本文主要是介绍逻辑这回事(五)---- 资源优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基础篇
Memory
- 避免细碎的RAM。将大的RAM拆分成多个小RAM,并根据地址关断可以优化功耗,但把多个小RAM合成大RAM可以优化面积。
- Block RAM和分布式RAM合理选择。根据存储容量,对Block RAM和分布式RAM的实现面积和功耗进行评估,选择更优的实现方式(对于40nm工艺,1bit 寄存器面积大约为5.3um2;对于22nm工艺,1bit 寄存器面积大约为2.9um2;对于Block RAM面积与深度/位宽不成线性比例,需要看综合工具的结果)。要例化一个位宽较大,但深度较浅的RAM块,例如宽度512bit,深度64的RAM,由于RAM位宽最大为72bit,至少需要8块RAM。此时,为了节省资源,可以使用分布式RAM。通常原则是:容量<2K,深度<64或宽度<64的RAM,使用分布式的RAM。对于宽度较大(大于256bit),深度较小(小于64)的RAM,这种比例失衡的RAM也可以考虑使用分布式RAM。
- 合理的选取RAM。无论是FPGA还是ASIC一般集成多个RAM块,这些RAM块大小固定。例如FPGA上一般为9Kbit,18Kbit,20Kbit、36Kbit,称为Block Ram。可实现RAM、ROM、FIFO等功能。RAM块位宽一般支持1,2,4,8,9,16,18,32,36,64,72等。例如FPGA要例化1个12bit的RAM,实现时会使用16bit或18bit位宽,造成浪费。假如RAM深度较深,那么可以例化1个8bit和1个4bit的RAM拼接成1个12bit的RAM来使用,以节省RAM块数。如果是ASIC,RAM设计时需要充分考虑块数、深度和宽度、单口/双口等特性,对各种组合情况充分评估面积和功耗,选择最优。不同memory类型如regfile、spram、dpram所占用的面积有所差异,可以用综合工具尝试不同深度和位宽,寻找最优的设计方案。
- ASIC设计使用高密度Memory,减小面积。通常我们以端口功能来对Memory分类,对应到物理实现上,每一种memory,都有多个不同的类型可以选择,包括HSD(高速)、HD(高密度)、UHD等。Memory的功耗、面积与其bit数,并不是理想的比例关系,具体选择哪一种memory类型,需要实际综合一下看看。
| 深度x位宽(bit) | Memory Type | Memory Lib | Density | Area(um2) |
| 512x32 | sprf | rf1 | hd | 6634.1 |
| 1024x32 | sprf | spsram | uhd | 10429.6 |
| 2048x32 | sprf | spsram | uhd | 17446.3 |
| 4096x32 | sprf | spsram | uhd | 30463.6 |
| 8192x32 | sprf | spsram | uhd | 56680.1 |
| 512x16 | sprf | rf1 | hd | 4016.0 |
| 1024x16 | sprf | spsram | uhd | 6538.7 |
| 2048x16 | sprf | spsram | uhd | 10429.6 |
| 4096x16 | sprf | spsram | uhd | 17446.3 |
| 8192x16 | sprf | spsram | uhd | 30561.7 |
| 512x8 | sprf | rf1 | hd | 2707.0 |
| 1024x8 | sprf | rf1 | hd | 3931.7 |
| 2048x8 | sprf | rf1 | hd | 6538.7 |
