本文主要是介绍RAG_Example,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
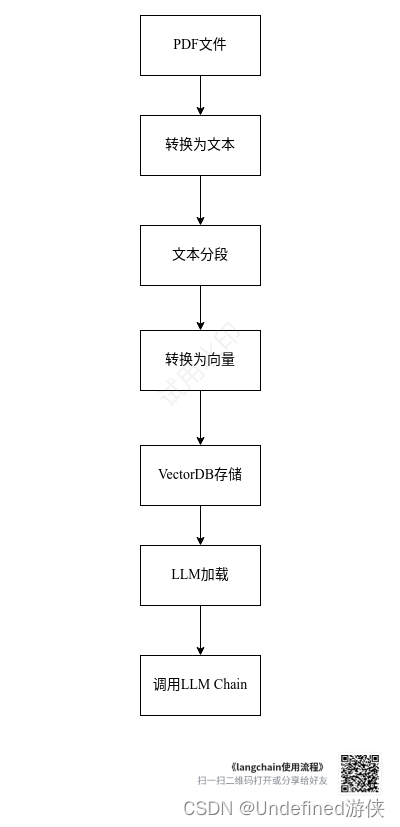
今天尝试基于langchain进行LLM RAG搭建,感觉使用难度没有想象中大。具体流程参考末尾链接。
主要流程包括下面几个模块,每一个模块都有很多选择,而不是唯一解。
但这里可以感受到潜在的几个问题
1. 文本转换过程中,PDF的信息可能会丢失和损坏。比如对于一个只包含很多小标题的文档,我怀疑是否能够获得足够多的有效信息。此外,一些文档中的信息,是通过图文结合的方式,这种信息是否能有效获取呢?
2. LLM基座模型的选择比较重要,目前来看,模型可以理解中文,但是不能说中文,这是一个问题,想到的解决方案就是替代基座模型。
3. 目前由于使用不够充分,无法给出结论,但是目前感觉每个环节都可能会出问题。
https://medium.com/@cch.chichieh/rag%E5%AF%A6%E4%BD%9C%E6%95%99%E5%AD%B8-langchain-llama2-%E5%89%B5%E9%80%A0%E4%BD%A0%E7%9A%84%E5%80%8B%E4%BA%BAllm-d6838febf8c4
这篇关于RAG_Example的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!