本文主要是介绍11_从注意力机制到序列处理的革命:Transformer原理详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.1 简介
Transformer是一种深度学习模型,主要用于处理序列数据,尤其是自然语言处理任务,如机器翻译、文本摘要等。该模型由Vaswani等人在2017年的论文《Attention is All You Need》中首次提出,它的出现极大地推动了自然语言处理领域的发展,并逐渐扩展应用到图像识别、音乐生成等多个AI领域。Transformer的核心优势在于其并行处理能力、长距离依赖的高效建模以及对序列数据的强大表达能力。
1.2 整体架构
Transformer模型通常采用编码器-解码器(Encoder-Decoder)结构,但与传统的RNN或LSTM模型不同,它完全基于自注意力(Self-Attention)机制和多层神经网络结构,摒弃了循环神经网络中的序列依赖性,从而实现了高度并行化,提高了训练速度。、
注意力机制详解:10_Transformer预热---注意力机制(Attention)-CSDN博客
编码器(Encoder)
编码器负责接收输入序列并将其转换成一个高级语义表示。每个编码器层包含以下主要组件:
-
自注意力(Self-Attention)层:
- 查询(Query)、键(Key)、值(Value)计算:首先,输入序列的每个位置的嵌入向量会被线性映射为Q、K、V三组向量。
- 注意力权重计算:通过计算Q和K的点积,然后应用softmax函数,得到每个位置上的注意力权重,这代表了序列中各位置的重要性。
- 加权求和:使用上述权重对V向量进行加权求和,得到每个位置的上下文感知表示。
-
层归一化(Layer Normalization):对自注意力层的输出进行归一化,帮助稳定训练过程。
-
残差连接(Residual Connection):自注意力层的输出与原始输入(或前一层的输出)相加,保留原始信息并促进梯度流通。
-
前馈神经网络(Feed Forward Network, FFN):
- 两次线性变换:通常包含两个全连接层,中间夹着一个非线性激活函数(如ReLU),用于学习复杂的特征表示。
- 再次归一化:FFN输出后也会进行层归一化。
解码器(Decoder)
解码器负责根据编码器产生的表示和之前已生成的输出序列部分来生成下一个输出。每个解码器层包含以下组件:
-
自注意力层:与编码器中的自注意力相似,但仅关注解码器自身的输入,帮助捕捉序列内的依赖。
-
编码器-解码器注意力层(Encoder-Decoder Attention):
- 计算:类似于自注意力,但这里的Q来自解码器的前一时刻输出,而K和V来自编码器的输出,这样解码器的每个位置都能关注到输入序列的所有位置。
- 加权求和与归一化:同自注意力层的操作。
-
残差连接与层归一化:与编码器相同,用于稳定训练和加速收敛。
-
前馈神经网络(FFN):与编码器的FFN相同,用于进一步的特征转换。
整体运行路线
-
输入编码:输入序列首先转换为词嵌入,并加上位置编码,形成初始输入向量。
-
编码器处理:输入向量通过编码器的每一层,每层中自注意力机制帮助模型理解输入序列的上下文关系,FFN则学习更复杂的特征表示。
-
解码器处理:
- 解码器逐步生成输出序列。每一步,解码器的自注意力层处理当前已生成的部分序列,编码器-解码器注意力层则利用编码器的输出信息,指导下一步的生成。
- 随着每一步的进行,解码器不断生成新的输出,并将其反馈给下一个时间步的解码器自注意力层。
-
输出:解码器的最后一层输出经过一个线性层和softmax函数,转换为预测的下一个单词的概率分布。

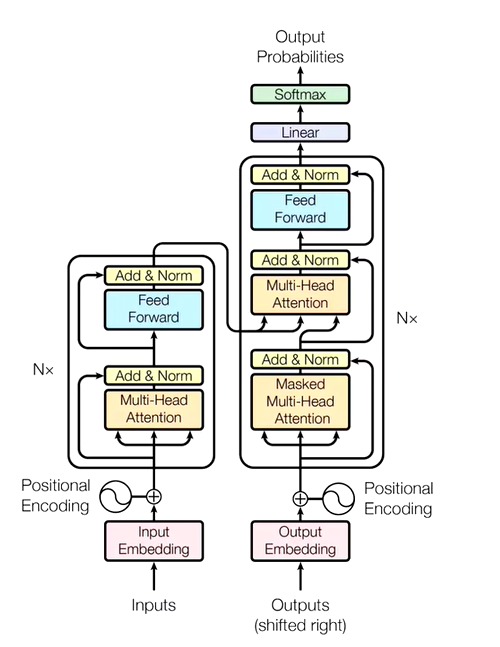
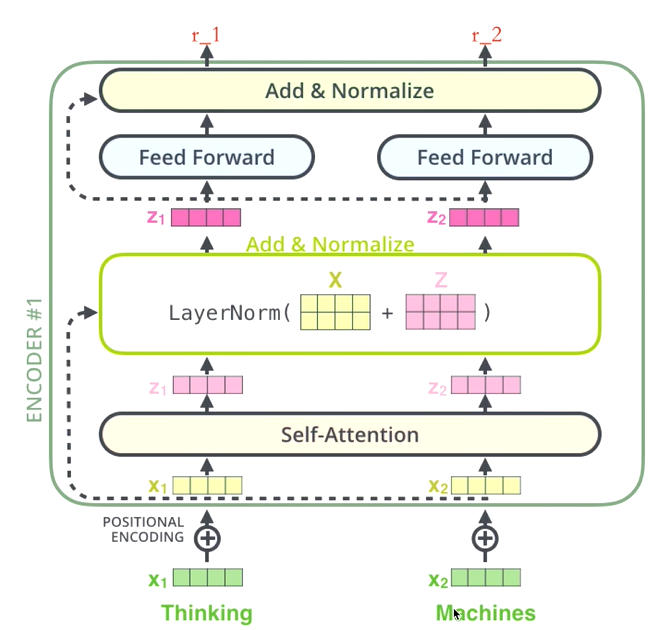
1.3 编码器
Transformer的编码器是其架构中的关键组成部分,负责将输入序列转换为一系列隐藏表示,这些表示携带了输入序列的语义信息。编码器由多个相同的层(通常称为编码器层)堆叠而成,每一层又可以细分为几个子层,主要包括自注意力(Self-Attention)机制、层归一化(Layer Normalization)、残差连接(Residual Connections),以及前馈神经网络(Feed Forward Networks, FFNs)。下面是编码器及其各部分的详细介绍:
编码器层结构
-
输入Embedding与位置编码(Positional Encoding)
- 输入Embedding:首先,输入序列的每个词被映射到一个高维向量空间中,这是通过查找预定义的词嵌入表实现的,每个词都有一个固定的向量表示。
- 位置编码:为了使模型能够区分不同位置的词,会为每个词的位置添加一个唯一的向量,这个向量包含了词在序列中的位置信息。位置编码通常是基于正弦和余弦函数计算的,确保了模型对序列长度的不变性。
-
自注意力(Self-Attention)
- 自注意力机制允许输入序列中的每一个词同时“关注”到其他所有词,从而捕捉序列中的长距离依赖关系。
- 每个位置的词首先被映射为查询(Q)、键(K)和值(V)向量。
- 计算查询与键之间的点积注意力分数,经过softmax函数归一化,得到每个位置的注意力权重。
- 使用这些权重加权求和值向量,得到每个位置的上下文感知表示。
-
多头注意力(Multi-Head Attention)
- 实际操作中,自注意力机制常常以多头的形式实现,即将Q、K、V向量分别分割成几个部分,独立进行注意力计算,最后再合并结果。这样可以使得模型能够并行地关注不同位置的不同表示子空间,增强模型的表达能力。
-
层归一化(Layer Normalization)