| 4096x8 | sprf | spsram | uhd | 10485.8 |
| 8192x8 | sprf | spsram | uhd | 17502.5 |
| 1024x16 | sprf | dpsram | uhd | 14168.6 |
| 1024x8 | sprf | dpsram | uhd | 9543.7 |
上面是22nm工艺指定深度x位宽后,综合工具遍历不同配置(如Memory Type、Memory Lib等),再根据结果(如面积、功耗等)打分,选出最优的配置。从上面可以看出:
- memory最终的面积与深度x位宽不是线性的关系;
- 当深度x位宽固定时,最终的面积差异不大;如2048x32和4096x16的面积都是17446.3um2。但吞吐量一定时,2048x32的读写频率只有4096x16的一半,2048x32的动态功耗会更优(前面的功耗优化章节已提供具体数据)。
- 当深度x位宽固定时,双端口memory的面积是单端口面积的2~3倍。
- RAM块单元集成输出寄存器,可选择使能或不使能。建议大家使用输出寄存器,一方面时序好,另一方面节省了额外的寄存器。
- 减少对冗余信息的存储,尽量减少片内存储器。减少对临时存储的需求,尽量快速利用计算后的结果。
- 采用Free List或Pointer RAM技术实现多端口共享存储FIFO。
举例1:提频--增强RAM性能
- 双宽度RAM:
将RAM频率提高,可以提升RAM带宽,利用该特性,使用倍频时钟。利用倍频时钟将RAM带宽加倍,2个倍频周期数据供一个同频时钟周期使用,实现RAM宽度加倍。一个M9K实现72bit读写位宽,在大位宽RAM应用中可节省一半RAM。
2.双端口RAM
直接使用双端口RAM面积更大(ASIC的双端口RAM面积大约是单端口的2~3倍),尽量使用单口RAM。要充分考虑是否一定需要使用双口RAM,能否用一个大的单口RAM和一个小的双口RAM代替一个大的双口RAM,或者全部用单口RAM代替双口RAM。例如:将RAM部分的时钟频率提高一倍,即可以一个同样大小的单口RAM代替原有的双口RAM。利用倍频时钟将RAM带宽加倍,倍频周期奇数拍作为一个端口使用,偶数拍作为另一个端口使用。一个M9K即可实现2个端口读,2个端口写。
某ASIC项目中,ACQ模块需要先暂存50ms的数据,写速率为4.092Ms/s,即需要存4092*50*4bit数据。
方案1:使用50块1024x16双端口RAM,Memory总面积就达到了惊人的 50*14168.6=708,430um2。
方案2:由于读写速率不高,因此完全可以把时钟提频,使用50块1024x16单端口RAM实现,总面积为50*6538.7=326,935 um2,相对于方案1面积减少了50%以上。
方案3:如果时钟提频,使用13块4096x16单端口RAM实现,总面积为13*17446.3=226,801.9um2,相对于方案1面积减少了60%以上。
举例2:活用RAM--大位宽数据并串/串并转换
某逻辑内部主处理部分到接口部分,面临大位宽到小位宽变换的问题。在通道数较多时,需要的REG在10K级别。利用多个小位宽RAM进行优化,以4路数据方例:
- 第一拍并行数据为第1路4个时刻的数据,将第1路的并行数据分为4部分,分到写人4个RAM中。第一个RAM的写地址为0,第二个RAM的写地址为1,第三个RAM的写地址为2,第4个RAM前写地进为3,见下图黄色分;
- 第二拍并行数据为第2路4个时刻的数据,同样将并行数据分为4部分。分到写人4个RAM中,但地址为1-2-3-0,见下图橙色部分;
- 第三拍,第四拍类似,见下图浅蓝色,深蓝色部分;
- 顺序读4个RAM,同时将输出数据分配到各自的接口即可。
经过上述处理,利用RAM完成了并串转换,处理简单而且节约了大量的寄存器资源。

举例3:活用RAM--用RAM实现多拍的数据延迟
