本文主要是介绍两句话让LLM逻辑推理瞬间崩溃!!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一道简单的逻辑问题,竟让几乎所有的LLM全军覆没?
对于人类来说,这个名为「爱丽丝梦游仙境」(AIW)的测试并不算很难——
「爱丽丝有N个兄弟,她还有M个姐妹。爱丽丝的兄弟有多少个姐妹?」
稍加思考,答案显而易见:M+1。(爱丽丝的姐妹数量加上爱丽丝自己)
然而,当研究人员让GPT-3.5/4、Claude、Gemini、Llama、Mistral等模型回答时,结果却非常离谱。只有OpenAI最新的GPT-4o勉强及格。
GPT-4o深夜发布!Plus免费可用!![]() https://www.zhihu.com/pin/1773645611381747712
https://www.zhihu.com/pin/1773645611381747712
没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几分钟搞定:
升级ChatGPT-4o Turbo步骤![]() https://www.zhihu.com/pin/1768399982598909952
https://www.zhihu.com/pin/1768399982598909952
问题不仅仅是基本的不准确性:当要求展示其工作过程时,AI会详细说明一些荒谬且错误的「思考」过程,这些过程毫无意义——更奇怪的是,当被告知其工作不准确时,模型反复变得愤怒并坚持其错误答案。

论文地址:https://arxiv.org/abs/2406.02061
开源地址:https://github.com/LAION-AI/AIW
正如来自知名开源AI研究机构LAION的团队所揭示的——即使是当今最先进的模型,也几乎不具有小学生的推理能力。
在本次研究中,团队借鉴「爱丽丝梦游仙境」的童话故事,将提出的测试集简称为AIW:「爱丽丝有N个兄弟,她还有M个姐妹。爱丽丝的兄弟有多少个姐妹?」

