本文主要是介绍【高频】从准备更新一条数据到事务的提交的流程描述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、相关问题
- SQL语句是如何被MySQL解析和分析的?
- MySQL是如何为SQL语句生成最优的执行计划的?
- 执行计划的各个步骤是如何一步步执行的?
- MySQL是如何访问存储引擎得到数据的?
- MySQL是如何将查询结果返回给客户端的?
- MySQL是如何处理事务的?
参考回答:
- 首先执行器根据 MySQL 的执行计划来查询数据,先是从缓存池中查询数据,如果没有就会去数据库中查询,如果查询到了就将其放到缓存池中
- 在数据被缓存到缓存池的同时,会写入 undo log 日志文件
- 更新的动作是在 BufferPool 中完成的,同时会将更新后的数据添加到 redo log buffer 中
- 完成以后就可以提交事务,在提交的同时会做以下三件事
- 将redo log buffer中的数据刷入到 redo log 文件中
- 将本次操作记录写入到 bin log文件中
- 将 bin log 文件名字和更新内容在 bin log 中的位置记录到redo log中,同时在 redo log 最后添加 commit 标记
著作权归@pdai所有 原文链接:https://pdai.tech/md/db/sql-mysql/sql-mysql-execute.html
二、过程详解:
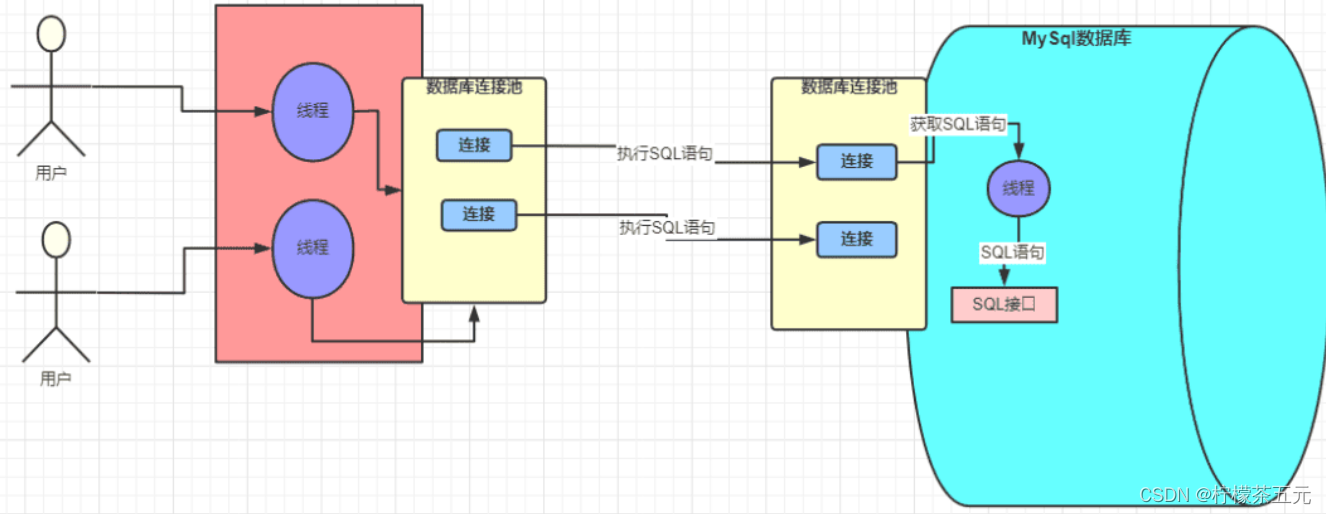
1.系统和数据库的连接
Mysql驱动在底层做数据库的连接,只有建立了连接,才能进行交互。一次SQL请求就会建立一个连接,多个请求就会建立多个连接,而web系统一般都是部署在tomcat容器中的,tomcat是可以并发处理多个请求的,这就会导致多个请求会去建立多个连接,再关闭,会大大降低系统的性能,因此采用数据库连接池进行连接。业务系统是并发的,因此系统和MySQL的架构体系中也已经提供了数据库连接池,双方都是通过数据库连接池来管理各个连接。【好处:线程之间不需要争抢,不需要反复放入创建和销毁连接。】
数据库连接池:维护一定的连接数,方便系统获取连接,使用时就去池子中获取,用完就放回去。不必关心连接的创建与销毁,也不必关心线程池如何维护连接。
网络中的连接都是由线程来处理的,对于 SQL 语句的请求在 MySQL 中是由一个个的线程去处理的。MySQL 中处理请求的线程在获取到请求以后获取 SQL 语句去交给 SQL 接口去处理。
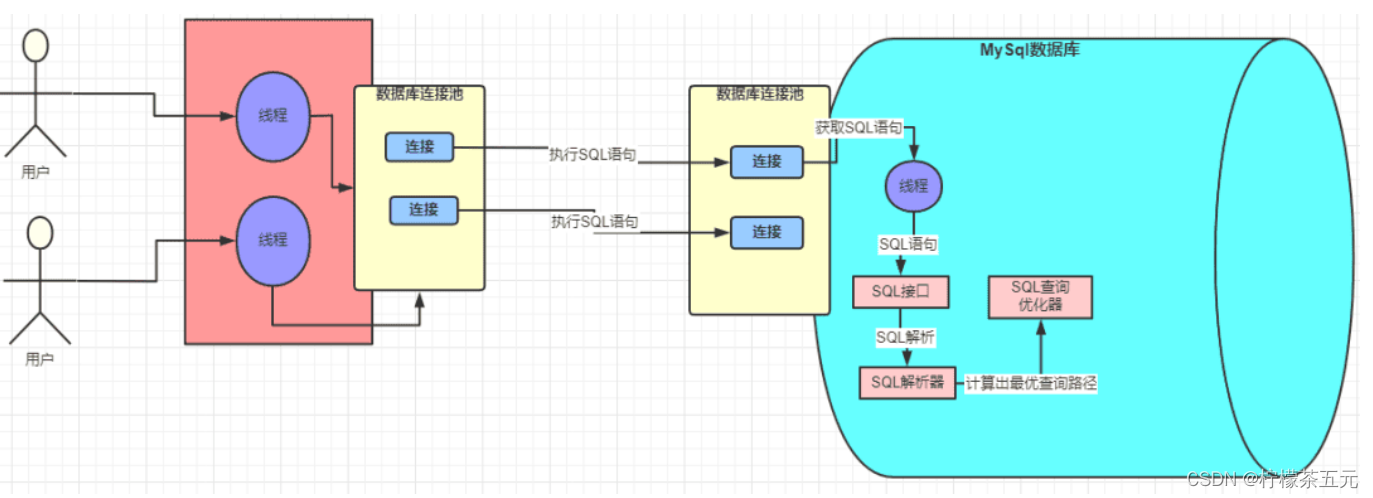
2.查询、解析、优化、执行
查询(Query)
- 这是SQL语句真正执行查询的核心阶段。
- MySQL会根据之前生成的执行计划,调用存储引擎执行具体的查询操作。
- 存储引擎会根据索引或全表扫描等方式访问数据页,并返回匹配的数据行
解析(Parse)
- 解析器会将SQL接口传递过来的SQL语句进行解析。
