AI+编程】工作日常场景随时可以AI编程,记一个问答SQL快速导出数据日常示例
这篇关于【AI+编程】工作日常场景随时可以AI编程,记一个问答SQL快速导出数据日常示例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







