本文主要是介绍AI大模型探索之路-实战篇:智能化IT领域搜索引擎之知乎网站数据获取(初步实践),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列篇章💥
| No. | 文章 |
|---|---|
| 1 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎的构建与初步实践 |
| 2 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之GLM-4大模型技术的实践探索 |
| 3 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之知乎网站数据获取(初步实践) |
| 4 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之知乎网站数据获取(函数封装) |
| 5 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之知乎网站数据获取(流程优化) |
| 6 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之github网站在线搜索 |
| 7 | AI大模型探索之路-实战篇:智能化IT领域搜索引擎之HuggingFace网站在线搜索 |
目录
- 系列篇章💥
- 一、前言
- 二、总体概览
- 三、搜索API封装测试
- 1、导入依赖并初始化客户端
- 2、大模型回答问题策略测试
- 3、function calling函数测试
- 4、谷歌搜索API开发
- 四、知乎网站数据爬取
- 1、数据格式定义
- 2、设置知乎排除的网站
- 3、Google api调用测试
- 4、爬虫之Cookie获取
- 5、爬虫之user-agent
- 6、爬虫之获取PATH
- 7、网络爬虫代码编写
- 8、question类型的网站爬虫测试
- 9、网页数据保存
- 10、question/answer网站爬虫测试
- 11、专栏类网站爬虫测试
- 结语
一、前言
在先前的文章中,我们完成了智能化IT领域搜索引擎的基础架构设计以及Google Search API的申请等前期准备工作。同时,我们还实践测试了GLM4的Function Calling能力,为后续的开发奠定了坚实的基础。本文将正式进入代码开发阶段,首先从知乎网站的数据搜索开始。
二、总体概览
本文将详细阐述如何逐步实现知乎网站数据获取的整个流程。我们将从知乎网站的结构分析入手,通过编写高效的网络爬虫程序,实现对知乎问题的智能检索,并利用先进的数据分析技术,对获取的数据进行深度挖掘和整合,最终将这些有价值的信息融入我们的智能化IT领域搜索引擎中,为用户提供更全面、准确的搜索结果。这一过程中,我们将不断优化算法,提升数据获取的效率和准确性,确保搜索引擎的智能化水平得到持续提升。
三、搜索API封装测试
1、导入依赖并初始化客户端
导入依赖
! pip install --upgrade zhipuai
! pip install --upgrade google-auth google-auth-httplib2 google-auth-oauthlib google-api-python-client requests
创建客户端
import os
import openai
from openai import OpenAI
import glob
import shutilimport numpy as np
import pandas as pdimport json
import io
import inspect
import requests
import re
import random
import stringfrom googleapiclient.discovery import build
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
import base64from bs4 import BeautifulSoup
import dateutil.parser as parser
import tiktoken
from lxml import etree## 初始化客户端
api_key = os.getenv("ZHIPU_API_KEY")from zhipuai import ZhipuAI
client = ZhipuAI(api_key=api_key)
2、大模型回答问题策略测试
测试一
response = client.chat.completions.create(model="glm-4",messages=[{"role": "system", "content": "根据用户输入的问题进行回答,如果知道问题的答案,请回答问题答案,如果不知道问题答案,请回复‘抱歉,这个问题我并不知道’"},{"role": "user", "content": "请问,什么是机器学习?"}]
)
response.choices[0].message.content
输出:
'机器学习是人工智能的一个核心领域,它让计算机能够模拟人类的学习和思考方式。通过使用大量数据和算法,机器学习可以使计算机学会分类、回归和聚类等任务,从而让计算机能够从数据中提取知识,进行决策和预测。在机器学习的流程中,包括数据获取、特征工程、建立模型、模型评估以及调参等步骤。深度学习和强化学习是机器学习的两个重要分支。深度学习主要用于处理复杂结构数据的建模问题,而强化学习则让机器在探索环境中通过试错进行学习。'
测试二
