变异性专题

变异性:Covariance与Contravariance在C#中的运用艺术
变异性:Covariance与Contravariance在C#中的运用艺术 摘要 在C#编程中,Covariance(协变)和Contravariance(逆变)是两种重要的类型系统特性,它们允许我们更灵活地使用泛型和委托。本文将深入探讨Covariance和Contravariance的概念、它们在C#中的实现以及如何利用这两种特性来提高代码的灵活性和可维护性。 1. 引言 Covar
动态功能连接评估方法的变异性
摘要 背景:动态功能连接(dFC)已成为理解大脑功能的一种重要测量指标。虽然已经开发了各种各样的方法来评估dFC,但目前尚不清楚方法的选择会如何影响结果。在这里,本研究旨在考察常用dFC方法的结果变异性。 方法:本研究在Python中实施了7种dFC评估方法,并使用它们对来自人类连接组计划的395名被试的功能磁共振成像数据进行分析。本研究使用了多种指标来量化不同方法产生的dFC结果之间的相似性

数据变异性的度量 - 极差、IQR、方差和标准偏差
来源:DeepHub IMBA本文约1200字,建议阅读5分钟可变性的最佳衡量标准取决于不同衡量标准和分布水平。 variability被称作变异性或者可变性,它描述了数据点彼此之间以及距分布中心的距离。 可变性有时也称为扩散或者分散。因为它告诉你点是倾向于聚集在中心周围还是更广泛地分散。 低变异性是理想的,因为这意味着可以根据样本数据更好地预测有关总体的信息。高可变性意味着值的一致性较低,
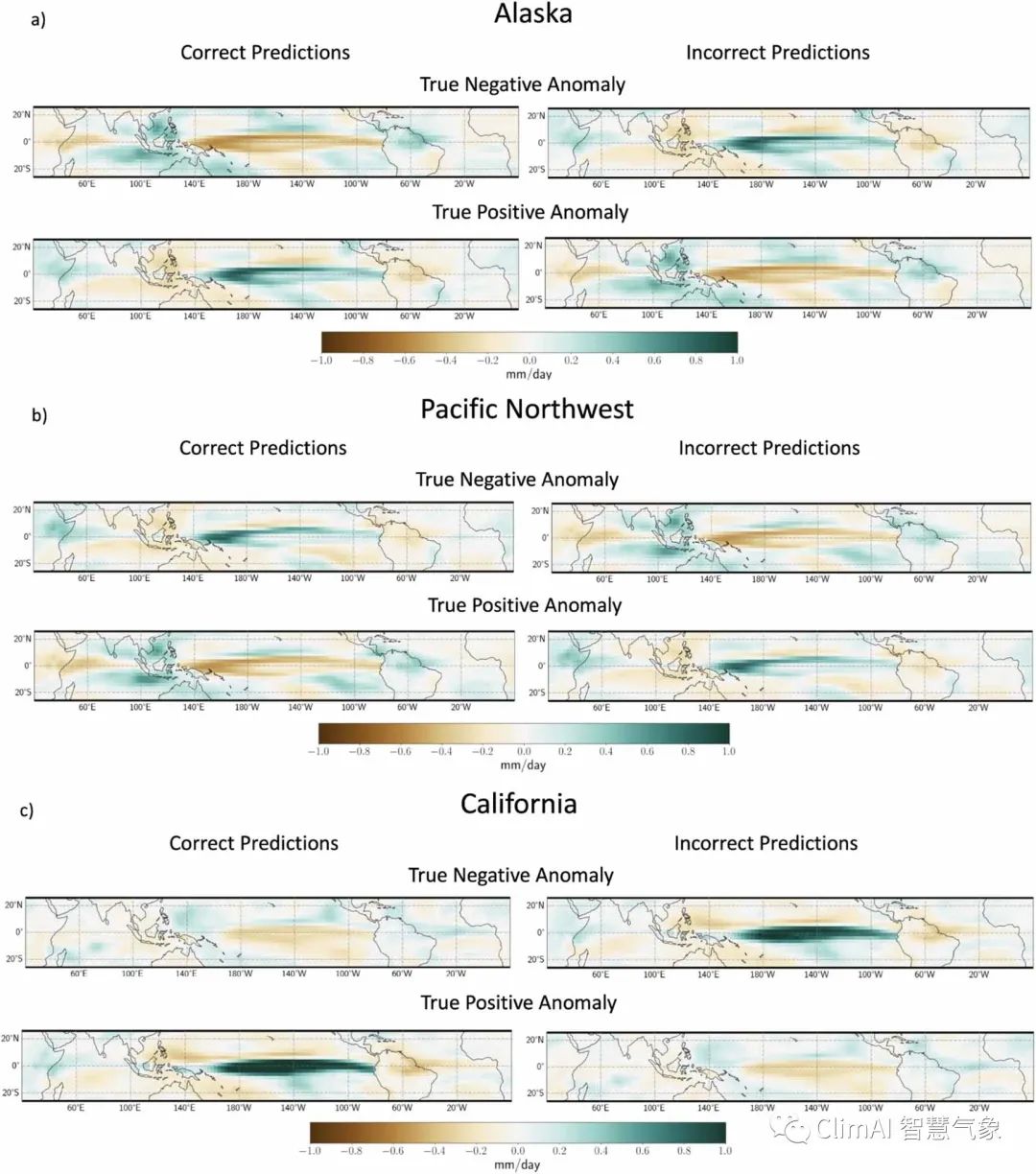
科罗拉多州立大学新突破:利用可解释人工智能评估次季节机会预测的年代际变异性
近日,科罗拉多州立大学联合劳伦斯利弗莫尔国家实验室的研究团队发布了一项开创性的研究《Assessing decadal variability of subseasonal forecasts of opportunity using explainable AI》。这项研究利用先进的可解释人工智能(XAI)技术,对次季节气候预测的年代际变化进行了深入探究。次季节时间尺度的气候预测介于常规天气预报

