本文主要是介绍矢量量化:原理、变体及码本优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
矢量量化 (VQ) 是一种类似于 k 均值算法的数据压缩技术,可以对任何数据分布进行建模。矢量量化已广泛应用于语音、图像和视频数据,例如图像生成、语音和音频编码、语音转换、音乐生成和文本到语音合成。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、矢量量化原理及变体
下图显示了矢量量化 (VQ) 的工作原理。对于 VQ 过程,我们需要一个包含多个码字的码本(codebook)。对数据点(data point,灰点)应用 VQ 意味着将其映射到最近的码字(codeword,蓝点),即将数据点的值替换为最接近的码字值。每个 Voronoi 单元(黑线)包含一个码字,使得位于该单元中的所有数据点都将映射到该码字,因为它是距离该 Voronoi 单元中数据点最近的码字:
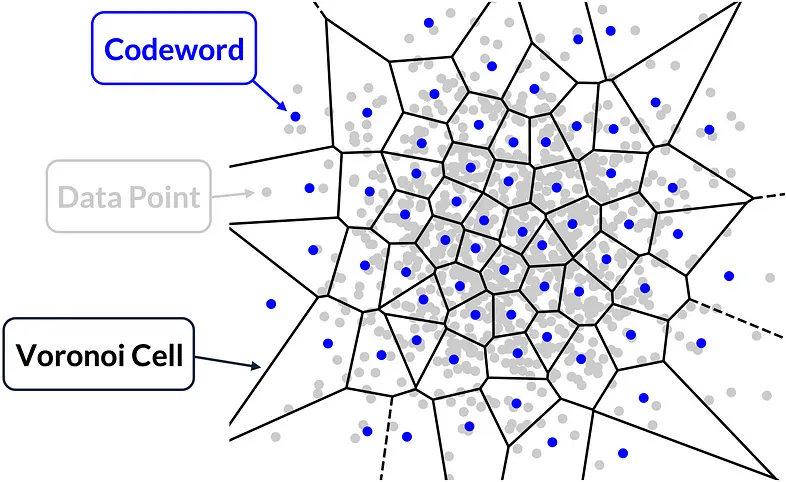
矢量量化操作
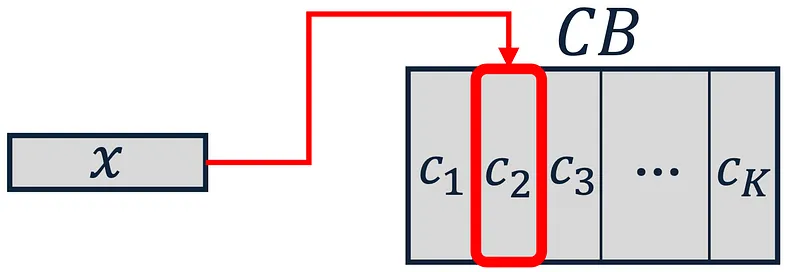
换句话说,矢量量化使用以下公式将输入矢量 x 映射到码本 (CB) 内的最接近码字:

如图所示:
随着码本大小的增加(VQ 比特率的增加),VQ 的计算复杂度呈指数增长。因此,这种简单形式的 VQ 仅适用于有限的比特率(有限的码本大小)。为了解决这一挑战并将 VQ 应用于更高的比特率和更高维度的数据,我们使用了一些 VQ 变体,例如残差 VQ、加法 VQ 和乘积 VQ。这些方法考虑多个码本来对数据应用 VQ。我们将在下面解释这三种 VQ 方法。
1.1 残差矢量量化 (RVQ)
残差矢量量化(Residual Vector Quantization)通过对输入矢量 x 应用 M 个连续的 VQ 模块对其进行量化:

根据上图,假设 M=3。我们使用第一个码本 (CB¹) 对输入矢量 x 应用第一个 VQ 模块。然后,在找到第一个码本中最接近的码字后,我们计算余数 (R1)。之后,我们使用第二个码本 (CB²) 将 R1 作为输入传递给下一个 VQ 模块。此过程将持续 M 个阶段,我们将在其中找到来自不同码本的三个最接近的码字。最后,我们将输入矢量 x 量化为 M 个最接近的码字的总和。
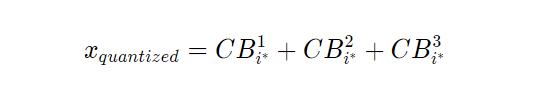
1.2 加法矢量量化 (AVQ)
与残差矢量量化类似,加法矢量量化(Additive Vector Quantization)通过应用 M 个连续的矢量量化模块来量化输入矢量 x。但是,加法矢量量化采用复杂的波束搜索(beam search)算法来为量化过程找到最接近的码字:

根据上图,我们假设 M=3。在加法矢量量化中,首先我们从所有三个码本(此处为 CB¹、CB²、CB³)的并集中搜索最接近的码字。然后,假设我们从 CB² 中找到最佳码字。之后,我们计算残差(R1)并将其作为输入传递给下一个矢量量化模块。由于第一个码字是从 CB² 中选择的,现在我们从 CB¹ 和 CB³ 的并集中搜索最接近的码字。计算残差 R2 后,我们将其作为输入传递给最后一个矢量量化模块,在那里我们使用尚未参与量化过程的最后一个码本(在本例中为 CB¹)进行搜索。最后,我们将输入向量 x 量化为 M 个最接近的代码字的总和:
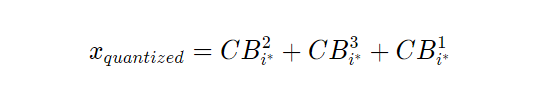
1.3 乘积矢量量化 (PVQ)
乘积矢量量化(Product Vector Quantization)将维度为 D 的输入矢量 x 拆分为维度为 D/M 的 M 个独立子空间。然后,它将 M 个独立矢量量化模块应用于现有子空间。最后,乘积矢量量化将输入矢量 x 量化为 M 个最接近码字(每个码本一个)的串联。
下图显示了 M=3 时的乘积矢量量化:
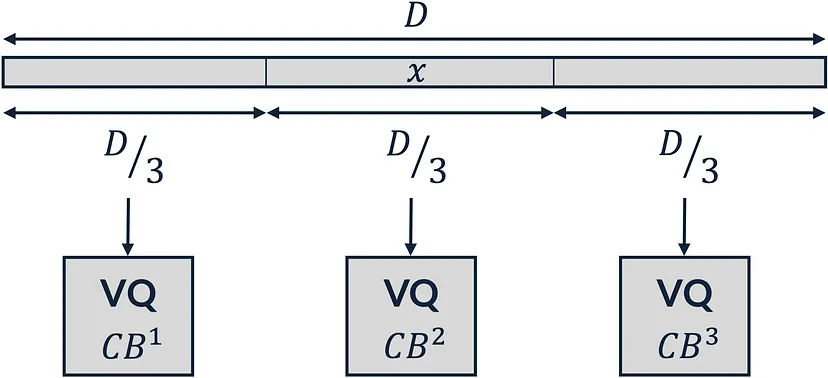
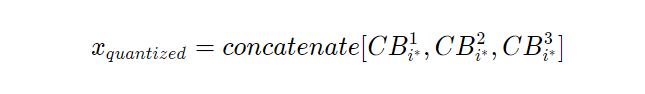
2、码本优化
矢量量化 (VQ) 训练意味着优化码本,使其以最小化数据点和码本元素之间的量化误差(如均方误差)的方式对数据分布进行建模。为了优化上述三种 VQ 变体(残差 VQ、加性 VQ 和乘积 VQ)的码本,我们在下面会提到不同的方法。
2.1 K-means 算法(传统方法)
根据文献综述,在大多数论文中,这三种 VQ 方法的码本都已通过 k-means 算法进行了优化。
2.2 随机优化(机器学习算法)
机器学习优化算法基于梯度计算。因此,无法使用机器学习优化来优化矢量量化方法,因为矢量量化函数(上面的第一个方程)中的 argmin 函数不可微。换句话说,我们无法在反向传播中将梯度传递到矢量量化函数上。这里我们提到了两种解决这个问题的方法。
- 直通估计器 (STE)
STE (Straight Through Estimator) 通过在反向传播中简单地将梯度完整地复制到 VQ 模块上来解决该问题。因此,它没有考虑矢量量化的影响,导致梯度与 VQ 函数的真实行为不匹配。
- 矢量量化 中的噪声替代(NSVQ)
NSVQ(Noise Substitution in Vector Quantization) 技术是我们最近提出的方法,其中通过向输入矢量添加噪声来模拟矢量量化误差,这样模拟的噪声将获得原始 VQ 误差分布的形状(你可以在这篇文章中简要了解 NSVQ)。
