本文主要是介绍操作系统论文导读(二十):Making Powerful Enemies on NVIDIA GPUs,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RTSS-2022: Making Powerful Enemies on NVIDIA GPUs
目录
一、文章核心
二、文章背景
背景介绍
干扰通道
研究问题
文章的创新点
方法论
三、必要知识与相关工作
A 背景知识
CUDA 基础
GPU 硬件
并发和干扰通道
干扰通道
SM 内部干扰通道
B 相关工作
CPU时间分析
GPU时间分析
GPU共享
四、生成方法
目标
方法论介绍
实验设置框架
受害者选择
具体步骤
环境实现(A. Environment Implementation)
实施细节
敌人程序的实现(B. Enemy Implementation)
计算敌人模板(Compute Enemy Template)
内存敌人模板(Memory Enemy Template)
敌人程序的评估(C. Enemy Evaluation)
占用内核(Occupation Kernels)
灵敏度(Sensitivity)
通用实验结构(D. Generic Experiment Structure)
一、文章核心
这篇文章的核心是提出了一种基于“敌人程序”的方法,用于更准确地估计GPU任务在并发执行时的最坏情况执行时间(WCET)。文章主要解决了GPU并发任务之间的资源争夺导致的执行时间不确定性问题。通过实验驱动的方法,设计了能够最大化干扰GPU资源的敌人程序,并通过大量实际GPU基准程序验证了这些程序的有效性。文章的主要贡献包括提出了一种新的实验方法论,识别和定义了多种GPU干扰通道,并提供了详细的实验结果,证明这些敌人程序在增加任务执行时间方面比现有基线方法更有效。
二、文章背景
背景介绍
现代图形处理器(GPU)由于其强大的并行计算能力,越来越多地被用于安全关键的实时系统中,比如自动驾驶车辆。这些系统中的任务通常需要高性能计算,因此GPU成为了理想的计算资源。但是,在同一个GPU上并行执行多个计算任务(称为“内核”)会导致资源争夺问题,进而使得任务的执行时间变得不确定,这种现象被称为“干扰通道”。
干扰通道
干扰通道是指多个并发任务可能共享的硬件资源,例如计算单元、缓存和寄存器。这些资源的共享会使得一个任务的执行时间受到其他任务的影响,增加了实时系统中执行时间分析的复杂性。
研究问题
在实时系统中,确定任务的最坏情况执行时间(WCET)是至关重要的。现有的方法大多依赖于静态分析或测量的方法,但这些方法在面对GPU时通常显得过于保守或复杂。
文章的创新点
为了更准确地估计GPU任务的最坏情况执行时间,这篇文章提出了一种基于“敌人程序”的方法。敌人程序的设计旨在通过故意争夺GPU资源,最大化受害者程序的干扰,从而更可靠地估计最坏情况执行时间。
方法论
- 设计敌人程序:敌人程序需要针对特定的干扰通道进行优化,以最大化对受害者程序的干扰。
- 实验驱动方法:通过实验确定不同干扰通道的有效参数,设计出能够有效干扰这些通道的敌人程序。
- 性能评估:通过大量实际的GPU基准程序进行评估,比较敌人程序对任务执行时间的影响。
三、必要知识与相关工作
A 背景知识
CUDA 基础
