本文主要是介绍每日一题——Python实现PAT乙级1109 擅长C(举一反三+思想解读+逐步优化)七千字好文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
Python编程学习
Python内置函数
Python-3.12.0文档解读
目录
初次尝试
代码分析
时间复杂度
空间复杂度
总结
我要更强
代码结构与功能
全局时间复杂度
全局空间复杂度
代码优点
代码优化建议
哲学和编程思想
1. 模块化(Modularity)
2. 封装(Encapsulation)
3. 抽象(Abstraction)
4. 可重用性(Reusability)
5. 递归与迭代(Recursion and Iteration)
6. 正则表达式(Regular Expressions)
7. 异常处理(Exception Handling)
总结
举一反三
模块化(Modularity)
封装(Encapsulation)
抽象(Abstraction)
可重用性(Reusability)
递归与迭代(Recursion and Iteration)
正则表达式(Regular Expressions)
异常处理(Exception Handling)
综合应用
总结
题目链接
初次尝试
letters=[]
for i in range(26):letters.append([input() for row in range(7)])
#letters
#[['..C..', '.C.C.', 'C...C', 'CCCCC', 'C...C', 'C...C', 'C...C'],
# ['CCCC.', 'C...C', 'C...C', 'CCCC.', 'C...C', 'C...C', 'CCCC.'],
# ['.CCC.', 'C...C', 'C....', 'C....', 'C....', 'C...C', '.CCC.'],
#...
#]words=list(input())
for i in range(len(words)):if words[i].isupper():passelse:words[i]=' 'while str(words[-2]).isupper()==False:words.pop()
while str(words[0]).isupper()==False:words.pop(0)
i=1
while i<len(words):while str(words[i-1]).isupper()==False and str(words[i]).isupper()==False:words.pop(i)i+=1#print(words)
word=['','','','','','','']for char_num in range(len(words)):if words[char_num].isupper():letter=letters[ord(words[char_num])-65]for i in range(7):tmp=word[i]+letter[i]+' 'word[i]=tmpelse:for i in range(7):tmp=word[i][:-1]word[i]=tmpif char_num<len(words)-1:for row in word:print(row)print()else:for row in range(6):print(word[row])print(word[6],end='')word=['','','','','','','']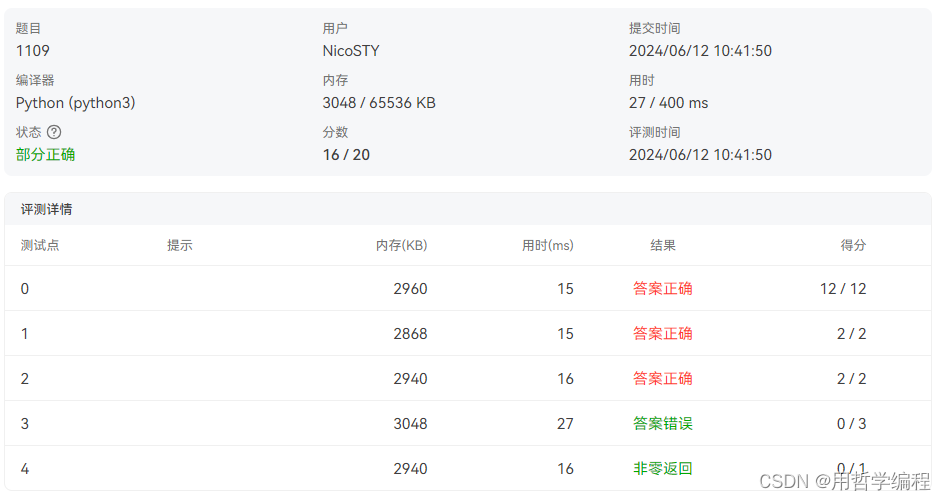
代码分析
这段代码从输入中读取 26 个字母,每个字母由 7 行字符组成,并将它们存储在 letters 列表中。这一部分的时间复杂度是 O(26 * 7) = O(182),空间复杂度是 O(182),因为存储了 26 个字母,每个字母占 7 行字符。
将输入的字符串转换为字符列表。
这段代码将所有小写字母替换为空格,时间复杂度是 O(n),其中 n 是输入字符串的长度。
这两段循环去除单词首尾的空格,最坏情况下时间复杂度是 O(n),因为可能需要遍历整个字符串。