response = client.chat.completions.create(model="glm-4",messages=[{"role": "system", "content": "根据用户输入的问题进行回答,如果知道问题的答案,请回答问题答案,如果不知道问题答案,请回复‘抱歉,这个问题我并不知道’"},{"role": "user", "content": "介绍一下关于GPT-6的猜想"}]
)
response.choices[0].message.content
输出
'抱歉,这个问题我并不知道。\n\n到2023为止,GPT-6尚未被公开提及或发布。GPT(Generative Pre-trained Transformer)系列模型由OpenAI开发,至今已发布了多个版本,如GPT-2和GPT-3。关于未来版本的GPT,如GPT-6,可能会有很多猜想和预期,但具体的内容和功能我无法提供,因为那将基于未来尚未公开的技术和信息。如果GPT-6在您提问之后有了新的消息,我可能无法获取那些最新的信息。'
3、function calling函数测试
增加外部函数测试一下,看大模型回答问题的时候是先去调用外部函数,还是先尝试自己回答。
1)定义函数信息生成器
def auto_functions(functions_list):"""Chat模型的functions参数编写函数:param functions_list: 包含一个或者多个函数对象的列表;:return:满足Chat模型functions参数要求的functions对象"""def functions_generate(functions_list):# 创建空列表,用于保存每个函数的描述字典functions = []# 对每个外部函数进行循环for function in functions_list:# 读取函数对象的函数说明function_description = inspect.getdoc(function)# 读取函数的函数名字符串function_name = function.__name__system_prompt = '以下是某的函数说明:%s,输出结果必须是一个JSON格式的字典,只输出这个字典即可,前后不需要任何前后修饰或说明的语句' % function_descriptionuser_prompt = '根据这个函数的函数说明,请帮我创建一个JSON格式的字典,这个字典有如下5点要求:\1.字典总共有三个键值对;\2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,用于说明该函数的参数输入规范。\5.输出结果必须是一个JSON格式的字典,只输出这个字典即可,前后不需要任何前后修饰或说明的语句' % function_nameresponse = client.chat.completions.create(model="glm-4",messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": user_prompt}])json_str=response.choices[0].message.content.replace("```json","").replace("```","")json_function_description=json.loads(json_str)json_str={"type": "function","function":json_function_description}functions.append(json_str)return functions## 最大可以尝试4次max_attempts = 4attempts = 0while attempts < max_attempts:try:functions = functions_generate(functions_list)break # 如果代码成功执行,跳出循环except Exception as e:attempts += 1 # 增加尝试次数print("发生错误:", e)if attempts == max_attempts:print("已达到最大尝试次数,程序终止。")raise # 重新引发最后一个异常else:print("正在重新运行...")return functions
2)大模型API调用封装
def run_conversation(messages, functions_list=None, model="glm-4"):"""能够自动执行外部函数调用的对话模型:param messages: 必要参数,字典类型,输入到Chat模型的messages参数对象:param functions_list: 可选参数,默认为None,可以设置为包含全部外部函数的列表对象:param model: Chat模型,可选参数,默认模型为glm-4:return:Chat模型输出结果"""# 如果没有外部函数库,则执行普通的对话任务if functions_list == None:response = client.chat.completions.create(model=model,messages=messages,)response_message = response.choices[0].messagefinal_response = response_message.content# 若存在外部函数库,则需要灵活选取外部函数并进行回答else:# 创建functions对象tools = auto_functions(functions_list)# 创建外部函数库字典available_functions = {func.