本文主要是介绍【数据结构】前缀树(字典树)汇总,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基础
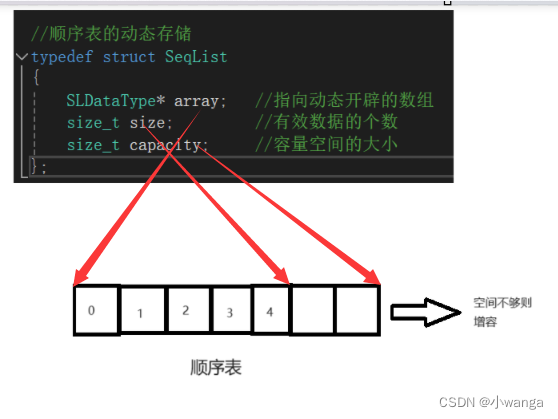
{“a”,“abc”,“bac”,“bbc”,“ca” }的字典树如下图:

最主用的应用:一,字符串编码。二,位运算。
字符串编码
相比利用哈希映射编码,优点如下:
依次查询长度为n的字符串s的前缀时间复杂度是O(n)。查询完s[0…i],再查询s[0…i+1]的时间复杂度是O(1)。而哈希映射的时间复杂度是:O(nn)。
利用哈希映射编码的代码如下:
注意m_iLeafIndex 为-1,表示此节点不是任何字符串的结束字符。
class CStrToIndex
{
public:CStrToIndex() {}CStrToIndex(const vector<string>& wordList) {for (const auto& str : wordList){Add(str);}}int Add(const string& str){if (m_mIndexs.count(str)) { return m_mIndexs[str]; }m_mIndexs[str] = m_strs.size();m_strs.push_back(str);return m_strs.size()-1;}vector<string> m_strs;int GetIndex(const string& str){if (m_mIndexs.count(str)) { return m_mIndexs[str]; }return -1;}
protected:unordered_map<string, int> m_mIndexs;
};
利用字典树编码的代码如下:
template<class TData = char, int iTypeNum = 26, TData cBegin = 'a'>
class CTrieNode
{
public:~CTrieNode(){for (auto& [tmp, ptr] : m_dataToChilds) {delete ptr;}}CTrieNode* AddChar(TData ele, int& iMaxID){
#ifdef _DEBUGif ((ele < cBegin) || (ele >= cBegin + iTypeNum)){return nullptr;}
#endifconst int index = ele - cBegin;auto ptr = m_dataToChilds[ele - cBegin];if (!ptr){m_dataToChilds[index] = new CTrieNode();
#ifdef _DEBUGm_dataToChilds[index]->m_iID = ++iMaxID;m_childForDebug[ele] = m_dataToChilds[index];
#endif}return m_dataToChilds[index];}CTrieNode* GetChild(TData ele){
#ifdef _DEBUGif ((ele < cBegin) || (ele >= cBegin + iTypeNum)){return nullptr;}
#endifreturn m_dataToChilds[ele - cBegin];}
protected:
#ifdef _DEBUGint m_iID = -1;std::unordered_map<TData, CTrieNode*> m_childForDebug;
#endif
public:int m_iLeafIndex = -1;
protected://CTrieNode* m_dataToChilds[iTypeNum] = { nullptr };//空间换时间 大约216字节//unordered_map<int, CTrieNode*> m_dataToChilds;//时间换空间 大约56字节map<int, CTrieNode*> m_dataToChilds;//时间换空间,空间略优于哈希映射,数量小于256时,时间也优。大约48字节
};
template<class TData = char, int iTypeNum = 26, TData cBegin = 'a'>
class CTrie
{
public:int GetLeadCount(){return m_iLeafCount;}CTrieNode<TData, iTypeNum, cBegin>* AddA(CTrieNode<TData, iTypeNum, cBegin>* par,TData curValue){auto curNode =par->AddChar(curValue, m_iMaxID);FreshLeafIndex(curNode);return curNode;}template<class IT>int Add(IT begin, IT end){auto pNode = &m_root;for (; begin != end; ++begin){pNode = pNode->AddChar(*begin, m_iMaxID);}FreshLeafIndex(pNode);return pNode->m_iLeafIndex;} template<class IT>CTrieNode<TData, iTypeNum, cBegin>* Search(IT begin, IT end){auto ptr = &m_root;for (; begin != end; ++begin){ptr = ptr->GetChild(*begin);if (nullptr == ptr){return nullptr;}}return ptr;}CTrieNode<TData, iTypeNum, cBegin> m_root;
protected:void FreshLeafIndex(CTrieNode<TData, iTypeNum, cBegin>* pNode){if (-1 == pNode->m_iLeafIndex){pNode->m_iLeafIndex = m_iLeafCount++;}}int m_iMaxID = 0;int m_iLeafCount = 0;
};
二进制位运算(01前缀树)
比如求nums和x的xor最大值。