NSVQ 技术比 STE 方法有一些优势,如下所示。1) NSVQ 为 VQ 函数产生更准确的梯度。2) NSVQ 实现了 VQ 训练的更快收敛(码本优化)。 3)NSVQ不需要任何额外的超参数调整来进行VQ训练(不需要在全局优化损失函数中添加额外的VQ训练损失项)。
3、实验
在我们的论文中,我们使用了我们最近提出的 NSVQ 技术,通过机器学习优化对上述三种 VQ 变体进行了优化。为了评估这三种 VQ 方法的性能并研究它们的准确性、比特率和复杂性之间的权衡,我们进行了四种不同的实验场景。我们将在下文中解释所有这些实验场景。
3.1 近似最近邻 (ANN) 搜索
在这个实验中,我们通过在其学习集上训练三种 VQ 方法,对 SIFT1M 数据集(128-D 图像描述符)的分布进行建模。SIFT1M 图像描述符数据集包括 10⁶ 基向量、10⁵ 学习向量和 10⁴ 查询向量,用于测试目的。基本事实包含一组实际的最近邻,从基向量到查询向量。
在 ANN 搜索中,我们首先使用在学习集上训练的相应学习码本压缩基向量。然后,对于每个查询向量,我们通过执行穷举搜索从压缩的基向量中找到近似的最近邻。为了评估数据压缩的质量,我们计算了参数 T 在不同值下的召回率指标,该指标显示了实际的最近邻(来自事实)是否存在于前 T 个计算出的最近邻中。下图说明了我们提出的 NSVQ 技术优化的三种 VQ 变体与基线方法在召回率指标下的比较。总体而言,所有三种基于机器学习的优化 VQ 方法都实现了与基线相当的(在 RVQ 的情况下甚至略胜一筹)召回率值。
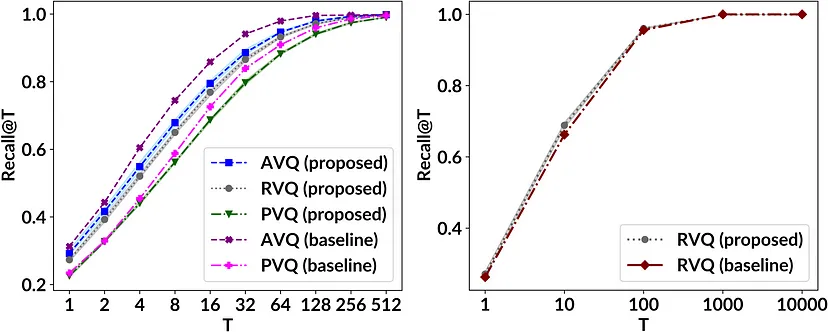
通过应用我们提出的 VQ 方法和 64 位基线(8 个码本,每个码本有 256 个码字)对 SIFT1M 数据集进行压缩,比较召回率值;Recall@T 显示了 T 个计算出的最近邻居中是否存在实际的最近邻居(来自事实)
3.2 使用 VQ-VAE 进行图像压缩
在这个实验中,我们在 CIFAR10 数据集的训练集上训练了一个矢量量化变分自动编码器 (VQ-VAE) 来压缩它。为了在 VQ-VAE 的瓶颈中应用矢量量化,我们使用了这三种 VQ 方法中的每一种。
训练后,我们使用训练过的编码器、解码器和学习过的每种 VQ 方法的码本重建了 CIFAR10 的测试图像。为了评估重建图像的质量,我们采用了峰值信噪比 (Peak SNR) 指标。
此外,我们使用符合 ITU-T 标准的加权每秒百万次操作 (WMOPS) 指标计算了每种 VQ 方法的复杂度。下图显示了本次实验的结果。
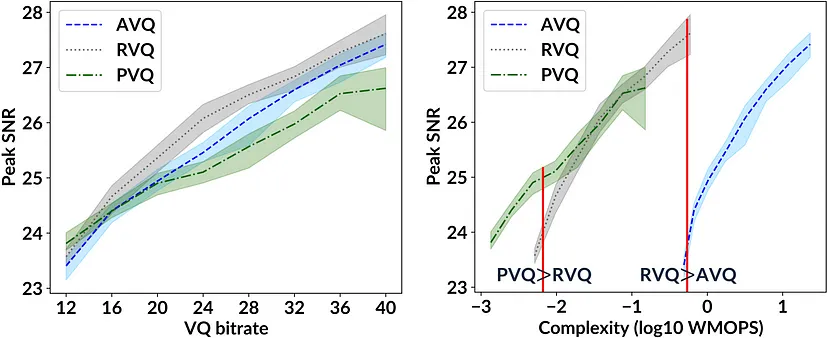
在图像压缩场景中,15k 个训练批次和 10 个单独实验中提出的 VQ 方法的峰值 SNR 和复杂度;线表示平均值,相应的填充区域表示其 95% 分位数。对于所有 VQ 比特率,我们使用了四个码本,即 M=4。