- 自注意力层的输出会通过层归一化,目的是对输入数据进行标准化处理,使其具有稳定的分布,有助于训练的稳定性。
-
残差连接(Residual Connections)
- 自注意力层(可能包括多头注意力后的组合)的输出会与该层的输入(即上一层的输出或最初的嵌入+位置编码)相加,保留原始信息并帮助梯度顺利传播。
-
前馈神经网络(Feed Forward Network, FFN)
- 通常包含两个线性层,中间夹着一个激活函数(如ReLU),用于进一步提取特征和转换表示。
- 第一个线性层增加模型的非线性,第二个线性层则用于降低维度,保持或减少输出的复杂度。
-
第二次层归一化
- FFN之后再次进行层归一化,确保输出稳定并准备进入下一层或作为最终输出。
层间堆叠
多个这样的编码器层按顺序堆叠,每一层都会对前一层的输出进行更深层次的特征提取和表示学习,使得模型能够逐步构建出更加抽象和丰富的输入序列表示。
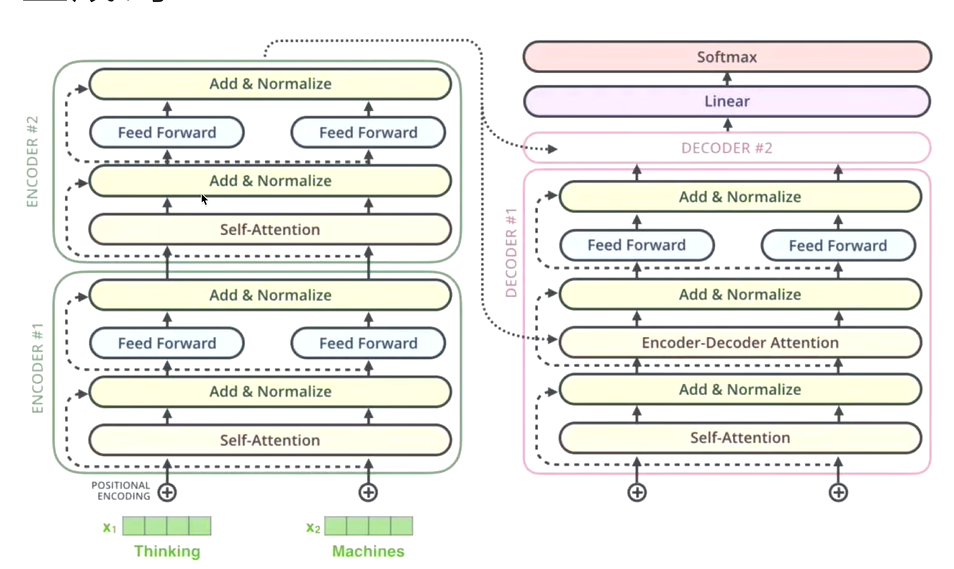
1.4 解码器
Transformer的解码器是其架构的另一半,负责根据编码器提供的输入序列的上下文信息生成目标序列。解码器同样是由多个相同的解码器层堆叠而成,每层包含自注意力机制、编码器-解码器注意力机制、层归一化和前馈神经网络等关键组件。以下是解码器及其各部分的详细介绍:
解码器层结构
-
自注意力(Self-Attention)
- 解码器中的自注意力机制与编码器相似,但有一个重要区别:为了保证自回归特性(即预测的词只能依赖于它前面的词),解码器在计算自注意力时会使用掩码(Masking),遮住当前位置之后的词,确保每个位置只能看到它之前的词。这通常通过在计算注意力权重时为未来位置设置负无穷大值来实现,使得softmax后这些位置的权重为0。
-
编码器-解码器注意力(Encoder-Decoder Attention)
- 这一层让解码器能够关注到编码器输出的每个位置,从而获取输入序列的全局信息。解码器的每个位置会产生一组查询向量,这些查询向量会与编码器输出的所有键(K)和值(V)向量进行匹配,计算注意力权重,然后加权求和得到解码器每个位置的上下文表示。这一步是解码器与编码器信息交流的关键,帮助生成与输入序列相关的输出。
-
层归一化(Layer Normalization)
- 同编码器一样,自注意力层和编码器-解码器注意力层的输出都会经过层归一化,以稳定训练过程并加速收敛。
-
残差连接(Residual Connections)
- 解码器中每个子层(自注意力、编码器-解码器注意力、FFN)的输出会与该层的输入相加,以保留低层信息并帮助梯度传播。
-
前馈神经网络(Feed Forward Network, FFN)
- 与编码器中的FFN类似,解码器中的FFN也包含两个线性层和一个激活函数,用于进一步处理和转换信息。
特殊之处
-
自回归生成:在生成模式下,解码器每一步生成一个词,并将此词添加到输入序列中,供下一步生成使用,这一过程是逐步进行的。训练时通常使用教师强制(Teacher Forcing)策略,即直接用真实的下一个词作为输入而非模型的预测,以提高训练效率和稳定性。
-
位置编码:和编码器一样,解码器的输入也需要加上位置编码,以区分不同时间步的位置信息。
-
并行与串行处理:虽然Transformer的编码器部分可以并行处理所有输入位置,解码器由于自回归的特性,其内部的自注意力计算是限制并行化的(因为需要按照序列顺序逐个位置生成),但编码器-解码器注意力和FFN层仍然可以并行执行。
1.5 为什么解码器需要掩码注意力
解码器需要掩码注意力机制主要是为了维持自回归(Autoregressive)属性,这是生成任务(如文本生成、机器翻译等)中的一个关键要求。自回归意味着每一个时间步的输出只依赖于它之前的时间步的输出,这样可以确保模型在生成序列时遵循正确的顺序。具体来说,掩码注意力机制在解码器中的作用体现在以下几个方面:
-
防止信息泄露(Future Information Leakage):在自注意力层中,如果没有掩码,解码器在生成当前位置的词时,可能会“看到”后面未生成的词,这违反了自回归原则。通过应用掩码,特别是“未来遮挡”(future masking),模型会“屏蔽”当前位置之后的所有位置,确保预测当前位置的输出时不考虑未来的上下文信息。
-
确保逐位生成:掩码机制允许模型在生成序列时,每次迭代只基于已经生成的部分,这有助于模型理解和学习到序列中元素间的依赖关系,从而更准确地预测下一个词。
-
训练与推理的一致性:在训练时使用掩码注意力可以帮助模型学会合理的生成顺序,这与实际推理过程中模型只能访问到目前为止已生成的信息是一致的。如果训练时不使用掩码,模型可能无法正确学习到这种依赖关系,导致推理时生成不合理的序列。
-
简化学习任务:掩码机制简化了学习问题,使得模型能够在每个时间步集中精力学习如何基于历史信息做出最佳预测,而不是试图解析复杂的时间依赖关系。
1.6为什么解码器的交叉注意力模块的KV矩阵来自编码器
解码器的交叉注意力模块的设计中,其Key(K)和Value(V)矩阵来源于编码器,这是基于Seq2Seq(Sequence to Sequence)模型的核心思想和Transformer架构的特点,具体原因包括:
-
传递编码信息:编码器负责捕获输入序列(如源语言句子)的语义信息,并将其编码为一系列高维向量。这些向量不仅包含了每个输入位置的语义,还包括了输入序列中的上下文依赖。将编码器的输出作为解码器交叉注意力模块的K和V矩阵,可以让解码器在生成目标序列的每个词时,都能够访问到源序列的完整上下文信息。
-
促进并行计算:Transformer架构利用自注意力机制,允许在计算过程中高度并行化。通过将编码器输出固定为解码器交叉注意力中的K和V,可以在解码阶段的每一步都独立地计算出与编码信息相关的注意力权重,这非常适合并行处理,加速训练和推断过程。