CUDA 是为 NVIDIA GPU 编写程序的 C/C++ 编程接口。执行在 GPU 上的代码称为“内核”。编写 CUDA 程序时,程序员需要指定执行内核时使用的并行 GPU 线程数量。GPU 线程被组织成块(blocks),每个块包含多个线程。在启动内核时,需要指定每个块中的线程数量以及总块数。
每个内核都关联一个 CUDA 上下文(CUDA context),该上下文包含使用 GPU 时所需的状态信息。通常,每个 CPU 进程由 CUDA 运行时创建一个这样的上下文,不同上下文的内核不会同时在 GPU 上执行。
GPU 硬件

文章使用 NVIDIA GTX 1080 GPU 作为测试平台。这个 GPU 包含多个流式多处理器(SMs),每个 SM 能够执行大量的 GPU 线程。图1展示了 GTX 1080 的硬件布局。
- CUDA 核心:主要用于执行计算任务。
- L1 缓存:每个 SM 都有自己的本地 L1 数据缓存,用于存储最近使用的数据。
- L2 缓存:所有 SM 共享的全局 L2 缓存。
- DRAM:全局内存,所有 SM 都可以访问。
流式多处理器(SMs)是NVIDIA GPU并行计算能力的核心,通过包含多个CUDA核心、warp调度器、特殊功能单元和加载/存储单元,SM能够高效地执行大量并行任务。SM的设计允许GPU在面对复杂并行计算任务时,能够高效利用硬件资源
并发和干扰通道
GPU 上的并发可能比 CPU 上的并发更复杂。多个内核可以在不同的 CUDA 上下文中“并发”启动,但实际上它们可能不会同时执行。默认情况下,CUDA 强制时间片轮转,每次只允许一个上下文访问 GPU 硬件。
干扰通道
干扰通道是指多个并发内核可能共享的硬件资源。例如:
- L2 缓存:多个内核共享的缓存,可能会导致缓存冲突,增加缓存未命中率和内存延迟。
- MSHRs(缺失状态保持寄存器):用于处理缓存未命中的寄存器,如果这些寄存器被占满,会导致等待时间增加。
- DRAM:GPU 的全局内存,不同内核对 DRAM 的访问可能导致内存冲突和延迟。
SM 内部干扰通道
如果内核共享一个 SM,它们可能会争夺该 SM 内的硬件资源,包括:
- 计算单元(如 CUDA 核心):多个内核可能同时需要使用这些单元,导致延迟。
- L1 缓存和共享内存:这些都是 SM 本地的内存资源,共享这些资源可能导致互相干扰。
B 相关工作
CPU时间分析
- 静态分析:用于单核CPU的静态分析技术通过分析程序代码来计算最坏情况执行时间(WCET)。然而,对于多核CPU,静态分析通常不可行,因为任务之间可能的交互数量随着核心数量的增加而呈爆炸性增长。
- 基于测量的分析:由于静态分析的局限性,基于测量的方法更常用,通过观察任务执行样本生成WCET估计。资源共享的影响必须在这种方法中被考虑到。
- 资源划分:一种常见的方法是划分平台资源,使任务间不共享资源,防止干扰。
- 灵活性问题:划分技术可能不灵活,对个别任务施加不必要的限制。相反,可以允许任务共享资源,但在分析方法中考虑干扰。例如,一些研究通过引入与缓存相关的抢占延迟来考虑缓存争用。
GPU时间分析
- 单个GPU内核的时间分析:一些研究提供了单个GPU内核的鲁棒时间分析。例如,一项研究为NVIDIA的Fermi GPU架构提出了时间模型,但这些方法适用于有限的工作负载,可能无法扩展到其他架构。
- 统计理论:另有研究利用统计理论增强基于测量的WCET估计的可靠性,但这些方法受限于一些不太实际的假设,如样本之间的统计独立性。