这段代码通过遍历字符串并删除连续的空格,最坏情况下时间复杂度是 O(n^2),因为每次 .pop(i) 操作都是线性时间复杂度。
- 输入处理
- letters=[]
- for i in range(26): letters.append([input() for row in range(7)])
- 处理输入的单词
- words=list(input())
- 删除小写字母并用空格替换
- for i in range(len(words)): if words[i].isupper(): pass else: words[i]=' '
- 去除首尾的空格
- while str(words[-2]).isupper()==False: words.pop()
- while str(words[0]).isupper()==False: words.pop(0)
- 去除多个连续空格
- i=1 while i<len(words): while str(words[i-1]).isupper()==False and str(words[i]).isupper()==False: words.pop(i) i+=1
- 构建字符图案
- 初始化 word 列表
- 遍历字符并构建图案
这一部分的时间复杂度是 O(n),其中 n 是字符数,因为每个字符需要处理 7 行。空间复杂度也是 O(n),因为每个字符的图案需要额外的存储空间。
时间复杂度
总体时间复杂度分析如下:
- 输入处理:O(182)
- 替换小写字母:O(n)
- 去除首尾空格:O(n)
- 去除多个连续空格:O(n^2)
- 构建字符图案:O(n)
总体时间复杂度:O(n^2)
空间复杂度
总体空间复杂度分析如下:
- 输入处理:O(182)
- 构建字符图案:O(n)
总体空间复杂度:O(n)
总结
这段代码在处理输入和构建图案方面是有效的,但存在一些可以优化的地方,例如在去除连续空格的部分。当前算法在最坏情况下的时间复杂度是 O(n^2),可以通过使用更高效的数据结构(如双端队列)来优化,将去除连续空格的时间复杂度降低到 O(n)。
同时,代码的可读性和结构也有提升的空间,建议将代码分解为多个函数,每个函数负责一个明确的任务,以提高代码的可维护性和可读性。
我要更强
def read_matrix():# 创建一个空列表,用于存储26个字母的矩阵表示letters = []for i in range(26):# 对于每个字母,读取7行输入,并去除每行的前后空白字符letter = [input().strip() for _ in range(7)]# 将该字母的矩阵表示添加到letters列表中letters.append(letter)return lettersdef split_words(sentence):import re# 使用正则表达式找到句子中的所有由连续大写字母组成的单词return re.findall(r'[A-Z]+', sentence)def print_word(word, letters):# 创建一个包含7个空字符串的列表,用于存储最终输出的每一行lines = ['' for _ in range(7)]for char in word:# 根据字符的ASCII值找到对应的字母矩阵letter = letters[ord(char) - ord('A')]for i in range(7):# 如果当前行已经有其他字母,则添加一个空格作为分隔符if lines[i]:lines[i] += ' '# 将当前字母的对应行添加到输出行中lines[i] += letter[i]# 打印每一行的最终结果for line in lines:print(line)def main():# 读取26个字母的矩阵表示letters = read_matrix()# 读取输入的句子,并去除前后空白字符sentence = input().strip()# 将句子分割成一个个单词(由连续大写字母组成)words = split_words(sentence)# 标记是否是第一个单词,以便在单词之间添加空行first_word = Truefor word in words:# 如果不是第一个单词,则在单词之间添加一个空行if not first_word:print()# 打印当前单词的字母矩阵表示print_word(word, letters)# 标记已经处理了第一个单词first_word = False# 如果脚本是作为主程序运行,执行main函数
