本文主要是介绍JProfiler 性能分析案列——dump.hprof 堆内存快照文件分析排查内存溢出,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在 windows 环境下实现。
一、配置 JVM 参数
配置两个 JVM 参数:
- -XX:+HeapDumpOnOutOfMemoryError,配置这个参数,会在发生内存溢出时 dump 生成内存快照文件(xxx.hprof)
- -XX:HeapDumpPath=F:\logs,指定生成内存快照文件的路径。
为了测试方便,将堆内存设置小一点
- -Xms512m,设置堆内存空间下限。
- -Xmx512m,设置堆内存空间上限。
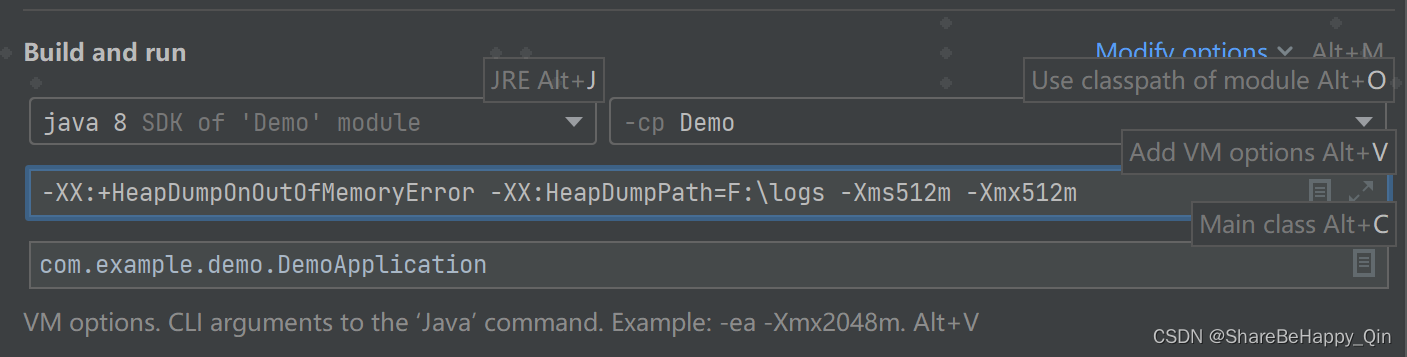
经过上述配置,当发生内存溢出时,会生成对应的快照文件,如下:

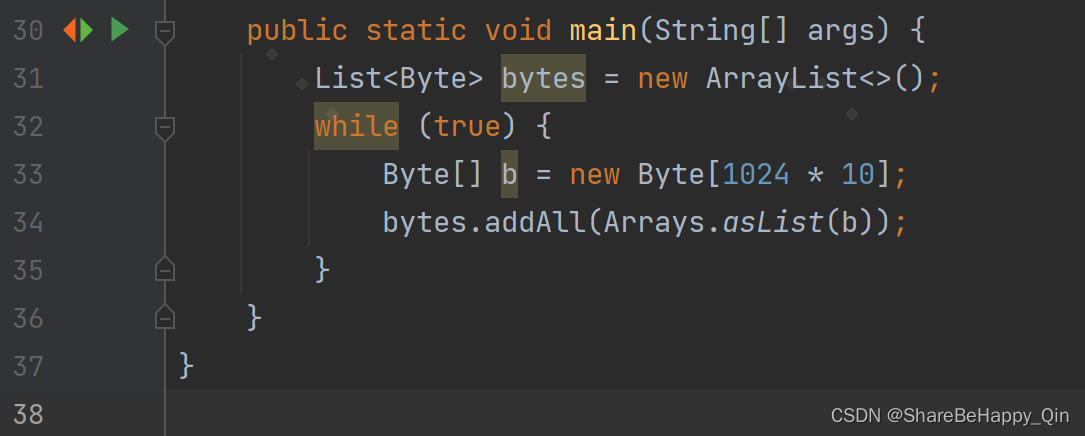
发生内存溢出的代码
public static void main(String[] args) {List<Byte> bytes = new ArrayList<>();while (true) {Byte[] b = new Byte[1024 * 10];bytes.addAll(Arrays.asList(b));}}
二、JProfiler 工具打开 .hprof 文件分析
1、打开.hprof 文件
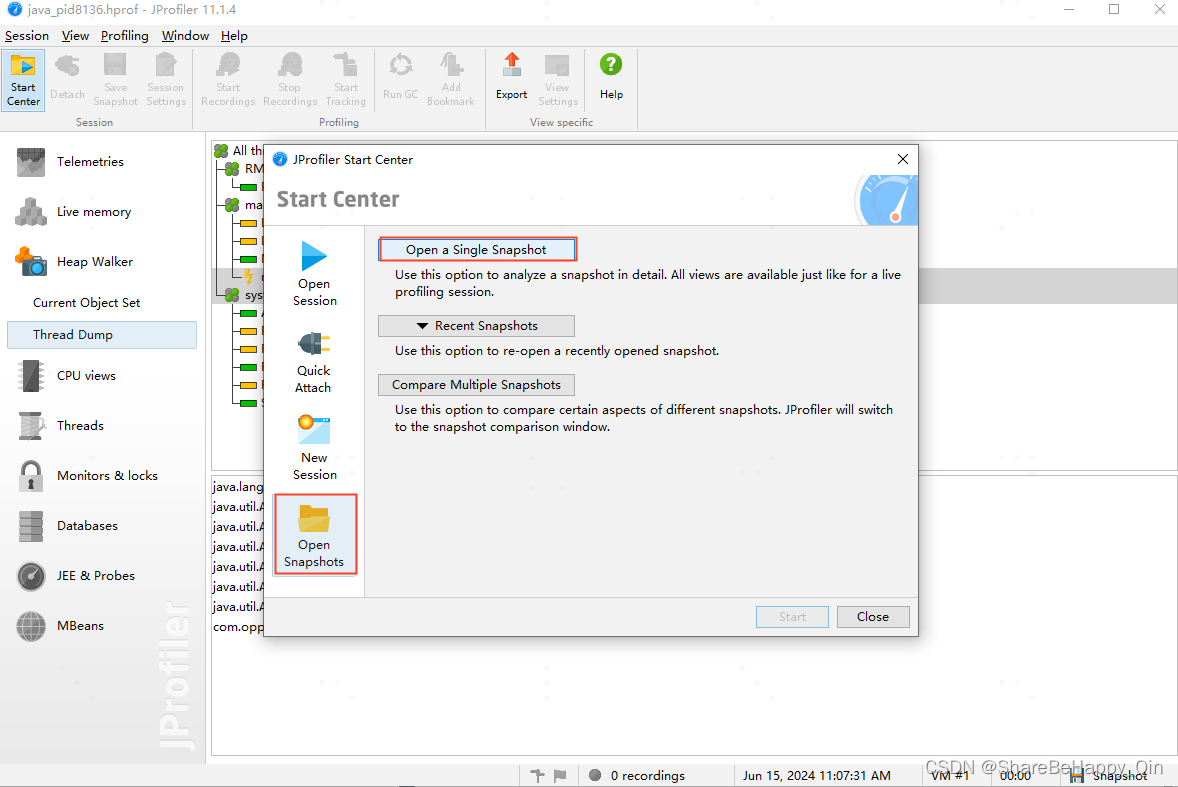
2、Classes(类)选项页面