__name__: func for func in functions_list}# 第一次调用大模型response = client.chat.completions.create(model=model,messages=messages,tools=tools,tool_choice="auto", )response_message = response.choices[0].messagetool_calls = response_message.tool_callsif tool_calls:#messages.append(response_message)messages.append(response.choices[0].message.model_dump())for tool_call in tool_calls:function_name = tool_call.function.namefunction_to_call = available_functions[function_name]function_args = json.loads(tool_call.function.arguments)## 真正执行外部函数的就是这儿的代码function_response = function_to_call(**function_args)messages.append({"role": "tool","content": function_response,"tool_call_id": tool_call.id,}) ## 第二次调用模型second_response = client.chat.completions.create(model=model,messages=messages,tools=tools) # 获取最终结果print(second_response.choices[0].message)final_response = second_response.choices[0].message.contentelse:final_response = response_message.contentreturn final_response
3)定义工具函数
def ml_answer(q='什么是机器学习'):"""解释什么是机器学习,返回机器学习的定义和解释:param q: 询问的问题,非必要参数,字符串类型对象:return:返回机器学习的定义和解释"""return("机器学习是一种人工智能(AI)的分支领域,旨在使计算机系统通过学习和经验改进性能。")
4)工具函数调用测试
ml_answer()
'机器学习是一种人工智能(AI)的分支领域,旨在使计算机系统通过学习和经验改进性能。'
functions_list = [ml_answer]
tools = auto_functions(functions_list)
tools
查看输出结果可以看到,大模型已经找到了工具函数

5)大模型调用测试1
response = client.chat.completions.create(model="glm-4",messages=[{"role": "user", "content": "解释什么是机器学习?"}],tools=tools,tool_choice="auto")
response.choices[0].message

注意:我们发现,加入了外部函数以后,大模型回答同一个问题,有时候去调外部函数,有时候是自己去回答的。
但是我们想要的效果是,问任何问题的时候,大模型先自己判断一下自己知不知道,如果知道,那就基于自己的知识进行回答
如果自己不知道的时候采取调用外部函数回答问题。
6)大模型调用测试2
response = client.chat.completions.create(model="glm-4",messages=[{"role":"system","content": "对于用户提的问题,如果知道就直接回答,不知道才通过调用外部函数回答"},{"role": "user", "content": "什么是机器学习?"}],tools=tools,tool_choice="auto")
response.choices[0].message

7)大模型调用测试3
response = client.chat.completions.create(model="glm-4",messages=[{"role":"system","content": "对于用户提的问题,如果知道就直接回答,不知道才通过调用外部函数回答"},{"role": "user", "content": "什么是大模型?"}],tools=tools,tool_choice="auto")
response.choices[0].message

4、谷歌搜索API开发
1)API调用测试
google_search_key = os.getenv("GOOGLE_SEARCH_API_KEY")
cse_id = os.getenv("CSE_ID")
search_term = "OpenAI"
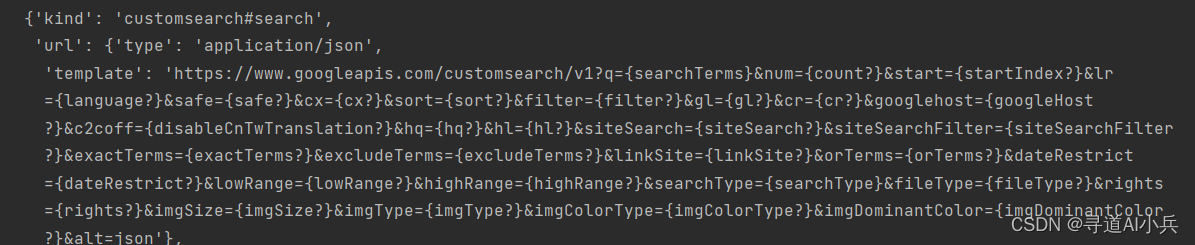
import requests# Step 1.构建请求
url = "https://www.googleapis.com/customsearch/v1"# Step 2.设置查询参数(还有很多参数)
params = {'q': search_term, # 搜索关键词'key': google_search_key, # 谷歌搜索API Key'cx': cse_id # CSE ID
