本文主要是介绍动态功能连接评估方法的变异性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
背景:动态功能连接(dFC)已成为理解大脑功能的一种重要测量指标。虽然已经开发了各种各样的方法来评估dFC,但目前尚不清楚方法的选择会如何影响结果。在这里,本研究旨在考察常用dFC方法的结果变异性。
方法:本研究在Python中实施了7种dFC评估方法,并使用它们对来自人类连接组计划的395名被试的功能磁共振成像数据进行分析。本研究使用了多种指标来量化不同方法产生的dFC结果之间的相似性,包括总体、时间、空间和被试间的相似性。
结果:研究结果显示,不同方法的结果之间存在强弱不等的相似性,这表明方法之间具有相当大的总体变异性。令人惊讶的是,dFC估计中观察到的变化与预期的功能连接随时间的变化相当,强调了方法选择对最终结果的影响。本研究结果揭示了3组不同的方法具有显著的组间差异,每组都具有不同的假设和优势。
结论:本研究结果揭示了dFC评估分析灵活性对结果的影响,并强调了采用多元分析方法和谨慎选择方法的必要性,以捕获dFC的全部变化。此外,还强调了区分神经驱动的dFC变化与生理混淆的重要性,并在已知真值下开发验证框架。为此,本研究提供了一个开源的Python工具箱(即PydFC),旨在促进多元分析dFC评估,以提高dFC研究的可靠性和可解释性。
引言
功能连接(FC)已成为理解大脑功能的重要指标,也是一种具有巨大潜力的生物标志物。FC通常功能磁共振成像(fMRI)中的血氧水平依赖(BOLD)信号来评估。FC评估最初是在假设其不随时间变化(平稳性)的前提下进行的。然而,越来越多的证据表明,FC的动态变化(dFC)在大脑功能组织中发挥着关键作用,并可能提供健康和疾病状态下神经动力学与认知之间的联系。dFC的重要性并不局限于理解大脑区域之间的相互作用。最近的研究表明,dFC模式可以揭示健康和患病个体之间的差异,因此可以用作临床生物标志物。在这方面,一些研究报道了多种神经或精神疾病条件下dFC模式的改变,包括自闭症谱系障碍(ASD)、注意缺陷/多动症(ADHD)、抑郁症、创伤后应激障碍(PTSD)、精神分裂症(SZ)、帕金森病(PD)和阿尔茨海默病(AD)。
近年来,已开发了多种评估dFC的方法。随着现有方法的数量不断增加,有必要全面审查这些方法并检查它们的相对优缺点,并对它们在实验数据中的应用提出建议。到目前为止,已有一些研究回顾了这些方法的不同方面,并强调了理解其局限性和基本假设的重要性。然而,只有少数研究在实际应用中比较了不同的方法,并且没有对常用dFC评估方法产生的结果进行全面比较。