打开后显示界面如下。在 Heap Walker(堆遍历器)— Current Object Set(当前对象集)— Classes(类)选项下,展示所有类,默认按照类生成实例的数量排序。
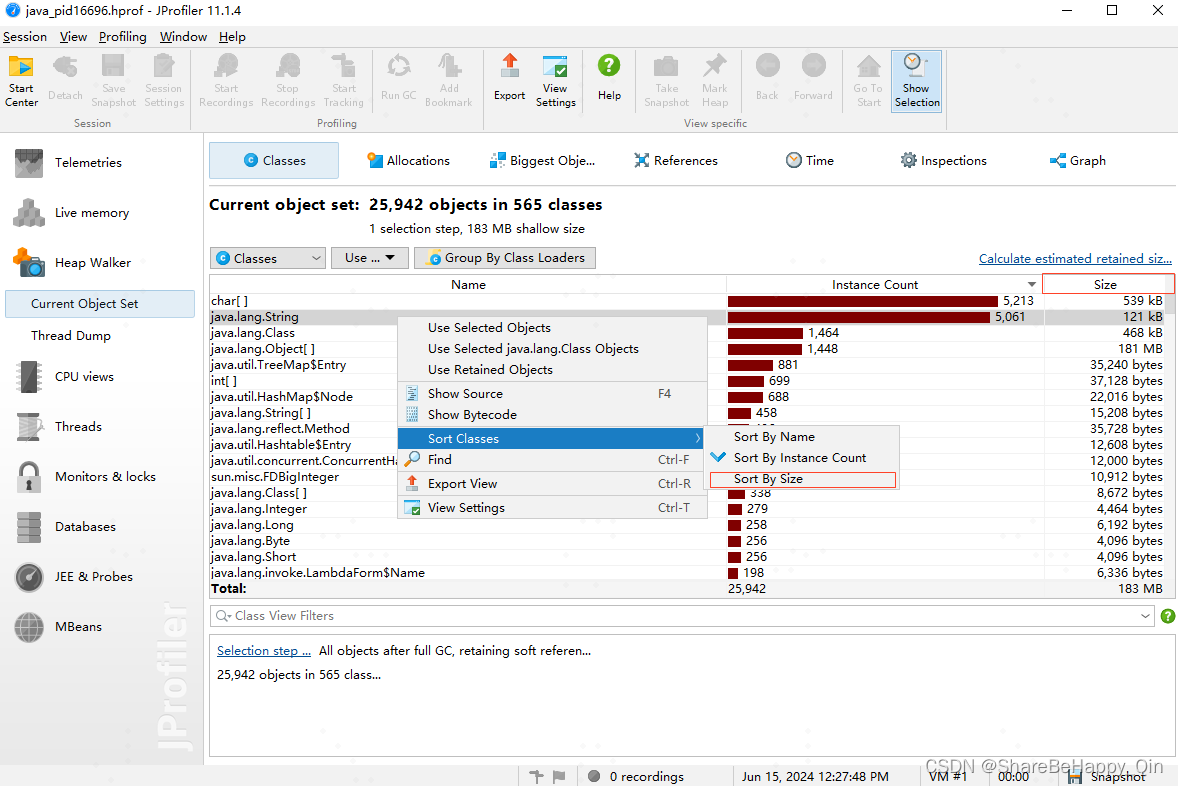
由于分析内存溢出,这里按照占用内存大小进行排序。
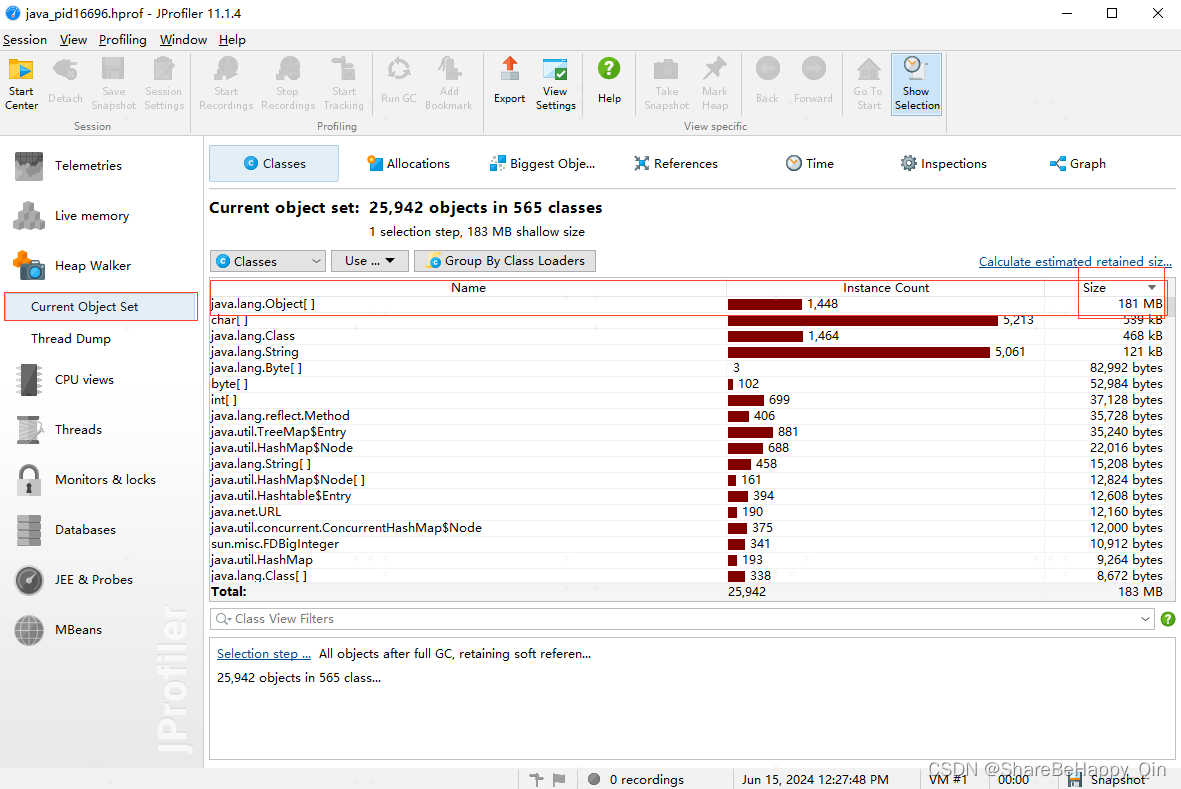
通过内存大小排序后,可以看到占用最大内存的类,其占据了大部分内存 181MB,可以大致定位是这个类的对象实例大量产生导致内存溢出,接着往下查找。