- 静态方法:早期的一些研究提出了在单个SM上静态推导一组线程WCET的方法,但这些方法不能扩展到多个SM。
- 混合方法:还有一些研究采用混合方法,结合静态和基于测量的分析,但这些方法需要使用GPU模拟器,且仅适用于小内核。
GPU共享
- 多任务处理:有研究引入了NVIDIA GPU上可预测多任务处理的方法,但也使用了模拟器。
- 缓存和DRAM划分:另一项广泛的研究通过页面着色技术实现了对NVIDIA GPU缓存和DRAM的划分,改善了并发GPU任务的可预测性,但需要复杂的逆向工程,并对并发内核施加了一些不受欢迎的限制。
- 本文的方法:本文的方法与上述方法不同,我们允许并发GPU共享,但旨在考虑最坏情况干扰而不进行划分。
- 管理框架:其他研究提出了各种管理框架,以不同的权衡和限制共享NVIDIA GPU。还有一项研究涉及嵌入式GPU在常见工作负载之间的共享。尽管在其他上下文中有用,但这些研究要么没有测量任意GPU共享下的资源干扰,要么在处理实际应用方面能力有限。
四、生成方法
目标
我们的目标是构建“敌人程序”,以便对并发执行的GPU内核进行基于测量的稳健时间分析。这需要尽可能全面地考虑所有可能影响内核执行时间的干扰通道。
方法论介绍
我们引入了一种生成和测量干扰通道的方法,这些通道可能会影响与未知内核同时竞争设备资源的受害者程序。基于之前在多核CPU计算上的研究,我们的方法是在执行受害者程序的同时运行由一个或多个合成内核组成的敌人程序,这些程序争夺GPU资源。最终目标是生成比实际竞争内核更有害的敌人程序。
实验设置框架
受害者选择
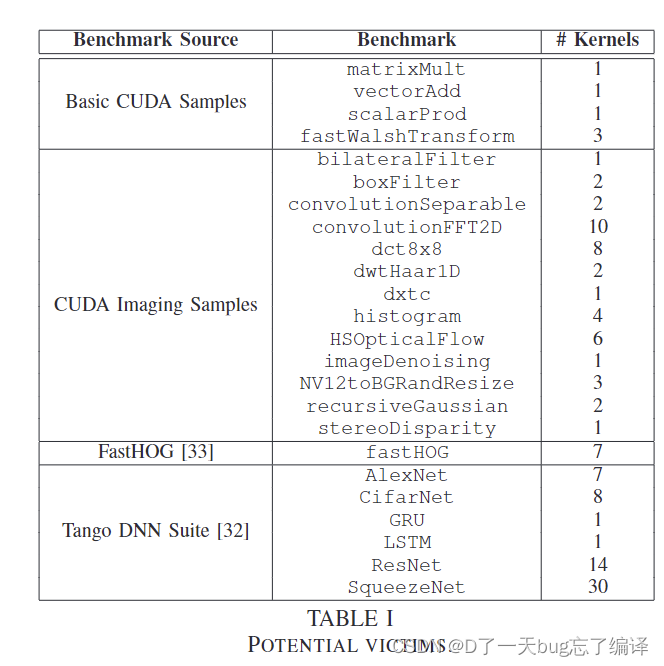
为了实验,我们从一组公开的基准应用程序中选择受害者。为了覆盖广泛的应用和内核类型,我们选择了24个CUDA程序中的每个内核进行评估,这些程序来源多样,包括几乎所有的Tango DNN套件程序和一组CUDA图像样本(不包括需要图形用户界面的图像程序)。表I列出了所有的受害者基准程序。某些基准执行多个内核,总共有117个不同的受害者内核。个别内核可能会用不同的输入多次调用。这些使用GPU的程序涵盖了与实时GPU使用相关的多个领域,包括图像处理、计算机视觉和神经网络。
具体步骤
-
定义和实现实验环境
- 环境包括硬件平台(如NVIDIA GTX 1080 GPU)、CUDA软件版本及其他可能影响内核竞争的约束条件。
-
选择敌人模板和参数
- 基于已有研究,我们选择不同类型的敌人模板(如计算密集型、内存密集型)和相应的参数来生成敌人程序。
-
评估敌人程序
- 使用定义的度量标准(如受害者程序的执行时间延迟)来评估敌人程序的干扰效果。
-
实验结构
- 按照预定的实验结构进行一系列测试,以确保敌人程序能够有效地干扰受害者程序的执行。
环境实现(A. Environment Implementation)
-
运行受害者和敌人程序
- 使用NVIDIA的多进程服务(MPS)来允许受害者内核和敌人内核并发运行。MPS将来自不同Linux进程的内核多路复用到一个CUDA上下文中,使它们能够在GPU上同时执行。
- 使用脚本先启动敌人程序,然后启动受害者程序。确保敌人内核的运行时间比受害者内核更长,以便在受害者程序的整个持续时间内都能发生干扰。
- 一些CUDA API函数可能会导致进程间阻塞,为避免这个问题,修改了部分基准程序的源代码,移除了这些阻塞函数的调用。
