本文主要是介绍如何愉快地实施数仓模型,对比下厨做饭,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

一般我们建设数仓,有一个链路:
比如这样的
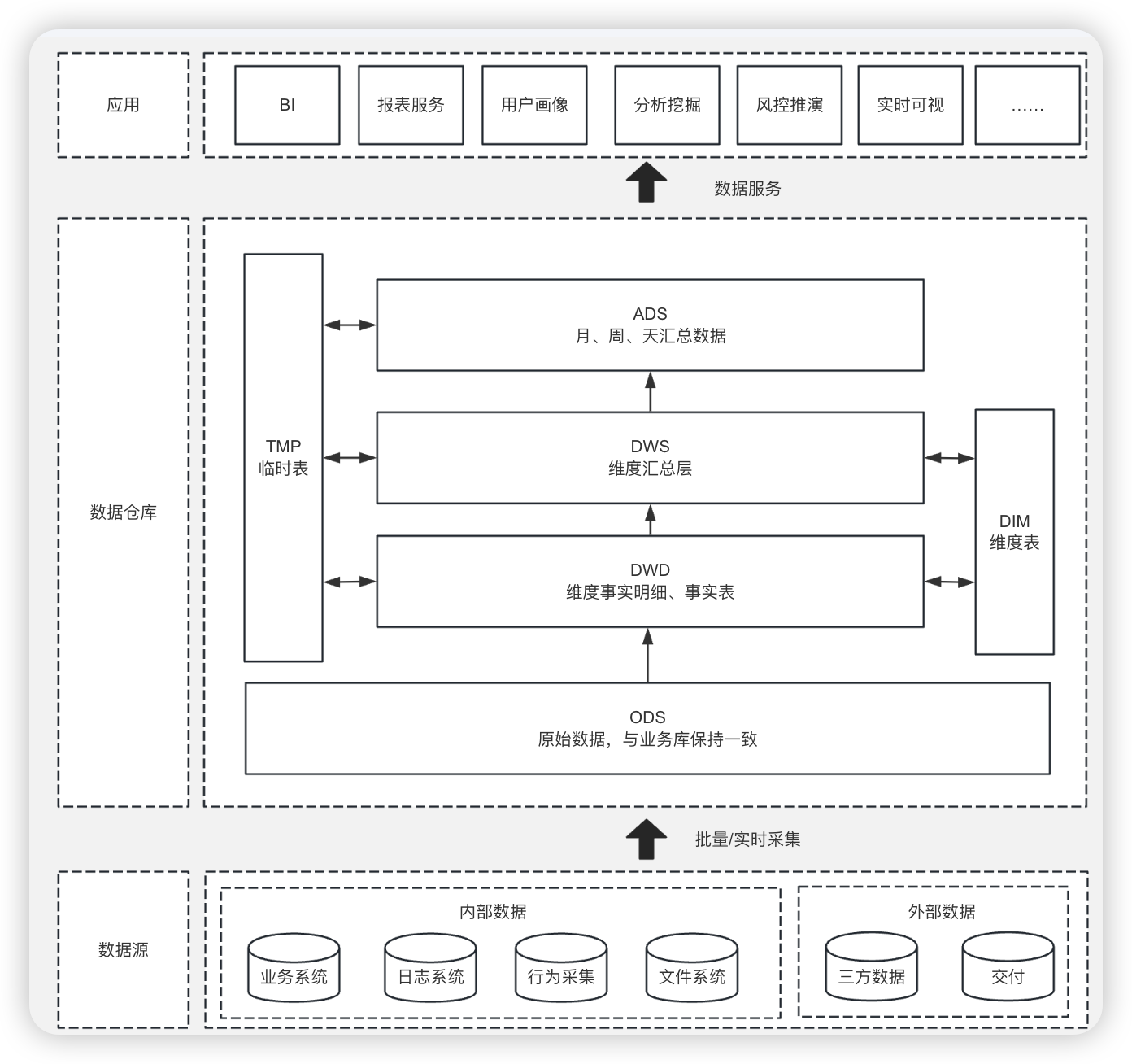
数据从原始层到DWD、DWS层、然后ADS层。
嘿,未来的大数据专家们!当我们开始实施数据模型时,不妨参考《大数据之路》这本宝藏书。
让我们一起简化流程,注重细节,同时保持愉快的心情!
以如下加工数据为例
1. 方案设计
方案设计是数据模型实施的第一步,主要考虑以下几个方面:
-
数据产出:设计数据链路的拓扑图(也就是上面👆的加工数据图),明确每个表的产出时间,确保数据模型的及时产出。比如,可以通过一张漂亮的拓扑图展示数据从源表到聚合层的流转过程。这就像设计一个美味的披萨,从面饼到撒上芝士,每一步都要精心设计。
-
链路设计:详细解释拓扑图中的每一步,包括聚合和连接操作,以及它们的具体逻辑。就像制作一杯复杂的咖啡,每一步的冲泡和添加糖浆都至关重要。
-
源表说明:列出并描述拓扑图中使用的所有源表,以及从这些表中获取的数据。想象一下,这就像列出厨房里所有的调料和配料,准备好一切才能开始烹饪。
-
口径说明:详细说明计算逻辑,包括where条件、group by字段和时间聚合范围等。这就像写食谱,要详细说明什么时候加盐、什么时候加糖。
如:
SELECT
product_id,
SUM(quantity * price) AS total_revenue
FROM sales
WHERE sale_date >= ‘2024-05-01’ AND sale_date < ‘2024-06-01’
GROUP BY product_id;
- **表结构设计**:定义产出表的字段、数据类型、是否增量更新等信息。就像设计菜谱的最终成品,定义每道菜的配料和做法。## 2. 链路性能与耗时评估数据链路中每个节点的资源消耗(CPU、内存)和耗时,以及数据存储需求,确保系统性能满足需求。就像你在健身房锻炼,每一个动作都需要评估你的体力和时间消耗。## 3. 数据查询记录Hive表到ES或MySQL、ClickHouse的数据流转路径,为后端调用提供必要的SQL查询示例,确保数据能够被正确查询和使用。这就像给朋友推荐一家餐厅,不仅要告诉他们地址,还要给出点菜的建议。## 4. 数据回溯在开发完成后,对历史数据进行回溯,以验证模型的准确性和完整性。这一步骤需要考虑的问题较多,不仅仅是简单的运行历史分区。就像看一部时间旅行的电影,回到过去验证一切是否正常。## 5. 值域说明处理特殊情况,如分母为0的情况,以及空值的处理方法(NULL、0或其他)。如:```sql
SELECTCOALESCE(quantity, 0) * COALESCE(price, 0) AS total_sales
FROM sales;
这就像在烹饪时,遇到食材不足或调料用完的情况,必须灵活应对,确保最终菜肴不出错。
6. 数据完整性
确保数据的完整性,包括例行任务、自动回溯和手动回溯的数据一致性。
需要提前评估风险,与业务方沟通,必要时牺牲部分数据以避免更大的损失。
就像在厨房里做饭,偶尔可能要牺牲一两个烤焦的面包,但我们最终还是会有一桌美味佳肴。
通过上述步骤,我们可以愉快地确保数据模型的有效实施,同时保证数据的准确性和完整性。
实际中可能有更多问题,欢迎交流~
这篇关于如何愉快地实施数仓模型,对比下厨做饭的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





