本文主要是介绍展示广告预估模型优势特征应用实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 简介
本文介绍阿里妈妈展示广告Rank团队对优势特征的应用实践。优势特征是指预估模型在线无法获取但离线能用于提升模型能力的特征。一种经典的优势特征使用方法是优势特征蒸馏(PFD)[1,2]:PFD方法使用全部特征(包括优势特征)来训练教师模型,然后利用以非优势特征(离在线均可得的常规特征)为输入的学生模型蒸馏教师模型能力,并用于在线打分。
对于预估模型,我们通常会使用准度和排序能力来作为评价指标,针对优势特征蒸馏这个问题,我们发现pointwise和listwise蒸馏损失分别存在一定问题:
pointwise蒸馏损失:虽然pointwise损失能很好地保证准度,但其在排序能力上表现要弱于使用listwise损失函数进行蒸馏。
listwise蒸馏损失:直接使用listwise损失函数进行蒸馏会造成预估不准的问题,这对于依赖准度的广告系统来说难以接受。
一种同时提升准度与排序能力的思路是使用 scale-calibrated ranking loss,例如阿里妈妈的JRC [3]以及Google的RCR [4] 。本文中,我们针对优势特征蒸馏问题的特性,设计了 scale-calibrated listwise distillation loss(准度兼容的listwise蒸馏损失)CLID:CLID 以session粒度进行listwise蒸馏,具体来说,我们将学生和教师模型输出的概率分别进行session内的归一化,得到「样本排在session top」的概率,随后对学生和教师模型输出的「样本排在session top」概率对齐,在实现蒸馏教师模型排序能力的同时也在理论上保证了学生模型的准度不被破坏。
基于该项工作的论文已被WSDM 2024接收,欢迎阅读交流~
论文:Calibration-compatible Listwise Distillation of Privileged Features for CTR Prediction
作者:Xiaoqiang Gui, Yueyao Cheng, Xiang-Rong Sheng, Yunfeng Zhao, Guoxian Yu, Shuguang Han, Yuning Jiang, Jian Xu, Bo Zheng
链接: https://arxiv.org/abs/2312.08727
2. 背景
在预估模型中,存在着一些离线可以获取在线无法获取的特征,我们将这一类特征统称为优势特征。对于精排CTR预估模型来说,目标商品的同页面曝光的商品列表就属于优势特征(context特征)。离线添加此类特征通常能极大提升模型预估能力,但在线精排模型预测时却拿不到此类后验特征。
一种经典的优势特征使用方法是优势特征蒸馏(PFD):PFD方法使用全部特征(包括优势特征)来训练一个教师模型,然后将教师模型的知识蒸馏到使用非优势特征(离在线均可得的常规特征)进行训练的学生模型上,学生模型进一步用于在线推理。在实际实践中,PFD方法通常使用pointwise的LogLoss作为蒸馏损失。然而我们发现,pointwise蒸馏损失难以完全学习到教师模型的排序能力。这是因为pointwise蒸馏损失假设数据独立同分布,而推荐系统中存在外部性问题,即同一展示页面上的候选物品点击率显著受其周围其他商品的影响。因此在进行优势特征蒸馏时,有必要将一个session内的商品做为整体进行蒸馏,以此提升学生模型的预估能力。
3. 方法
考虑到时效性要求以及资源需求,我们并没有先训练好教师模型再单独训练一个学生模型,而是使教师模型和学生模型共享一部分参数,同时流式训练。以精排点击率预估任务为例,CLID方法示意图如下所示。
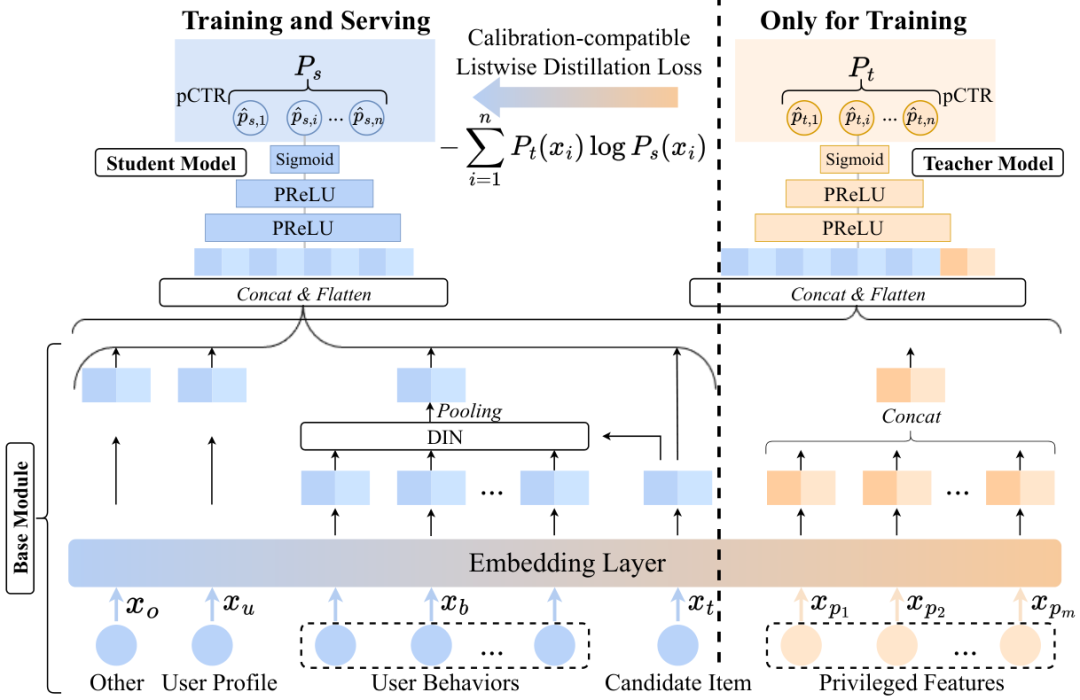
3.1 模型结构
在点击率预估任务中,我们使用的非优势特征包括用户行为序列,用户画像,候选物品以及其他特征。此外我们还额外构造了候选商品的同session展示商品列表作为其优势特征。
