本文主要是介绍MapReduce的Reduce Size Join,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
mapper side join
这个没仔细讲,但是是在每个Mapper里来做的。
reduce side join
老师讲的非常清楚了,比如说CustomerMapper和OrderMapper,我都是处理出一个key-value值,这个key就是两个表都有的字段比如说Customer_Id。当然,order这边可能一个Customer会有多个订单,所以是多个订单记录组成的value。
现在就非常清晰了:
CustomerMapper的key是Customer_Id
CustomerMapper的value是整条记录(我们给他加个001, 来表示一下它是Customer的数据)
OrderMapper的key也是Customer_Id
OrderMapper的value是整条记录(我们给他加个002, 来表示一下它是Order的数据,注意一下他是可能一个客户有多个订单)

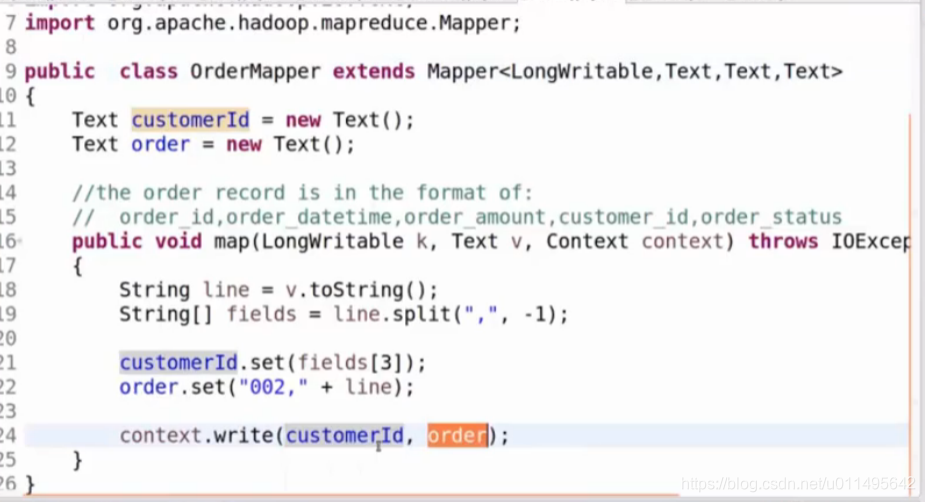
然后这两对key-value,shuffle到Reducer。
Reducer接收这两组数据,001的和002的数据,key相同的直接用 +合并即可。
order这里的处理呢,是因为一个客户有多个订单。

这篇关于MapReduce的Reduce Size Join的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