-
维护时序一致性:在解码器生成目标序列的过程中,每个时间步的Query(Q)来自前一时间步的解码器输出或者初始的解码器状态(在没有先前输出时)。通过查询编码器的K和V矩阵,模型能够在生成每个目标词时,基于已经编码的输入序列选择性地聚焦相关信息,从而维护了从输入到输出的时序一致性,这对于生成高质量的、符合逻辑的输出序列至关重要。
-
增强注意力机制的有效性:交叉注意力机制使得解码器能够根据当前生成进度的不同需求,动态地调整对输入序列不同部分的关注。这种灵活性允许模型在生成特定词汇时,侧重考虑输入序列中的相关部分,提高了翻译或生成任务的准确性。
1.7 Transformer的输出和输入是什么
输入
-
编码器(Encoder)的输入:
- 编码器接收一个序列作为输入,比如一个句子。这个序列首先被转换成一系列token(分词),每个token对应一个唯一的ID。然后,这些ID通过一个嵌入层(Embedding Layer)转换成高维向量,代表每个单词的语义信息。除此之外,还会给每个位置添加位置编码(Positional Encoding),以告知模型单词在序列中的位置信息。因此,编码器的输入是一个形状为
[batch_size, sequence_length, embedding_dim]的张量,其中sequence_length是序列的长度,embedding_dim是嵌入向量的维度。
- 编码器接收一个序列作为输入,比如一个句子。这个序列首先被转换成一系列token(分词),每个token对应一个唯一的ID。然后,这些ID通过一个嵌入层(Embedding Layer)转换成高维向量,代表每个单词的语义信息。除此之外,还会给每个位置添加位置编码(Positional Encoding),以告知模型单词在序列中的位置信息。因此,编码器的输入是一个形状为
-
解码器(Decoder)的输入:
- 解码器的输入也是序列形式,但与编码器不同,它不仅要处理目标序列的单词,还要考虑已经生成的部分序列。解码器的自注意力部分(Self-Attention)只关注已生成的词(通过使用掩码遮盖未来的信息),而交叉注意力(Cross-Attention)部分则会使用编码器的输出作为K和V矩阵,来获取源序列的信息。解码器的输入同样经过嵌入层和位置编码处理,形状同样是
[batch_size, target_sequence_length, embedding_dim]。
- 解码器的输入也是序列形式,但与编码器不同,它不仅要处理目标序列的单词,还要考虑已经生成的部分序列。解码器的自注意力部分(Self-Attention)只关注已生成的词(通过使用掩码遮盖未来的信息),而交叉注意力(Cross-Attention)部分则会使用编码器的输出作为K和V矩阵,来获取源序列的信息。解码器的输入同样经过嵌入层和位置编码处理,形状同样是
输出
-
编码器(Encoder)的输出:
- 编码器的最后一个自注意力和前馈网络(Feed Forward Network, FFN)层之后,会产生一系列高维向量,每个向量对应输入序列中的一个位置。这些向量综合了序列中的上下文信息,形状为
[batch_size, sequence_length, model_dim],其中model_dim是模型的隐藏层维度。这些输出会被解码器的交叉注意力模块使用。
- 编码器的最后一个自注意力和前馈网络(Feed Forward Network, FFN)层之后,会产生一系列高维向量,每个向量对应输入序列中的一个位置。这些向量综合了序列中的上下文信息,形状为
-
解码器(Decoder)的输出:
- 解码器的输出经过一个线性层(Linear Layer)和softmax函数处理,转化为一个概率分布,表示下一个预测词的可能性。形状为
[batch_size, target_vocab_size],其中target_vocab_size是目标词汇表的大小。在生成任务中,模型通常会选择概率最高的词作为输出;而在序列到序列的翻译或文本生成任务中,这一过程会重复进行,每次为序列增加一个新词,直到达到终止条件(如遇到结束标记)。
- 解码器的输出经过一个线性层(Linear Layer)和softmax函数处理,转化为一个概率分布,表示下一个预测词的可能性。形状为
2.pytorch复现
# Author:SiZhen
# Create: 2024/6/12
# Description: pytorch构建一个transformer框架
import copy
import math
import torch
import numpy as np
import torch.nn as nn
import torch.nn as nn
import torch.nn.functional as F
from collections import namedtuple
from torch.autograd import Variable#克隆n次
def clones(module,n):return nn.ModuleList([copy.deepcopy(module)for _ in range(n)])class FeatEmbedding(nn.Module):def __init__(self, d_feat, d_model, dropout):super(FeatEmbedding, self).__init__()self.video_embeddings = nn.Sequential(LayerNorm(d_feat),nn.Dropout(dropout),nn.Linear(d_feat, d_model))def forward(self, x):return self.video_embeddings(x)class TextEmbedding(nn.Module):def __init__(self, vocab_size, d_model):super(TextEmbedding, self).__init__()self.d_model = d_modelself.embed = nn.Embedding(vocab_size, d_model)def forward(self, x):return self.embed(x) * math.sqrt(self.d_model)#层归一化