选中这个类,点击右键 — Use Selected Instances — 选中(incoming references)— 确定,可以得到这个类的所有对象实例的引用关系,如下图:
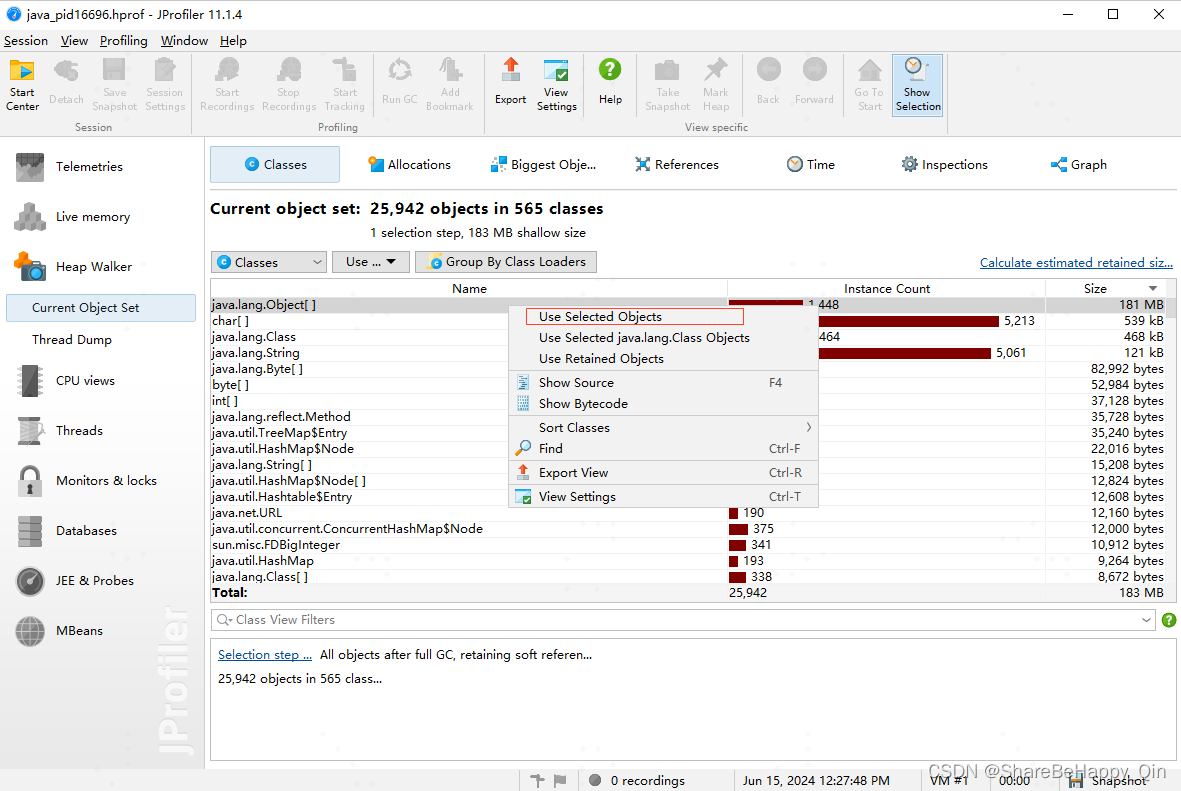
可以看到这个类的所有实例大小,第一个实例对象占据大部分内存,可能是因为这个对象实例导致的内存溢出,展开栈内引用链,查看有哪些地方使用了这个对象,从而定位到有问题的调用地方。
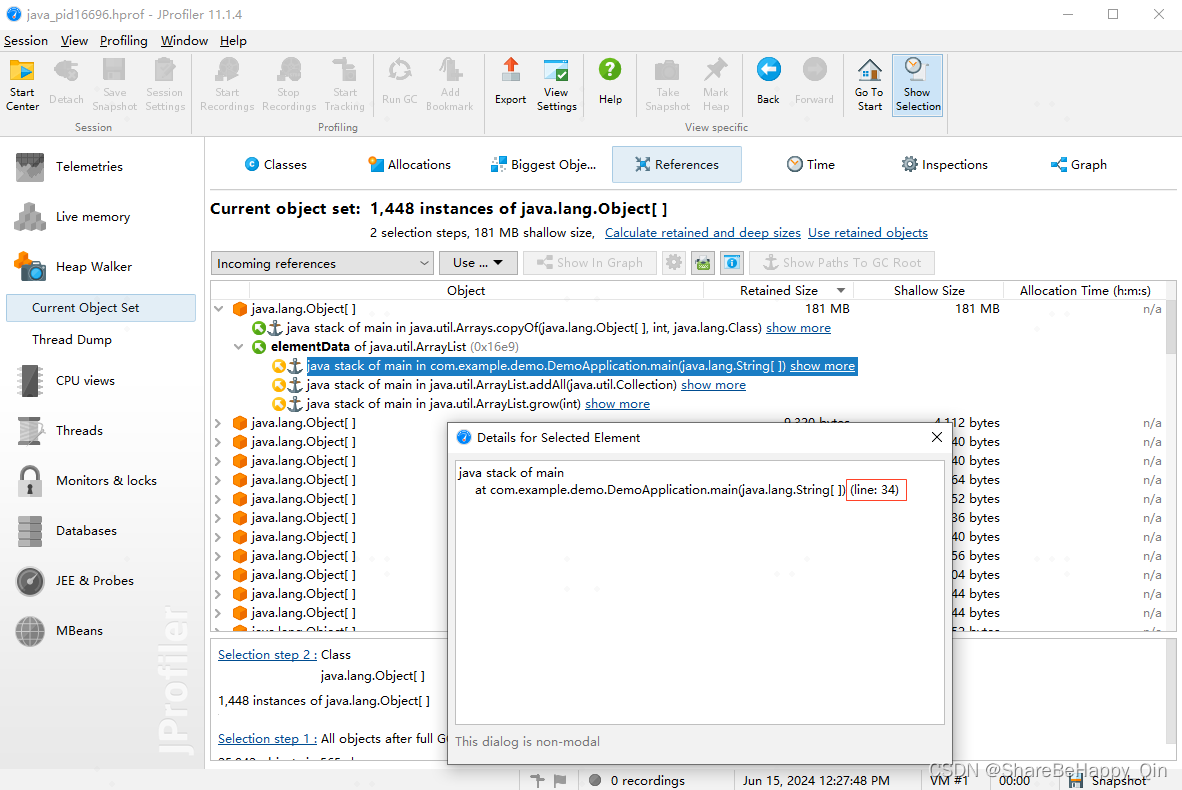
