本文主要是介绍【QNN】——Binarized Neural Networks论文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载自:https://blog.csdn.net/liujianlin01/article/details/80917646
使用micronet
论文:https://arxiv.org/pdf/1602.02830.pdf
亮点:NIPS2016
[NIPS ‘16]论文地址:https://arxiv.org/pdf/1602.02830.pdf
代码地址:https://github.com/MatthieuCourbariaux/BinaryNet
这篇文章提出了一个新的网络:二值化网络(BNN),在运行时使用二值权重和激活。在训练时,二值权重和激活用于计算参数梯度。
摘要
我们介绍了一种训练二值化神经网络(BNNs)的方法——在运行时具有二值权值和激活的神经网络。在训练时,使用二值权值和激活值来计算参数梯度。在前向传递过程中,bnn大大减少了内存大小和访问次数,并将大部分算术操作替换为位操作,预计将大幅提高能效。为了验证bnn的有效性,我们在Torch7和Theano框架上进行了两组实验。在这两方面,BNNs都在MNIST、CIFAR-10和SVHN数据集上取得了几乎最先进的结果。最后但并非最不重要的是,我们编写了一个二进制矩阵乘法GPU内核,它可以比使用未优化的GPU内核运行MNIST BNN的速度快7倍,而不会损失任何分类精度。培训和运行BNNs的代码可以在线获得。
1. 二值化准则
文章给出了2种二值化函数。 第一种是决策式二值化:
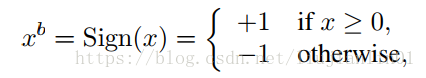
第二种是随机二值化:

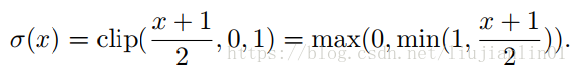
看公式第二种随机二值化更合理,但是每次生成随机数的时候非常耗时,所以文章中采用的第一种方法。
2. 梯度计算
如果采用上面的第一种二值化函数求导的话,那么求导后的值都是0。所以文章采用了一种方法,将sign(x)进行宽松。这样,函数就变成可以求导的了。

2.1 code
- 梯度反向训练的时候,权重和激活值采用了不同的反向策略。权重采用了"直通估计器",激活值采用了Htanh
class BinaryActivation(Function):@staticmethoddef forward(self, input):self.save_for_backward(input)output = torch.sign(input)# ******************** A —— 1、0 *********************#output = torch.clamp(output, min=0)return output@staticmethoddef backward(self, grad_output):input, = self.saved_tensors# *******************ste*********************grad_input = grad_output.clone()# ****************saturate_ste***************grad_input[input.ge(1.0)] = 0grad_input[input.le(-1.0)] = 0'''#******************soft_ste*****************size = input.size()zeros = torch.zeros(size).cuda()grad = torch.max(zeros, 1 - torch.abs(input))#print(grad)grad_input = grad_output * grad'''return grad_input# weight
class BinaryWeight(Function):@staticmethoddef forward(self, input):output = torch.sign(input)return output@staticmethoddef backward(self, grad_output):# *******************ste*********************grad_input = grad_output.clone()return grad_input
3. pytorch中网络定义
可以看到网络的第一层conv是没有二值化的,是在第一层relu的时候才对激活值进行输出二值化。最后一个模块的Conv+bn+relu是没有做量化的。
if layer_counter[0] > 1 and layer_counter[0] < layer_num: # 第一层和最后一层不进行二值化
OrderedDict([('model', Sequential((0): ConvBNReLU((conv): Conv2d(3, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ActivationQuantizer((relu): ReLU(inplace=True)))(1): ConvBNReLU((conv): QuantConv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), groups=2(weight_quantizer): WeightQuantizer())(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ActivationQuantizer((relu): ReLU(inplace=True)))(2): ConvBNReLU((conv): QuantConv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), groups=2(weight_quantizer): WeightQuantizer())(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ActivationQuantizer((relu): ReLU(inplace=True)))(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(4): ConvBNReLU((conv): QuantConv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=16(weight_quantizer): WeightQuantizer())(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ActivationQuantizer((relu): ReLU(inplace=True)))(5): ConvBNReLU((conv): QuantConv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), groups=4(weight_quantizer): WeightQuantizer())(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ActivationQuantizer((relu): ReLU(inplace=True)))(6): ConvBNReLU((conv): QuantConv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), groups=4(weight_quantizer): WeightQuantizer())(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ActivationQuantizer((relu): ReLU(inplace=True)))(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(8): ConvBNReLU((conv): QuantConv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32(weight_quantizer): WeightQuantizer())(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ActivationQuantizer((relu): ReLU(inplace=True)))(9): ConvBNReLU((conv): QuantConv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), groups=8(weight_quantizer): WeightQuantizer())(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ActivationQuantizer((relu): ReLU(inplace=True)))(10): ConvBNReLU((conv): Conv2d(1024, 10, kernel_size=(1, 1), stride=(1, 1))(bn): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(11): AvgPool2d(kernel_size=8, stride=1, padding=0)
))])
总结
- 训练后模型的参数还是浮点数,只是在前向计算的时候,多了一步将conv2d的weight,relu的激活值二值化为{-1,1}的操作,可能计算更快。
- 这样的操作需要推理框架,实际硬件的支持才能加速,不然利用现有的框架与硬件推理速度应该是差不多的。
这篇关于【QNN】——Binarized Neural Networks论文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