-
硬件平台
- 选择的硬件平台是NVIDIA GeForce GTX 1080,运行CUDA 11.1。
-
资源约束
- 资源约束可以有多种形式,例如最大可用内存、最大并发内核总数等。在我们的工作中,最重要的资源约束是竞争内核允许运行的SM数量或每个SM允许占用的warps(CUDA线程合集)数量。
- 在实验中,限制计算资源是必要的。例如,如果允许敌人完全占用GPU上的所有SM,测量结果将主要反映受害者等待SM可用的时间,而不是干扰通道相关的延迟。同样,如果允许受害者完全占用所有可用的SM,敌人将无法运行,受害者将不会受到任何干扰。
-
环境定义
- 定义了两个环境,每个环境使用不同的方法确保敌人和受害者始终一致地访问GPU的SM:
- SMK环境:用于测量SM内干扰,限制敌人最多占用每个SM的32个warps(SM容量的一半),确保每个SM上剩余的warps可供受害者使用。
- 空间多任务环境:用于测量SM间干扰,强制敌人完全占用GTX 1080的20个SM中的8个,使受害者只能在剩下的12个SM上执行。
- 定义了两个环境,每个环境使用不同的方法确保敌人和受害者始终一致地访问GPU的SM:
实施细节
-
SMK环境的实施
- 按照之前讨论的原则,构建SMK环境,使受害者和敌人必须共享SM。通过在每个可用的SM上启动一个敌人块,每个块包含我们希望敌人占用的精确warp数量。这样确保每个SM上都有一个敌人块。
- 受害者启动后,必须与敌人共享每个SM。由于设备资源限制(如每个SM的寄存器数量),在SMK环境下无法同时执行AlexNet、CifarNet和ResNet的所有内核,因此仅使用剩下的88个内核进行实验。
-
空间多任务环境的实施
- 同样的假设下,实施空间多任务环境,使敌人和受害者不共享SM。通过在GPU上启动64个warps的敌人内核,完全占用所有SM。
- 使用之前工作中的技术,强制内核只使用指定的一组SM。敌人内核代码检查其分配的SM ID,如果运行在我们希望分配给受害者的SM上,立即退出。
敌人程序的实现(B. Enemy Implementation)
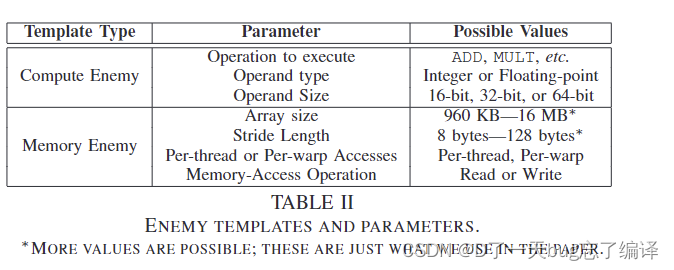
本文设计了两种类型的敌人内核模板,分别用于争夺计算资源和内存/缓存资源。表II列出了这两种模板及其相关参数。
计算敌人模板(Compute Enemy Template)
计算导向的敌人内核旨在最大化单个计算资源的压力。模板会反复执行选择的指令,目标是特定的硬件单元,如CUDA核心或特殊功能单元(SFUs)。计算敌人模板需要以下三个参数:
- 操作类型(Operation to execute):例如加法(ADD)、乘法(MULT)等。
- 操作数类型(Operand type):整数或浮点数。
- 操作数大小(Operand Size):16位、32位或64位。
这些参数组合决定了敌人内核将执行的指令。
内存敌人模板(Memory Enemy Template)
内存敌人模板旨在对内存和/或缓存资源施加压力,涉及以下四个参数:
- 数组大小(Array size):根据目标内存层次结构选择。例如,要对L2缓存施加压力,数组大小必须至少为L2缓存的大小(在GTX 1080上为2MB)。