大多数dFC研究并未明确说明采用特定方法评估dFC的理由。例如,在临床应用中,一些研究采用了滑动窗口和聚类方法(例如PTSD,PD,SZ),而另一些则更倾向于使用隐马尔可夫模型(HMM)方法(例如SZ,PTSD,轻度认知障碍[MCI])或者时频方法(例如ASD,SZ)。值得注意的是,很少有研究使用多种方法(例如慢性头痛,意识障碍[DOCs])。同样,在认知和行为应用中,一些研究使用滑动窗口和聚类方法(例如任务预测,认知和行为灵活性),另一些研究则使用了共激活模式(CAP)分析(例如自然刺激,多任务)和HMM(例如睡眠阶段,冲动行为),而很少有研究使用多种方法(例如工作记忆任务)。令人惊讶的是,在本文回顾的62项dFC研究中,只有4项研究考虑了一种以上的方法来评估其结果的稳健性。因评估方法的选择而引起的dFC评估结果的变异性尚未得到充分研究,这可能会影响对dFC的准确理解和应用。
本研究通过考察从相同数据集估计的dFC模式在多种方法中的变化,来评估dFC估计的分析灵活性。在现有的dFC评估方法中,本研究选择了7种广泛使用的方法:共激活模式(CAP)、聚类方法、连续隐马尔可夫模型(CHMM)、离散HMM、滑动窗口法、时频(基于小波)方法和无窗法。表1列出了这7种方法及其引用次数、出版年份和假设。有关每种方法使用的详细管道及其重要超参数如图1所示。
表1.7种dFC评估方法及其引用次数、首次发表年份和假设。
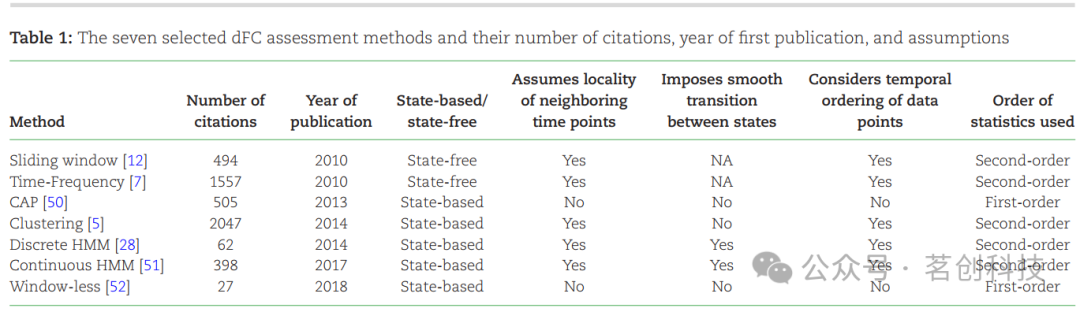
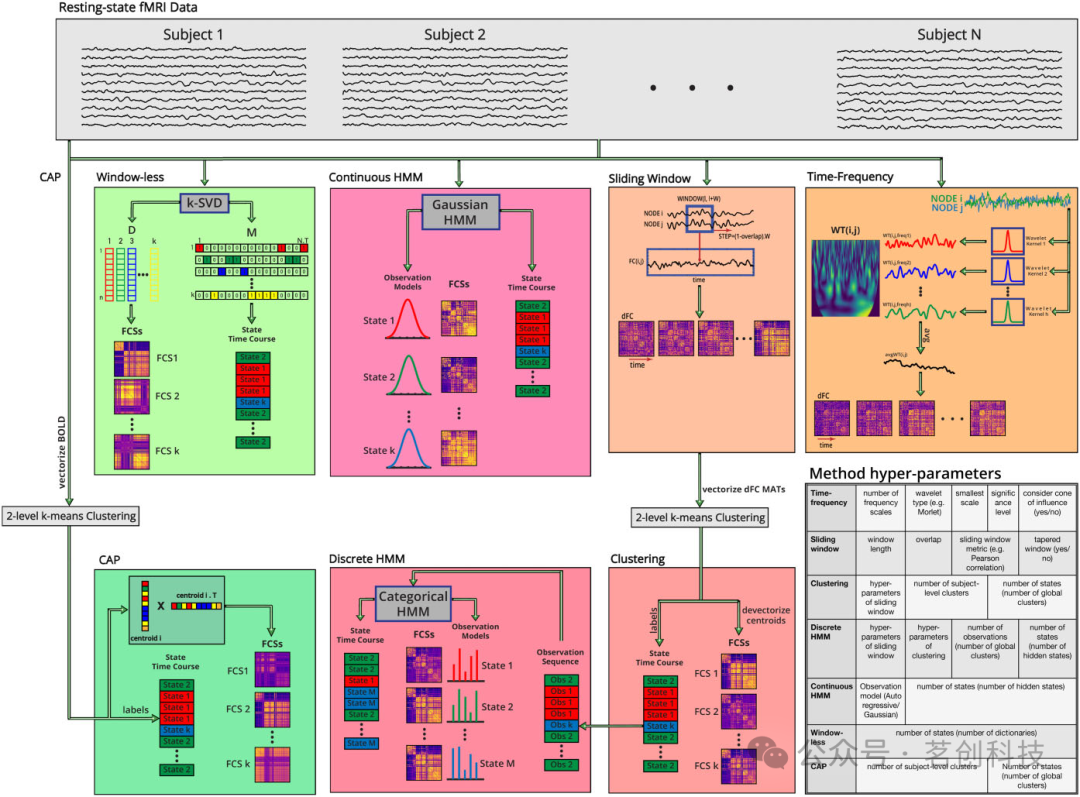
图1.7种dFC评估方法(时频、滑动窗口、聚类、离散隐马尔可夫模型[DHMM]、连续HMM、无窗口、共激活模式[CAP])的管道。
由于多种因素,比较不同的dFC评估方法存在一定的挑战。主要的挑战来自各种方法的基本假设和数学框架的差异,以及缺乏明确的基本事实来衡量结果的准确性。为此,本研究开发了一个适用于基于状态和无状态方法的综合比较框架。该框架根据空间、时间和整体相似性来比较方法。然后,使用来自人类连接组计划(HCP)数据集中395名被试的静息态fMRI数据来评估dFC。
方法和材料
数据
