本文主要是介绍关于yolov5训练的那些事儿,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.YOLOv5 的模型系列包括从最小到最大的多种模型:YOLOv5n(Nano),YOLOv5s(Small),YOLOv5m(Medium),YOLOv5l(Large),以及 YOLOv5x(Extra Large)。这些模型的区别主要在于网络的深度和宽度,即层数和每层的通道数。具体来说,YOLOv5x 是一个参数更多、计算量更大的模型,旨在提供最高的检测精度。
2.
最小和最快的模型,适合极低计算资源的环境。
参数数量和计算量最少。
配置文件:yolov5n.yaml
yolov5n.yaml
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
适合快速推理和资源受限的环境。
参数数量和计算量相对较少。
配置文件:yolov5s.yaml
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
在推理速度和检测精度之间取得平衡。
参数数量和计算量适中。
配置文件:yolov5m.yaml
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
适合需要更高检测精度的场景。
参数数量和计算量较多,推理速度相对较慢。
配置文件:yolov5l.yaml
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
最大规模的模型:YOLOv5x 拥有最深的网络层数和最宽的通道数,这使得它在复杂任务上具有更高的表现力和精度。
高计算复杂度:由于网络深度和宽度的增加,YOLOv5x 的计算量也显著增加,这需要更多的计算资源(如 GPU 内存和计算能力)。
最高精度:在所有 YOLOv5 模型中,YOLOv5x 通常能够实现最高的检测精度,适用于对精度要求最高的应用场景。
yolov5x.yaml
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
主要区别总结
depth_multiple 和 width_multiple:YOLOv5x 的 depth_multiple 和 width_multiple 分别是 1.33 和 1.25,相较于其他模型更大,这意味着它有更多的层和更宽的通道。
计算量和参数数量:由于网络的深度和宽度增加,YOLOv5x 具有最高的计算量和参数数量。
检测精度:YOLOv5x 通常能够提供最高的检测精度,适合需要高精度的任务。
选择合适的模型
选择哪种 YOLOv5 模型取决于你的应用场景、硬件资源和对模型性能的要求:
如果你需要快速推理且计算资源有限,选择 YOLOv5n 或 YOLOv5s。
如果你需要在推理速度和检测精度之间取得平衡,选择 YOLOv5m。
如果你需要高检测精度且有足够的计算资源,选择 YOLOv5l 或 YOLOv5x。
3.训练的时候要注意pytorch中cuda的版本和服务器上的版本是否对应:
torch中版本的查看方法如下:
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
print(torch.cuda.nccl.version())
print(torch.cuda.is_available()) # gpu是否可用
print(torch.cuda.device_count()) # 可使用的GPU个数
4.需要安装git
apt-get install git
5.为了防止关闭远程连接服务器的终端就终止训练,可以用以下几种方法:
1.nohup(no hangup)命令可以在后台运行进程,即使用户断开连接,进程也不会停止。
使用 nohup 运行你的训练脚本,并将输出重定向到一个日志文件:
nohup python3 train.py --data yolov5/data/data.yaml --epochs 300 --weights /yolov5/yolov5s.pt --cfg yolov5/models/yolov5s.yaml --batch-size 128 > train.log 2>&1 &
data.yaml内容如下
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: python train.py --data coco.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco ← downloads here (20.1 GB)# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: yolov5/dataset # dataset root dir
train: train2.lst # train images (relative to 'path') 118287 images
val: val2.lst # val images (relative to 'path') 5000 images# Classes
names:0: tray# Download script/URL (optional)
download: |from utils.general import download, Path# Download labelssegments = False # segment or box labelsdir = Path(yaml['path']) # dataset root dirurl = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labelsdownload(urls, dir=dir.parent)# Download dataurls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)download(urls, dir=dir / 'images', threads=3)nohup 会将命令放入后台运行,& 符号表示后台运行,输出将被重定向到 train.log 文件。
你可以使用 tail -f train.log 来查看日志文件的输出:
tail -f train.log
方法2:使用 screen
screen 是一个窗口管理器,可以在一个终端会话中运行多个全屏窗口。使用 screen 可以在断开连接后继续保持会话。
启动一个新的 screen 会话:
screen -S my_training_session
在 screen 会话中运行你的训练脚本:
python3 train.py --data yolov5/data/data.yaml --epochs 300 --weights /yolov5/yolov5s.pt --cfg yolov5/models/yolov5s.yaml --batch-size 128
断开 screen 会话:
按 Ctrl+A 然后按 D 键将会话断开。此时训练脚本仍然在后台运行。
重新连接到 screen 会话:
screen -r my_training_session
使用 tmux
tmux(terminal multiplexer)是另一个用于管理终端会话的工具,类似于 screen。
启动一个新的 tmux 会话:
tmux new -s my_training_session
在 tmux 会话中运行你的训练脚本:
python3 train.py --data yolov5/data/data.yaml --epochs 300 --weights /yolov5/yolov5s.pt --cfg yolov5/models/yolov5s.yaml --batch-size 128
断开 tmux 会话:
按 Ctrl+B 然后按 D 键将会话断开。此时训练脚本仍然在后台运行。
重新连接到 tmux 会话:
tmux attach -t my_training_session
使用 systemd 服务
如果你需要更高级的解决方案,可以创建一个 systemd 服务来管理你的训练任务。以下是一个示例 systemd 服务文件:
创建一个服务文件,例如 /etc/systemd/system/yolov5_train.service:
[Unit]
Description=YOLOv5 Training Service
After=network.target[Service]
ExecStart=/usr/bin/python yolov5/train.py --data yolov5/data/data.yaml --epochs 300 --weights yolov5/yolov5s.pt --cfg yolov5/models/yolov5s.yaml --batch-size 128
WorkingDirectory=yolov5
StandardOutput=append:/var/log/yolov5_train.log
StandardError=append:/var/log/yolov5_train.log
Restart=always
[Install]
WantedBy=multi-user.target
重新加载 systemd 并启动服务:
sudo systemctl daemon-reload
sudo systemctl start yolov5_train.service
sudo systemctl enable yolov5_train.service
5.上述代码的运行环境为python 3.10.12,H800:
torch 2.3.0+cu118
torchaudio 2.3.0+cu118
torchvision 0.18.0+cu118
pillow 10.3.0
当pillow==10.3.0训练时会报错:
AttributeError: 'FreeTypeFont' object has no attribute 'getsize'
此时可以将版本降低为pillow==9.5.0
6.训练时指定–devices时会报错,只有把–devices设置为""时可以正确运行。
7.如何监控GPU在训练时的状态
nvtop
or
watch -n 1 nvidia-smi
8.如何训练自己的数据集
首先要将数据集转换成yolov5需要的格式,yolov5中label的格式如下
0 0.5068664169787765 0.7690387016229713 0.12983770287141075 0.019975031210986267
每行包含五个参数
class x_center y_center width height
class:目标类别的索引(从0开始)。表示该目标所属的类别。
x_center:目标的中心点在图片宽度方向上的相对坐标,取值范围为 [0, 1]。计算方法为:目标中心点的绝对坐标除以图片的宽度。
y_center:目标的中心点在图片高度方向上的相对坐标,取值范围为 [0, 1]。计算方法为:目标中心点的绝对坐标除以图片的高度。
width:目标在图片宽度方向上的相对宽度,取值范围为 [0, 1]。计算方法为:目标的宽度除以图片的宽度。
height:目标在图片高度方向上的相对高度,取值范围为 [0, 1]。计算方法为:目标的高度除以图片的高度。
class:0 表示目标类别为第0类。
x_center:0.5068664169787765 表示目标中心点在图片宽度方向上的相对坐标,大约在图片宽度的 50.69% 位置。
y_center:0.7690387016229713 表示目标中心点在图片高度方向上的相对坐标,大约在图片高度的 76.90% 位置。
width:0.12983770287141075 表示目标在图片宽度方向上的相对宽度,大约占图片宽度的 12.98%。
height:0.019975031210986267 表示目标在图片高度方向上的相对高度,大约占图片高度的 1.99%。
YOLOv5 中标签文件的每行包含五个参数:类别索引、目标中心点的相对横坐标、目标中心点的相对纵坐标、目标的相对宽度、目标的相对高度。这些相对坐标和尺寸确保了标签文件与图片分辨率无关,可以适应不同尺寸的输入图片。
标注用的工具,能够直接生成YOLO的标签格式的工具 LabelImg。
pip install labelImg
还需要修改一些参数,在train.py中
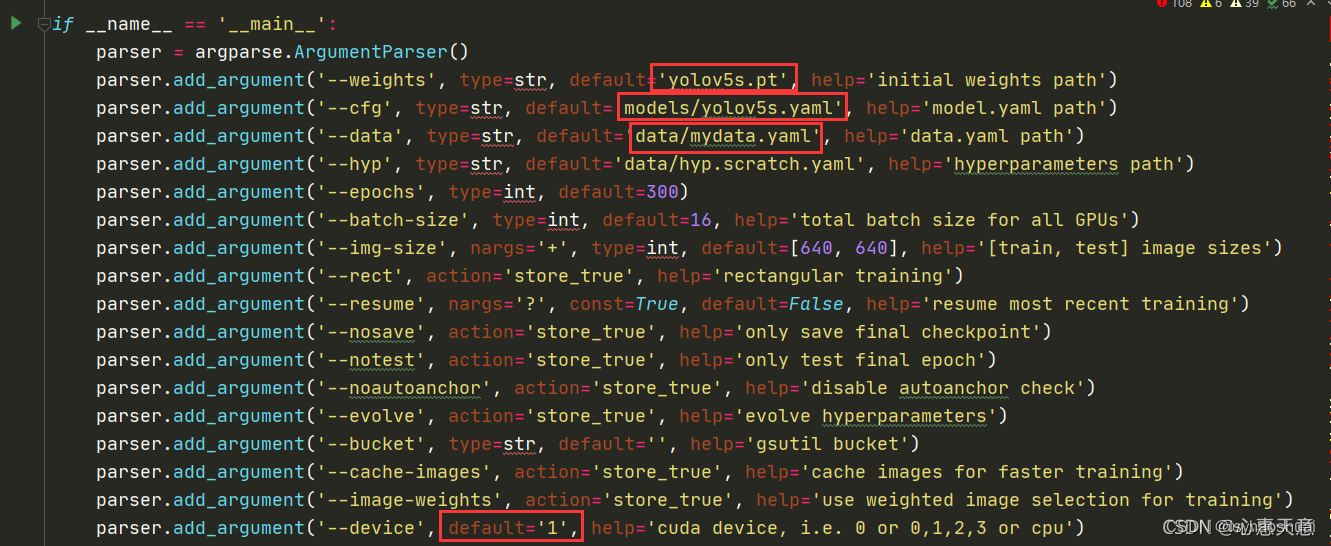 mydata.yaml中需要修改
mydata.yaml中需要修改
path: yolov5/dataset # dataset root dir
train: train2.lst # train images (relative to 'path') 118287 images
val: val2.lst # val images (relative to 'path') 5000 images
names:0: person
yolov5s.yaml
nc:1 #分类个数
这篇关于关于yolov5训练的那些事儿的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[yolov5] --- yolov5入门实战「土堆视频」](https://i-blog.csdnimg.cn/direct/8e01ba7709e34acc929cfe32af9e4c41.png)