class LayerNorm(nn.Module):def __init__(self,feature,eps=1e-6):super(LayerNorm, self).__init__()#feature 是self-attention中x的大小self.a_2 = nn.Parameter(torch.ones(feature))self.b_2 = nn.Parameter(torch.zeros(feature))self.eps = eps #epsilon,一个很小的正数,用来避免除以零或者其他数值稳定性问题。def forward(self,x):mean = x.mean(-1,keepdim=True)std = x.std(-1,keepdim=True)return self.a_2*(x-mean)/math.sqrt(std+self.eps) + self.b_2#残差和层归一化
class SublayerConnection(nn.Module):def __init__(self,size,dropout= 0.1):super(SublayerConnection, self).__init__()#层归一化self.layer_norm = LayerNorm(size)#随机失活self.dropout = nn.Dropout(p=dropout)def forward(self,x,sublayer):#x:self-attention的输入,sublayer:self-attention层return self.dropout(self.layer_norm(x+sublayer(x)))#自注意力机制
def self_attention(query,key,value,dropout=None,mask=None):d_k = query.size(-1)scores = torch.matmul(query,key.transpose(-2,-1))/math.sqrt(d_k)if mask is not None:mask.cuda()scores = scores.masked_fill(mask==0,-1e9)self_attn = F.softmax(scores,dim=-1)if dropout is not None :self_attn = dropout(self_attn)return torch.matmul(self_attn,value),self_attn#多头自注意力机制
class MultiHeadAttention(nn.Module):def __init__(self,head,d_model,dropout=0.1):super(MultiHeadAttention, self).__init__()#d_model是输入的维度assert (d_model % head == 0)self.d_k = d_model // head #每个头分配到的维度数,空间上并行学习,增加模型的表达能力self.head = headself.d_model = d_modelself.linear_query = nn.Linear(d_model,d_model)self.linear_key = nn.Linear(d_model,d_model)self.linear_value = nn.Linear(d_model,d_model)# 自注意力机制的QKV同源,线性变换self.linear_out = nn.Linear(d_model,d_model)self.dropout = nn.Dropout(p=dropout)self.attn = Nonedef forward(self,query,key,value,mask=None):if mask is not None:mask = mask.unsqueeze(1)n_batch = query.size(0)#需要对X切分成多头query = self.linear_query(query).view(n_batch,-1,self.head,self.d_k).tranpose(1,2) #[b,8,32,64]key = self.linear_key(key).view(n_batch,-1,self.head,self.d_k).tranpose(1,2) #[b,8,28,64]value = self.linear_value(value).view(n_batch,-1,self.head,self.d_k).tranpose(1,2) #[b,8,28,64]x,self.attn = self_attention(query,key,value,dropout=self.dropout,mask=mask)x = x.transpose(1,2).contiguous().view(n_batch,-1,self.head*self.d_k) #[b,32*8,512]return self.linear_out(x)#位置编码
