本文主要是介绍吴恩达2022机器学习专项课程C2W3:实验Lab_01模型评估与选择,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这里写目录标题
- 导入模块与实验环境配置
- 回归
- 1.构建并可视化数据集
- 2.分割数据集
- 3.重新绘制数据集
- 3.特征缩放
- 4.评估模型:计算训练集的误差
- 5.评估模型:计算交叉验证集的误差
- 添加多项式
- 1.构建多项式特征集
- 2.缩放特征
- 3.使用标准化的计训练集和交叉验证集,计算它们的均方误差
- 4.整合代码
- 5.选择模型
- 6.使用测试集检测泛化
- 神经网络
- 1.特征缩放
- 2.构建和训练模型
- 分类
- 1.加载数据集
- 2.划分数据集
- 3.评估分类的误差
- 4.构建和训练模型
- 总结
导入模块与实验环境配置
首先,您将导入此实验室中所需的软件包。我们还包含了一些命令,以通过减少冗长和抑制非关键警告使后续输出更易读。

回归
1.构建并可视化数据集
为回归问题开发一个模型,首先构建数据集并可视化。

可视化数据集。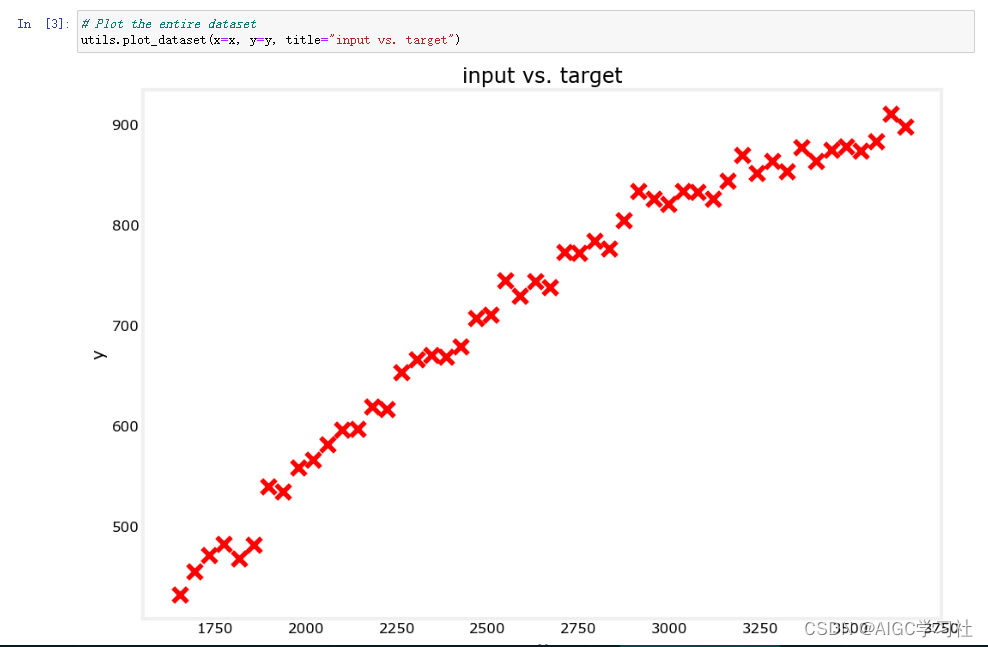
2.分割数据集