本研究使用了来自3T HCP数据集S1200版的395名年轻健康被试(年龄范围:22-36岁)的静息态fMRI BOLD时间序列,按照Alba等人(2021)中描述的方法进行预处理。每位被试在两天内进行了4个session的扫描。每天扫描两次,每次扫描15分钟,一次采用从左到右(LR)相位编码方向进行采集,另一次采用从右到左(RL)进行采集。在本研究中,除了整体相似性矩阵(使用了所有4个session的数据)之外,所有其他主要结果都使用了来自第一个session的Rest1_LR数据。
每次扫描包含1200个时间点,重复时间TR=0.720s。其他fMRI采集参数如下:梯度回波EPI;回波时间TE=33.1ms;翻转角FA=52°;视野FOV=208×180mm(RO×PE);矩阵=104×90(RO×PE);层厚=2.0mm;72层;2.0mm各向同性体素;多波段因子=8;回波间隔ES=0.58ms;带宽BW=2290Hz/Px。本研究使用了HCP FIX去噪数据,其中包括额外的去噪步骤(即去趋势、头动校正和独立成分分析(ICA))。此外,对下载的FIX去噪体积数据进行最小空间平滑处理,半高全宽(FWHM)为4mm。
然后,基于Gordon图谱将数据分成333个感兴趣区域(ROIs),每个ROI都属于一个特定的静息态网络(RSN)。在这333个ROIs中,有47个不属于任何脑网络,因此被排除在外,最终得到286个ROIs。此外,对分区数据进行高通滤波,截止频率为0.01Hz。出于计算原因,本研究将这286个ROIs均匀地下采样为96个ROIs。这个下采样过程涉及从每个RSN中选择大约三分之一的ROIs,以确保均匀覆盖该特定RSN区域,并且每个半球的ROIs数量相等。在分析之前对每个ROI时间序列进行z标准化处理。
无状态方法
这些方法是无模型的,因此在进行dFC评估之前无需在组水平上实施。相反,它们被分别应用于每个被试。无状态方法及其dFC矩阵的说明见图1。
滑动窗口(SW)
使用长度为44s(或60个时间点)、重叠率为50%的滑动锥形窗口来计算ROI对随时间变化的功能连接(FC)。通过将长度为44s的矩形与σ=3个TR的高斯曲线进行卷积来生成锥形窗口,然后沿1200个时间点移动,其中有30个时间点重叠。这个过程产生了38个窗口,因此得到了一个38×ROI×ROI的dFC矩阵。该方法的超参数主要包括窗长、重叠率和锥形或矩形窗口。这些超参数的值按照Allen等人(2014)的研究进行选择。
时频(TF)