3.1.1 基模块
如上图所示,我们将学生模型和教师模型共享的这部分参数称为基模块(Base Module),其包含embedding层和用户行为序列建模模块。首先我们通过embedding层将高维稀疏特征转化为低维嵌入表示.这些特征包括非优势特征和优势特征。个优势特征被定义为 。对于用户行为特征,我们采用DIN作为序列建模模块。通过拼接所有embedding,我们可以得到非优势特征表示向量作为学生模型的输入:
随后,我们拼接个优势特征的embedding得到优势特征表示向量:
因为优势特征在训练时可得而测试时不可得,因此我们将它们添加到教师模型中,教师模型的输入由非优势特征表示向量和优势特征表示向量拼接得到:
3.1.2 教师和学生模型
给定一个样本,其label,和分别表示学生和教师模型的输入。在训练过程中,将输入到教师模型中得到样本的logit ,然后经过sigmoid激活函数得到样本的pCTR 。对于教师模型,我们采用pointwise LogLoss作为损失函数:
不同于教师模型,学生模型仅使用非优势特征表示向量作为输入来得到样本的pCTR ,这里是学生模型的logit。学生模型将使用两个损失进行训练,一个与教师模型一样,以为监督信号通过LogLoss优化。另一个损失是知识蒸馏损失,用于从教师模型中蒸馏知识。因为教师模型引入了优势特征,其具有比学生模型更好的预测效果,可以指导学生模型进行学习。学生模型的最终损失构成如下:
这里是平衡LogLoss和蒸馏损失的超参数。
3.2 listwise优势特征蒸馏
3.2.1 存在的挑战
如上所述,对于学生模型,之前的PFD方法使用pointwise LogLoss作为蒸馏损失:
然而,在推荐系统中,一个物品的点击率显著地受同页面内其他物品的影响。而pointwise蒸馏损失基于同分布假设独立地对待每一个物品,并没有考虑同一展示页中物品预测分的相对顺序信息,这就导致pointwise蒸馏损失不足以蒸馏教师模型的排序能力。
另一方面,listwise损失以商品列表为单位进行优化,天然考虑了同一展示页中物品预测分的相对顺序信息。然而,我们实际中发现尽管相较于pointwise蒸馏损失直接使用listwise损失作为蒸馏损失可以大幅蒸馏教师模型的排序能力,但这种方式使得学生模型输出的pCTR失去了概率意义,出现预估不准的问题。实际生产中,准度对于CTR预估模型也尤为重要,因此,我们需要准度兼容的listwise蒸馏损失,即在提升模型排序能力的同时保持模型准度。
3.2.2 准度兼容的listwise蒸馏
我们首先形式化定义了蒸馏损失的准度兼容性质并分析了pointwise LogLoss蒸馏损失和常用的listwise损失作为蒸馏损失的准度兼容性质,然后我们给出了准度兼容的listwise蒸馏损失的设计方案。
定义1. 一个蒸馏损失是准度兼容的,如果对于任意候选物品,蒸馏损失在学生和教师模型的LogLoss损失实现全局最小的时候也同时实现全局最小。
可以证明pointwise LogLoss蒸馏损失是准度兼容的。具体来说,对于每个session,令表示其中第i个样本的真实点击率。假设从样本的真实标签分布中取个样本,第个样本的标记是。可以推导出学生模型和教师模型的LogLoss损失分别在 和 时达到最小,其中在时 。因此,教师和学生模型的LogLoss损失总能够在的时候同时实现全局最小。对于LogLoss蒸馏损失,它也在时最小,因此根据定义1它满足准度兼容性质。
以常用的listwise损失ListNet [5] 为例,可以证明它在作为蒸馏损失的时候不是准度兼容的:
这里是包含样本的session中全部商品的数量。根据微分法则,可以知道ListNet蒸馏损失在如下情况下实现全局最小:
可以观察到,蒸馏损失在学生和教师模型的LogLoss损失都实现全局最小的情况下并没被最小化(即),因此不满足准度兼容的性质。
为了使listwise蒸馏损失满足准度兼容性质,我们提出CLID蒸馏损失框架。具体来说,对于蒸馏损失,我们首先将和映射到概率单纯形上来构建教师模型预测分布和学生模型预测分布:
这些概率编码了样本排在商品列表顶部的概率。给定这两个分布,CLID使用交叉熵损失惩罚它们之间的差异:
根据微分法则,可以得到该蒸馏损失在如下情况下全局最小:
可以观察到当学生和教师模型的LogLoss损失都全局最小的时候,蒸馏损失也是最小的。因此,我们所设计的CLID listwise蒸馏损失满足准度兼容性质,故而能够在大幅蒸馏教师模型排序能力的同时保持学生模型的准度不被破坏。
4. 实验
4.1 实验设置
我们使用了两个经典的Learning-To-Rank公开数据集Web30K和Istella-S,以及一个收集自阿里妈妈展示广告系统的生产数据集用以验证CLID方法的有效性。采用的对比方法如下:
Base:该方法将非优势特征作为输入并用LogLoss损失进行优化。
PriDropOut [7]: 该方法训练时为优势特征构建浅层网络,浅层网络的logits与主网络的logits相加来计算pCTR用于训练,训练时采用dropout的方式模拟在线拿不到优势特征的情况。当在线推理时,浅层网络被丢弃,由主网络的logits计算pCTR。
PAL [8]: 该方法也是在训练时为优势特征构建浅层网络,训练时,通过浅层网络和主网络输出分数相乘的方式计算pCTR。当在线推理时,也是丢弃浅层网络,用主网络的输出分数作为pCTR。
Base+Pointwise [1,2,9]:基于pointwise蒸馏损失的PFD方法。
Base+ListMLE [6]:基于listwise蒸馏损失的PFD方法,采用ListMLE损失作为蒸馏损失。
Base+ListNet [5]:基于listwise蒸馏损失的PFD方法,采用ListNet损失作为蒸馏损失。
在公开数据集上,我们采用NDCG@10作为排序能力的评价指标,ECE和LogLoss作为准度的评价指标。在生产数据集上,我们采用GAUC作为排序能力的评价指标,LogLoss作为准度的评价指标。NDCG@10(GAUC)值越大代表模型排序能力越好,ECE(LogLoss)值越小代表模型准度越好。
4.2 实验
4.2.1 实验效果

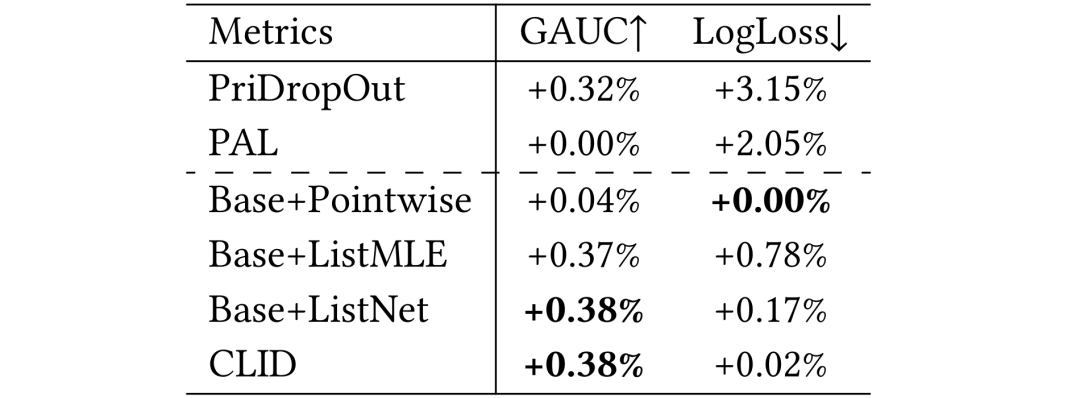
以上分别是公开数据集和生产数据集上的实验效果,从中我们可以看出:
(1)基于listwise的PFD方法在排序能力上一致地比基于pointwise的方法表现要好。这一事实证明了listwise蒸馏损失能够考虑推荐数据的非独立同分布特征,学到教师模型预测分布的相对顺序信息。然而Base+ListMLE和Base+ListNet方法由于不满足准度兼容性质,破坏了模型的准度。
(2) CLID在所有方法中取得了ranking能力同时确保了模型的准度不被破坏。这一观察证实了CLID中设计的listwise蒸馏损失的优越性。
(3) PFD方法通过解决训练-测试不一致问题有效地保持了模型的泛化性。这一结论可由非PFD方法(PAL和PriDropOut方法)的不稳定的排序性能提升和破坏的准度来证明。因为这两个非PFD方法的浅层网络在线上推理时会被丢弃,所以导致了训练和测试时pCTR不一致问题。这个不一致破坏了模型输出的概率意义,给学生模型造成了巨大的准度下降。
通过上述分析,我们证明了CLID方法能够很好地蒸馏教师模型的排序能力,同时保持学生模型的准度。
4.2.2 权重分析

我们在公开数据集上分析了CLID的权重比 对学生模型排序能力和准度的影响,我们从权重比集合中进行检验,图5画出了NDCG@10和-LogLoss指标随权重比变化的趋势,权重比越大表示蒸馏损失越主导模型参数优化过程,NDCG@10和-LogLoss越大证明模型性能越好。我们观察到模型的准度和排序能力在两个数据集上都呈现先增加后降低的趋势。这是因为权重比过大会削弱LogLoss损失的贡献,该损失直接影响准度,因此造成了模型准度下降;另一方面,蒸馏损失权重过大可能使得学生模型从教师模型中学到了一些噪声,从而造成了次优的排序性能。因此,在实际生产中我们推荐使用一个折中的权重比。