将数据集分为训练集,交叉验证集,测试集。Scikit-learn提供了train_test_split函数,可以将数据集划分为训练集、交叉验证集和测试集。数据划分比例:60%数据用于训练集。20%数据用于交叉验证集。20%数据用于测试集。
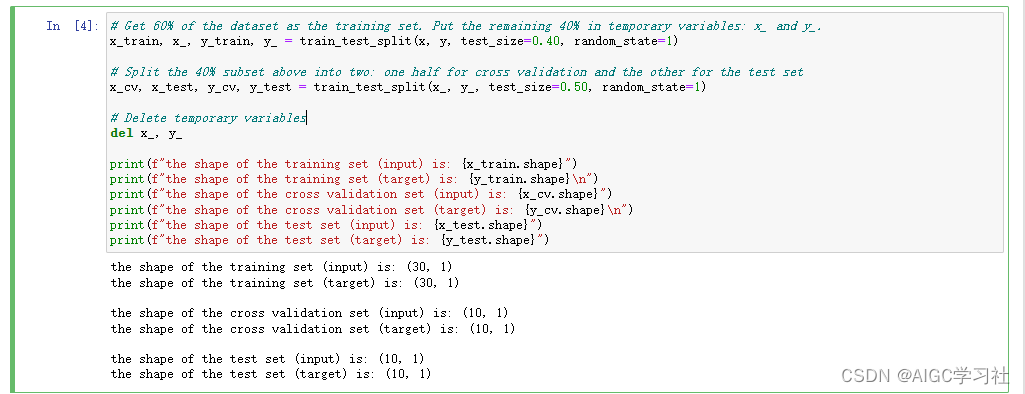
3.重新绘制数据集
看看哪些点被用作训练、交叉验证或测试数据
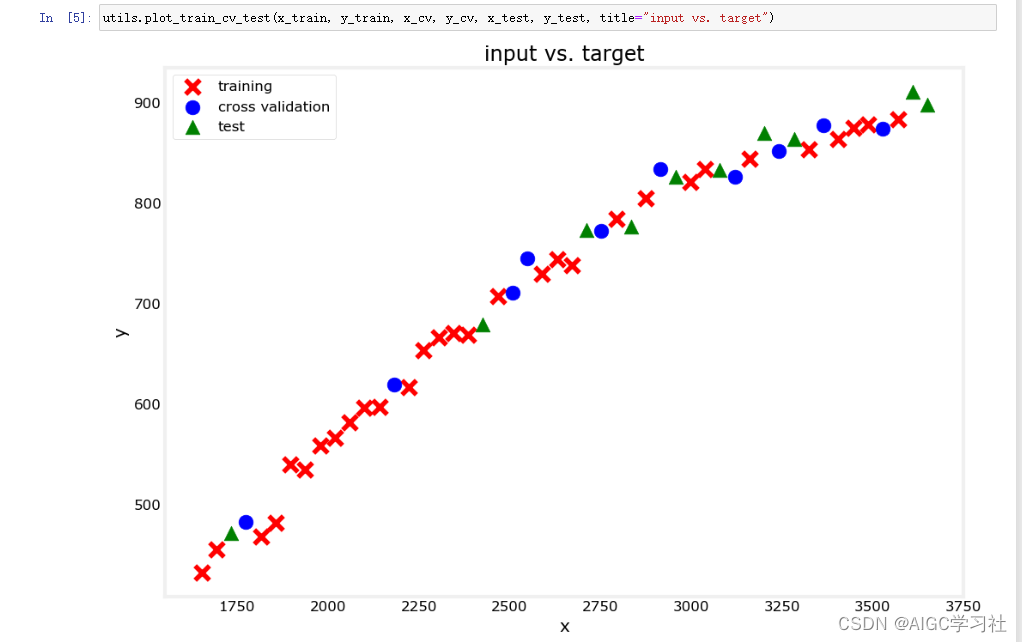
3.特征缩放
(1)概述:特征缩放有助于加快模型收敛速度,特别是在输入特征具有不同数值范围时。在后续实验中,加入多项式项会使得输入特征范围更加广泛,例如 x 从 1600 到 3600,x^2从2.56百万到12.96百万。
(2)代码解释:StandardScaler()是一个特征缩放的类,这个类对象scaler_linear调用fit_transform方法计算 x_train训练集的均值和标准差,然后对数据进行标准化处理,返回标准化后的训练数据 X_train_scaled。
能够看到x的范围缩小了,范围在-1.5和2之间。
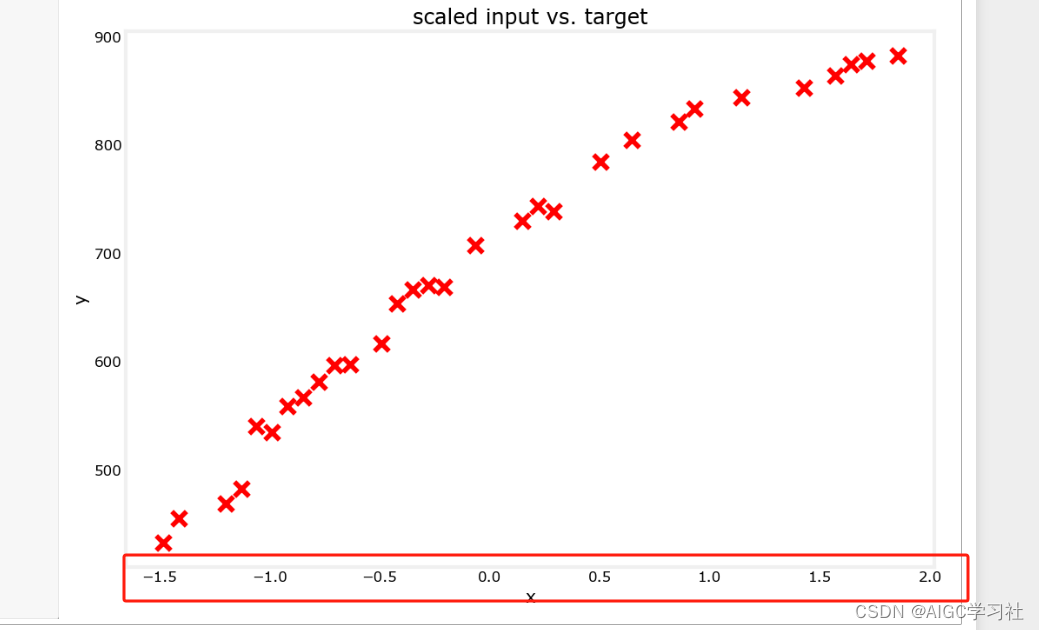
初始化线性回归模型并使用标准化后的训练数据来训练模型。
4.评估模型:计算训练集的误差