流水处理中经常对数据打拍,一般REG实现,现在的设计数据位宽通常是64/128/256甚至512位宽,打上几拍后资源消耗还是很大的。对于打拍大于2,小于几十的应用,可以用分布式RAM来实现,这将节省大量的寄存器资源。例如fir滤波器,resample滤波器中的打拍均可以通过RAM实现,通过控制读写地址实现延迟。
举例4:活用RAM—使用RAM进行统计上报
对统计来源较少,但对应统计项较多、规律性强的统计计数器,应考虑用RAM实现。例如统计有效数据包的个数,假设数据中存在pkt_id,pkt_id为0~63,则ram的深度为64,pkt_id用于作为读写地址,当匹配到pkt_id后,相应的地址的内容加1。
举例5:活用RAM--复杂状态机由RAM替换
APS复杂状态机占用资源较多:
- 线性APS有6种倒换模式,对应的6个状态机,单独综合结果占用463 LUT;
- 环网APS状态机单独综合结果占用202个LUT;
- 新增BFD PSC协议,状态机复杂度与线性APS状态机相当;
- 状态机表格中,状态跳转存在大状态机套小状态机的情况,如初态NR_P,条件FAR_NR_P,需要看上一状态,如果上一状态为SF_W,进入WTR,否则进入NR_W。
优化措施:状态机通过RAM实现,RAM地址为初态和条件的编码,RAM存储内容为下一跳转状态。
思考:使用XILINX K7器件,例化一个宽度为24bit,深度为2K的RAM块,需要几块M18K?
3块,使用3个8bit宽,2K深度的RAM拼起来,每个RAM消耗一个M18K。
可编程IO
FPGA的IO非常强大,几乎可以支持所有的电平标准,并能与多种器件对接,但是FPGA的IO数目有限,要节省使用。
- 减少冗余IO
例如CPU对接,一般带宽要求不高,可以适当减少CPU接口的地址线和数据线。
- 合理使用接口模式
例如一个GE接口,如果选择GMII接口,需要22个管脚;如果选择RGMII接口,只需要12个管脚;如果使用SGMII接口,只需要4个管脚。
- IO寄存器
IO模块集成了很多寄存器,如果能够使用其中的寄存器,实现输入输出信号需要的寄存功能,即节省了寄存器,又可以减少输入输出信号的延迟。
时钟资源
FPGA时钟资源包括:PLL、DLL、全局线、区域线等。FPGA的时钟资源非常有限,一般器件只有4~8个锁相环,16~32根全局线,使用时合理取舍。
例如:要使用某个时钟的180度相位,直接使用该时钟的负沿,而不用生成一个独立的180度相位时钟。
要节省FPGA的布线资源,将扇出较大的信号,例如复位信号上全局线。要节省全局线资源,将扇出不大的时钟上区域线。对于不需要做复位同步化,使用不同时钟的多个逻辑块,使用1个复位信号。
资源复用
复用--节省资源的最好方法
如果一个寄存器,或一块RAM做了两件甚至多件事,那么就相当于一分钱辦成了多份花。这就是节省逻辑资源最好的办法----复用。固网从窄带到宽带,移动网从1G到5G,都是因为采用各种复用技术。逻辑复用可以采取如下办法:
- 复用寄存器,例如寄存多种报文的KEY,如果不同时使用,可以复用。
- 复用RAM,在带宽和容量足够的情况下,多个表项共享1块RAM。
- 复用流水线,例如查找2个没有前后关系的表项,可以在1个流水完成。
- 复用公共模块;
……
注意:不能无限度的复用,关键是各种资源的平衡。
举例1:
优化前:某项目中,输入补码格式数据需要复制很多份,经过选择等处理后,送到乘法器前再转为原码。
优化后:将补码转原码挪到复制前,大大节省了逻辑资源(>8000LUT)。
举例2:
某模块原设计使用4个40bit/20bit的除法器,每个除法器资源1K+;通过分析,同一时间只会使用1个除法器,复用除法器后减少资源3K+。
线性APS与环网APS存在较多类似的功能点,提取线性APS与环网APS共性部分,共用一套轮询机制,寄存器资源进行复用。
举例3:
某项目在做DPD校准时,需要在频域进行计算。但DPD方案是在离线做,不会有正常业务。因此把DPD dump的数据直接送到RX链路的rxfreq的RAM中,再复用RX的fft模块,fft模块再给出校正结果。这样直接节省了一个fft模块,优化了面积xx。
提频--资源优化的重要方法
提升频率的好处:
(1)提升频率能够减小输出处理位宽,大幅度节省资源;
(2)提升频率能够大幅度提高模块处理性能。
假设1个10G的设计,如果主频提高1倍,资源不变(假设不涉及外部存储器),那么处理能力可达到20G。也就是说,如果主频提高1倍,资源减半(假设不涉及外部存储器),那么处理能力可近似达到10G。
某项目实现AES加解密,一个加解密模块大约1200LUTs,10拍才能完成,如果模块跑100M,需要10个。项目组进行挑战,将加密模块提频到200M,只使用了5个模块,节省6000+LUTs。
深入理解HDL语言
作为设计人员,需要清楚HDL语言中各种运算消耗的资源相对大小,通常情况下:逻辑运算<加减<乘除
- 设计时优先采用逻辑运算。习惯使用位操作符(|、&、~)描述逻辑,避免&&、||、== 类操作,特别避免>、<类描述。尤其在ASIC设计时,位操作描述是最接近逻辑本身结构的,能够很好地描述逻辑,并引导DC综合工具实现对应逻辑。习惯用~写代码,我们喜欢(Valid == 1’b1 && Ready == 1’b1)的描述,却忽视了~(valid_n|ready_n)这样更加优异的描述。工艺上,所有的Cell,天生带非门,任何不带非门的逻辑描述,都需要额外的~ Cell来解决。所以,我们在主要的Data Path上,每过一级逻辑,天然取非,到下一级,再取非。
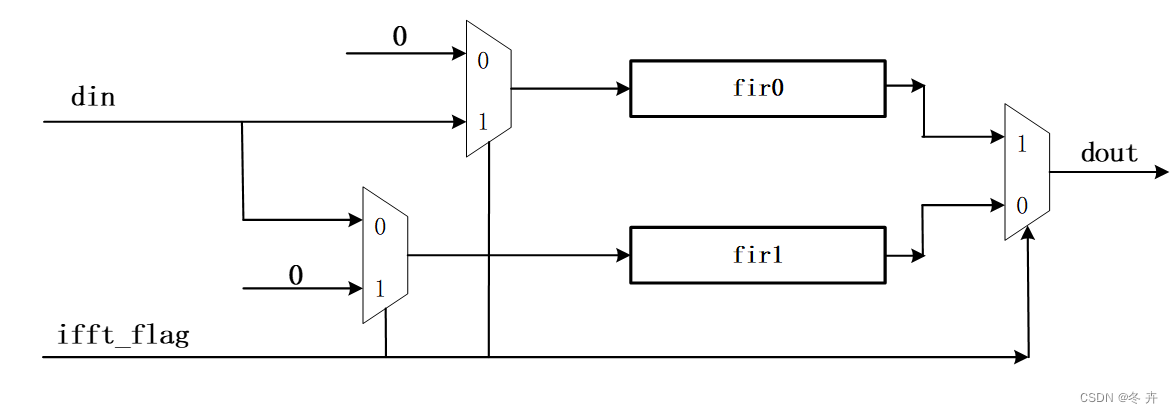
- 乘除尽量用加减和移位来做,乘法的本质上是加法的组合,对于常系数乘法,最节省硬件资源的做法是用累加的方法来实现,如X*3=X*2+X=(X<<1)+X。特别是对于阶数较大的定系数滤波器,可以节省不少资源。如某项目,会用到47阶变系数的fir滤波器,系数根据ifft_flag指示取不同的值。有两种方案,方案1:直接设计47阶的变系数滤波器;方案2:设计2个定系数的滤波器,输入根据ifft_flag进行操作数隔离降低功耗,输出通过ifft_flag进行MUX。从综合的结果看,方案2的面积只有方案1的一半。
编程小技巧
- 复位信号,统一采用高复位或者低复位,可以下全局网络后再取反使用。
- 寄存器不复位,例如打拍寄存器,不关心复位后的状态,不带复位端的寄存器面积会更小,还可以节省布线资源,功耗也更优。
- 寄存器不清零,只要保证使用时刻的正确性,其他时刻可以不保证,从而减少输入条件和逻辑级数。
- 减少冗余条件,例如配置寄存器译码,不使用全部地址线,只使用其中几位地址,减少判断条件。
- 跨时钟域时可以用同步FIFO代替异步FIFO。可以用一个小的异步FIFO和一个大的同步FIFO来代替大的异步FIFO。
- 设计编码时要能估计使用的资源(寄存器、加法器、乘法器、RAM等) 数量,清楚占用面积,从而有目的的进行优化。对拿不准的地方,子模块前期一定要单独综合,根据综合结果进行定向优化。
- 多路选择器的输入状态数尽量设置为2^n。17选1的mux的面积,比16选1的mux大不少。但是从17选1到32选1,面积增加不多。多路选择器输入状态的增加,对面积的增加有很大影响。所以在性能允许的前提下,尽量选择用少输入的选择器多拍来实现。mux的输入端很多时,不仅对面积有影响,还会对布线不利。因此尽量将大的mux拆分成小的mux,多拍流水实现。
- 对于非2^n的多路选择器,合理选择纯case和提取case的形式。当状态数接近相邻的小的2^n,用提取case方法对面积更优化;当状态数接近相邻的大的2^n,用纯case方法对面积更优化。
- 合理选择if/else和case的形式描述多路选择器。输入选择条件较少 (小于等于5) 时,用case和if/else相当; 大于5时用case比if/else综合后的面积小。
