本文主要是介绍GoogLeNet(InceptionV3)模型算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GoogLeNet 团队在给出了一些通用的网络设计准则,以期望在不提高网络参数 量的前提下提升网络的表达能力:
避免特征图 (feature map) 表达瓶颈:从理论上讲,尺寸 (seize) 才包含了相关结构等重要因素,维度(channel) 仅仅提供了信息内容的粗略估计,因此特征图的尺寸应该从输入到输出慢慢减小,避免使用极端压缩。更高的维度特征图更容易获得网络的局部表达:在卷积网络结构中,增加非线
性能够使得更多的特征解耦合,相互独立的特征更多,输入的信息就被分解的更彻底,分解的子特征间相关性低,子特征内部相关性高,因此高维特征带有更多的判别信息,会更容易收敛。在低维特征上的空间聚合( 池化 ) 不会 ( 极少 ) 损失太多信息:相邻的位置的信息具有强相关性,即使进行了降维,也不会带来太多的损失,并且维数的降低,也能够加速网络学习。
平衡网络的宽度与深度:最优的网络应该在每一层网络宽度和网络深度之间有一个很好的平衡。
1.Factorized Convolutions卷积分解
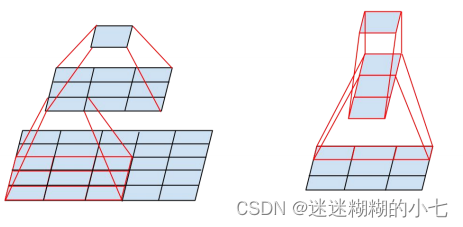
分解卷积的主要目的是为了 减少网络中的参数 ,主要方法有:大卷积分解成小卷积,小卷积分解为非对称卷积。
大卷积分解成小卷积: 大尺度的卷积可以获得更大的感受野,但是也带来参数量的增加VggNet 表明使用大于大卷积核 ( 大于 3×3) 完全可以由一系列的3×3卷积核来替代,即使用小卷积核串联来替代大卷积核。因此在 InceptionV2中已经通过堆叠两层3×3 的卷积核的方式替代一层 5×5 的卷积核,这样的连接方式在保持感受野范围的同时又减少了参数量,不会造成表达缺失,降低网络性能,并且可以避免表达瓶颈,加深非线性表达能力。
小卷积分解为非对称卷积: 3x3 卷积是能够完全获取上下文信息 ( 上、下、左、右) 的最小卷积核,是否能把小卷积核分解的更小呢?在 InceptionV3 中, GoogLeNet团队考虑了非对称卷积分解,引入了将一个较大的二维卷积拆成两个较小的一维卷积的做法,即任意n×n 的卷积都可以通过 1×n 卷积后接 n×1 卷积来替代,非对称卷积能够降低运算量,并且不会降低模型的整体表征能力。