两种方式计算误差:使用 scikit-learn 提供的 mean_squared_error 函数和手动实现的 for 循环。过程就是先通过标准化后的训练集计算预测值,然后将预测值,真实值传入mean_squared_error,标准化后的训练集误差为406。

5.评估模型:计算交叉验证集的误差
(1)概述:使用 z-score 标准化时要使用训练集的均值和标准差对交叉验证集进行标准化,不能使用交叉验证集自身的均值和标准差,这样预测不会出错。在对交叉验证集进行标准化时,应使用 StandardScaler 的 transform() 方法,而不是 fit_transform() 方法。 fit_transform() 计算的是交叉验证集的均值和标准差,使用transform() 用计算好的均值和标准差对验证集数据进行标准化。
(2)代码解释:使用训练集的实例对象scaler_linear调用 transform() ,这样就是使用训练集的均值和标准差计算验证集的标准化。然后使用训练好的线性回归模型对标准化后的交叉验证集 X_cv_scaled 进行预测,结果存储在 yhat 中。交叉验证集的误差为551。
添加多项式
使用直线模型可能不合适,因为 y 在 x 增加时趋于平缓。建议尝试添加多项式特征以改善模型性能,虽然代码大部分不变,但会增加一些预处理步骤。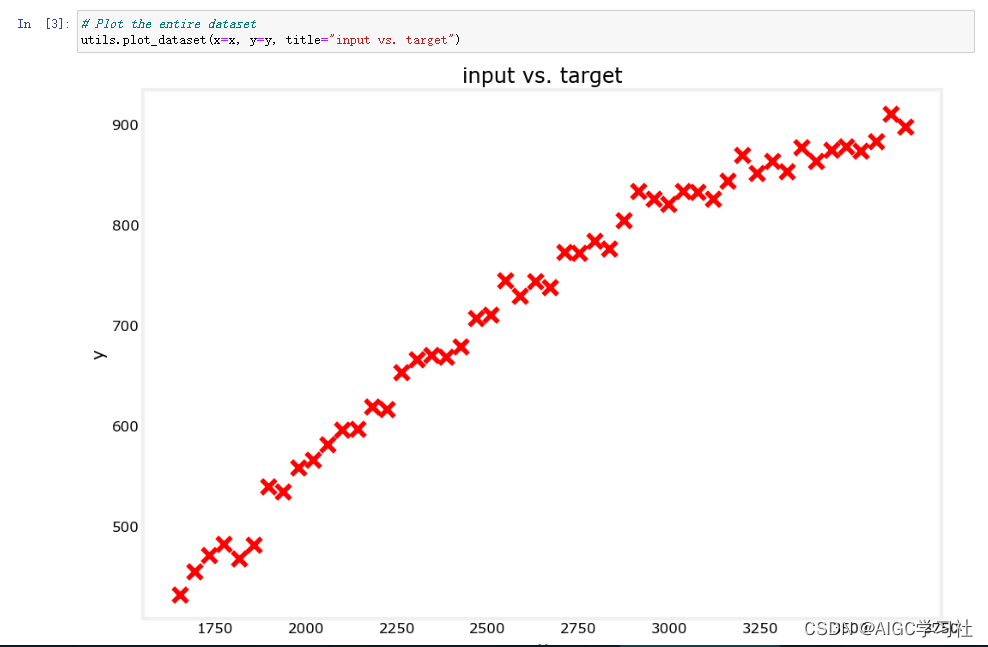
1.构建多项式特征集