}# Step 3.发送GET请求
response = requests.get(url, params=params)# Step 4.解析响应
data = response.json()
data
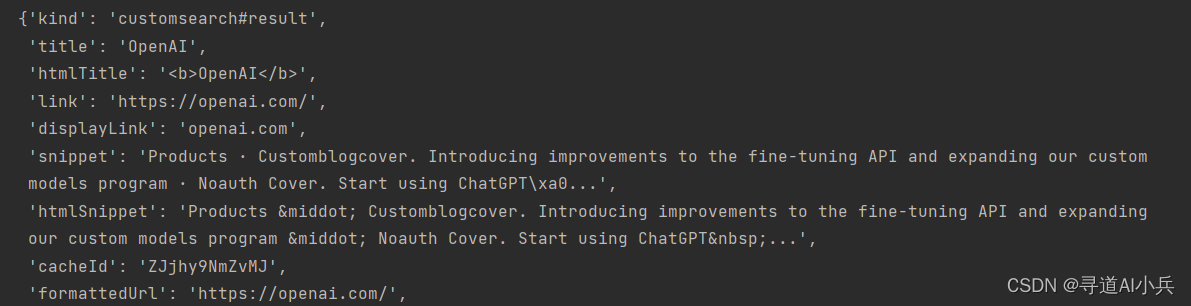
data['items'][0]
2)Google API封装
def google_search(query, num_results=10, site_url=None):api_key = os.getenv("GOOGLE_SEARCH_API_KEY")cse_id = os.getenv("CSE_ID")url = "https://www.googleapis.com/customsearch/v1"# API 请求参数if site_url == None:params = {'q': query, 'key': api_key, 'cx': cse_id, 'num': num_results }else:params = {'q': query, 'key': api_key, 'cx': cse_id, 'num': num_results, 'siteSearch': site_url}# 发送请求response = requests.get(url, params=params)response.raise_for_status()# 解析响应search_results = response.json().get('items', [])# 提取所需信息results = [{'title': item['title'],'link': item['link'],'snippet': item['snippet']} for item in search_results]return results
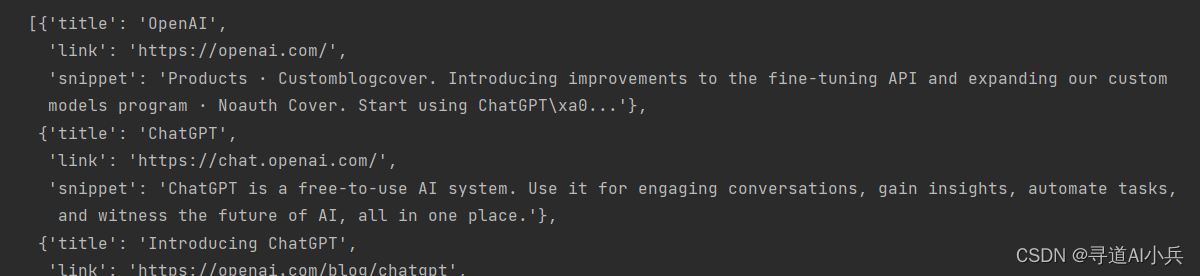
3)API调用测试
search_term = "OpenAI"
results = google_search(query=search_term, num_results=5)
results
输出:
results = google_search(query='GLM4大模型有什么新特性?', num_results=10, site_url='https://www.zhihu.com/')
results
输出:
[{'title': '智谱发布GLM-4 基座大模型,性能效果如何? - 知乎','link': 'https://www.zhihu.com/question/639753877?write','snippet': 'Jan 16, 2024 ... ... 大小时,路坚终于出现了。「我这边终于有新进展了,你在学校吗?我要当面告诉你!」室友激动坏了,突然高喊了一声「我赢了」,把我吓一跳。这个小镇\xa0...'},{'title': '智谱发布GLM-4 基座大模型,性能效果如何? - 新智元的回答- 知乎','link': 'https://www.zhihu.com/question/639753877/answer/3364585933','snippet': 'Jan 15, 2024 ... 它能够支持更长的上下文,具备更强的多模态 功能,支持更快的推理,更多并发,推理成本大大降低。 同时,GLM-4也增强了智能体能力。 基础能力. 从众多评测\xa0...'},{'title': '智谱发布GLM-4 基座大模型,性能效果如何? - 杨夕的回答- 知乎','link': 'https://www.zhihu.com/question/639753877/answer/3364710951','snippet': 'Jan 15, 2024 ... 众所周知,在我国众多大型模型企业中,我一直对智谱AI抱有极高的好感。 这不仅是因为他们浓厚的学术氛围…'},{'title': '智谱AI 宣布基座大模型GLM-4 发布,该大模型有何功能? - 知乎','link': 'https://www.zhihu.com/question/640050703','snippet': 'Jan 17, 2024 ... 1月16日下午消息,智谱AI首届技术开放日上,智谱AI宣布发布新一代基座大模型GLM-4。据介绍,GLM-4的整体…'},{'title': '智谱发布GLM-4 基座大模型,性能效果如何? - 大林的回答- 知乎','link': 'https://www.zhihu.com/question/639753877/answer/3364780672','snippet': 'Jan 16, 2024 ... 智谱发布GLM-4 基座大模型,性能效果如何? 量子位 ... 大模型的微调都是有益处的。 2、更长的上下文 ... 特性的基础之上,ChatGLM2-6B 引入了如下新特性:.'},{'title': '智谱发布GLM-4 基座大模型,性能效果如何? - 数字生命卡兹克的 ...','link': 'https://www.zhihu.com/question/639753877/answer/3364475601','snippet': 'Jan 15, 2024 ... 再将它们全部打包在了一起。 比如我说一句:“搜索一下过去7天北京的天气,然后给我处理成一张表格让我可以下载”.'},{'title': '如何看待智谱AI发布GLM4?