通过在每个ROI时间序列上应用k=101个小波核进行小波变换,从而产生具有k个频率尺度的小波时间序列。然后,计算每个ROI对在每个频率尺度下的时间序列之间的小波变换相干性(WTC),并在所有频率尺度上进行平均。由此产生的成对WTC时间序列形成了相应形状为1200×ROI×ROI的dFC矩阵。注意,根据Chang等人(2010)的研究,最终的dFC矩阵只考虑影响锥外的WTC值。该方法的超参数包括频率尺度的数量、小波类型、相干幅值显著性水平,以及是否考虑影响锥。根据Chang等人(2010)的研究,在101个频率尺度上进行Morlet小波变换。显著性水平设定为0.95,只考虑影响锥外的WTC指数。
基于状态的方法
由于基于状态的方法假设有限数量的FC状态会随时间和所有被试重复出现,因此首先需要在组水平上应用以识别组水平的FC状态。每个状态由形状为ROI×ROI的状态FC矩阵表示,该矩阵对应于状态发生时的时间点的FC模式。然后,将拟合的模型应用于每个个体被试,从而得到个体的dFC矩阵。将拟合模型应用于个体水平的数据会将每个时间点分配给组水平的FC状态之一,从而产生一个状态时间序列。接下来,将每个状态的状态FC矩阵分配给属于该状态的时间点上,以构建该被试的dFC矩阵。目前关于大脑状态的数量尚无共识。在本研究中,为了使结果更具可比性,假定所有基于状态的方法的FC状态数量为12(参照Vidaurre等人(2017)的研究)。有关基于状态的方法及其状态FC矩阵和状态时间序列的示意图如图1所示。
共激活模式(CAP)
CAP方法是一种点过程分析方法,具有单个时间点的时间分辨率和较少的假设。原始CAP方法在种子区域内使用激活阈值,并在显著时间点对BOLD时间序列进行平均。原始方法不直接产生dFC矩阵。CAP分析的扩展版本直接将k均值聚类应用于BOLD时间序列。在本研究中,出于计算原因,聚类分为两个阶段。首先,对每个被试的时间点进行聚类,以找到被试水平的聚类质心。然后,对所有质心进行聚类。最后,根据Maltbie等人(2022)所提出的实现方法,计算质心的ROI×ROI外积矩阵,得到状态FC矩阵。将时间点的聚类标签视为状态时间过程。最终的dFC矩阵形状为1200×ROI×ROI。该方法的超参数为被试水平聚类数和FC状态数。基于Ou等人(2015)的研究将被试水平聚类数目设置为20。
滑动窗口+聚类(SWC)