首先实例化 PolynomialFeatures类,对象poly,将训练集的平方值添加为新特征。然后用poly.fit_transform对训练集进行转换,生成包含原始特征和其平方的新训练集。最后,预览新训练集的前5个元素,展示每个样本的原始特征和平方特征。左侧是原始特征x的值,有右侧是x平方特征。

2.缩放特征

3.使用标准化的计训练集和交叉验证集,计算它们的均方误差
初始化回归模型,用标准化后的训练集训练模型,计算并打印训练集的均方误差(MSE),使用训练集的实例化对象poly,对交叉验证集添加多项式特征,因此不用fit_transform,直接transform。然后用scaler_poly标准化处理数据,同样用训练集的scaler_poly标准化对象。训练集的误差为49,交叉验证集的误差为87。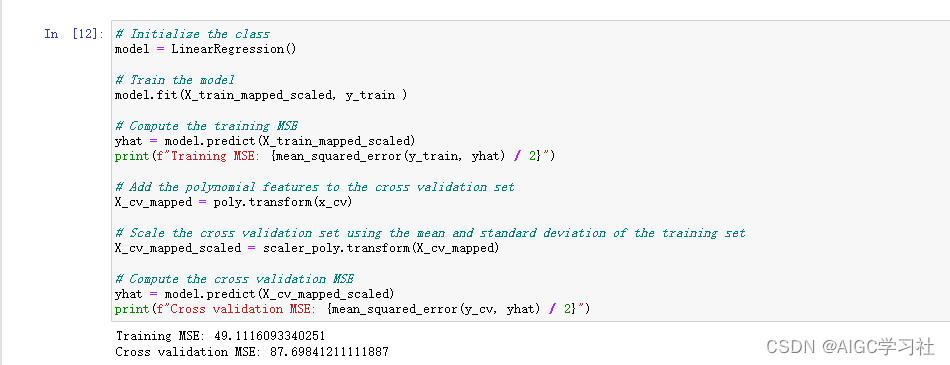
4.整合代码
你会注意到,当你添加二阶多项式时,训练集和交叉验证集的均方误差(MSE)显著改善。你可能希望引入更多的多项式项,看看哪一个能提供最佳性能。如课堂上所示,你可以这样创建10个不同的模型: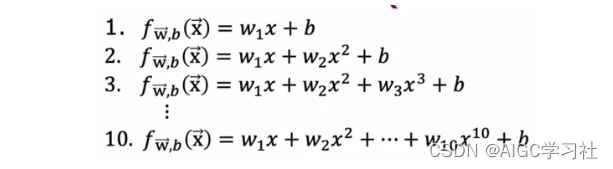
您可以创建一个循环,该循环包含之前代码单元格中的所有步骤。以下是一个实现方式,它会添加直至次数为10的多项式特征。我们将在最后进行绘图,以便于比较每个模型的结果。