2.InceptionV3结构(一)
与 InceptionV2 结构相同,即 5x5 卷积使用两个 3x3 的卷积代替,目的是减少参数量和计算量—— 大卷积分解成小卷积。

3.InceptionV3结构(二)
将 InceptionV2 结构中 3x3 的卷积使用 1x3 和 3x1 的卷积组合来代替, 5x5 的卷积使用俩个1x3 和 3x1 的卷积组合来代替,目的也是减少参数量和计算量 ———小卷积分解为非对称卷积。
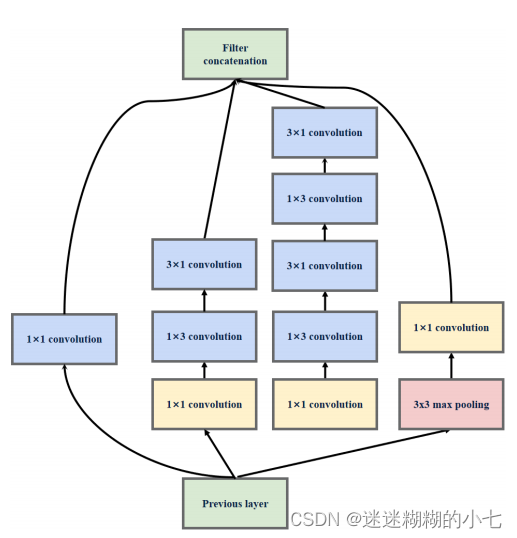
采用这种分解在模型的早期网络层上不能有效发挥作用,但是在中等特征
图大小 (m×m ,其中 m 在 12 和 20 之间的范围 ) 上取得了非常好的效果。
使用 3x3 的卷积代替 5x5 的卷积,输出 512 通道特征图,输出 128 通道特征图:参数量: 512×3×3×128+128×3×3×128=737280计算量: 512×3×3×128×W×H+128×3×3×128×W×H=737280×W×HW×H 是特征图尺寸,假设卷积层的输入输出特征图尺寸保持一致使用 1x3 和 3x1 的卷积组合代替 5x5 的卷积,输出 512 通道特征图,输出 128 通道特征图:参数量: 512×1×3×128+128×3×1×128+128×1×3×128+128×3×1×128=344064计算量:512×1×3×128×W×H+128×3×1×128×W×H+128×1×3×128×W×H+128×3×1×128×W×H=344064×W×H
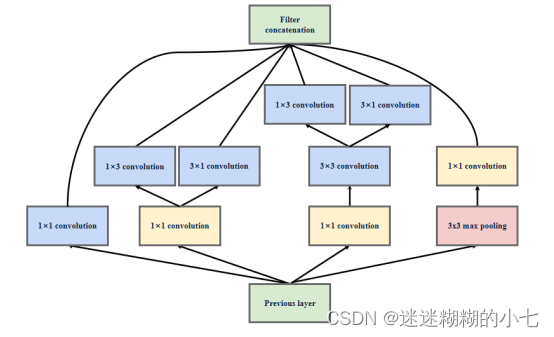
4. InceptionV3结构(三)
该结构主要用于扩充通道数,网络变得更宽,该结构被放置在所以放在
GoogLeNet(InceptionV3) 的最后。
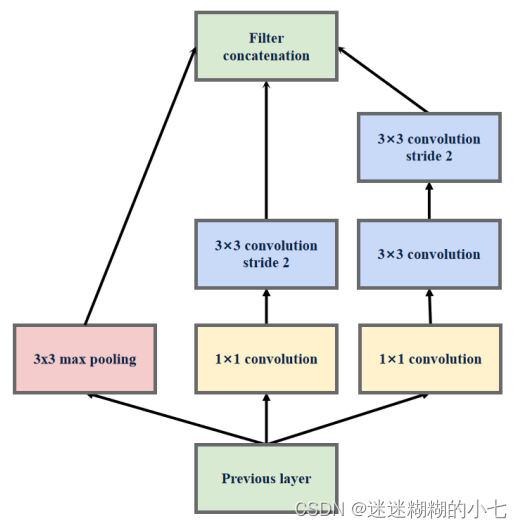
4. InceptionV3特殊结构
在传统方法中,卷积神经网络使用池化等操作以减小特征图大小。先池化
再进行卷积升维会导致瓶颈结构,过程中将丢失很多信息,对于后面输出的特
征图提取的图像中的特征将会更少;先卷积升维再进行池化,计算量将增加三
倍,增加了计算成本:
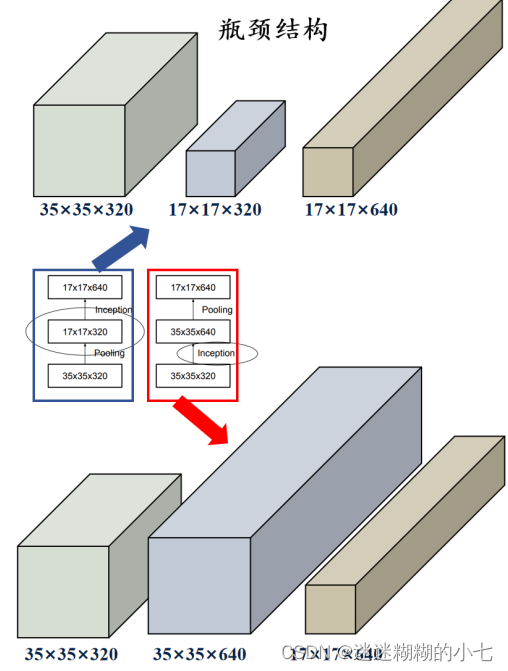
GoogLeNet(InceptionV3)的改进方案采用一种并行的降维结构,在扩充通
道数的同时下采样减小特征图大小,既减少计算量保证了计算效率又避免了瓶
颈结构。
替换 GoogLeNet(InceptionV1) 模型中的 MaxPool 。
辅助分类器
GoogLeNet(InceptionV1)引入了辅助分类器的概念,最初的动机是为了将有用
的梯度反向传递到网络低层,解决梯度消失的问题,提高网络的收敛能力,保
证网络训练正常进行。
GoogLeNet(InceptionV3)的实验则发现 1. 辅助分类器并不能保证收敛更快,并
且有无辅助分类器,训练过程基本保持一致,只有在训练的最后阶段,有辅助
分类器略微高于无辅助分类器的网络; 2. 位于网络低层的辅助分类器对最终结果
没有影响; 3. 辅助分类器充当了正则化器,如果辅助分类器带有 BN 或 Dropout 层那么主分类器性能会更好。
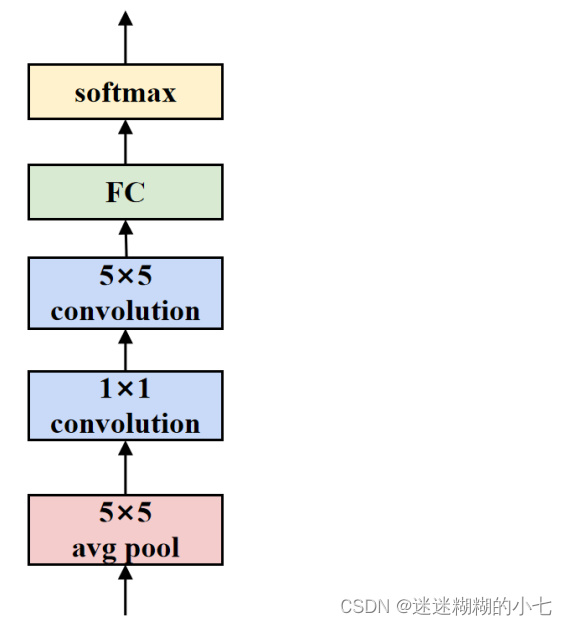
GoogLeNet(InceptionV3) 中的辅助分类器同样不直接用于最终的预测结
果。在训练过程中,辅助分类器的损失函数会被加权,并与主分类器的损失函
数相结合。在推理阶段,辅助分类器被舍弃,仅使用主分类器进行预测。
GoogLeNet(InceptionV3)模型结构
下图是原论文给出的关于 GoogLeNet(InceptionV3) 模型结构的详细示意图:
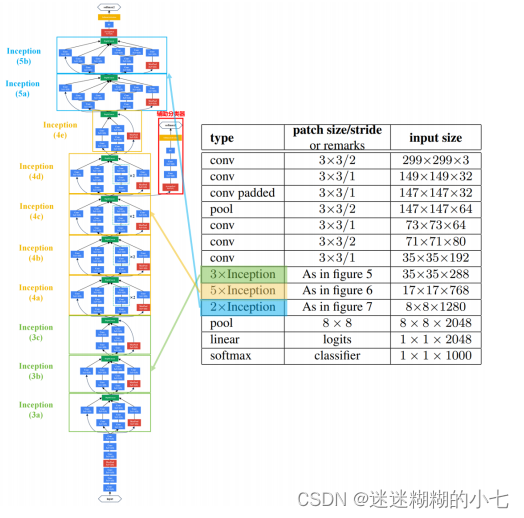
GoogLeNet(InceptionV3)在图像分类中分为两部分: backbone 部分: 主
要由 InceptionV3 模块、卷积层和池化层 ( 汇聚层 ) 组成,分类器部分: 由主分类
器和辅助分类器组成。
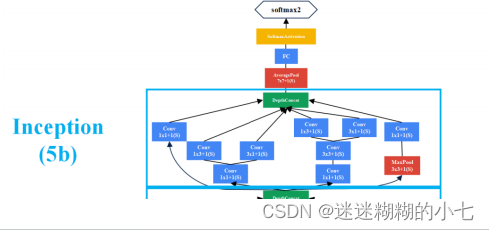
博主仿造GoogLeNet(InceptionV1) 的结构绘制了以下 GoogLeNet(InceptionV3)
的结构。

这篇关于GoogLeNet(InceptionV3)模型算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