class PositionalEncoding(nn.Module):def __init__(self,dim,dropout,max_len=5000):super(PositionalEncoding, self).__init__()if dim % 2 !=0:raise ValueError("Cannot use sin/cos positional encoding with""odd dim (got dim = {:d})".format(dim))#位置编码pe : PE(pos,2i/2i+1) = sin/cos (pos/10000^{2i/d_{model}})pe = torch.zeros(max_len,dim) #max_len是解码器生成句子的最长的长度,假设是10position = torch.arange(0,max_len).unsqueeze(1)div_term = torch.exp((torch.arange(0,dim,2,dtype=torch.float)*-(math.log(10000.0)/dim)))pe[:,0::2]=torch.sin(position.float()*div_term)pe[:,1::2] = torch.cos(position.float()*div_term)pe = pe.unsqueeze(1)self.register_buffer('pe',pe)self.dropout = nn.Dropout(p=dropout)self.dim = dimdef forward(self,emb,step = None):#emb:初始的xemb = emb*math.sqrt(self.dim)if step is None :emb = emb+self.pe[:emb.size(0)]else:emb = emb+self.pe[step]emb = self.drop_out(emb)return emb#前馈神经网络feedforward
class PositionWiseFeedForward(nn.Module):def __init__(self,d_model,d_ff,dropout=0.1):super(PositionWiseFeedForward, self).__init__()self.w_1 = nn.Linear(d_model,d_ff)self.w_2 = nn.Linear(d_ff,d_model)self.layer_norm = nn.LayerNorm(d_model,eps=1e-6)self.dropout_1 = nn.Dropout(dropout)self.relu = nn.ReLU()self.dropout_2 = nn.Dropout(dropout)def forward(self,x):inter = self.dropout_1(self.relu(self.w_1(self.layer_norm(x))))output = self.dropout_2(self.w_2(inter))return output#Linear和softmax
class Generator(nn.Module):def __init__(self,d_model,vocab_size):super(Generator, self).__init__()self.linear = nn.Linear(d_model,vocab_size)def forward(self,x):return F.log_softmax(self.linear(x),dim=-1)#掩码自注意力机制
def pad_mask(src,r2l_trg,trg,pad_idx):if isinstance(src,tuple):if len(src)==4:src_image_mask = (src[0][:,:,0]!=pad_idx).unsqueeze(1)src_motion_mask=(src[1][:,:,0]!=pad_idx).unsqueeze(1)src_object_mask = (src[2][:,:,0]!=pad_idx).unsqueeze(1)src_rel_mask = (src[3][:, :, 0] != pad_idx).unsqueeze(1)enc_src_mask=(src_image_mask,src_motion_mask,src_object_mask,src_rel_mask)dec_src_mask_1=src_image_mask & src_motion_maskdec_src_mask_2=src_image_mask & src_motion_mask &src_object_mask & src_rel_maskdec_src_mask =(dec_src_mask_1,dec_src_mask_2)src_mask = (enc_src_mask,dec_src_mask)if len(src)==3:src_image_mask = (src[0][:, :, 0] != pad_idx).unsqueeze(1)src_motion_mask = (src[1][:, :, 0] != pad_idx).unsqueeze(1)src_object_mask = (src[2][:, :, 0] != pad_idx).unsqueeze(1)enc_src_mask = (src_image_mask, src_motion_mask, src_object_mask)dec_src_mask = src_image_mask &src_motion_masksrc_mask = (enc_src_mask,dec_src_mask)if len(src)==2:src_image_mask = (src[0][:, :, 0] != pad_idx).unsqueeze(1)src_motion_mask = (src[1][:, :, 0] != pad_idx).unsqueeze(1)enc_src_mask = (src_image_mask, src_motion_mask)dec_src_mask = src_image_mask &src_motion_masksrc_mask = (enc_src_mask,dec_src_mask)else:src_mask = (src[:,:,0]!