代码解释:实例化多项式类对象poly和标准化类对象scaler_poly,在给训练集标准化处理时,方法都是fit_transform。然后同样的过程处理交叉验证集,就只用同样的对象调用transform。这样做的目的就是训练集和交叉验证集使用同一套标准化数据,防止预测出错。
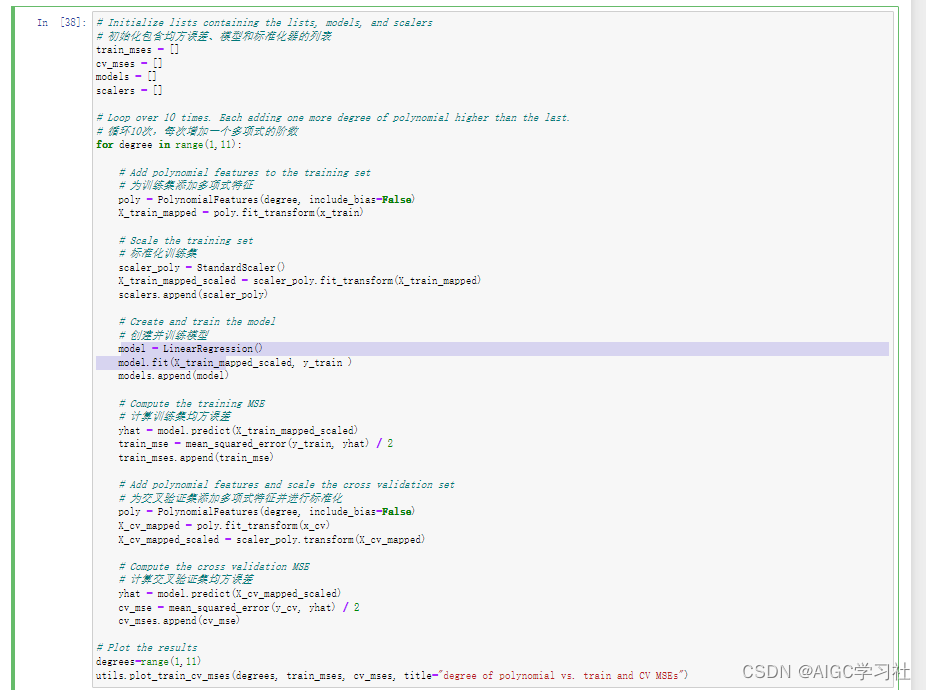
代码输出:X轴表示多项式的阶数,从1到10。Y轴表示均方误差(MSE)。红色线条表示训练集的均方误差,蓝色线条表示交叉验证集的均方误差。低阶多项式(1到2):
均方误差大幅下降,模型性能显著改善。
中阶多项式(3到5):
训练集和交叉验证集的误差趋于平稳,模型在这一区间可能达到最佳性能。
高阶多项式(6到10):
训练集误差继续保持较低水平,但交叉验证集误差开始增加,表明模型开始过拟合训练数据,对新数据的泛化能力变差。

5.选择模型
np.argmin(cv_mses) 返回列表 cv_mses 中最小值的索引,这个索引对应于交叉验证均方误差(CV MSE)最小的模型。
+1 是因为多项式阶数从1开始,而列表索引从0开始,所以需要加1来得到实际的多项式阶数。

6.使用测试集检测泛化
您可以通过计算测试集的均方误差(MSE)来公布模型的泛化误差。像往常一样,您应该以与训练集和交叉验证集相同的方式对测试数据进行转换。
