本文主要是介绍Spark高级数据分析(1) ——纽约出租车轨迹的空间和时间数据分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文在之前搭建的集群上,运行一个地理空间分析的示例,示例来自于《Spark高级数据分析》第八章。
Github项目地址:https://github.com/sryza/aas/tree/master/ch08-geotime ,
这个例子是通过分析纽约市2013年1月份的出租车数据,统计纽约市乘客下车点落在每个行政区的个数。
在开始正文之前,需要掌握以下基础知识:
- Scala基础语法
- Spark基础概念和原理(推荐《Spark快速大数据大分析》)
纽约出租车地理空间数据分析的主要流程:
- 数据获取
- 数据时间和和空间处理类库
- 数据预处理与地理空间分析
- 提交应用至集群,分布式计算
数据获取
本文的数据是纽约市2013年1月份乘客打车费用数据,数据大小是914.9M,解压后为2.5G。
数据下载地址
http://www.andresmh.com/nyctaxitrips/(trip_data_1.csv.zip)
数据下载方式
- 直接在window下载,上传至linux服务器,注意我的集群是docker容器,直接传到容器master节点。
- 在linux直接下载,命令如下
wget http://www.andresmh.com/nyctaxitrips/(trip_data_1.csv.zip)
数据描述
#解压数据集
unzip trip_data_1.csv.zip
# 查看前10行数据
head -n 10 trip_data_1.csv
结果如下图
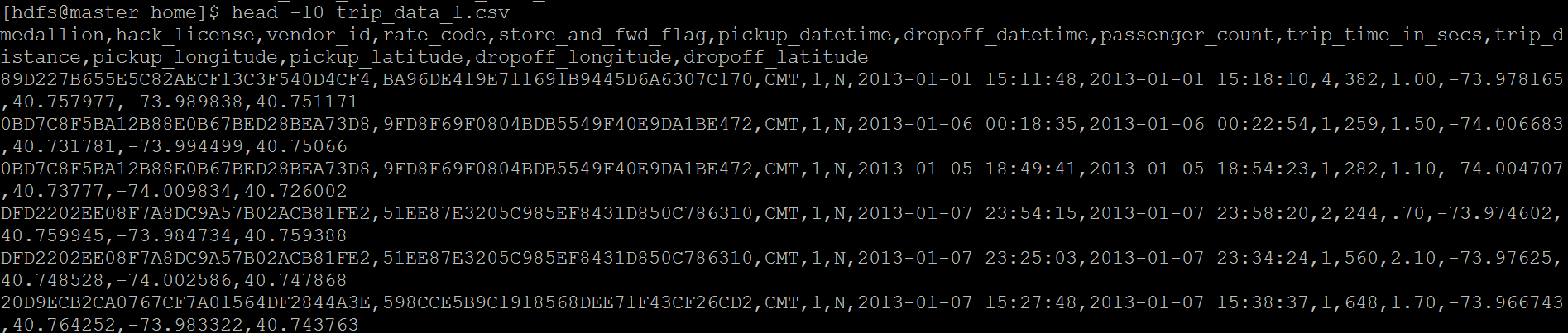
数据字段描述:
vendor_id:类型 rate_code:比率 store_and_fwd_flag:是否是四驱
pickup_datatime:客人上车时间 dropoff_datatime:客人下车时间
passenger_count:载客数量 trip_time_in_secs:载客时间 trip_distance:载客距离
pickup_longitude:客人上车经度 pickup_latitude:客人上车维度
dropoff_longitude:客人下车经度 dropoff_latitude:客人下车维度
数据处理第三方类库
注意Scala是可以直接调用Java类库的。
时间处理类库:joda-time,nscala-time_2.11.jar(2.11对应scala版本)
本文空间关系处理库采用Esri的esri-geometry-api,当然也可以采用GeoTools等开源库。
自定义RichGeometry类封装Esri矢量空间处理接口;
package com.cloudera.datascience.geotime
import com.esri.core.geometry.{GeometryEngine, SpatialReference, Geometry}
import scala.language.implicitConversions
/*** A wrapper that provides convenience methods for using the spatial relations in the ESRI* GeometryEngine with a particular instance of the Geometry interface and an associated* SpatialReference.** @param geometry the geometry object* @param spatialReference optional spatial reference; if not specified, uses WKID 4326 a.k.a.* WGS84, the standard coordinate frame for Earth.*/
class RichGeometry(val geometry: Geometry,val spatialReference: SpatialReference = SpatialReference.create(4326)) extends Serializable {def area2D(): Double = geometry.calculateArea2D()def distance(other: Geometry): Double = {GeometryEngine.distance(geometry, other, spatialReference)}def contains(other: Geometry): Boolean = {GeometryEngine.contains(geometry, other, spatialReference)}def within(other: Geometry): Boolean = {GeometryEngine.within(geometry, other, spatialReference)}def overlaps(other: Geometry): Boolean = {GeometryEngine.overlaps(geometry, other, spatialReference)}def touches(other: Geometry): Boolean = {GeometryEngine.touches(geometry, other, spatialReference)}def crosses(other: Geometry): Boolean = {GeometryEngine.crosses(geometry, other, spatialReference)}def disjoint(other: Geometry): Boolean = {GeometryEngine.disjoint(geometry, other, spatialReference)}