= pad_idx).unsqueeze(1)if trg is not None:if isinstance(src_mask,tuple):trg_mask = subsequent_mask(trg.size(1)).type_as(src_image_mask.data)trg_mask = (trg != pad_idx).unsqueeze(1).type_as(src_image_mask.data)else:return src_maskdef subsequent_mask(size):attn_shape = (1,size,size)mask = np.triu(np.ones(attn_shape),k=1).astype('uint8')return (torch.from_numpy(mask)==0).cuda()#编码器模块
class EncoderLayer(nn.Module):def __init__(self,size,attn,feed_forward,dropout=0.1):super(EncoderLayer, self).__init__()self.attn = attnself.feed_forward = feed_forwardself.sublayer_connection = clones(SublayerConnection(size,dropout),2)def forward(self,x,mask):x = self.sublayer_connection[0](x,lambda x:self.attn(x,x,x,mask))return self.sublayer_connection[1](x,self.feed_forward)#整个编码器
class Encoder(nn.Module):def __init__(self,n,encoder_layer):super(Encoder, self).__init__()self.encoder_layer = clones(encoder_layer,n)def forward(self,x,src_mask):for layer in self.encoder_layer:x = layer(x,src_mask)return x#解码器模块
class DecoderLayer(nn.Module):def __init__(self,size,attn,feed_forward,sublayer_num,dropout=0.1):super(DecoderLayer, self).__init__()self.attn = attnself.feedforward = feed_forwardself.sublayer_connection = clones(SublayerConnection(size,dropout),sublayer_num)def forward(self,x,memory,src_mask,trg_mask,r2l_memory=None,r2l_trg_mask=None):x = self.sublayer_connection[0](x,lambda x:self.attn(x,x,x,trg_mask))x = self.sublayer_connection[1](x,lambda x:self.attn(x,memory,memory,src_mask))if r2l_memory is not None:x = self.sublayer_connection[-2](x,lambda x:self.attn(x,r2l_memory,r2l_memory,r2l_trg_mask))return self.sublayer_connection[-1](x,self.feedforward)#双向解码器(右到左)
class R2L_Decoder(nn.Module):def __init__(self,n,decoder_layer):super(R2L_Decoder, self).__init__()self.decoder_layer = clones(decoder_layer,n)def forward(self,x,memory,src_mask,r2l_trg_mask):for layer in self.decoder_layer:x = layer(x,memory,src_mask,r2l_trg_mask)return x#双向解码器(左到右)
class L2R_Decoder(nn.Module):def __init__(self,n,decoder_layer):super(L2R_Decoder, self).__init__()self.decoder_layer = clones(decoder_layer,n)def forward(self,x,memory,src_mask,trg_mask,r2l_memory,r2l_trg_mask):for layer in self.decoder_layer:x = layer(x,memory,src_mask,trg_mask,r2l_memory,r2l_trg_mask)return x#构建Transformer