国产大模型与GPT-4更加接近了吗? - 一 ...','link': 'https://www.zhihu.com/question/639787253/answer/3365580226','snippet': 'Jan 16, 2024 ... ... 新一代基座大模型GLM-4。 ➤GLM-4模型:性能逼近GPT-4. 先看总体的评测数据:. 在大规模多任务语言理解评测中,GLM-4得分远超GPT-3.5,平均达到GPT-4的\xa0...'},{'title': 'chatGLM和chatGPT的技术区别在哪里? - 李孟聊AI 的回答- 知乎','link': 'https://www.zhihu.com/question/604393963/answer/3367583114','snippet': 'Jun 1, 2023 ... \ufeff本文以GLM-4 发布功能作为基准对比ChatGPT4,Claude-2测试。 ... 新一代基座大模型GLM-4。 多模态理解. GLM-4 ... 目前ChatGLM是基于Base 模型进行有监督微调\xa0...'},{'title': '如何看待智谱AI发布GLM4?国产大模型与GPT-4更加接近了吗? - 知乎','link': 'https://www.zhihu.com/question/639787253','snippet': 'Jan 16, 2024 ... 他立刻下载安装,试用后发现ChatGLM4 All Tools功能强大,使用方便,心中无比高兴。'},{'title': '智谱发布GLM-4 基座大模型,性能效果如何? - GLM大模型的回答- 知乎','link': 'https://www.zhihu.com/question/639753877/answer/3365018019','snippet': 'Jan 16, 2024 ... GLMs & MaaS API. GLM-4的全线能力提升使得我们有机会探索真正意义上的GLMs。用户可以下载(更新)智谱清\xa0...'}]
四、知乎网站数据爬取
1、数据格式定义
import jsonfile_path = 'result.json'# 创建包含JSON对象的列表
json_data = [{"link": "https://example.com/article/1","title": "Sample Article 1","content": "This is the content of the first article...","tokens": "Number of tokens..."}
]# 指定保存文件的路径
file_path = "result.json"# 将JSON数据写入本地文件
with open(file_path, "w", encoding="utf-8") as json_file:json.dump(json_data, json_file, ensure_ascii=False, indent=4)print(f"JSON数据已保存到文件:{file_path}")
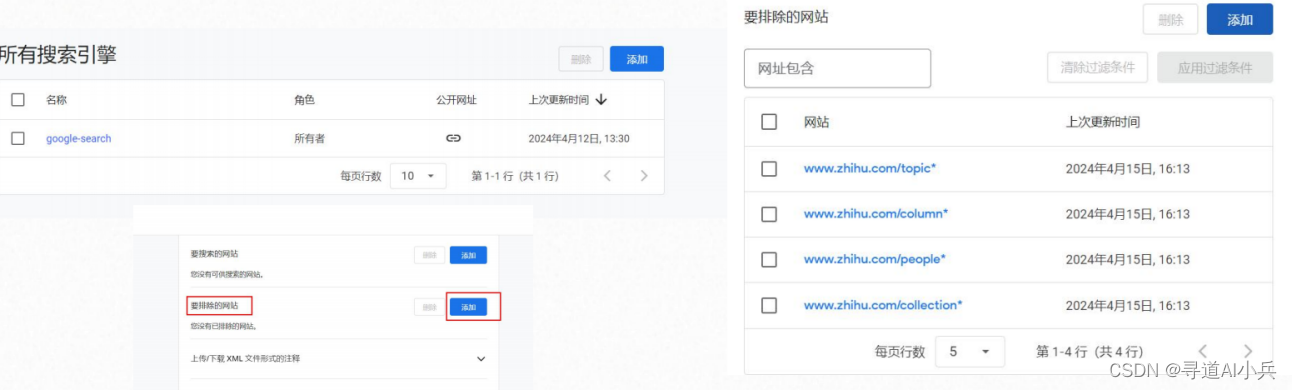
2、设置知乎排除的网站
对搜索引擎设置:https://programmablesearchengine.google.com/ ,设置排除的网址;以下几类是不需要的网页数据:
www.zhihu.com/collection 类网站(收藏列表),
www.zhihu.com/people 类网站(个人主页),
www.zhihu.com/column 类网站(个人文章主页),
www.zhihu.com/topic 类网站(主题)
3、Google api调用测试
results = google_search(query='GLM4大模型有什么新特性?', num_results=5, site_url='https://www.zhihu.com/')
results
输出:

4、爬虫之Cookie获取
- 手动登录:首先,你需要在浏览器中手动访问目标网站并登录知乎。
- 开发者工具:登录后,打开浏览器的开发者工具。在 Chrome 和 Firefox 中,你可以右键点击
页面,然后选择“检查”或“检查元素”。 - 网络标签:在开发者工具中,转到“网络”或“Network”标签。
- 刷新页面:在开发者工具打开的情况下,刷新页面。这会捕获所有页面加载过程中的网络请求。
- 查找请求:在捕获的请求列表中,找到主要的请求(通常是顶部的第一个,或者是与你的目标
URL匹配的请求)。 - 查看请求头:点击这个请求,然后查找“请求头”或“Request Headers”部分。
- 复制Cookie:在“请求头”部分,你应该能看到一个名为
Cookie的字段。你可以直接复制这个
字段的值。 - 使用在爬虫中:将复制的
Cookie值用于你的爬虫代码中的请求头。
需要注意的是Cookie通常有有效期,过了有效期它可能会过期。如果你的爬虫在某个时间点突
然无法工作,你可能需要重新获取新的Cookie。
5、爬虫之user-agent
- Chrome (Windows 10):
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 - Firefox (Windows 10):
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0 - Safari (macOS):
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15 - Edge (Windows 10):
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Edg/91.0.864.59 - Chrome (Android):