}/*** Helper object for implicitly creating RichGeometry wrappers* for a given Geometry instance.*/
object RichGeometry extends Serializable {implicit def createRichGeometry(g: Geometry): RichGeometry = new RichGeometry(g)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
数据预处理与地理空间分析
上传原始数据到HDFS集群
#在Hdfs集群下创建taxidata目录,注意必须带/
hadoop fs -mkdir /taxidata
#上传本地物理机数据至HDFS集群
hadoop fs -put trip_data_1.csv /taxidata/trip_data_1.csv
自定义safe函数处理格式不正确的数据
详细请看代码注释第三部分
地理空间分析
获取纽约行政区划数据,利用esri gerometry类库判断各行政区下车点的记录数(详细请看代码注释第四部分)。
/*** 打车信息类* **/
case class Trip(pickupTime: DateTime,dropoffTime: DateTime,pickupLoc: Point,dropoffLoc: Point)/*** 出租车数据地理空间分析*/
object RunGeoTime extends Serializable {val formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss", Locale.ENGLISH)def main(args: Array[String]): Unit = {val sc = new SparkContext(new SparkConf().setAppName("SpaceGeo"))val taxiRaw = sc.textFile("hdfs://master:9000/taxidata")val safeParse = safe(parse)val taxiParsed = taxiRaw.map(safeParse)taxiParsed.cache()val taxiGood=taxiParsed.filter(_.isLeft).map(_.left.get)taxiGood.cache()def hours(trip: Trip): Long = {val d = new Duration(trip.pickupTime, trip.dropoffTime)d.getStandardHours}taxiGood.values.map(hours).countByValue().toList.sorted.foreach(println)taxiParsed.unpersist()val taxiClean = taxiGood.filter {case (lic, trip) => {val hrs = hours(trip)0 <= hrs && hrs < 3}}val geojson = scala.io.Source.fromURL(getClass.getResource("/nyc-boroughs.geojson")).mkStringval features = geojson.parseJson.convertTo[FeatureCollection]val areaSortedFeatures = features.sortBy(f => {val borough = f("boroughCode").convertTo[Int](borough, -f.geometry.area2D())})val bFeatures = sc.broadcast(areaSortedFeatures)def borough(trip: Trip): Option[String] = {val feature: Option[Feature] = bFeatures.value.find(f => {f.geometry.contains(trip.dropoffLoc)})feature.map(f => {f("borough").convertTo[String]})}taxiClean.values.map(borough).countByValue().foreach(println)def hasZero(trip: Trip): Boolean = {val zero = new Point(0.0, 0.0)(zero.equals(trip.pickupLoc) || zero.equals(trip.dropoffLoc))}val taxiDone = taxiClean.filter {case (lic, trip) => !hasZero(trip)}.cache()taxiDone.values.map(borough).countByValue().foreach(println)taxiGood.unpersist()}def point(longitude: String, latitude: String): Point = {new Point(longitude.toDouble, latitude.toDouble)}def parse(line: String): (String, Trip) = {val fields = line.split(',')val license = fields(1)val formatterCopy = formatter.clone().asInstanceOf[SimpleDateFormat]val pickupTime = new DateTime(formatterCopy.parse(fields(5)))val dropoffTime = new DateTime(formatterCopy.parse(fields(6)))val pickupLoc = point(fields(10), fields(11))val dropoffLoc = point(fields(12), fields(13))val trip = Trip(pickupTime, dropoffTime, pickupLoc, dropoffLoc)(license, trip)}def safe[S, T](f: S => T): S => Either[T, (S, Exception)] = {new Function[S, Either[T, (S, Exception)]] with Serializable {def apply(s: S): Either[T, (S, Exception)] = {try {Left(f(s))} catch {case e: Exception => Right((s, e))}}}}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
分布式计算
打包应用
Windows下环境spark项目环境配置
在Windows上安装maven scala2.11.8(我的版本),intelij 及inteli的scala插件,导入ch08-geotime项目,如下图

配置pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.cloudera.datascience.geotime</groupId><artifactId>ch08-geotime</artifactId><packaging>jar</packaging><name>Temporal and Geospatial Analysis</name><version>2.0.0</version><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.11.8</version><scope>provided</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.3</version><scope>provided</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.0.1</version><scope>provided</scope></dependency><dependency><groupId>com.github.nscala-time</groupId><artifactId>nscala-time_2.11</artifactId><version>1.8.0</version></dependency><dependency><groupId>com.esri.geometry</groupId><artifactId>esri-geometry-api</artifactId><version>1.2.1</version></dependency><dependency><groupId>io.spray</groupId><artifactId>spray-json_2.11</artifactId><version>1.3.2</version></dependency><dependency><groupId>joda-time</groupId><artifactId>joda-time</artifactId><version>2.9.4</version></dependency></dependencies><build><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version><configuration><scalaVersion>2.11.8</scalaVersion