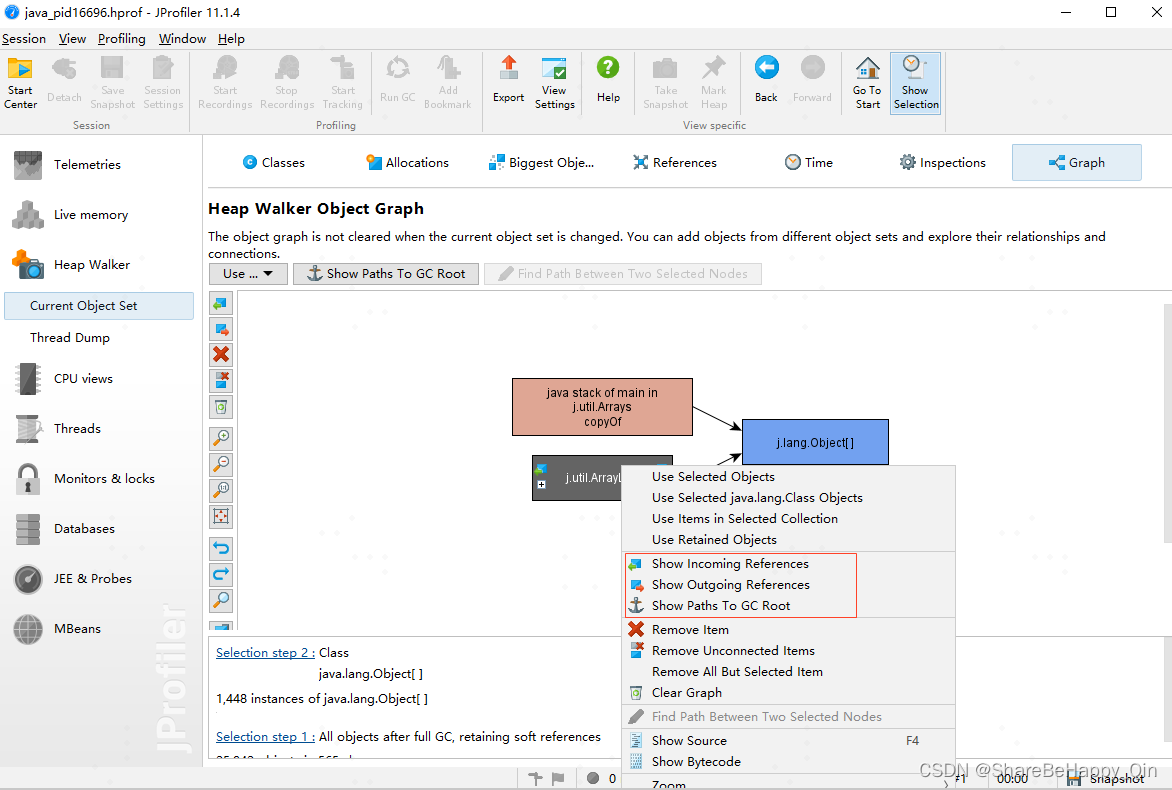
若引用这个对象的地方太多,上面看着不方便,可以通过调用示图查看。选中这个对象,点击右键 — Show In Graph,进入调用关系图,如下图:
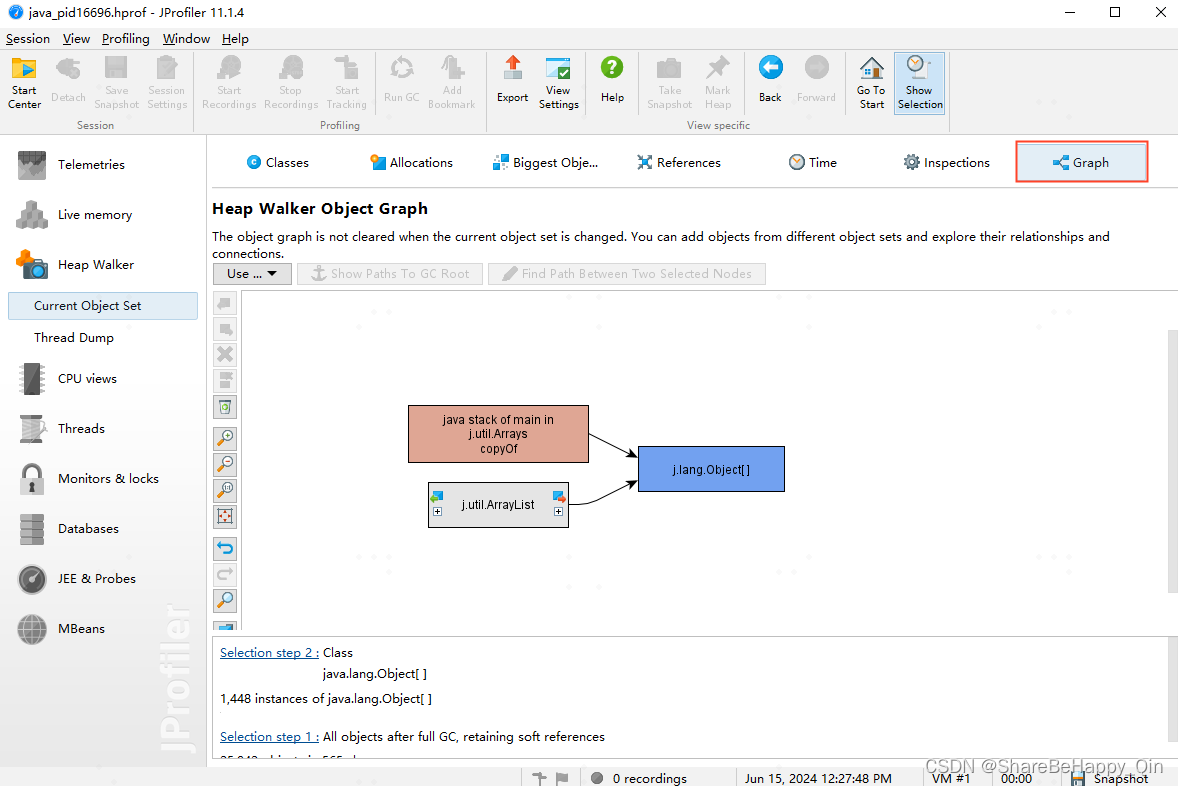
选中某个模块对象,点击右键,基于红框中的三个选项继续寻找调用或被调用的对象图。
- Show Incoming References:拓展调用者图谱