Mozilla/5.0 (Linux; Android 10; SM-A205U) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.120 Mobile
Safari/537.36 - Safari (iPhone):
Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1 Mobile/15E148
Safari/604.1
6、爬虫之获取PATH
以下是使用Google Chrome浏览器查看和获取XPath的步骤,但其他现代浏览器(如Firefox、Edge等)的操作方式也类似:
- 打开网页: - 在Chrome中打开你想要查看的网页。
- 打开开发者工具: - 右键点击页面上的任意位置,然后选择“检查”(或“Inspect Element”)。
- 或者,你可以使用快捷键
Ctrl + Shift + I(Windows/Linux)或Cmd + Option + I(Mac)。
- 使用元素选择器: - 在开发者工具的左上角,你会看到一个鼠标指针图标,这是“选择元素”工具。点击它。
- 然后,将鼠标悬停在页面上的元素上。你会看到元素被高亮显示,并在开发者工具的“Elements”面板中显示其HTML结构。
- 获取XPath: - 当你找到想要的元素后,在“Elements”面板中右键点击它。
- 在弹出的菜单中,选择“Copy” > “Copy XPath”。这将元素的XPath复制到剪贴板。
- 粘贴XPath: - 接下来即可将复制的XPath粘贴到你的代码或其他地方。
7、网络爬虫代码编写
1)请求头样例
## 请求头
headers = {'authority': 'www.zhihu.com','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8','cache-control': 'max-age=0','cookie': "Your cookie", # 需要手动获取cookie'upgrade-insecure-requests': '1','user-agent': 'Your user-agent', # 手动编写或者选择之后给出的user-agent选项选择其一填写
}
- authority: 通常表示请求的目标主机名。在当前项目中需要视情况填写
www.zhihu.com或者zhuanlan.zhihu.com; - accept: 告诉服务器客户端能够处理的内容类型。这里列出了多种内容类型,包括HTML、XML和各种图片格式,该参数按照给定内容填写即可;
- accept-language: 告诉服务器客户端的首选语言。这里,首选语言被设置为简体中文(zh-CN),其次是其他中文版本(zh),然后是英文(en)。同样该参数的内容按照给定内容填写即可;
- cache-control: 控制缓存的行为。
max-age=0通常表示客户端不希望得到缓存的响应,而希望从原始服务器获取一个新的响应。该参数的内容按照给定内容填写即可; - cookie: 包含服务器之前发送给客户端的cookie。这些cookie可能用于身份验证、会话跟踪或其他目的。这里需要重点注意,建议大家自行获取对应个人浏览器产生的cookie,以避免cookie滥用导致被识别为机器人从而导致封IP;
- upgrade-insecure-requests: 这个头部告诉服务器,如果可能的话,客户端希望使用更安全的协议(如HTTPS)进行通信。建议取值为1即可;
- user-agent: 描述发出请求的客户端的类型。这里,它模拟了一个Chrome浏览器的用户代理字符串。网站有时会根据这个头部提供不同的内容或布局,或者检测是否是爬虫。该参数也需要根据自己实际情况进行编写。
2)设置cookie和user-agent
cookie = "q_c1=3c10baf5bd084b3cbfe7eece648ba243|1704976541000|1704976541000; _zap=086350b3-1588-49c4-9d6d-de88f3faae03; d_c0=AGCYfYvO_RePTvjfB1kZwPLeke_N5AM6nwo=|1704949678; _xsrf=qR1FJHlZ9dvYhhoj4SUj43SAIBUwPOqm; __snaker__id=wNWnamiJKBI0kzkI; q_c1=d44e397edb6740859a7d2a0d4155bfab|1706509753000|1706509753000; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1706509695,1706589529,1706765465,1708650963; z_c0=2|1:0|10:1713167971|4:z_c0|80:MS4xOGRHQVNnQUFBQUFtQUFBQVlBSlZUYjZqOTJaLXVDSjdRSmJKMHgyVEhxTE13UGN1TUJBdHZnPT0=|15b2c2ece393ac4ea374d9b36cde5af7304f8ee7632e060fe6835bfadb5e4132; KLBRSID=9d75f80756f65c61b0a50d80b4ca9b13|1713170212|1713167958"
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
3)设置请求头信息