5. 总结和展望
我们针对PFD方法常用pointwise LogLoss蒸馏损失的不足,提出了准度兼容的listwise蒸馏框架CLID。我们理论分析发现,相比于经典的listwise损失,CLID满足准度兼容性质,因此在蒸馏教师模型排序能力的同时能够保持学生模型的准度不被破坏,阿里妈妈生产数据集上的实验结果证明了CLID框架的优势。
在实验中,我们也发现了未来几个值得探索的方向,首先目前CLID的学生和教师模型都分别使用pointwise loss学习用户真实点击行为,如何在学生和教师模型中引入ranking loss,并设计准度兼容的蒸馏损失是一个有意思的研究方向,事实上,我们发现可以同时使用JRC [3]提升教师模型自身的排序能力和使用CLID提升学生模型蒸馏教师模型排序的能力,二者在效果提升方面不存在重叠。其次,目前的CLID的蒸馏损失主要基于RCR [4]进行设计(便于理论推导),未来我们会将更多的scale-calibrated ranking loss融入到CLID的框架中。
▐ 参考文献
[1] Xu C, Li Q, Ge J, et al. Privileged features distillation at taobao recommendations. KDD 2020.
[2] Yang S, Sanghavi S, Rahmanian H, et al. Toward Understanding Privileged Features Distillation in Learning-to-Rank. NeurIPS. 2022.
[3] Sheng X R, Gao J, Cheng Y, et al. Joint Optimization of Ranking and Calibration with Contextualized Hybrid Model. KDD 2023.
[4] Bai A, Jagerman R, Qin Z, et al. Regression Compatible Listwise Objectives for Calibrated Ranking with Binary Relevance. CIKM 2023.
[5] Cao Z, Qin T, Liu T Y, et al. Learning to rank: from pairwise approach to listwise approach. ICML 2007.
[6] Xia F, Liu T Y, Wang J, et al. Listwise approach to learning to rank: theory and algorithm. ICML 2008. [7] Zhang Y, Yan L, Qin Z, et al. Towards Disentangling Relevance and Bias in Unbiased Learning to Rank. KDD 2023.
[8] Guo H, Yu J, Liu Q, et al. PAL: a position-bias aware learning framework for CTR prediction in live recommender systems. RecSys 2019.
[9] Liu C, Li Y, Zhu J, et al. Position Awareness Modeling with Knowledge Distillation for CTR Prediction. RecSys 2022.
END

也许你还想看
丨展示广告多模态召回模型:混合模态专家模型
丨深度点击率预估模型的One-Epoch过拟合现象剖析
丨基于特征自适应的多场景预估建模
关注「阿里妈妈技术」,了解更多~
喜欢要“分享”,好看要“点赞”哦ღ~
这篇关于展示广告预估模型优势特征应用实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