将nums放到01放到前缀树中。通过拆位法依次从高到低处理各位,如果x 此为1,则优先选择前缀树的0分支;如果x为0,则优先选择前缀树的1分支。
class C2BNumTrieNode
{
public:C2BNumTrieNode(){m_childs[0] = m_childs[1] = nullptr;}bool GetNot0Child(bool bFirstRight){auto ptr = m_childs[bFirstRight];if (ptr && (ptr->m_iNum > 0)){return bFirstRight;}return !bFirstRight;}int m_iNum = 0;C2BNumTrieNode* m_childs[2];
};template<class T = int, int iLeveCount = 31>
class C2BNumTrie
{
public:C2BNumTrie(){m_pRoot = new C2BNumTrieNode();}void Add(T iNum){m_setHas.emplace(iNum);C2BNumTrieNode* p = m_pRoot;for (int i = iLeveCount - 1; i >= 0; i--){p->m_iNum++;bool bRight = iNum & ((T)1 << i);if (nullptr == p->m_childs[bRight]){p->m_childs[bRight] = new C2BNumTrieNode();}p = p->m_childs[bRight];}p->m_iNum++;}void Del(T iNum){auto it = m_setHas.find(iNum);if (m_setHas.end() == it){return;}m_setHas.erase(it);C2BNumTrieNode* p = m_pRoot;for (int i = iLeveCount - 1; i >= 0; i--){p->m_iNum--;bool bRight = iNum & ((T)1 << i);p = p->m_childs[bRight];}p->m_iNum--;} void Swap(C2BNumTrie<T, iLeveCount>& o) {swap(m_pRoot, o.m_pRoot);swap(m_setHas, o.m_setHas);}C2BNumTrieNode* m_pRoot;std::unordered_multiset<T> m_setHas;
};template<class T = int, int iLeveCount = 31>
class CMaxXor2BTrie : public C2BNumTrie<T, iLeveCount>
{
public:T MaxXor(T iNum){C2BNumTrieNode* p = C2BNumTrie<T, iLeveCount>::m_pRoot;T iRet = 0;for (int i = iLeveCount - 1; i >= 0; i--){bool bRight = !(iNum & ((T)1 << i));bool bSel = p->GetNot0Child(bRight);p = p->m_childs[bSel];if (bSel == bRight){iRet |= ((T)1 << i);}}return iRet;}
};
题解
| 给字符串编码 | 难道分 |
|---|---|
| 字典树】 【哈希表】 【字符串】3076. 数组中的最短非公共子字符串 | 1635 |
| 【字典树(前缀树) 字符串】2416. 字符串的前缀分数和需要记录子孙数量 | 1725 |
| 【字典树 最长公共前缀】1316. 不同的循环子字符串 | 1836 |
| 【字典树(前缀树)】1032. 字符流 | 1970 |
| 【map】【滑动窗口】【字典树】C++算法:2781最长合法子字符串的长度 | 2203 |
| 【字典树】【字符串】【 前缀】3093. 最长公共后缀查询 | 2118 |
| 【字典树】【KMP】【C++算法】3045统计前后缀下标对 II | 2327 |
| 【字典树 离线查询 深度优先】1938. 查询最大基因差 | 2502 |
| 动态规划 多源路径 字典树 LeetCode2977:转换字符串的最小成本 | 2695 |
| 【动态规划】 【字典树】C++算法:472 连接词 | |
| 【回溯 字典树(前缀树)】212. 单词搜索 II | |
| 【字典树 马拉车算法】336. 回文对 |
| 01前缀树 | |
|---|---|
| 【字典树】2935找出强数对的最大异或值 II | 2348 |
| 【字典树(前缀树) 异或 离线查询】1707. 与数组中元素的最大异或值 | 2358 |
| 【字典树(前缀树) 位运算】1803. 统计异或值在范围内的数对有多少 | 2479 |
| 其它前缀树 | |
|---|---|
| 【字典树(前缀树) 哈希映射 后序序列化】1948. 删除系统中的重复文件夹需要DFS | 2533 |

扩展阅读
视频课程
有效学习:明确的目标 及时的反馈 拉伸区(难度合适),可以先学简单的课程,请移步CSDN学院,听白银讲师(也就是鄙人)的讲解。
https://edu.csdn.net/course/detail/38771
如何你想快速形成战斗了,为老板分忧,请学习C#入职培训、C++入职培训等课程
https://edu.csdn.net/lecturer/6176
相关下载
想高屋建瓴的学习算法,请下载《喜缺全书算法册》doc版
https://download.csdn.net/download/he_zhidan/88348653
| 我想对大家说的话 |
|---|
| 《喜缺全书算法册》以原理、正确性证明、总结为主。 |
| 闻缺陷则喜是一个美好的愿望,早发现问题,早修改问题,给老板节约钱。 |
| 子墨子言之:事无终始,无务多业。也就是我们常说的专业的人做专业的事。 |
| 如果程序是一条龙,那算法就是他的是睛 |
测试环境
操作系统:win7 开发环境: VS2019 C++17
或者 操作系统:win10 开发环境: VS2022 C++17
如无特殊说明,本算法用**C++**实现。

这篇关于【数据结构】前缀树(字典树)汇总的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!