## 请求头
headers = {'authority': 'www.zhihu.com','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8','cache-control': 'max-age=0','cookie': cookie, # 需要手动获取cookie'upgrade-insecure-requests': '1','user-agent': user_agent, # 手动编写或者选择之后给出的user-agent选项选择其一填写
}
8、question类型的网站爬虫测试
## question类型的网站
url = 'https://www.zhihu.com/question/639753877'
res = requests.get(url, headers=headers).text
res
输出:
1)网页标题解析
res_xpath = etree.HTML(res)
res_xpath

title = res_xpath.xpath('//div/div[1]/div/h1/text()')[0]
#%%
title

2)网页内容解析
## 获取回答的正文
#//*[@id="root"]/div/main/div/div/div[1]/div[2]/div/div[1]/div[1]/div[6]/div/div/div/div/span/p[1]/text()
text = ''
text_d = res_xpath.xpath('//div/div/div/div[2]/div/div[2]/div/div/div[2]/span[1]/div/div/span/p/text()')
for t in text_d:txt = str(t).replace('\n', ' ')text +=txtprint(text)

9、网页数据保存
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
len(encoding.encode(text))
json_data = [{"link": url,"title": title,"content": text,"tokens": len(encoding.encode(text))}
]
title="智谱发布GLM-4基座大模型,性能效果如何"
#%%
with open('./auto_search/介绍一下GLM4大模型的特性/%s.json' % title, 'w') as f:json.dump(json_data, f)
#%%
with open('./auto_search/介绍一下GLM4大模型的特性/%s.json' % title, 'r') as f:jd = json.load(f)
#%%
jd

10、question/answer网站爬虫测试
## question/answer网站
url = 'https://www.zhihu.com/question/639787253/answer/3365580226'
res = requests.get(url, headers=headers).text
res_xpath = etree.HTML(res)
#%%
# question/answer网站标题
res_xpath.xpath('//div/div[1]/div/h1/text()')[0]
回答内容爬取解析
# question/answer网站置顶回答内容
dic = []
text_d = res_xpath.xpath('//*[@id="root"]/div/main/div/div/div[3]/div[1]/div/div[2]/div/div/div/div[2]/span[1]/div/div/span/p/text()')
for t in text_d:txt = str(t).replace('\n', ' ')dic.append(txt)print(txt)
11、专栏类网站爬虫测试
# 专栏类网站
url = 'https://zhuanlan.zhihu.com/p/469793124'
res = requests.get(url, headers=headers).text
res_xpath = etree.HTML(res)
#%%
# 专栏类网站标题
res_xpath.xpath('//div[1]/div/main/div/article/header/h1/text()')[0]

网页内容解析读取
# 专栏类网站标题内容
dic = []
text_d = res_xpath.xpath('//div/main/div/article/div[1]/div/div/div/p/text()')
for t in text_d:txt = str(t).replace('\n', ' ')dic.append(txt)print(txt)

结语
随着本章的结束,我们已经完成了知乎网站数据的智能搜索的基本链路拉通,下一篇章我们将对想要的函数进行封装改造,提高整各项目模块的扩展和复用性。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:建立有技术交流群,可以扫码👇 加入社群,500本各类编程书籍、AI教程、AI工具等你领取!
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
这篇关于AI大模型探索之路-实战篇:智能化IT领域搜索引擎之知乎网站数据获取(初步实践)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