2020年第九届数学建模国际赛小美赛B题血氧饱和度的变异性解题全过程文档及程序
2020年第九届数学建模国际赛小美赛 B题 血氧饱和度的变异性 原题再现: 脉搏血氧饱和度是监测患者血氧饱和度的常规方法。在连续监测期间,我们希望能够使用模型描述血氧饱和度的模式。 我们有36名受试者的数据,每个受试者以1 Hz的频率连续测试血氧饱和度约1小时。我们还记录了参与者的以下信息,包括年龄、BMI、性别、吸烟史和/或当前吸烟状况,以及可能影响阅读的任何重要疾病。 我们想

《爱上统计学》笔记(二) 理解变异性
变异性(也叫散步或离散度)可被看作是对不同数值之间的差异性的测量。 如果把变异性看作是每个数值与特定值的差异程度可能更精确。那么你认为哪个“数值”可能被作为那个特定值呢?通常情况下这个特定值就是均值。因此,变异性成为测量数据组中每一个数值与均值的差异性的数量。 变异性的三种量数通常用于反映一组数据的变异性、散布或者离散度。这三种量数就是极差、标准差和方差。 我们最初正常的想法可能是计算数据
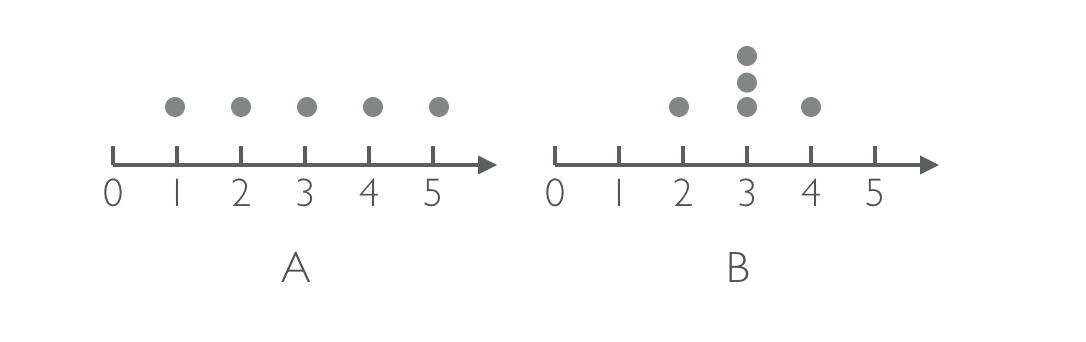
变异性的数值特征-方差
文章主要介绍通过样本方差来了解数据集变化的原理。 我们对两个数据集做观察,数据集A和数据集B: A: 1,2,3,4,5B: 2,3,3,3,4 对于定量数据集,最常用、也最容易理解的集中趋势测度是数据集的算数平均数。类比我们学生年代,经常谈论的班级平均分。那么,我们对数据集A、B做平均数计算: A: 3B: 3 两个样本集的均值都是3。接着,我们计算每个值与均值之间的差值,观察这些偏差数据
整理总结:深入浅出统计学——分散性和变异性的量度
参考资料:电子工业出版社的《深入浅出统计学》 前言 平均数能让我们知道数据集典型值——数据中心所在处,但若要给数据下具体的结论,则还是缺少足够的信息。通过分析各种距和差,来判断数据集离平均值的波动程度。 本篇目录 参考资料:电子工业出版社的《深入浅出统计学》前言具体内容一、全距二、迷你距1、四分位距2、百分位距 三、箱线图四、方差和标准差五、标准分六、图形的鉴别 具体内容

统计学 学习笔记 (三)—— 掌握数据的整体状态 数据的变异性
数据的变异性 从上节的分析可看到,均值、中值、众数等可以反映数据组的集中趋势。但为了了解数据的变异性,光有这些集中趋势量度是不够的。比如下面的例子: 7, 6, 3, 3, 1 3, 4, 4, 5, 4 4, 4, 4, 4, 4 从集中趋势来看,这三组的均值都是4。但明显它们之间的数值不一样。 数据的变异性(散布,离散度)可看作是对不同数值间的差异性的度量。直观

Nature:相同fMRI数据集多中心分析的变异性
一、引言 许多科学领域的数据分析工作已经变得越来越复杂和灵活,这也意味着即使相同的数据,不同研究者采用的处理方法和步骤也可能不同,那么得到的结果也不尽然一致。近期,Nature杂志发表一篇题目为《Variability in the analysis of a single neuroimaging dataset by many teams》的研究论文,该研究通过要求70个独立团队分析相同的fM