- 步长长度(Stride Length):决定敌人程序的后续数组访问之间的字节数。例如,在L2缓存实验中,最有效的敌人程序步长长度应匹配缓存行大小(在GTX 1080上为128字节),以便每次数组访问都落入不同的缓存行。
- 每线程或每warp访问(Per-thread or Per-warp Accesses):如果每个warp中的每个线程访问数组的不同元素,则为每线程访问;如果每个warp访问不同元素,但同一warp内的所有线程访问相同元素,则为每warp访问。图2展示了这两种访问方式的区别。
- 内存访问操作(Memory-Access Operation):敌人程序访问数组时是读取还是写入数据。
内存敌人的参数值会根据目标内存层次结构的不同而有所不同。例如,要对L2缓存施加压力,数组大小至少应为L2缓存大小;步长长度应匹配缓存行大小(128字节),以确保每次访问都落入不同的缓存行。

图2展示了每线程访问和每warp访问的区别:
- 每线程访问(Per-Thread Access):每个线程访问数组中的不同元素。这种方式适用于更大规模的内存结构,比如L2缓存。
- 每warp访问(Per-Warp Access):每个warp访问数组中的不同元素,但warp内部的所有线程访问相同的元素。这种方式更适用于较小的内存结构,比如L1缓存。
敌人程序的评估(C. Enemy Evaluation)
为了测量敌人程序对受害者程序的影响,我们不能简单地将受害者程序在孤立情况下(即完全访问整个GPU)的性能与其在存在敌人情况下的性能进行比较。这是因为我们通过让敌人程序占用所有剩余的warps或SM来间接限制受害者的资源使用。这意味着即使某个特定的敌人程序对受害者没有干扰,受害者仍然会因为可用的SM或warps较少而执行得更慢。
占用内核(Occupation Kernels)

为了解决这个问题,我们实现了所谓的占用内核:一个占用与敌人相同数量的SM和warps,但对受害者干扰最小的内核。图3展示了占用内核代码的简化版本。占用内核不进行内存引用,每个块只有一个线程执行计算指令以浪费时间,而其余线程使用CUDA的__syncthreads指令故意停顿。
灵敏度(Sensitivity)
通过占用内核,我们可以定义一个敌人干扰的度量,排除部分SM或warps不可用对受害者的影响。这个度量称为灵敏度(sensitivity):定义为受害者在与敌人并发运行时的执行时间除以其与占用内核并发运行时的执行时间。
通用实验结构(D. Generic Experiment Structure)
以下部分的所有实验都使用相同的程序:
- 选择一个模板压力内核,计算或内存。注意有些实验需要多个内核来结合多种压力类型。
- 设置除一个敌人参数外的所有其他参数在实验中保持不变。这些常量参数要么设置为默认值(例如缓存实验的数组大小),要么设置为在之前实验中产生最大压力的值。
- 对于非恒定参数,选择多个值进行评估。这些值定义了将与受害者并发运行的一组敌人内核。
- 对受害者的时间进行多次测量,分别针对每个敌人内核和占用内核(我们在第IV节的实验中至少进行了十次采样,在第V节的实验中至少进行了五次)。
- 基于前一步的测量结果,计算受害者对每个敌人内核的灵敏度。
这篇关于操作系统论文导读(二十):Making Powerful Enemies on NVIDIA GPUs的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