该方法依赖于使用滑动窗口法评估的dFC矩阵。因此,首先使用上述的滑动窗口法对dFC矩阵进行评估,其形状为38×ROI×ROI。其次,将dFC矩阵的每个时间点视为一个样本,并将其向量化为一个长度为ROI×(ROI−1)/2的特征向量。然后,使用类似于CAP方法的二分k均值聚类过程,将特征向量聚类为对应于12个FC状态的12个簇。然后将各状态的质心向量重构为ROI×ROI的原始形状,得到各状态的FC矩阵,将得到的聚类标签序列视为状态时间序列。最终的dFC矩阵形状为38×ROI×ROI。该方法的超参数除了滑动窗口法的超参数外,还包括被试水平聚类数和FC状态数。滑动窗口超参数的取值与滑动窗口法相同,并且将被试水平聚类数目设置为20,与CAP方法一致。
连续隐马尔可夫模型(CHMM)
该方法使用了连续隐马尔可夫模型(连续HMM或CHMM),其观测模型为高斯模型。直接将静息态fMRI数据中的BOLD时间序列作为HMM的连续观测序列。随后,识别出12个隐藏状态,每个状态对应一个FC状态。每个隐藏状态用多元高斯模型表示。通过对所有被试的BOLD时间序列进行拟合,推导出每个隐藏状态的均值和协方差。然后,将拟合好的模型应用于被试水平数据,推断出每个被试的隐藏状态序列,然后将推断出的序列作为状态时间序列,将每个隐藏状态的协方差矩阵视为对应的状态FC矩阵。最终的dFC矩阵形状为1200×ROI×ROI。该方法的唯一超参数是观测模型类型(例如,高斯或自回归)和FC状态数。选择高斯模型作为观测模型(Vidaurre等人(2017))。
离散隐马尔可夫模型(DHMM)
该方法使用离散隐马尔可夫模型(离散HMM或DHMM),其观测模型为分类模型。由于该方法是基于聚类方法的结果,因此本研究使用聚类方法初步评估了dFC矩阵,其形状为38×ROI ROI。初始聚类分析假设的FC状态数等于离散HMM方法假设的观测数,而不是最终的FC状态数。此外,这里使用的DHMM需要一个离散的观测序列。因此,将通过聚类方法得到的状态时间序列作为离散HMM的离散观测序列。然后对观测序列进行HMM拟合,识别出与12个FC状态相对应的12个隐藏状态,将得到的隐藏状态序列作为状态时间序列,通过对聚类方法得到的dFC矩阵中分配给该FC状态的所有FC矩阵进行平均,得到每个FC状态的FC矩阵。最终的dFC矩阵形状为38×ROI×ROI。该方法的超参数包括聚类方法的超参数、观测模型中假设的观测数和FC状态数。对于聚类方法的超参数,选择与聚类方法相同的值,观测数与FC状态数之比采用Ou等人(2015)的研究中的16/24。
无窗法(WL)