- 会先对SQL语句进行语法分析和验证,确保语句符合SQL标准。
- 这个阶段会生成一个抽象语法树(AST)作为内部表示。
优化(Optimize)
- MySQL的优化器会分析AST,结合统计信息选择最优的执行计划。
- 优化器会考虑索引、表连接顺序、子查询等因素进行优化,选择成本最低的执行方案。
- 可以使用EXPLAIN命令查看MySQL选择的执行计划。
执行(Execute)
- 根据优化器生成的执行计划,MySQL会调用存储引擎执行具体的查询操作。
- 这个阶段就是实际执行查询、返回结果集的过程。
- MySQL会监控SQL语句的执行情况,可以通过
SHOW PROCESSLIST查看当前正在执行的语句
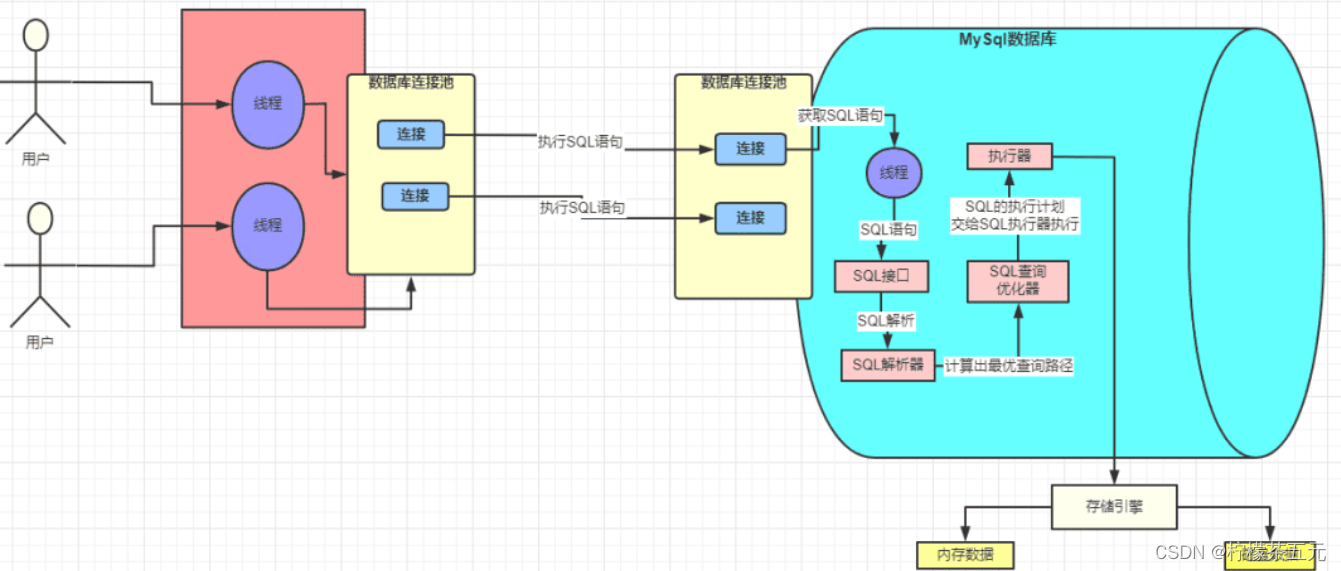
3.存储引擎
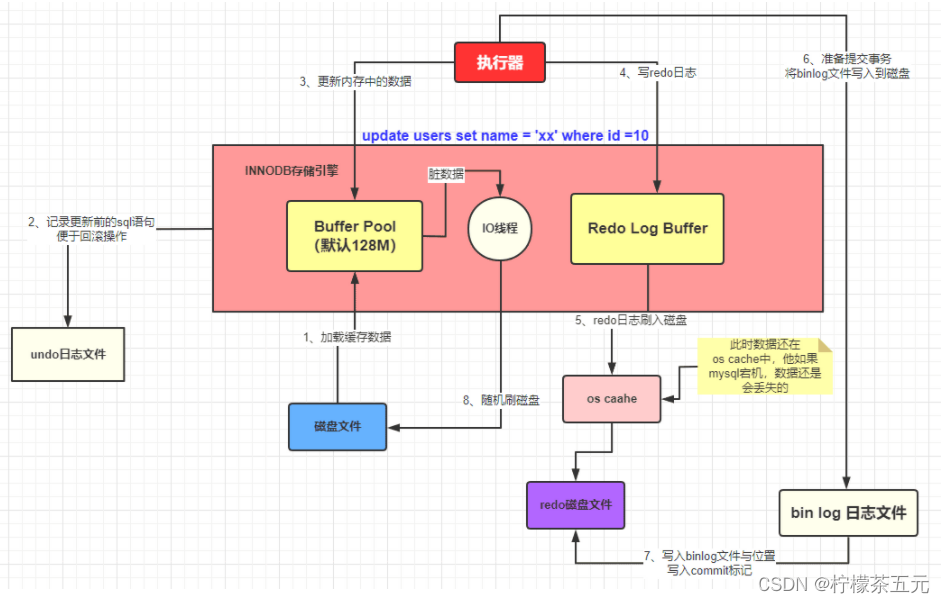
执行 SQL 的时候 SQL 语句对应的数据一般加载到内存中,这块内存就是 InnoDB 中一个非常重要的组件:缓冲池 Buffer Pool【Buffer Pool (缓冲池)是 InnoDB 存储引擎中非常重要的内存结构,顾名思义,缓冲池其实就是类似 Redis 一样的作用,起到一个缓存的作用】
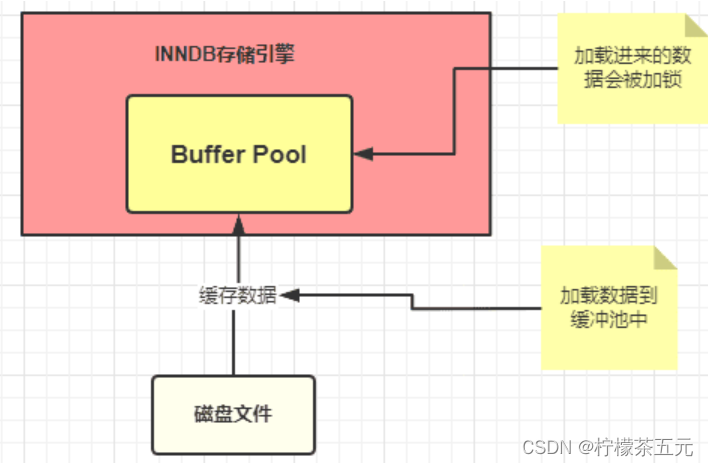
SQL 语句的执行步骤
- innodb 存储引擎会在缓冲池中查找 id=1 的这条数据是否存在
- 发现不存在,那么就会去磁盘中加载,并将其存放在缓冲池中