><scalaCompatVersion>2.11.8</scalaCompatVersion><args><arg>-unchecked</arg><arg>-deprecation</arg><arg>-feature</arg></args><javacArgs><javacArg>-source</javacArg><javacArg>1.8.0</javacArg><javacArg>-target</javacArg><javacArg>1.8.0</javacArg></javacArgs></configuration><executions><execution><phase>compile</phase><goals><goal>compile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>2.6</version><configuration><archive><manifest><mainClass>com.cloudera.datascience.geotime.RunGeoTime</mainClass></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs><recompressZippedFiles>false</recompressZippedFiles></configuration><executions><execution><id>make-assembly</id> <phase>package</phase> <goals><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
Maven打包
在ch08-geotime项目下Terminal命令行
名称为ch08-geotime-2.0.0-jar-with-dependencies.jar(包含依赖包)
mvn clean
mvn package
提交应用到集群
上传jar包至master节点,确保集群已启动,提交应用至集群,主要过程如下:
- 用户通过 spark-submit 脚本提交应用。
- spark-submit 脚本启动驱动器程序,调用用户定义的 main() 方法。
- 驱动器程序与集群管理器通信,申请资源以启动执行器节点。
- 集群管理器为驱动器程序启动执行器节点。
- 驱动器进程执行用户应用中的操作。 根据程序中所定义的对RDD的转化操作和行动操
作,驱动器节点把工作以任务的形式发送到执行器进程。 - 任务在执行器程序中进行计算并保存结果。
- 如果驱动器程序的 main() 方法退出,或者调用了 SparkContext.stop()
驱动器程序会终止执行器进程,并且通过集群管理器释放资源。
————————《Spark快速大数据分析》
# --class 运行 Java 或 Scala 程序时应用的主类
# --master 表示要连接的集群管理器
# --deploy-mode 选择在本地(客户端“ client”)启动驱动器程序,还是在集群中的一台工作节点机
器(集群“ cluster”)上启动。在客户端模式下, spark-submit 会将驱动器程序运行
在 spark-submit 被调用的这台机器上。在集群模式下,驱动器程序会被传输并执行
于集群的一个工作节点上。默认是本地模式
# --name 应用的显示名,会显示在 Spark 的网页用户界面中
# 最后是应用入口的 JAR 包或 Python 脚本
spark-submit --class com.cloudera.datascience.geotime.RunGeoTime
--master yarn --deploy-mode cluster
--executor-memory 2g --executor-cores 2
--name "taxiGeoSpace"
/home/ch08-geotime/ch08-geotime-space-2.0.0.jar
# 注意集群模式地址是 spark://master:6066,客户端模式地址是spark://master:7077
spark-submit --class com.cloudera.datascience.geotime.RunGeoTime
--master spark://master:6066 --deploy-mode cluster
--executor-memory 2g --executor-cores 2 --name "taxiGeoSpace1" /home/ch08-geotime/ch08-geotime-space--2.0.0.jar
执行结果如下图
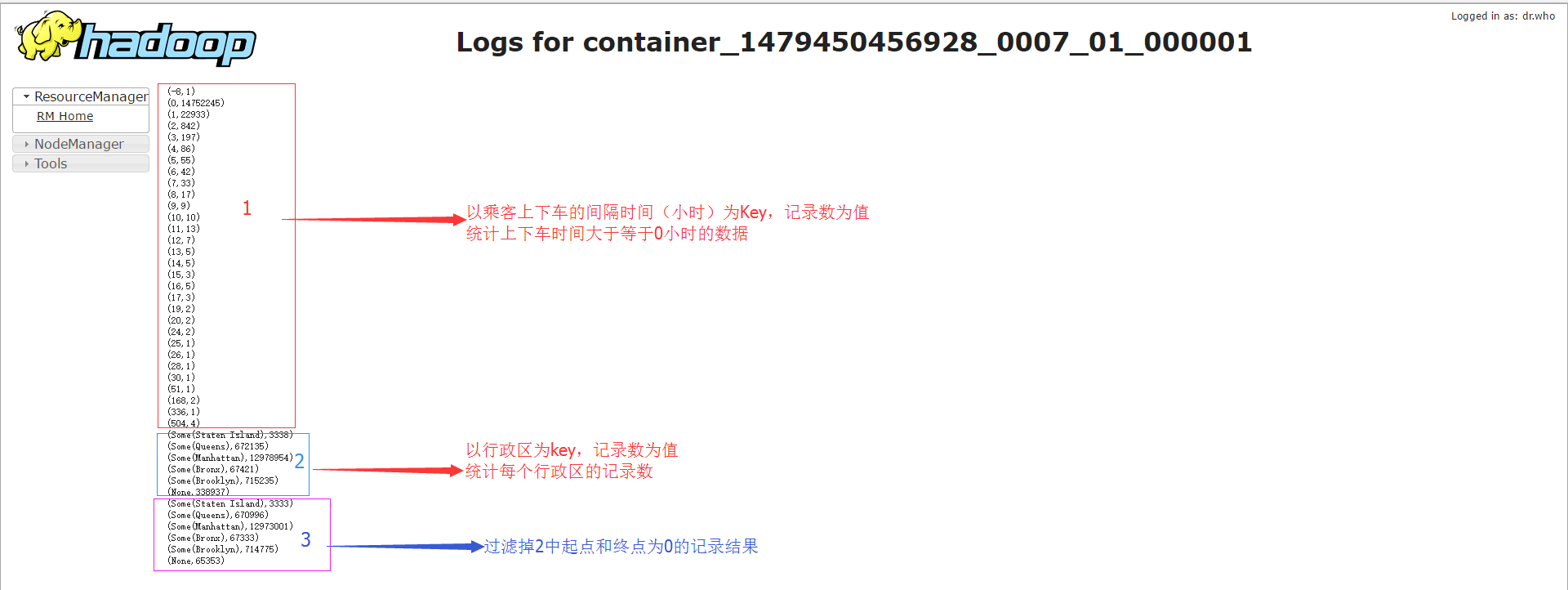
总结
执行时间是3min,后期要了解spark集群的运行参数配置
参考文献
- 《Spark快速大数据分析》
- 《Spark高级数据分析》
- http://spark.apache.org/docs/latest/running-on-yarn.html Running Spark on YARN
这篇关于Spark高级数据分析(1) ——纽约出租车轨迹的空间和时间数据分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