if __name__ == "__main__":main()
 这段代码的功能是根据输入的字母矩阵表示和一个包含大写字母的句子,生成并输出句子的矩阵表示。以下是对代码的详细点评,包括时间复杂度和空间复杂度的分析。
这段代码的功能是根据输入的字母矩阵表示和一个包含大写字母的句子,生成并输出句子的矩阵表示。以下是对代码的详细点评,包括时间复杂度和空间复杂度的分析。
代码结构与功能
- 函数 read_matrix
- 功能:从标准输入读取26个字母的矩阵表示,每个字母由7行字符组成,并去除每行的前后空白。
- 处理过程:循环26次,每次读取7行输入,去除空白并存储在letters列表中。
- 时间复杂度:O(26 * 7) = O(182)
- 空间复杂度:O(26 * 7) = O(182)
- 函数 split_words
- 功能:使用正则表达式从输入句子中提取出由连续大写字母组成的单词。
- 处理过程:使用re.findall函数匹配正则表达式[A-Z]+。
- 时间复杂度:O(n),其中n是输入句子的长度。
- 空间复杂度:O(k),其中k是匹配到的单词总长度。
- 函数 print_word
- 功能:根据输入的单词和字母矩阵表示,生成并打印单词的矩阵表示。
- 处理过程:
- 初始化一个包含7个空字符串的列表lines。
- 对于每个字符,查找其对应的字母矩阵,并将其拼接到lines的对应行中。
- 打印生成的每一行。
- 时间复杂度:O(m * 7),其中m是单词的长度,因为每个字符需要处理7行。
- 空间复杂度:O(7),因为lines列表始终包含7个字符串。
- 函数 main
- 功能:协调以上函数,读取输入,分割单词,并打印每个单词的矩阵表示。
- 处理过程:
- 调用read_matrix读取字母矩阵表示。
- 调用split_words分割输入句子为单词列表。
- 循环处理每个单词,调用print_word打印其矩阵表示,并在单词之间添加空行。
- 时间复杂度:整体受read_matrix、split_words和print_word的时间复杂度影响。
- 空间复杂度:整体受read_matrix、split_words和print_word的空间复杂度影响。
全局时间复杂度
- read_matrix:O(182)
- split_words:O(n)
- print_word:(最坏情况下)设输入句子长度为n,单词总数为w,平均单词长度为m,则总时间复杂度为O(w * m * 7),整体为O(n * 7) = O(7n) = O(n)
综合以上分析,总体时间复杂度为: [ O(182) + O(n) + O(n) = O(n) ]
全局空间复杂度
- read_matrix:O(182)
- split_words:O(k), 其中k是正则表达式匹配到的单词长度总和。
- print_word:O(7)
综合以上分析,总体空间复杂度为: [ O(182) + O(k) + O(7) = O(182 + k) ]
代码优点
- 模块化:函数划分明确,可读性强。
- 简洁:使用了Python的标准库和内置函数,简化了代码逻辑。
- 高效:在处理和输出方面都较为高效。
代码优化建议
- 缓存和复用:在print_word函数中,如果字母矩阵可以重复使用,可以考虑缓存处理过的字母以减少重复操作。
- 输入验证:增加输入验证,确保输入的格式和内容符合预期。
- 异常处理:增加异常处理,确保程序在异常情况下能有适当的响应。
总体来说,这段代码设计合理,效率较高,适合处理由大写字母构成的句子矩阵表示生成任务。
哲学和编程思想
在这段代码中,可以看到多种编程思想和哲学的应用。这些思想不仅帮助提高代码的质量和可维护性,还使代码更加高效和易于理解。以下是一些具体的编程思想和相关的哲学观点:
1. 模块化(Modularity)
编程思想:
- 将代码划分为多个独立的函数,每个函数负责一个明确的任务。这种方法使代码更易于理解、维护和测试。
哲学观点:
- 单一职责原则(Single Responsibility Principle):一个函数(或模块)应当只负责一个明确的功能,避免功能混杂。
- 分而治之(Divide and Conquer):将复杂的问题分解为更小、更易处理的子问题。
具体应用:
- read_matrix函数负责读取字母的矩阵表示。
- split_words函数负责处理输入句子,将其分割为单词。
- print_word函数负责打印单词的矩阵表示。
- main函数负责协调整个过程,各函数各司其职。
2. 封装(Encapsulation)
编程思想:
- 将数据和操作数据的方法封装在一起,隐藏内部实现细节,只对外暴露接口。这种方法提高了代码的安全性和可维护性。
哲学观点:
- 信息隐藏(Information Hiding):通过隐藏实现细节,减少模块之间的耦合,使代码更易维护。
具体应用:
- 各个函数内部实现细节是独立的,外部调用者不需要关心这些细节,只需要使用暴露的接口即可。例如,main函数只需要调用read_matrix、split_words和print_word,而不需要知道这些函数的内部实现。
3. 抽象(Abstraction)
编程思想:
- 提取出程序中共性的部分,忽略具体的实现细节,只关注核心功能。这种方法使得代码更简洁、更通用。
哲学观点:
- 抽象化(Abstraction):通过抽象化,将具体问题提升到概念层次,使其更易于处理和理解。
具体应用:
- split_words函数使用正则表达式来匹配大写字母单词,这是一种抽象化的字符串处理方法,简洁而高效。
- print_word函数将字符矩阵的拼接抽象为对每行字符串的操作,从而简化了处理过程。
4. 可重用性(Reusability)
编程思想:
- 编写可以在不同场景下重复使用的代码,以减少重复劳动,提高开发效率。
哲学观点:
- 不要重复自己(Don't Repeat Yourself,DRY):通过抽象和封装,减少重复代码,提高代码质量。
具体应用:
- 各个函数可以在不同的上下文中重复使用。例如,print_word函数可以用于打印任何输入单词的矩阵表示,而不仅限于特定的输入。
5. 递归与迭代(Recursion and Iteration)
编程思想:
- 递归和迭代是解决问题的两种基本方法。递归适用于问题的自然分解,而迭代则更适合于顺序处理。
哲学观点:
- 自相似性(Self-Similarity):递归方法通过将问题分解为更小的自相似问题来解决。
- 顺序处理(Sequential Processing):迭代方法通过按顺序处理数据来解决问题。
具体应用:
- 代码中主要使用了迭代方法(如for循环和while循环)来读取输入、处理字符串和打印输出。
6. 正则表达式(Regular Expressions)
编程思想:
- 使用正则表达式进行字符串匹配和处理,提供了一种强大的文本处理工具。
哲学观点:
- 模式识别(Pattern Recognition):通过定义模式来识别和处理字符串,简化复杂的文本处理任务。
具体应用:
- split_words函数使用正则表达式提取大写字母组成的单词。
7. 异常处理(Exception Handling)
编程思想:
- 在代码中加入异常处理机制,以应对可能出现的错误,提高代码的健壮性。
哲学观点:
- 鲁棒性(Robustness):通过处理异常情况,使程序能够在意外情况下仍然正常运行。
具体应用:
- 当前代码中没有明显的异常处理,可以加入例如try/except结构来处理可能的输入错误或文件读取错误。
总结
这段代码通过模块化、封装、抽象、可重用性、迭代、正则表达式等编程思想,使得代码结构清晰、功能明确、易于维护和扩展。同时,这些编程思想也体现了相关的哲学观点,如单一职责原则、信息隐藏和模式识别等,进一步提升了代码的整体质量。
举一反三
要掌握这些编程哲学和思想,并能举一反三,以下是一些具体的技巧和建议:
模块化(Modularity)
技巧:
- 函数化编程:将代码功能分解为独立的函数,每个函数负责一个明确的任务。
- 接口设计:为每个模块设计明确的接口(输入和输出),确保模块间的低耦合性。