- 该条记录会被加上一个独占锁
undo 日志文件:记录数据被修改前的样子
redo 日志文件:记录数据被修改后的样子
【redo 日志文件是 InnoDB 特有的,他是存储引擎级别的,不是 MySQL 级别的】
MySQL 的执行器调用存储引擎的过程:
- 准备更新一条 SQL 语句
- MySQL(innodb)会先去缓冲池(BufferPool)中去查找这条数据,没找到就会去磁盘中查找,如果查找到就会将这条数据加载到缓冲池(BufferPool)中
- 在加载到 Buffer Pool 的同时,会将这条数据的原始记录保存到 undo 日志文件中
- innodb 会在 Buffer Pool 中执行更新操作
- 更新后的数据会记录在 redo log buffer 中
- MySQL 提交事务的时候,会将 redo log buffer 中的数据写入到 redo 日志文件中 刷磁盘可以通过 innodb_flush_log_at_trx_commit 参数来设置
- 值为 0 表示不刷入磁盘
- 值为 1 表示立即刷入磁盘
- 值为 2 表示先刷到 os cache
- myslq 重启的时候会将 redo 日志恢复到缓冲池中
参考博文:MySQL - 一条 SQL 的执行过程详解 | Java 全栈知识体系
这篇关于【高频】从准备更新一条数据到事务的提交的流程描述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