- 在使用有待选项的情况下,尽量固定default值为固定的逻辑1或0,得到较小的面积。
- 尽量选择case起始状态为0的多路选择器。
- 注意比较器在不同位宽、常量/变量比较、大于/小于比较等条件下的面积的不同。合理使用大位宽运算单元,有效减小芯片面积
- 在满足时序、性能的前提下,通过提高时钟频率,采用时分复用、串行处理、模块复用节省面积。
- 用流分类方案实现遍历查找,降低芯片资源和面积。
- 优先使用树状结构实现优先级编码器;合理选择链状结构和树状结构实现复用器的编码设计。链状结构面积占优;树状结构速度占优。
- 综合考虑数据位宽、面积要求、时序要求、综合的时间约束等因素选择index方式或foroop方式实现解码器。
- 如果FPGA有较多的DSP块,也可以来做乘除运算,以节省可编程逻辑单元的消耗。另外,也可以使用RAM查表的方法实现位宽较小的乘除法。
采用最优实现方式
异步信号握手
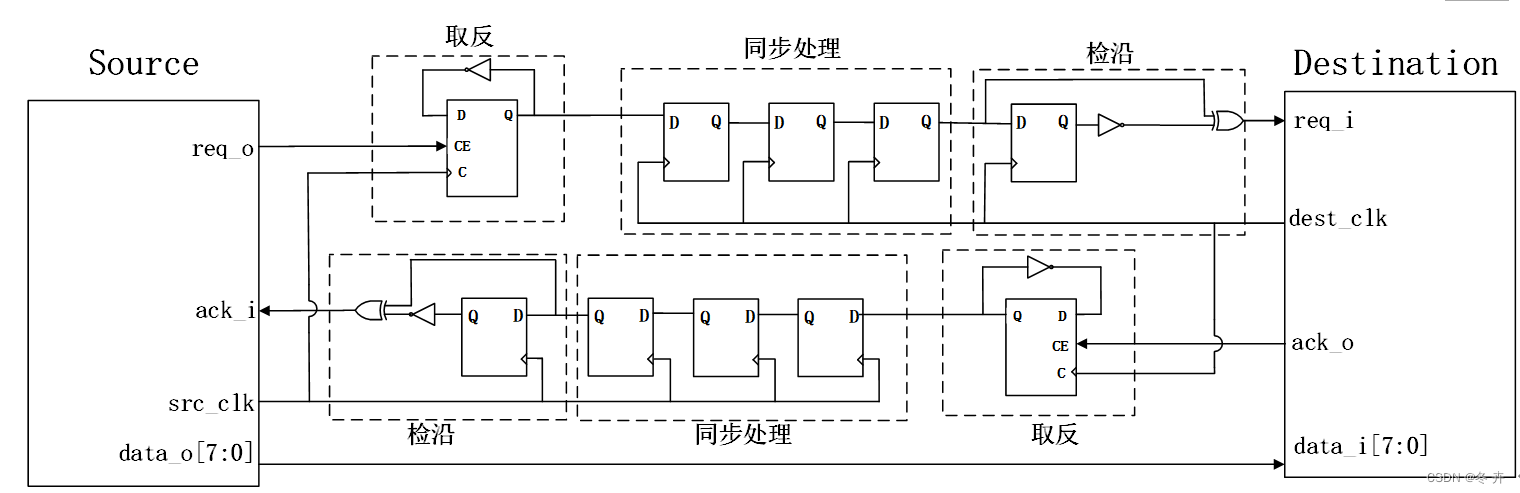
在异步信号握手时,如果源时钟较快,一般将信号展宽,保证其能够被目的端慢速时钟采到。展宽设计需要使用多个寄存器,并且需要的寄存器数目和两个时钟的比例相关,不通用。这个设计可以进行优化,如下图所示,每次握手时将信号取反,目的端通过采样上升和下降沿来实现握手,简洁又通用。
运算顺序
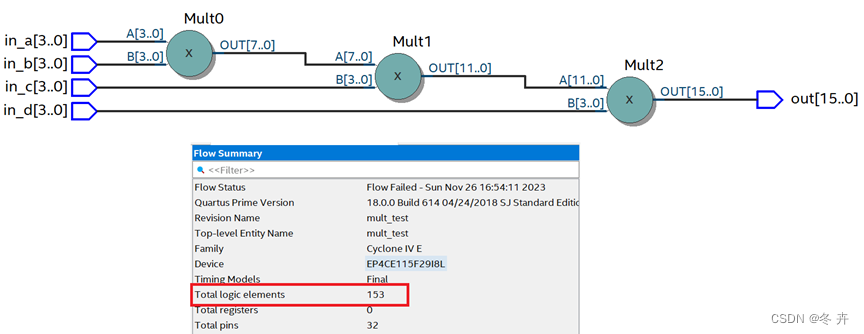
如果4个位宽都为4bit的a、b、c、d四个信号相乘,有2种方案。
方案1:assign out = a*b*c*d;
方案2:assign out = (a*b)*(c*d);
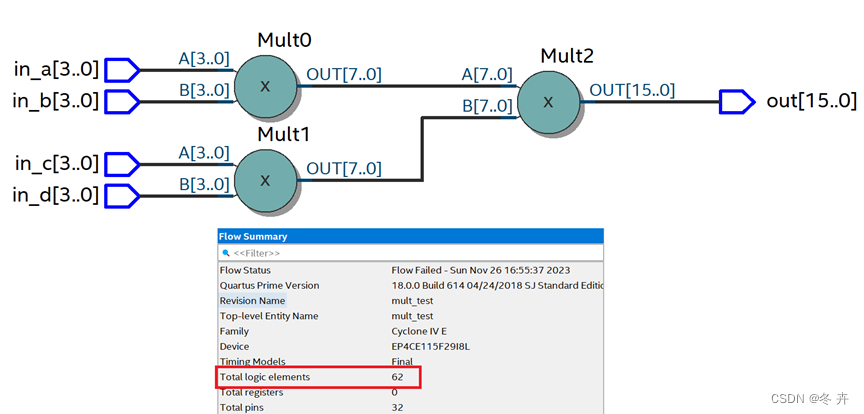
显然方案2的面积和时序都优于方案1。
面积和时序的平衡
代码的风格会直接影响到网表结果,向关键路径要时间,向非关键路径要面积。如下图,a[31:0]是one-hot编码,中间的省略号省略了[29:3]共27个信号的赋值语句。下面2种风格的代码,哪个的面积更小?哪种时序更好?

如下案例是一个常系数乘法的两种实现方案:
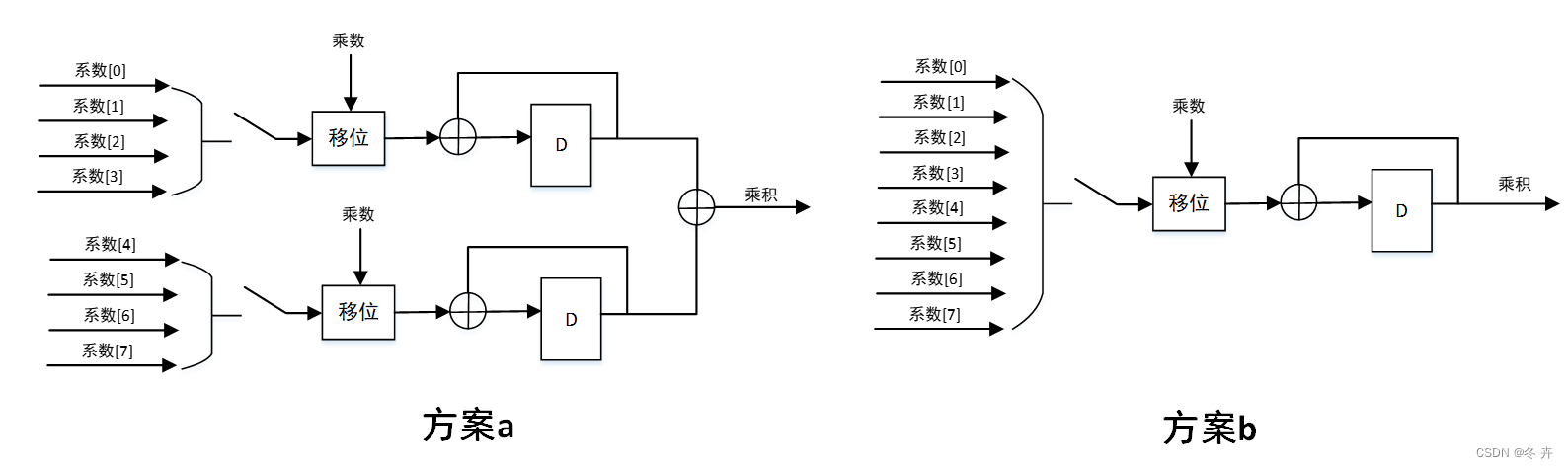
方案b所采用的处理,所需硬件最少,只用一个加法器,但是需要8拍才处理完一次乘法。方案a增加了一个加法器可以节省一半的时间。因此资源和时间的互换是一种设计思路,可以用时间换资源,也可以用资源换时间,具体使用哪一种应该在明确需求的基础上灵活选择。
大的组合逻辑分多级处理
对复杂逻辑进行合理的pipeline拆分,增加小量reg情况下,解决时序瓶颈,并能提升资源利用率。
举例:
(1)在64字节(512bit)位宽处理时,实现挤气泡功能,用两个8选1级联,比一次完成64选1资源少,且速率高;
(2)某大型TM调度中要实现32K选1,原来是两级,一级512选1,另一级是64选1。改为三级后,每级32选1,资源优化了xxx。
无关项的处理
无关项的赋值指定成不同值,可能会对资源有明显的影响。如下图,左边写法使用了24个ALM,右边的写法使用了20个ALM。写代码时,无关项的赋值需要进行分析和比较。

减少冗余寄存
逻辑设计中,为了优化时序,往往会插入寄存器,以减少组合逻辑级数。
要把握好寄存的度,并不是寄存得越多越好。要减少无效寄存,尤其是位宽大的数据,因为大量使用寄存器会降低LUT的利用率。
对于资源优先的项目,为了简化处理,可以规定模块输出接口要寄存,模块输入接口不寄存。如果条件允许,可以利用多周期约束,减少寄存器消耗。
算法优化
我们设计大多数自顶向下的,越在高层,优化的空间越大。不同的算法方案,对PPA影响都不一样,需要折中考虑。算法优化可以分为两类,一类是无损失性能的优化,例如复数乘法一般需要4个乘法器,但在某些位宽情况下,用3个乘法器能够达到一样的效果,性能无损失,但面积会更优。另一类是对性能有损失,但算法评估在预期以内,例如复数的abs运算。