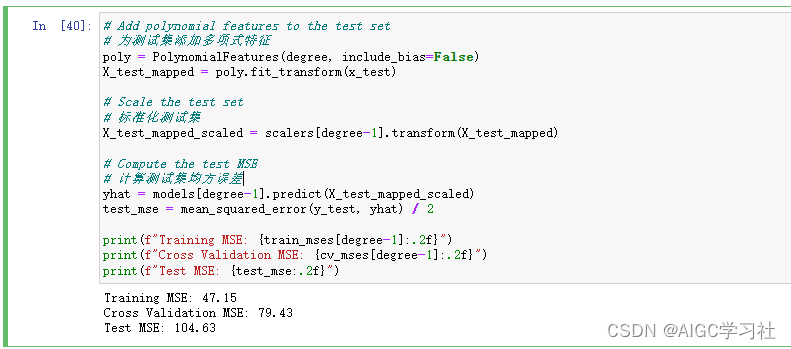
神经网络
模型选择的过程也适用于选择不同架构的神经网络。由于神经网络可以学习非线性关系,因此不用添加多项式,因此还是使用原来的x_train,x_cv,x_test,degree设置为1表示保留原始特征,因此前后转换的内容一致,这里是为了方便以后自行查看多项式而保留的代码。

1.特征缩放
请注意,在交叉验证集和测试集中,使用的是从训练集中计算的均值和标准差,只需使用 transform(),而不是 fit_transform()。

2.构建和训练模型
构建模型的代码

遍历构建的3个模型,对每个模型如下操作:编译并使用特征缩放后的训练集训练模型,然后使用模型计算训练集的预测值和交叉验证集的预测值,在调用mean_squared_error计算两个集的均方误差,最后打印每个模型训练集的均方误差。
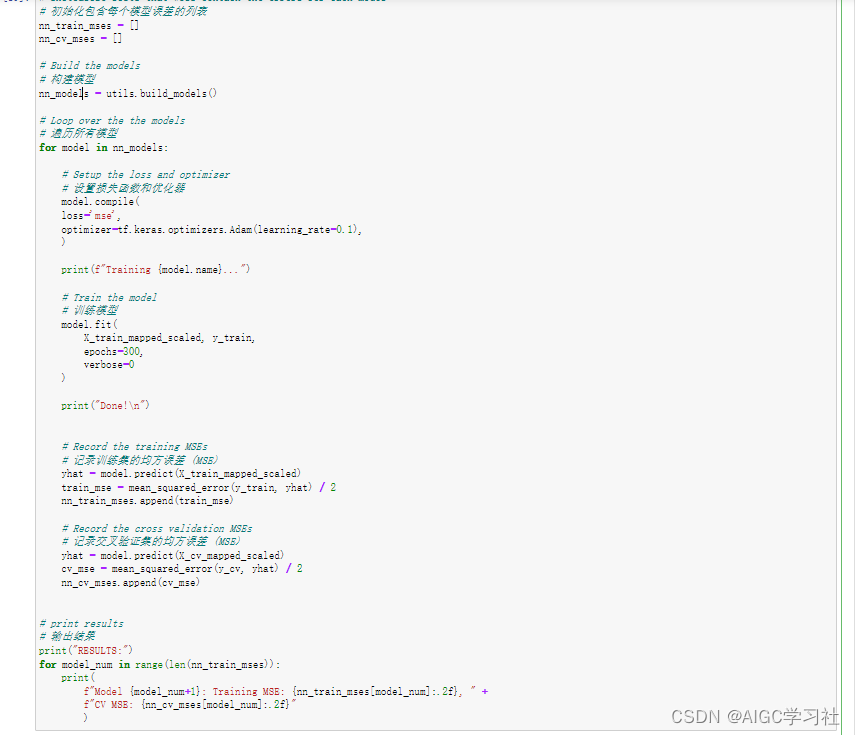
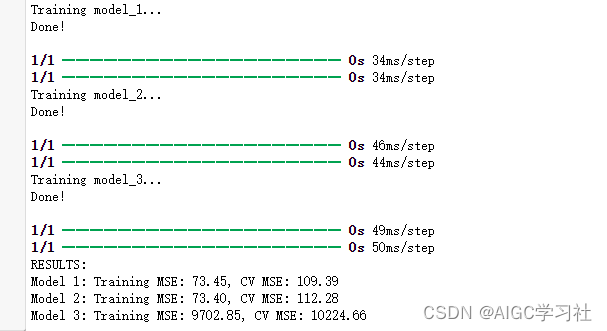
我们可以通过训练集和交叉验证集的均方误差大小,来选择模型,然后通过测试集检测模型的泛化能力,实验中的意思是它选择了模型3,然后问你是否同意这个选择,结果自然是模型3不够好,误差太大,泛化能力太弱。
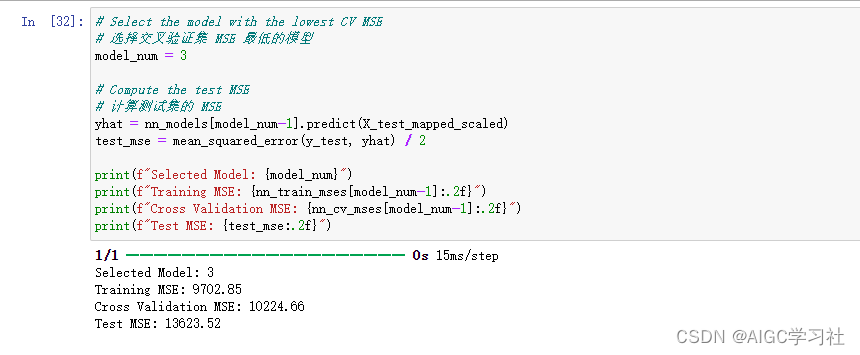