根据复杂度图(右侧),我们发现,在计算资源使用量相同(左侧垂直红线)和比特率较高的情况下,产品 VQ 的性能优于残差 VQ。此外,在计算资源使用量相同(右侧垂直红线)和比特率较高的情况下,残差 VQ 的性能优于加法 VQ。因此,根据可用的计算资源量,我们可以得出哪种 VQ 方法最好。
3.3 语音编码
在此实验中,我们使用语音编解码器,通过三种 VQ 方法对语音信号的频谱包络进行建模。为了评估解码语音信号的质量,我们使用语音质量感知评估 (PESQ) 和感知加权信噪比 (pSNR) 作为客观指标。
下图显示了 PESQ 和 pSNR 标准下这三种 VQ 方法的性能。根据结果,我们观察到加法 VQ 在两个指标上都比残差 VQ 和产品 VQ 获得更高的均值和更低的方差。
在语音编码场景中,对于 16 位 VQ(具有 4 个码本,即 M=4),在总比特率为 8、9.6、13.2、16.4、24.4 和 32 kbit/s 时,所提出的 VQ 方法在 PESQ 和 pSNR 指标方面的性能;实线表示 PESQ 和 pSNR 的平均值,相应的填充区域表示它们的 95% 分位数。
3.4 示例
在这个实验中,我们打算比较三种 VQ 方法在数据相关性方面的性能。因此,我们准备了两个维度为 64 的相关和不相关的数据集。然后,我们使用这三种 VQ 方法压缩这些数据集。为了评估性能,我们计算了每个数据集与其量化版本之间的均方误差 (MSE)。下图显示了此实验的结果。
使用所有三种提出的 VQ 方法(数据维度=64,对于所有 VQ 比特率,我们使用四个码本,即 M=4)对相关和不相关数据集进行矢量量化误差。
在相关数据集中,由于残差矢量量化和加法矢量量化考虑了所有数据维度之间的相关性,因此它们的量化误差比乘积矢量量化低得多,这是意料之中的。另一方面,对于不相关的数据,乘积矢量量化比加法矢量量化和残差矢量量化性能更好,因为数据维度之间没有相关性,而这正是乘积矢量量化所假设的。
4、结束语
使用矢量量化 (VQ) 的变体(例如残差 VQ、加法 VQ 和乘积 VQ)可以将 VQ 应用于高比特率和高维数据。到目前为止,这些 VQ 方法已通过经典期望最大化和 k-menas 算法进行了优化。
在本文中,我们使用我们最近提出的矢量量化噪声替换 (NSVQ) 技术通过机器学习优化优化这些 VQ 方法。此外,NSVQ 允许在神经网络中端到端优化 VQ 方法。我们还研究了这三种 VQ 方法的比特率、准确性和复杂性之间的权衡。因此,我们的开源实现有助于针对特定用例做出最佳的 VQ 方法选择。
原文链接:矢量量化原理及优化 - BimAnt
这篇关于矢量量化:原理、变体及码本优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