- 代码复用:将通用功能提取为独立模块,以便在不同项目中复用。
举一反三:
- 在任何编程任务中,先思考如何将大任务分解为更小的子任务,并为每个子任务编写独立的函数。
- 例如,处理文件输入输出时,可以创建单独的函数来处理文件读取、数据解析和结果写入。
封装(Encapsulation)
技巧:
- 隐藏实现细节:将实现细节封装在模块内,只对外暴露必要的接口。
- 使用类和对象:在面向对象编程中,将数据和操作数据的方法封装在类中。
- 访问控制:使用访问修饰符(如私有、保护和公共)来控制不同成员的访问权限。
举一反三:
- 在设计类时,确保将属性设置为私有,提供必要的公共方法来访问和修改属性。
- 在Web开发中,隐藏数据库实现细节,通过API接口对外提供服务。
抽象(Abstraction)
技巧:
- 提取共性:识别代码中的共性部分,将其提取为抽象接口或基类。
- 使用继承和多态:在面向对象编程中,通过继承和多态实现代码的抽象和复用。
- 定义接口:使用接口或抽象类定义抽象行为,具体实现交给子类。
举一反三:
- 在不同项目中寻找相似的功能模块,将其抽象为通用库或工具类。
- 在数据处理时,定义一个抽象的处理流程,将具体的处理步骤交给子类实现。
可重用性(Reusability)
技巧:
- 编写通用代码:编写通用的、可配置的代码,使其在不同场景下都能使用。
- 创建库和工具:将常用功能封装为库或工具,使其在多个项目中复用。
- 避免硬编码:使用配置文件或参数传递,避免在代码中硬编码特定值。
举一反三:
- 创建一个通用的日志模块,可以在不同项目中使用,只需修改配置文件即可。
- 在Web开发中,编写通用的中间件或插件,能够在不同的Web框架中使用。
递归与迭代(Recursion and Iteration)
技巧:
- 选择适当的方法:根据问题的自然分解特点选择递归或迭代方法。
- 优化递归:使用递归时,注意尾递归优化或将递归转化为迭代以提高性能。
- 理解终止条件:在编写递归函数时,确保定义清晰的终止条件,避免无限递归。
举一反三:
- 在树或图的遍历问题中,理解如何使用递归进行深度优先搜索(DFS)和广度优先搜索(BFS)。
- 在算法设计中,尝试将递归算法转化为迭代算法,优化其性能。
正则表达式(Regular Expressions)
技巧:
- 学习正则语法:熟练掌握正则表达式的基本语法和常用模式。
- 测试和调试:使用正则表达式测试工具,保证正则表达式的正确性。
- 性能优化:在处理大文本时,注意正则表达式的性能,避免过于复杂的模式。
举一反三:
- 在数据清洗和文本处理任务中,使用正则表达式快速匹配和替换特定模式。
- 在Web开发中,使用正则表达式进行表单验证,确保输入格式的正确性。
异常处理(Exception Handling)
技巧:
- 捕获和处理异常:使用try/except结构捕获并处理可能的异常,防止程序崩溃。
- 提供有用的错误信息:在异常处理代码中,记录有用的错误信息,以便调试和排错。
- 清理资源:在异常处理代码中,确保正确地释放资源(如关闭文件、网络连接等)。
举一反三:
- 在文件处理、网络请求等可能出错的操作中,使用异常处理代码确保程序的健壮性。
- 在Web开发中,提供友好的错误页面,捕获并处理应用程序中的异常。
综合应用
技巧:
- 综合运用:在实际编程中,综合运用上述各种思想和技巧,提高代码质量。
- 持续学习:不断学习新的编程思想和技术,提高自己的编程能力。
- 代码评审:通过代码评审,与他人交流和学习,提高团队的整体代码质量。
举一反三:
- 在团队项目中,规范代码风格,制定代码评审流程,确保代码的质量和一致性。
- 定期学习和实践新的编程模式和设计原则,如SOLID原则、设计模式等,提高设计和编程能力。
总结
通过掌握这些编程思想和具体技巧,可以在不同的编程任务中灵活运用,提高代码的质量、可维护性和效率。持续学习和实践是提升编程能力的关键,不断总结经验,将理论应用于实践,才能真正做到举一反三。
这篇关于每日一题——Python实现PAT乙级1109 擅长C(举一反三+思想解读+逐步优化)七千字好文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