该方法依赖于估计所有BOLD时间序列值在样本空间中的主导线性模式。每个主导线性模式对应于一个FC状态。为了估计主导线性模式,将稀疏字典学习算法——k-SVD算法应用于组水平数据。主导线性模式由一个字典元素表示。将对应12个FC状态的12个字典元素存储在字典矩阵D中,每个时间点由这些字典元素的线性组合近似。每个时间点的线性组合系数存储在混合矩阵M的行中。对该算法施加一个硬稀疏约束,使得每个时间点只分配一个字典,这表明M行是稀疏的。通过计算D列中字典元素的外积矩阵得到状态FC矩阵,使用混合矩阵M计算状态时间序列,最终的dFC矩阵形状为1200×ROI×ROI。该方法的唯一超参数是FC状态数。
分析灵活性评估
本研究使用Python实现了所有7种方法,并对395个预处理过的fMRI被试数据进行dFC矩阵估计,总共得到了2765个dFC矩阵。图2是使用单个被试的BOLD数据,通过不同的方法得到的具有代表性的dFC矩阵。为了确保数据之间具有可比性,当基于滑动窗口法(SW、SWC和DHMM)对时间样本进行下采样时,对其他方法的dFC矩阵也进行均匀下采样,以匹配基于滑动窗口法的分辨率。将每种方法的输出转换为38×96×96的dFC矩阵的通用格式,为每个被试生成7个相同大小的dFC矩阵。由此得到一个dFC数组,其维度为(被试,方法,时间,ROI,ROI)∈(395,7,38,96,96)。通过将形状ROI×ROI的二维FC矩阵的下三角向量化为functionalConnection×1,在某些情况下,dFC数组也被重塑为(被试,方法,时间,功能连接)∈(395,7,38,4560)。为了评估不同方法下dFC结果的分析灵活性,本研究使用几种相似性指标计算了7×(7−1)/2的成对相似性,包括Spearman相关、Pearson相关、欧氏距离和互信息。本研究评估了每对方法之间的相似性,包括它们的dFC矩阵相关性、功能连接的时间序列、每个时间点的FC模式以及度和聚类系数等图属性。这些相似性指标的计算公式如下:

此外,本研究比较了不同方法的被试间相似性:

为了识别产生相似结果的方法组,本研究使用Ward方法进行层次聚类来分析使用上述指标(Spearman相关、Pearson相关、欧氏距离和互信息)计算的相似值。对于基于相关性的指标,使用1-相关性作为方法之间的距离。层次聚类使我们能够概括测量的相似性矩阵,并且将具有较高相似性的方法分组在一起。
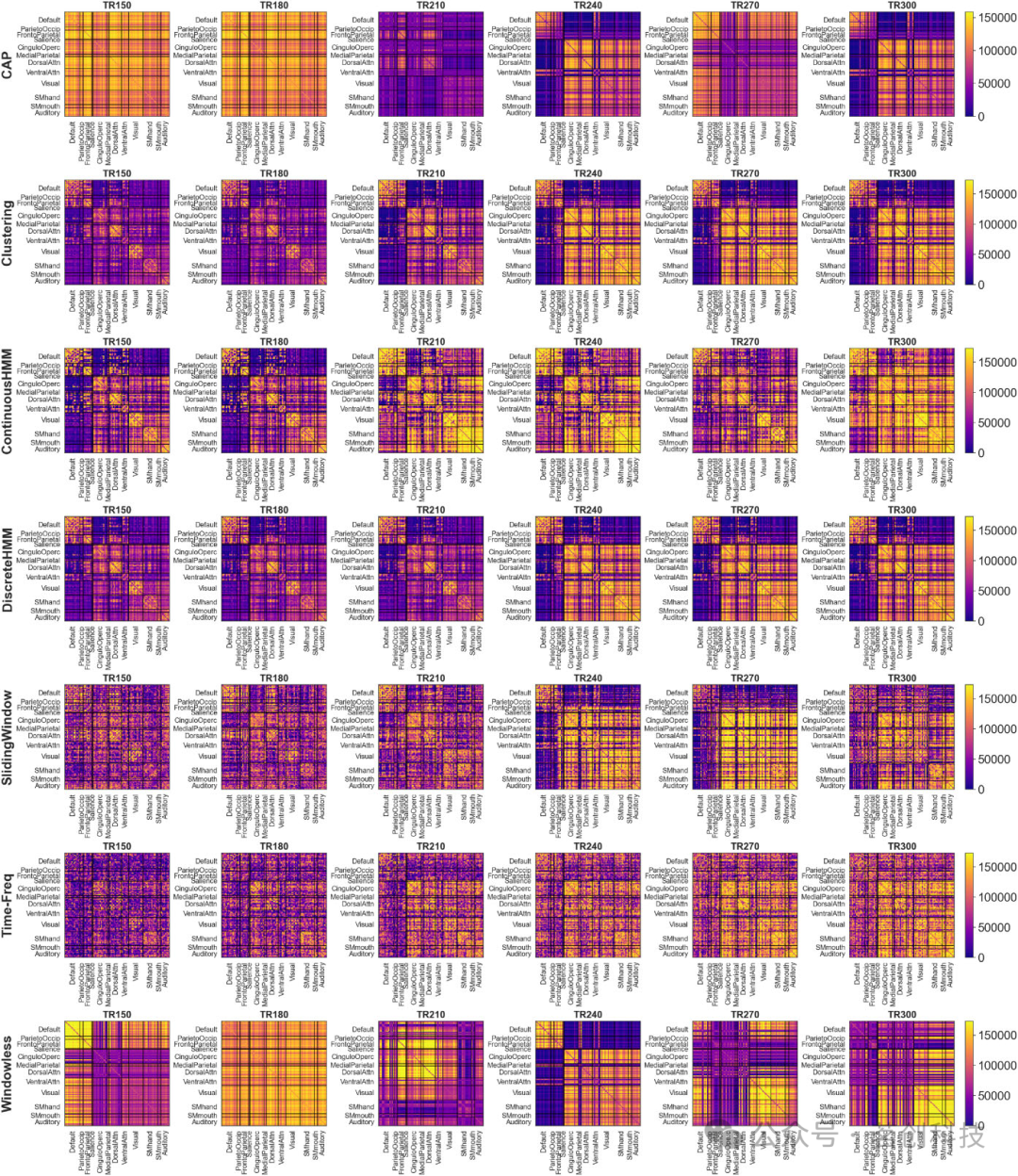
图2.单个被试的dFC矩阵。
结果
根据评估结果的相似性,DFC评估方法可分为3类