class ABDTransformer(nn.Module):def __init__(self,vocab,d_feat,d_model,d_ff,n_heads,n_layers,dropout,feature_mode,device = 'cuda',n_heads_big=128):super(ABDTransformer, self).__init__()self.vocab = vocabself.device = deviceself.feature_mode = feature_mode #多模态c = copy.deepcopyattn_no_heads = MultiHeadAttention(0,d_model,dropout)attn = MultiHeadAttention(n_heads,d_model,dropout)attn_big = MultiHeadAttention(n_heads_big,d_model,dropout)feed_forward = PositionWiseFeedForward(d_model,d_ff)if feature_mode == 'one':self.src_embed = FeatEmbedding(d_feat,d_model,dropout)elif feature_mode == "two":self.image_src_embed= FeatEmbedding(d_feat[0],d_model,dropout)self.motion_src_embed = FeatEmbedding(d_feat[1],d_model,dropout)elif feature_mode == 'three':self.image_src_embed = FeatEmbedding(d_feat[0],d_model,dropout)self.motion_src_embed = FeatEmbedding(d_feat[1],d_model,dropout)self.object_src_embed = FeatEmbedding(d_feat[2].d_model,dropout)elif feature_mode == 'four':self.image_src_embed = FeatEmbedding(d_feat[0],d_model,dropout)self.motion_src_embed = FeatEmbedding(d_feat[1],d_model,dropout)self.object_src_embed = FeatEmbedding(d_feat[2],d_model,dropout)self.rel_src_embed = FeatEmbedding(d_feat[3],d_model,dropout)self.trg_embed = TextEmbedding(vocab.n_vocabs,d_model)self.pos_embed = PositionalEncoding(d_model,dropout)self.encoder = Encoder(n_layers,Encoder(d_model,c(attn),c(feed_forward),dropout))self.r2l_decoder = R2L_Decoder(n_layers,DecoderLayer(d_model,c(attn),c(feed_forward),sublayer_num=3,dropout=dropout))self.l2r_decoder = L2R_Decoder(n_layers,DecoderLayer(d_model,c(attn),c(feed_forward),sublayer_num=4,dropout=dropout))self.generator = Generator(d_model,vocab.n_vocabs)def encode(self, src, src_mask, feature_mode_two=False):if self.feature_mode == 'two':x1 = self.image_src_embed(src[0])x1 = self.pos_embed(x1)x1 = self.encoder_big(x1, src_mask[0])x2 = self.motion_src_embed(src[1])x2 = self.pos_embed(x2)x2 = self.encoder_big(x2, src_mask[1])return x1 + x2if feature_mode_two:x1 = self.image_src_embed(src[0])x1 = self.pos_embed(x1)x1 = self.encoder_big(x1, src_mask[0])x2 = self.motion_src_embed(src[1])x2 = self.pos_embed(x2)x2 = self.encoder_big(x2, src_mask[1])return x1 + x2if self.feature_mode == 'one':x = self.src_embed(src)x = self.pos_embed(x)return self.encoder(x, src_mask)elif self.feature_mode == 'two':x1 = self.image_src_embed(src[0])x1 = self.pos_embed(x1)x1 = self.encoder_big(x1, src_mask[0])x2 = self.motion_src_embed(src[1])x2 = self.pos_embed(x2)x2 = self.encoder_big(x2, src_mask[1])return x1 + x2elif self.feature_mode == 'three':x1 = self.image_src_embed(src[0])x1 = self.pos_embed(x1)x1 = self.encoder(x1, src_mask[0])x2 = self.motion_src_embed(src[1])x2 = self.pos_embed(x2)x2 = self.encoder(x2, src_mask[1])x3 = self.object_src_embed(src[2])x3 = self.pos_embed(x3)x3 = self.encoder(x3, src_mask[2])return x1 + x2 + x3elif self.feature_mode == 'four':x1 = self.image_src_embed(src[0])x1 = self.pos_embed(x1)x1 = self.encoder(x1, src_mask[0])x2 = self.motion_src_embed(src[1])x2 = self.pos_embed(x2)x2 = self.encoder(x2, src_mask[1])x3 = self.object_src_embed(src[2])# x3 = self.pos_embed(x3)x3 = self.encoder(x3, src_mask[2])# x3 = self.encoder_no_attention(x3, src_mask[2])x4 = self.rel_src_embed(src[3])# x4 = self.pos_embed(x4)# x4 = self.encoder_no_# heads(x4, src_mask[3])x4 = self.encoder_no_attention(x4, src_mask[3])# x4 = self.encoder(x4, src_mask[3])return x1 + x2 + x3 + x4def r2l_decode(self, r2l_trg, memory, src_mask, r2l_trg_mask):x = self.trg_embed(r2l_trg)x = self.pos_embed(x)return self.r2l_decoder(x, memory, src_mask, r2l_trg_mask)def l2r_decode(self, trg, memory, src_mask, trg_mask, r2l_memory, r2l_trg_mask):x = self.trg_embed(trg)x = self.pos_embed(x)return self.l2r_decoder(x, memory, src_mask, trg_mask, r2l_memory, r2l_trg_mask)def forward(self, src, r2l_trg, trg, mask):src_mask, r2l_pad_mask, r2l_trg_mask, trg_mask = maskif self.feature_mode == 'one':encoding_outputs = self.encode(src, src_mask)r2l_outputs = self.r2l_decode(r2l_trg, encoding_outputs, src_mask, r2l_trg_mask)l2r_outputs = self.l2r_decode(trg, encoding_outputs, src_mask, trg_mask, r2l_outputs, r2l_pad_mask)elif self.feature_mode == 'two' or 'three' or 'four':enc_src_mask, dec_src_mask = src_maskr2l_encoding_outputs = self.encode(src, enc_src_mask, feature_mode_two=True)encoding_outputs = self.encode(src, enc_src_mask)r2l_outputs = self.r2l_decode(r2l_trg, r2l_encoding_outputs, dec_src_mask[0], r2l_trg_mask)l2r_outputs = self.l2r_decode(trg, encoding_outputs, dec_src_mask[1], trg_mask, r2l_outputs, r2l_pad_mask)# r2l_outputs = self.r2l_decode(r2l_trg, encoding_outputs, dec_src_mask, r2l_trg_mask)# l2r_outputs = self.l2r_decode(trg, encoding_outputs, dec_src_mask, trg_mask, None, None)else:raise Exception("没有输出")r2l_pred = self.generator(r2l_outputs)l2r_pred = self.generator(l2r_outputs)return r2l_pred, l2r_pred
这篇关于11_从注意力机制到序列处理的革命:Transformer原理详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!