举例1:
某项目中某个算法为有符号数A和B分别平方后相加得到C,如下图。最开始采用处理a的方式实现,在时序分析时发现该计算过程中的加法运算为一条关键路径,无法达到频率要求。通过分析定点化方案,发现加法器的输出结果不必全部保留,通过将u(57,47)饱和到u(47,37),可使参与加法运算数据的位宽减少到37bit,而不再是46bit。 修改后采用处理b的方式,该路径能够达到频率要求。
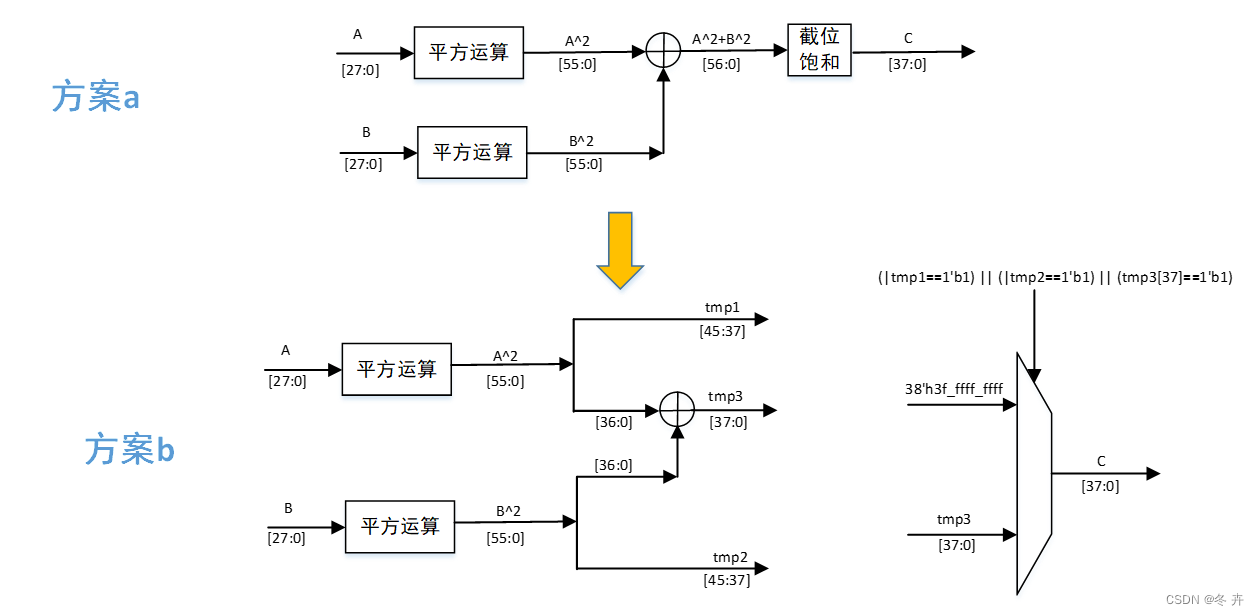
在算法设计过程中,对定点方案的分析至关重要。通过优化定点方案能对整个设计时序、面积带来较大收益。算法电路的选取需要在算法精度、工作频率、面积功耗以及处理延迟之间做平衡;合理的使用datapath进行算法设计,会带来较大的收益。
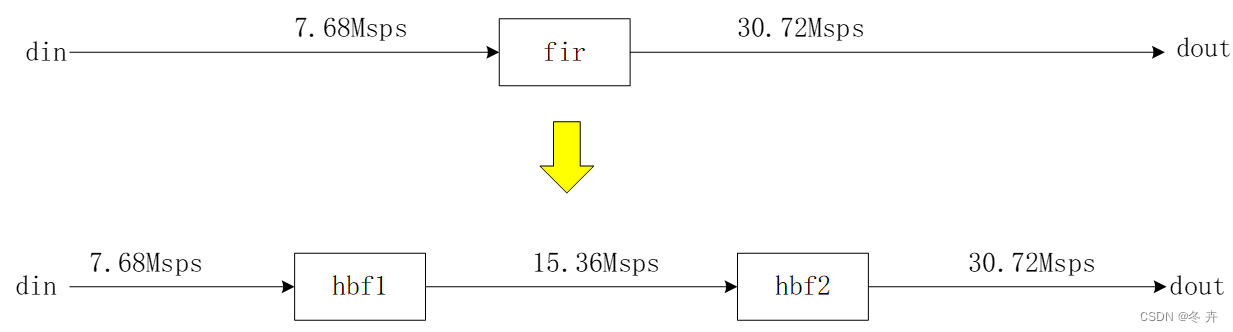
举例2:
某项目中用两个27阶的HBF就能得得和一个47阶的FIR相当的性能,由于HBF的一些特性,会节省更多的乘法器和加法器。
举例3:
某项目需要根据PING-PANG RAM的方式,处理40ms+40ms的数据,即需要预先缓存80ms的数据进行算法运算,共使用40块2048*16bit的RAM,22nm工艺下综合的总面积达到了70万um^2。后来跟算法讨论,采用跳窗的方式实现,每个channel只移动一个PRN code长度,这样的话就只需要缓存50ms的数据了。算法仿真性能会损失2dB,但RAM面积可以节省30%以上。
举例4:
在进行数据截位时,可以采用floor/nearest/round方案,面积上floor <nearest <round,但floor会引入有负的直流值,nearest会引入正的直流值,round无直流影响。饱和时,有对称饱和与非对称饱和,非对称饱和面积会更小,但输出在满量程负数时,可能会引起下游模块溢出的风险。虽然单个截位/饱和模块不同方式的面积差异不大,但如果芯片中使用的个数较多时,面积收益还是可观的。
Datapath编码优化
对于运算处理集中的电路,通过熟练掌握datapath的综合优化特点,可以较好的节省设计面积和资源。提升datapath性能的关键技术是避免复杂进位传递(expensive carry-propagations),而尽量(对中间结果)使用元余表达(redundant representations,比如carry-save),其他技术还包括高阶算数优化等。Datapah不应被某些类型的表达式(任意长的积之和,有限长的和之积,选择、比较、移位处理等)打断,而应采用冗余表达。
//Case1: bad QoR(quality of result)
input [7:0] a,b;
output [15:0] z;
// a, b sign-extended to width of z
assign z ={{8{a[7]}},a[7:0]}* {{8{b7]}},b[7:0]};
// ->unsigned 16x16=16 bit multiply
//Case2: good QoR (quality of result)
input signed [7:0] a,b;
output signed [15:0] z;
assign z =a*b; // ->signed 8x8=16 bit multiply
对于上面所示的运算电路,通过采用datapath进行综合,无论是工作频率还是面积Case1都更有优势,如果存在更多的数学运算形成datapath那么收益会更大。
| Slack | Area | |
| Case1 | -2.42 | 14296 |
| Case2 | -2.11 | 8598 |
