本文主要是介绍大数据快速使用Kerberos认证集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、创建安全集群并登录其Manager
-
创建安全集群,开启“Kerberos认证“参数开关,并配置“密码“、“确认密码“参数。该密码用于登录Manager,请妥善保管。
-
登录MRS管理控制台页面。
-
单击“集群列表“,在“现有集群“列表,单击指定的集群名称,进入集群信息页面。
-
单击“集群管理页面“后的“前往Manager”,打开Manager页面。
-
若用户创建集群时已经绑定弹性公网IP。
-
添加安全组规则,默认填充的是用户访问公网IP地址9022端口的规则。如需对安全组规则进行查看,修改和删除操作,请单击“管理安全组规则“。

说明:
- 自动获取的访问公网IP与用户本机IP不一致,属于正常现象,无需处理。
- 9022端口为knox的端口,需要开启访问knox的9022端口权限,才能访问Manager服务。
-
勾选“我确认xx.xx.xx.xx为可信任的公网访问IP,并允许从该IP访问MRS Manager页面。“
-
-
若用户创建集群时暂未绑定弹性公网IP。
-
在弹性公网IP下拉框中选择可用的弹性公网IP或单击“管理弹性公网IP“创建弹性公网IP。
-
添加安全组规则,默认填充的是用户访问公网IP地址9022端口的规则。如需对安全组规则进行查看,修改和删除操作,请点击“管理安全组规则“。

说明:
- 自动获取的访问公网IP与用户本机IP不一致,属于正常现象,无需处理。
- 9022端口为knox的端口,需要开启访问knox的9022端口权限,才能访问Manager服务。
-
勾选“我确认xx.xx.xx.xx为可信任的公网访问IP,并允许从该IP访问MRS Manager页面。“
-
-
-
单击“确定“,进入Manager登录页面。
-
输入创建集群时默认的用户名“admin“及设置的密码,单击“登录“进入Manager页面。
二、创建角色和用户
开启Kerberos认证的集群,必须通过以下步骤创建一个用户并分配相应权限来允许用户执行程序。
-
在Manager界面选择“系统 > 权限 > 角色”。
-
单击“添加角色“。
填写如下信息:
- 填写角色的名称,例如mrrole。
- 在“配置资源权限”选择待操作的集群,然后选择“Yarn > 调度队列 > root”,勾选“权限”列中的“提交”和“管理”,勾选完全后,不要单击确认,要单击如下图的待操作的集群名,再进行后面权限的选择。
- 选择“HBase > HBase Scope”,勾选global的“权限”列的“创建”、“读”、“写”和“执行”,勾选完全后,不要单击确认,要单击如下图的待操作的集群名,再进行后面权限的选择。
- 选择“HDFS > 文件系统 > hdfs://hacluster/”,勾选“权限”列的“读”、“写”和“执行”,勾选完全后,不要单击确认,要单击如下图的待操作的集群名,再进行后面权限的选择。
- 选择“Hive > Hive读写权限”,勾选“权限”列的“查询”、“删除”、“插入”和“建表”,单击“确定”,完成角色的创建。
-
选择“系统 > 权限 > 用户组 > 添加用户组”,为样例工程创建一个用户组,例如mrgroup。
-
选择“系统 > 权限 > 用户 > 添加用户”,为样例工程创建一个用户。
-
填写用户名,例如test,当需要执行Hive程序时,请设置用户名为“hiveuser“。
-
用户类型为“人机”用户。
-
输入密码(特别注意该密码在后面运行程序时要用到)。
-
加入用户组mrgroup和supergroup。
-
设置其“主组”为supergroup,并绑定角色mrrole取得权限。
单击“确定”完成用户创建。
-
-
选择“系统 > 权限 > 用户”,选择新建用户test,选择“更多 > 下载认证凭据”,保存后解压得到用户的keytab文件与krb5.conf文件。
三、执行MapReduce程序
本小节提供执行MapReduce程序的操作指导,旨在指导用户在安全集群模式下运行程序。
前提条件
已编译好待运行的程序及对应的数据文件,如mapreduce-examples-1.0.jar、input_data1.txt和input_data2.txt。
操作步骤
-
采用远程登录软件(比如:MobaXterm)通过ssh登录(使用集群弹性IP登录)到安全集群的master节点。
-
登录成功后分别执行下列命令,在/opt/Bigdata/client目录下创建test文件夹,在test目录下创建conf文件夹:
cd /opt/Bigdata/client mkdir test cd test mkdir conf -
使用上传工具(比如:WinScp)将mapreduce-examples-1.0.jar、input_data1.txt和input_data2.txt复制到test目录下,将“创建角色和用户“中的步骤5获得的keytab文件和krb5.conf文件复制到conf目录。
-
执行如下命令配置环境变量并认证已创建用户,例如test。
cd /opt/Bigdata/client source bigdata_env export YARN_USER_CLASSPATH=/opt/Bigdata/client/test/conf/ kinit test然后按照提示输入密码,无异常提示返回(首次登录需按照系统提示修改密码),则完成了用户的kerberos认证。
-
执行如下命令将数据导入到HDFS中:
cd test hdfs dfs -mkdir /tmp/input hdfs dfs -put input_data* /tmp/input -
执行如下命令运行程序:
yarn jar mapreduce-examples-1.0.jar com.huawei.bigdata.mapreduce.examples.FemaleInfoCollector /tmp/input /tmp/mapreduce_output其中:
/tmp/input指HDFS文件系统中input的路径。
/tmp/mapreduce_output指HDFS文件系统中output的路径,该目录必须不存在,否则会报错。
-
程序运行成功后,执行 hdfs dfs -ls /tmp/mapreduce_output会显示如下:
图 1 查看程序运行结果

