本文主要是介绍【光流】——liteflownet3论文详析与推理代码浅析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
光流,liteflownet
code from:pytorch-liteflownet3
1. 前言
深度学习方法在解决光流估计问题方面取得了巨大的成功。成功的关键在于使用成本量和从粗到细的流推理。然而,当图像中存在部分遮挡或均匀区域时,匹配问题就变得不适态。这将导致成本卷包含异常值,并影响来自它的流解码。此外,从粗到细的流推理还需要精确的流初始化。模糊的对应关系会产生错误的流场,并影响后续层次上的流场推断。在本文中,我们介绍了由两个专门模块组成的LiteFlowNet3深度网络来解决上述挑战。(1)我们通过在流解码之前的自适应调制来修改每个成本向量,从而改善了成本体积中的异常值问题(2),我们通过探索局部光流的一致性,进一步提高了光流的精度。为此,每一种不准确的光流都通过一种新的流场扭曲而被附近位置的精确光流所取代
就是对光流中cost volume模块做了创新,2.提出了一种新的warp,对异常点的光流进行了处理
2. 网络

2.0 Flow Field Deformation
直观地说,我们将每个不精确的光流替换为来自具有相似特征向量的附近位置的精确光流。通过根据计算得到的位移场对流场进行元翘曲(类似于光流,但位移场不再代表对应关系)来实现替换。我们通过使用来自自相关成本体积的置信引导解码来计算位移场。
2.1 encoder
encoder 部分和前面一样,liteflownet系列激活函数都使用leakyrelu
Features((netOne): Sequential((0): Conv2d(3, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))(1): LeakyReLU(negative_slope=0.1))(netTwo): Sequential((0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))(1): LeakyReLU(negative_slope=0.1)(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): LeakyReLU(negative_slope=0.1)(4): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(5): LeakyReLU(negative_slope=0.1))(netThr): Sequential((0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))(1): LeakyReLU(negative_slope=0.1)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): LeakyReLU(negative_slope=0.1))(netFou): Sequential((0): Conv2d(64, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))(1): LeakyReLU(negative_slope=0.1)(2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): LeakyReLU(negative_slope=0.1))(netFiv): Sequential((0): Conv2d(96, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))(1): LeakyReLU(negative_slope=0.1))(netSix): Sequential((0): Conv2d(128, 192, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))(1): LeakyReLU(negative_slope=0.1))
)
2.2 基础的cost volume
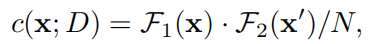
得到cost volume结果后,然后使用卷积在C上进行光流解码。所得到的光流场 u : Ω → R 2 u:\Omega\rightarrow R^{2} u:Ω→R2提供了从I1到I2的密集对应关系
2.3 可调制cost volume

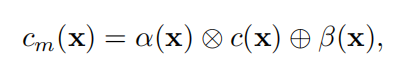
⊗ \otimes ⊗和 ⊕ \oplus ⊕分别表示像素级的乘法和加法,通过已经两个运算对原来的cost volume矩阵进行自适应调整。 α 和 β \alpha和\beta α和β同C具有同样的维度,二者由下图计算而来。

由M(x), F1, cost volume三者生成 α 和 β \alpha和\beta α和β。 M ( x ) M(x) M(x)表示在x处具有精确光流的概率。 M ( x ) M(x) M(x)最后的激活函数用sigmoid用于将其值约束为[0,1]。我们使用具有地面真实标签Mgt(x)的L2损失来训练置信图 M ( x ) M(x) M(x)
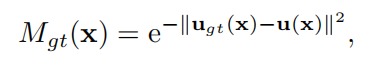
不知道这里的u(x)表示什么
2.4 cost volume到流解码
不同的流场解码方式,模型参数与精度的比较。


第一种就直接解码,第二种相当于多个feature concat之后+conv,第三种相当于加入了attention模块,像素级attention。 可以看到第三种方式最优。
2.5 新的流场变形(warp)
在从粗到细的流估计中,来自前一个解码器的流估计被用作后续解码器的流初始化。这非常要求之前的估计是准确的。错误的光流被传播到随后的水平,并影响流的推断。单独使用成本体积调制并无法解决这个问题。我们探索了局部流动一致性[29,33],并提出使用 m e t a − w a r p i n g meta-warping meta−warping来提高光流的精度。

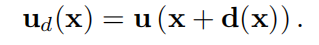
就是求一个 d ( x ) d(x) d(x),用其他点的光流来替换当前点的光流。d(x)怎么求呢?
特征F1求一个自相关矩阵,再光流置信度M(x)一起解码得到d(x)

3. 实验
3.1 训练
为了进行公平的比较,我们使用与文献[6,10,11,12,13,19,24,27,28,31]中其他光流cnn相同的训练集。我们使用与LiteFlowNet2[11]相同的训练协议(包括数据增强和批处理大小)。我们首先使用阶段级训练程序[11]在飞行椅数据集[6]上训练LiteFlowNet2。然后,我们将全新的模块、成本体积变形和流场调制集成到LiteFlowNet2中,形成LiteFlowNet3。新引入的CNN模块的训练学习率为1e-4,而其他组件的训练学习率降低为2e-5,进行300K迭代。然后,我们在飞行事物3D[20]上微调整个网络,学习速率为5e-6,可进行500K迭代。最后,我们分别在Sintel[4]和KITTI[22]的混合物上对LiteFlowNet3进行微调,训练集为KITTI,学习速率为600K迭代5e-5。这两个模型也以降低学习率和迭代与LiteFlowNet2相同

总结
- cost volume中引入了attention
- warp中引入了dx,对已经得到的光流进行修正
- 后续附上代码浅析
这篇关于【光流】——liteflownet3论文详析与推理代码浅析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