分类
分类任务中进行模型评估和选择。过程将类似,主要区别在于误差的计算。
1.加载数据集
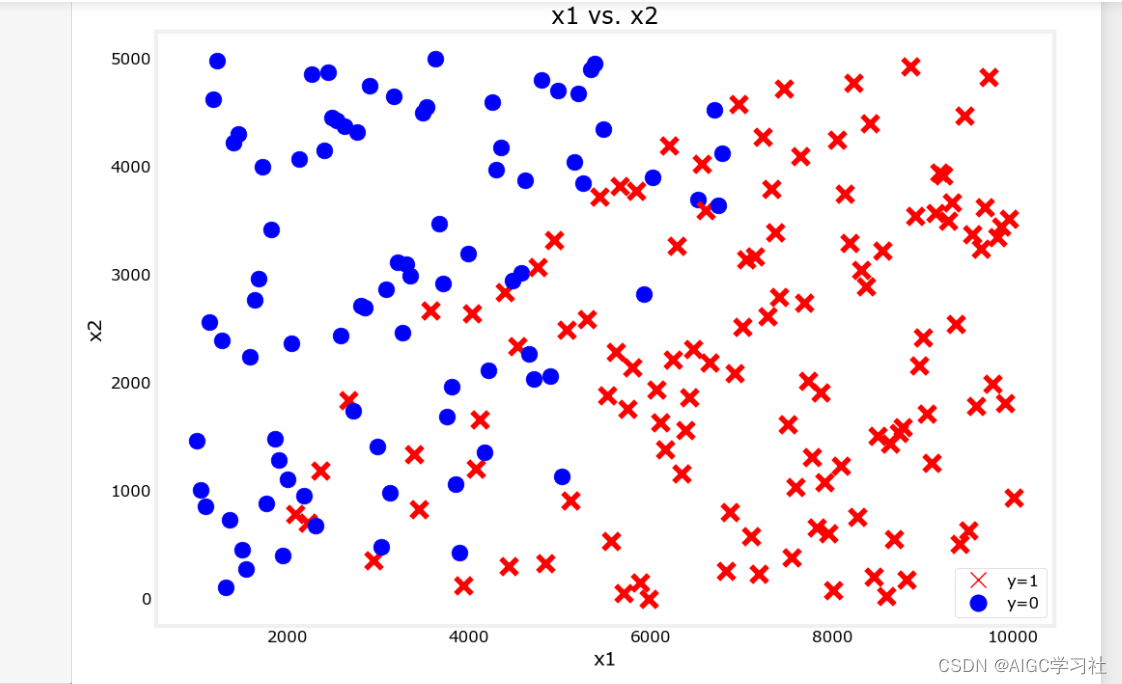
训练样本200个,特征2个。加载一个用于二元分类任务的数据集。

可视化数据集
2.划分数据集
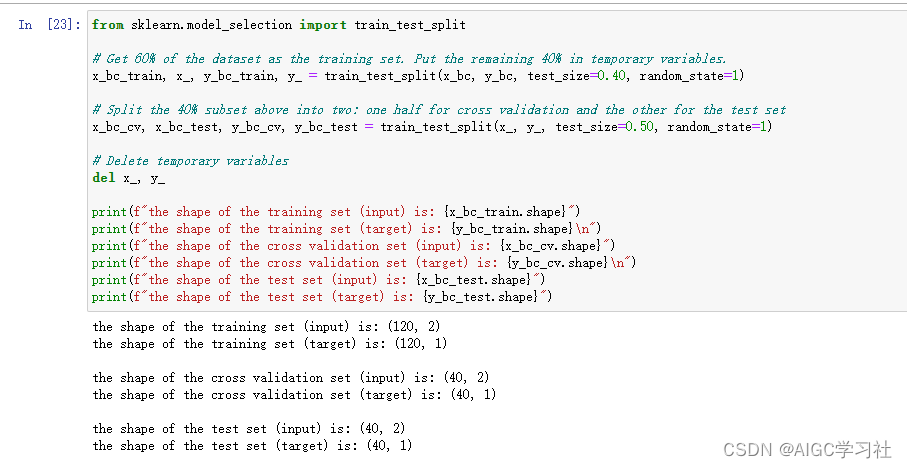
和之前的方式一致,使用train_test_split将数据集划分训练集,交叉验证集,测试集。
3.评估分类的误差
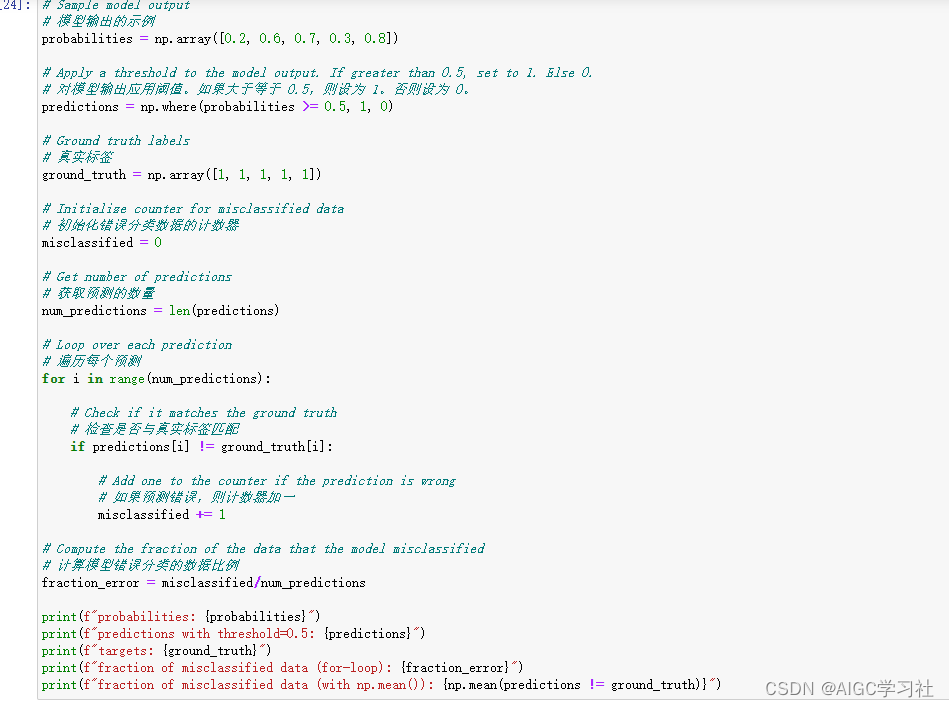
(1)概述:在之前关于回归模型的部分,您使用均方误差来衡量模型的表现。在分类任务中,您可以通过计算模型错误分类的数据比例来得到类似的度量。例如,如果您的模型在5个样本中做出了2个错误预测,那么您将报告 40% 或 0.4 的误差。
(2)代码解释:代码举了一个简单的例子,用5个数和阈值,假设了预测值,例如[0.2, 0.6, 0.7, 0.3, 0.8]的预测值为[0,1,1,0,1],然后又列出了真实值[1,1,1,1,1],对比这两个数组,如果不一致,则错误累加1,最终用累加的错误/预测数量,即为错误分类比例。比例越高,表示模型分类误差越大。
4.构建和训练模型