| 约束 | 1、Target Library TSMC 0.18um 2、set_max_delay -from [all_inputs] -to [all_outputs] 0 3、set_max_area 0 | |
善用卡诺图化简
不要迷信DC能够将所有的条件描述化简到最优,换句话说,卡诺图化简确实非常有效。任何一份没有经过反复敲打的代码,它的条件描述一定可以被优化,从无例外。化简后的条件,难以阅读,可适当增加可读的注释。
化简选择条件
下面代码主要完成在固定时隙,进行不同的数据拼凑。其中的case选择范围很大0~955优化的方案,就是寻找其中的规律,将选择范围分解成多个小范围的选择,从而减少逻辑资源大约50%。
减小数据位宽
某项目要求处理8Gbps,主频为166M,数据位宽128bit,实际处理能力达到166*128=21.2Gbps。
处理能力严重浪费,将数据位宽修改为64bit,处理能力10.6G,即满足了处理要求,又大大节省了资源。
规范统计位宽
逻辑DFX设计中,需要使用大量的统计计数器,这些计数器加起来,要消耗大量的逻辑资源。
要优化资源,一方面要减少无用统计,另一方面可以适当减少计数器位宽,例如:对于前后两个模块,要确定是否丢包,两个模块的报文统计计数器位宽不用一致,只要看计数器的尾数部分是否一致就可以。另外,有些计数器只要确定有变化,就可以确定逻辑没有挂死,这时4-8位即可以满足需求。可以规定,内部DFX统计统一为4/8bit 位宽,一些特殊的计数统计可以根据需求放宽。
多周期约束
如果条件允许,可以利用多周期约束,减少资源消耗。例如寄存器译码模块,其地址线,数据线扇出很大,要满足时序要求需要多次寄存,消耗大量逻辑资源。如果采用多周期约束,则即可以轻松满足时序要求,又可以节省大量逻辑资源。
进阶篇
把好需求关
同样是编程,软件和逻辑从差别是什么?软硬件编程的差别:
- 软件代码消耗的是程序RAM、CPU内存,这些资源一般比较充裕,相对便宜的,只会影响系统的快慢。
- 逻辑代码消耗的是FPGA的LUT、REG、布线资源等,这些资源少且昂贵,会极大影响成本,如果资源消耗过多,可能会导致布线失败,项目FAIL。
例如:软件可以使用大的CASE进行分支编程,简洁而且耦合少,同一时刻只有一个分支调入内存进行处理。逻辑如果写CASE形式,所有CASE都会占用逻辑资源,且是同时只有一个分支的结果被使用。
硬件擅长做简单,重复,性能高的需求。复杂的,性能低的需求,尽量交给软件做。
几个看似简单,实际实现难度大的例子:
- 短包线速
包处理速率要求高,要求更少的流水线拍数,更高的查表带宽。
- 任意包长线速
主要设计N+1问题,例如65字节,129字节等,逻辑内部一般分片处理,包尾小分片对逻辑处理,数据存储等多方面提出高要求。
- Jumbo帧
要支持9600字节的包长,在接口、错包过滤、缓存管理等多方面带来难度以及较多的资源消耗。
实际上这些需求并不是必须的,某产品针对这几个需求进行了优化,使逻辑设计难度,成本大为降低,例如:
在包长线速方面,只支持混合包长线速,例如xx%的64字节报文,xx%的512字节报文。在报文长度方面,只支持2K字节以下的包长。
接纳需求要慎重,要分析对逻辑的影响,实现的成本。
资源平衡
与ASIC不同,FPGA是通用器件,可用资源是确定的,网络逻辑主要关注3部分资源,即REG、RAM、LUT。设计方案需要预估消耗的3种资源,不要因为某种资源使用过多而导致器件升级。一般FPGA的RAM可以使用到80%,REG和LUT可使用到60%。如果资源太多,后果很严重:轻则升级器件,重则重新投板。
位宽和主频
位宽和主频的乘积决定了数据处理能力,位宽(数据通道位宽,控制通道位宽)越小,资源越少。
假如提高主频,就能够减小位宽,大幅度节省资源。举例来说,一个10G的设计:
- 如果主频提高1倍,那么资源不变的情况下(假设不涉及外部存储器),处理能力达到20G。