四、执行Spark程序
本小节提供执行Spark程序的操作指导,旨在指导用户在安全集群模式下运行程序。
前提条件
已编译好待运行的程序及对应的数据文件,如FemaleInfoCollection.jar、input_data1.txt和input_data2.txt。
操作步骤
-
采用远程登录软件(比如:MobaXterm)通过ssh登录(使用集群弹性IP登录)到安全集群的master节点。
-
登录成功后分别执行下列命令,在/opt/Bigdata/client目录下创建test文件夹,在test目录下创建conf文件夹:
cd /opt/Bigdata/client mkdir test cd test mkdir conf -
使用上传工具(比如:WinScp)将样FemaleInfoCollection.jar、input_data1.txt和input_data2.txt复制到test目录下,将“创建角色和用户“中的步骤5获得的keytab文件和krb5.conf文件复制到conf目录。
-
执行如下命令配置环境变量并认证已创建用户,例如test。
cd /opt/Bigdata/client source bigdata_env export YARN_USER_CLASSPATH=/opt/Bigdata/client/test/conf/ kinit test然后按照提示输入密码,无异常提示返回,则完成了用户的kerberos认证。
-
执行如下命令将数据导入到HDFS中:
cd test hdfs dfs -mkdir /tmp/input hdfs dfs -put input_data* /tmp/input -
执行如下命令运行程序:
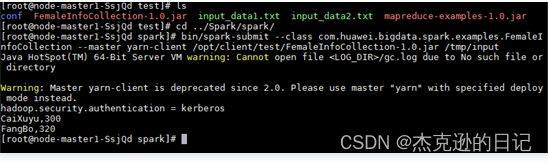
cd /opt/Bigdata/client/Spark/spark bin/spark-submit --class com.huawei.bigdata.spark.examples.FemaleInfoCollection --master yarn-client /opt/Bigdata/client/test/FemaleInfoCollection-1.0.jar /tmp/input -
程序运行成功后,会显示如下:
图 2 程序运行结果
五、执行Hive程序
本小节提供执行Hive程序的操作指导,旨在指导用户在安全集群模式下运行程序。
前提条件
已编译好待运行的程序及对应的数据文件,如hive-examples-1.0.jar、input_data1.txt和input_data2.txt。
操作步骤
-
采用远程登录软件(比如:MobaXterm)通过ssh登录(使用集群弹性IP登录)到安全集群的master节点。
-
登录成功后分别执行下列命令,在/opt/Bigdata/client目录下创建test文件夹,在test目录下创建conf文件夹:
cd /opt/Bigdata/client mkdir test cd test mkdir conf -
使用上传工具(比如:WinScp)将样FemaleInfoCollection.jar、input_data1.txt和input_data2.txt复制到test目录下,将“创建角色和用户“中的步骤5获得的keytab文件和krb5.conf文件复制到conf目录。
-
执行如下命令配置环境变量并认证已创建用户,例如test。
cd /opt/Bigdata/client source bigdata_env export YARN_USER_CLASSPATH=/opt/Bigdata/client/test/conf/ kinit test然后按照提示输入密码,无异常提示返回,则完成了用户的kerberos认证。
-
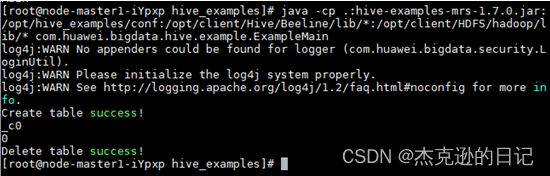
执行如下命令运行程序:
chmod +x /opt/hive_examples -R cd /opt/hive_examples java -cp .:hive-examples-1.0.jar:/opt/hive_examples/conf:/opt/Bigdata/client/Hive/Beeline/lib/*:/opt/Bigdata/client/HDFS/hadoop/lib/* com.huawei.bigdata.hive.example.ExampleMain -
程序运行成功后,会显示如下:
图 3 程序运行的结果
这篇关于大数据快速使用Kerberos认证集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