图3A显示了使用Spearman相关计算的dFC矩阵的整体相似性(每种方法获得的dFC矩阵示例见图2)。相关系数值显示了dFC方法之间从弱到强的相似性范围。所有被试对的平均Spearman相似性为0.38,属于中度相似。然而,相应的标准差较高(0.18;方差:0.032),约为平均相似性值的一半。这种变异性也显著高于被试对相似性的平均方差(SD:0.076,方差:0.0058)。换句话说,方法对的dFC相似性变异性比被试间高5倍。
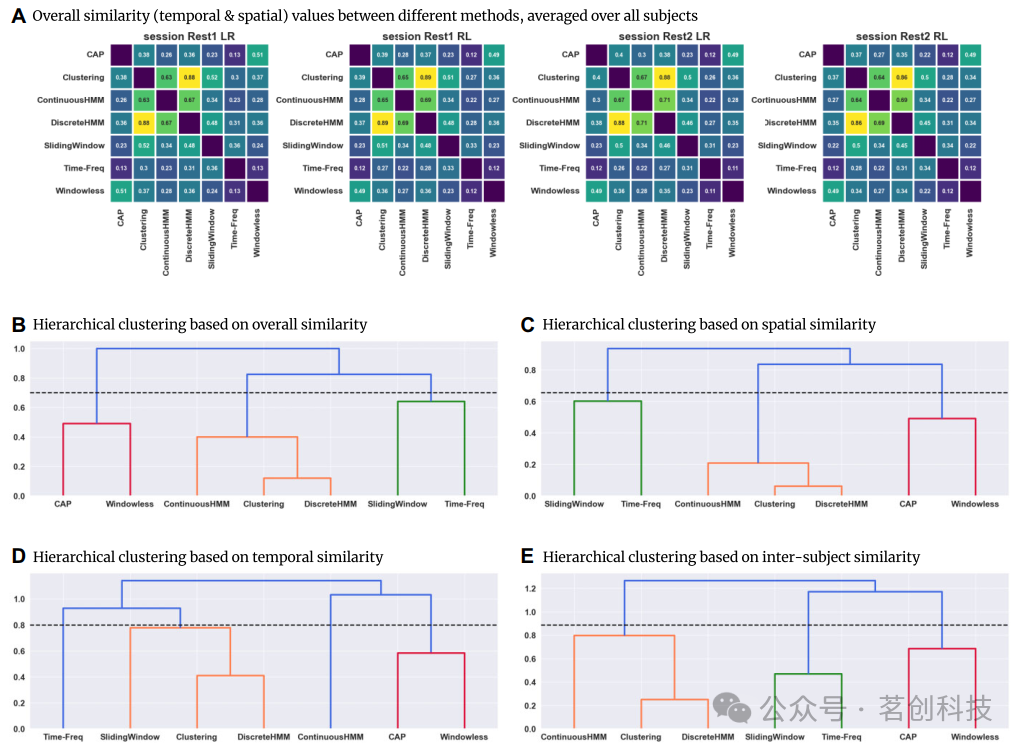
图3.采用Spearman相关评估7种方法的dFC模式相似性。
dFC空间模式的相似性遵循整体相似性模式
使用每个被试在每个时间点对应的空间模式(FC矩阵)之间的Spearman相关来估计从不同方法获得的dFC矩阵之间的空间相似性(见公式2)。然后对产生的空间相似性在时间和被试上取平均值。平均空间相似性矩阵的层次聚类分析(图3C)显示出与平均整体相似性相同的层次结构。聚类分析发现了相同的三个组,表明它们的空间相似性遵循相同的组内和组间模式。
与空间相似性相比,不同方法dFC的时间相似性较低
利用每个功能连接方法获得的时间序列之间的Spearman相关性(见公式3)来评估每对方法dFC矩阵之间的时间相似性。然后将得到的时间相似性矩阵在功能连接(ROI×ROI)和被试上进行平均。虽然两种方法可能会产生具有相似空间模式的dFC矩阵,但相应的时间模式可能不同。其中,空间相似性侧重于功能连接在某一时刻的空间模式和空间值,而时间相似性则侧重于各功能连接的dFC时间演变的一致性。基于被试时间相似性矩阵的平均层次聚类(图3D)显示,与空间(和整体)相似性相比,方法之间的相似性整体下降。对于CHMM和TF与组内其他方法之间的相似性来说,这一点尤其明显,与相应的空间相似性相比,它们产生的时间相似性要低得多。这表明,尽管CHMM和TF显示出与其组中其他方法相似的空间模式,但它们的时间动态却并不完全相似。
被试间相似性反映了先前观察到的整体相似性模式
为了评估方法之间的被试间相似性,使用每种方法估计的dFC矩阵来测量被试间的相关性(395×(395−1)/2值)(见公式4)。然后比较每种方法获得的被试间数值,并使用Spearman相关来测量方法之间的相似性(见公式5)。由此得到的相关性值(图3E)表明了不同方法之间的被试间相关性。这意味着,如果一种方法根据其dFC模式将两个被试识别为相似,则同一组的另一种方法也可能将两个被试识别为相似。这一发现表明,组合在一起的方法不仅在捕获被试水平模式方面表现出相似性,而且在捕获被试间模式方面也表现出一致性。
大多数功能连接的方法变异性与时间变异性相当。