(1)概述:这里正式开始构建模型,为了减少误差(上周的改良softmax代码的内容),模型的输出层使用 linear 激活函数(而不是 sigmoid),然后在声明模型的损失函数时设置 from_logits=True。由于这是一个二元分类问题,将使用 binary crossentropy loss。训练后,您将使用 sigmoid函数将模型输出转换为概率。然后,您可以设置一个阈值,并从训练集和交叉验证集中获得错误分类示例的比例。
(2)代码解释:步骤基本上都是一致的,只是预测的步骤多了一个tf.math.sigmoid,意思是把模型输出转换成概率,因为输出层使用linear,因此我们要转换输出值。

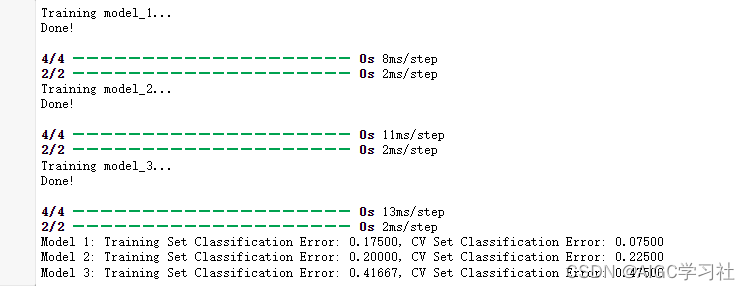
从上面的输出中,您可以选择表现最好的模型。如果交叉验证集上的错误相同,那么可以选择训练集错误较低的模型。这里选择模型2并计算它的测试集误差。

总结
本篇实验只是描述了回归问题,分类问题,以及神经网络如何使用训练集,交叉验证集,测试集,然后通过交叉验证集误差选择模型,通过测试集误差评估模型,下一篇会详细描述当发现模型的这种误差时,应该如何解决。
这篇关于吴恩达2022机器学习专项课程C2W3:实验Lab_01模型评估与选择的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