- Show Outgoing References:拓展被调用者图谱
- Show Paths To GC Root:沿着GC Root路径拓展调用者图谱
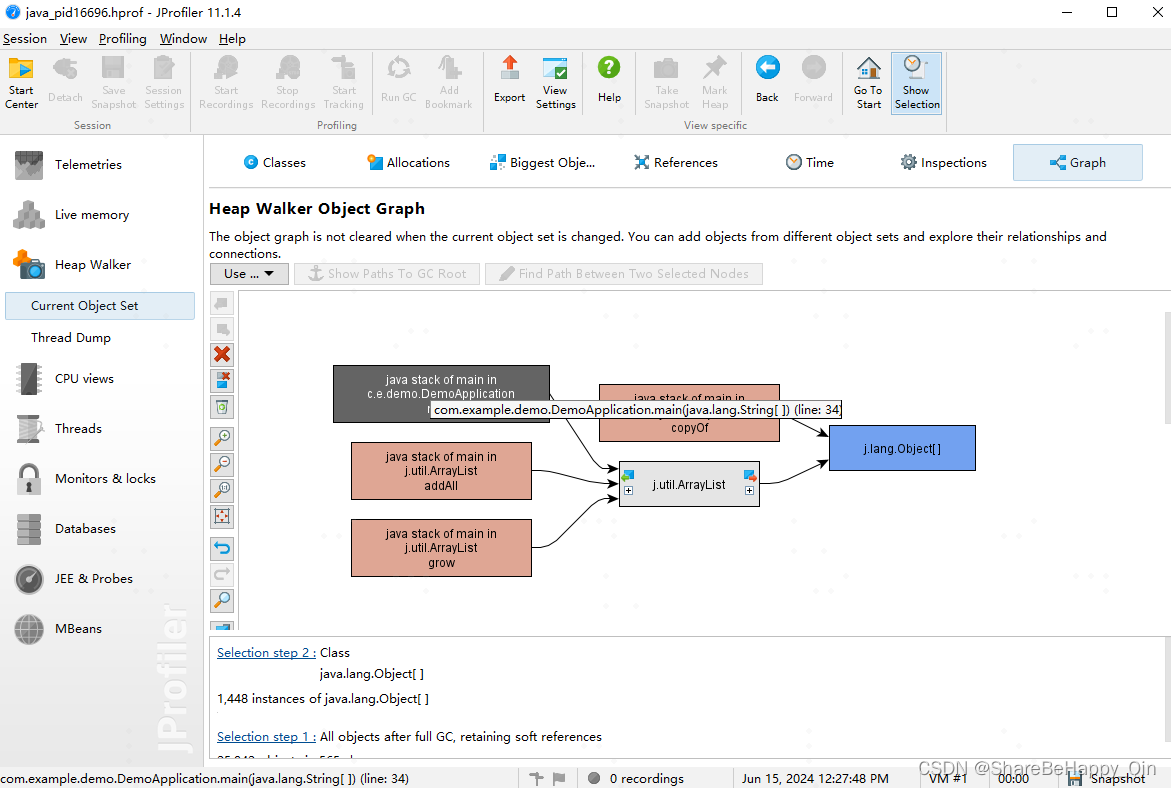
同样也可以定位到有问题的代码。
这篇关于JProfiler 性能分析案列——dump.hprof 堆内存快照文件分析排查内存溢出的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