对于每个功能连接,计算dFC(被试,方法,时间,功能连接)随时间和方法的变化,以及不同功能连接和被试间的差异。考虑到每种方法的值分布不同,通过值排序对每个被试的dFC矩阵(被试n,方法i,时间,功能连接)进行归一化,类似于计算Spearman相关时使用的方法。本研究计算了随时间变化的方差var(dFC(被试,方法,:,功能连接)),以及方法的方差var(dFC(被试,:,时间,功能连接))。因此,两种计算都产生了一个被试×功能连接值的数组(每个功能连接和每个被试都有1个“时间方差”和1个“方法方差”值)。结果如图4A所示,对于大多数功能连接和被试而言,dFC的方法方差与时间方差相当,即varmethod/vartime的平均比率=0.95,或SDmethod/SDtime平均比率=0.97。此外,图4B突出显示了一对具有功能连接的RSNs,其方法方差高于时间方差。这些功能连接主要包括默认模式与其他网络之间的连接,如顶枕网络、额顶网络、突显网络、扣带-鳃盖网络、内侧-顶叶网络、背侧注意网络和腹侧注意网络,以及除扣带-鳃盖网络外的大部分网络内连接。
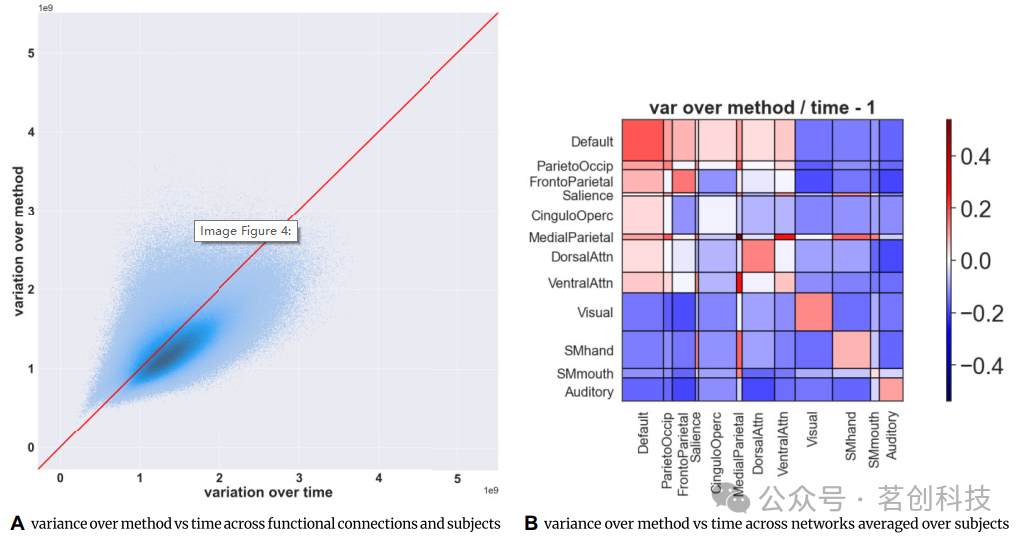
图4.(A)每个功能连接和每个被试的方法方差与时间方差的散点图。(B)在所有被试的功能连接水平上,方法方差与时间方差的比值。
结论
总的来说,本研究旨在评估dFC测量方法的分析灵活性,并建立分析灵活性与生物变异性的比较。比较结果显示,不同方法之间具有广泛的相似性模式。结果中发现的变异性突出了仔细激励和验证特定dFC评估方法选择的重要性。使用多种方法可以缓解分析灵活性所带来的问题,并更好地表征dFC测量的丰富性。未来的工作应致力于开发一个验证框架,并通过外部验证技术来评估dFC评估的准确性。
参考文献:Mohammad Torabi, Georgios D Mitsis, Jean-Baptiste Poline, On the variability of dynamic functional connectivity assessment methods, GigaScience, Volume 13, 2024, giae009, https://doi.org/10.1093/gigascience/giae009
小伙伴们关注茗创科技,将第一时间收到精彩内容推送哦~
这篇关于动态功能连接评估方法的变异性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