显然,这对大多数成年人来说并没有挑战性;甚至对于一定年龄以上的儿童来说,通过常识推理也不难解决。
研究人员最初也认为,这对LLM不会构成什么挑战。
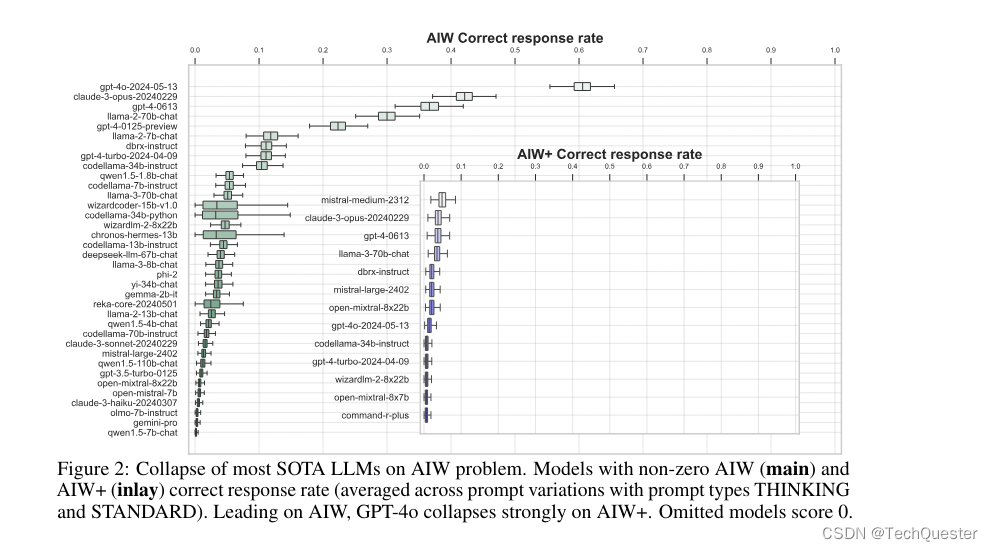
然而,大多数的SOTA模型竟然回答得非常费劲。而且,更改句子表述方式或者N、M具体数值时,回答正确率会产生大幅变化。
对此团队认为,模型似乎是在「蒙」答案,几乎不考虑逻辑,只是对问题中提到的数字加减乘除后给出结果,因此有些N和M值的对应答案比较容易蒙对。
实验结果出乎很多人的意料——大多数的先进LLM无法对AIW问题推理出正确答案,即使尝试各种提示方法也没能改变模型崩溃的结果。
可以看到,大多数模型的正确响应率都不超过0.2,只有4个模型超过了0.3,包括GPT-4o和Claude 3 Opus,以及唯一的开源模型Llama2-70B Chat。其中GPT-4o的均值达到了0.6附近。
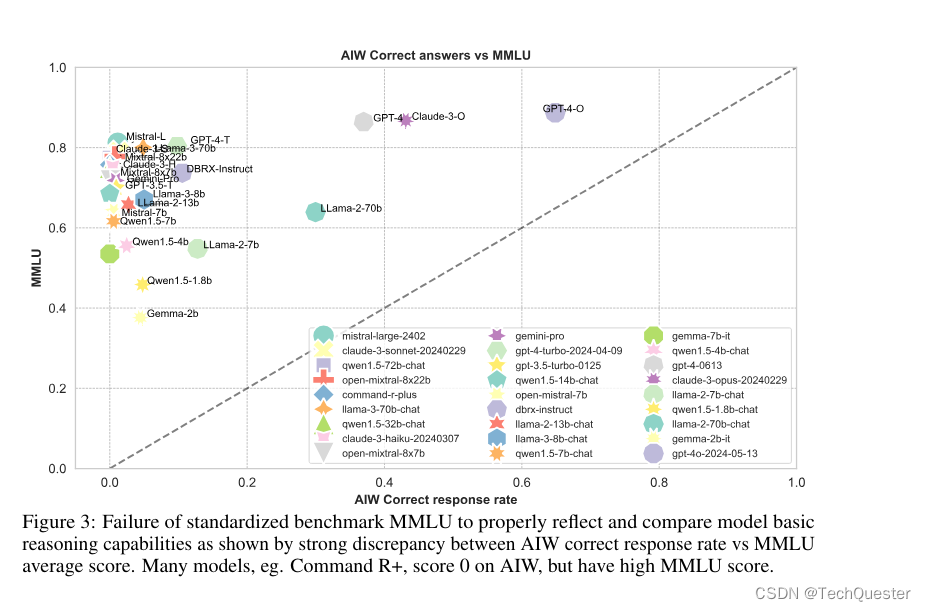
图3中可以看到,大多数模型聚集在纵轴附近,只有Llama2-70B、GPT-4、GPT-4o和Claude 3几个模型较为接近校准线,这表明MMLU分数与AIW之间的显著不匹配。
但值得注意的是,在和MATH的对比中,Llama2-7B和Llama2-70B两个模型在AIW的得分反而高于MATH。这两个模型在AIW与各个基准测试的校准中都有较好的表现。
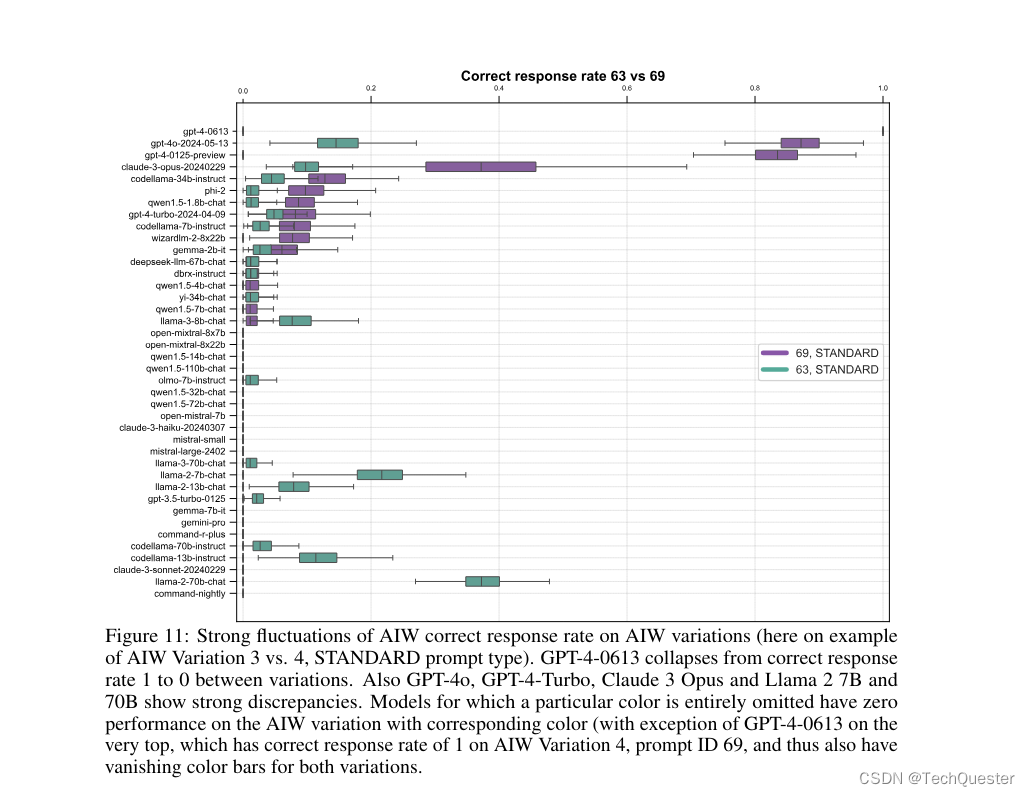
团队还对AIW不同变体上的准确率进行了横向比较,结果很多模型的表现都出现了大幅波动。
比如本来能挤进前四的GPT-4-0613,换了个问题,准确率就快降到0了。GPT-4o、GPT-4 Turbo、Claude 3 Opus和Llama2-70B等高分模型也都出现较大的波动。
在目睹了LLM推理能力的溃败后,研究人员们非常好奇这些模型到底错在哪里。
在Thinking类型的prompt中,包含重新检查答案的要求,结果发现这些LLM都有「蜜汁自信」,对自己给出的解决方案非常有信心。
甚至在给出错误推理和错误答案时,模型还会称它们提供的解决方案质量很高。

推荐阅读:
如何免费使用GPT-4o?如何升级GPT...
更强大Mamba-2正式发布啦!!!
黎曼猜想取得重大进展!!
这篇关于两句话让LLM逻辑推理瞬间崩溃!!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

![[轻笔记] ubuntu Shell脚本实现监视指定进程的运行状态,并能在程序崩溃后重启动该程序](/front/images/it_default2.jpg)