- 如果位宽增加1倍,那么资源增加1倍,处理能力不一定达到20G,因为控制通道流水拍数不变,包处理能力没有提高。建议位宽:
4G以下性能:32bit;
10G性能:64bit;
20G性能:128bit;
40G性能:256bit.
流水线
定长流水线:所有流水同步,同时开始,同时结束,每拍时钟的状态都是可知的。
变长流水线:各个流水不同步,有长有短,流水直接使用FIFO隔离。
个人建议:
定长流水适合控制通道模块,例如调度模块、查找模块。
变长流水适合数据通道模块,例如报文收发、报文读写RAM.
原因:
- 控制通道与报文长度无关,定长流水方便各个模块间的配合,避免模块间FIFO的使用。
- 数据通道定长切片后,尾片变长,变长流水容易达到处理性能的要求。
举例说明:
最小包长为64字节,处理性能10Mbps,主频150M的系统,一般15拍处理1个报文就够了。但是,由于设计要对报文进行分片处理,如果分片大小为64字节,那么65字节的报文就要分两个分片处理,要求的处理能力就是20Mbps了。
对于定长系统,处理能力需要加倍,则每级流水最多只能由7拍;
对于变长系统,第一个分片使用12拍,第二个分片3拍;比较起来,变长系统第一个分片处理时间比定长系统多5拍,设计难度大大降低。
方案设计的关键问题-外挂存储器
外挂存储器个数决定外挂成本,同时决定了IO多少,控制器个数。以DDR为例,需要掌握:
- DDR的通用读写时序;
- DDR的BANK操作要求,例如,DDR的TRC时间一般为50-60ns左右,因此一秒可以访问一个BANK约20M次左右,可以用于10Gbps的应用场景;
- DDR的读写切换参数;
- 要想尽办法提高DDR的利用率,设计要点:
- 减少读写切换次数,连续写几次后,再连续读几次,通过加大读写缓存深度来实现;
- 不同BANK之间依次操作,轮流激活和读写;
- 同BANK操作尽量是同行操作,避免二次激活;
思考:
1、20Gbps的应用可以用DDR查表么?
2、10x1G的和1x10G的项目,存储要求一样吗?
外挂存储器优化举例一:利用DDR的写掩码功能简化RAM设计
某模块对4K个数据流的分片进行重组,优化前使用3块RAM,一块存储重组信息,一块存储分片最后不满16字节数据,一块存储重组后的报文数据;其中前2块RAM使用QDR,第三块使用DDR,逻辑资源6741 LUTS。
利用DDR的写掩码信号改写后,使用2块RAM,一块存储重组信息,一块存储重组后的报文数据;第一块RAM使用内部RAM,45Bit*4K,共11块M18K;上一分片不满16字节的数据先写入DDR中,下一个分片从不满16字节的位置写数据,对于已写入的有效数据将相应字节的写掩码bit置有效,保证有效数据不被改写。
优化结果:省去外部QDR,模块处理流程简化,资源减少为2215 LUTS。
外挂存储器优化举例二
某项目,部分数据流为二层业务,部分数据流为三层业务,其中层转发需要使用DDR的4个bank带宽;三层转发需要使用DDR的3个bank带宽;那么一共需要多少使用个bank?
可以使用4个bank,其中3个bank由二层表项和三层表项共享,另一个bank由二层表项独享。
思考:如果采用定长流水,可以共享RAM么?
方案设计的关键问题-架构
上下行架构:接口分为两部分,即上行接口和下行接口,逻辑处理分为两条通路。
集中式架构:所有入口数据汇聚起来,集中处理,之后再分发到各个出口。
如果上下行业务相差不大,所有接口带宽不高,则可以考虑采用集中式架构,相对上下行架构就是通路复用,可以节省近一半逻辑资源。
当然,如果接口带宽达到80G,集中式处理架构的数据位宽会达到512bit,流水线也只有1到2拍,这时最好采用上下行架构,降低实现难度。
这篇关于逻辑这回事(五)---- 资源优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






